
随着信息技术的发展,人们在日常生活和工作中都不可避免的要用到邮箱、聊天工具、云存储等网络服务。然而,这些服务很多时候都是单独运行的,不能很好的实现资源共享。针对该问题,IFTTT 提出了“让互联网为你服务”的概念,利用各网站和应用的开放 API,实现了不同服务间的信息关联。例如,IFTTT 可以把指定号码发送的短信自动转发邮箱等。为了实现这些功能,IFTTT 搭建了高性能的数据架构。近期, IFTTT 的工程师 Anuj Goyal 对数据架构的概况进行了介绍,并分享了在操作数据时的一些经验和教训。
在 IFTTT,数据非常重要——业务研发和营销团队依赖数据进行关键性业务决策;产品团队依赖数据运行测试 / 了解产品的使用情况,从而进行产品决策;数据团队本身也依赖数据来构建类似 Recipe 推荐系统和探测垃圾邮件的工具等;甚至合作伙伴也需要依赖数据来实时了解 Channel 的性能。鉴于数据如此重要,而 IFTTT 的服务每天又会产生超过数十亿个事件,IFTTT 的数据框架具备了高度可扩展性、稳定性和灵活性等特点。接下来,本文就对数据架构进行详细分析。
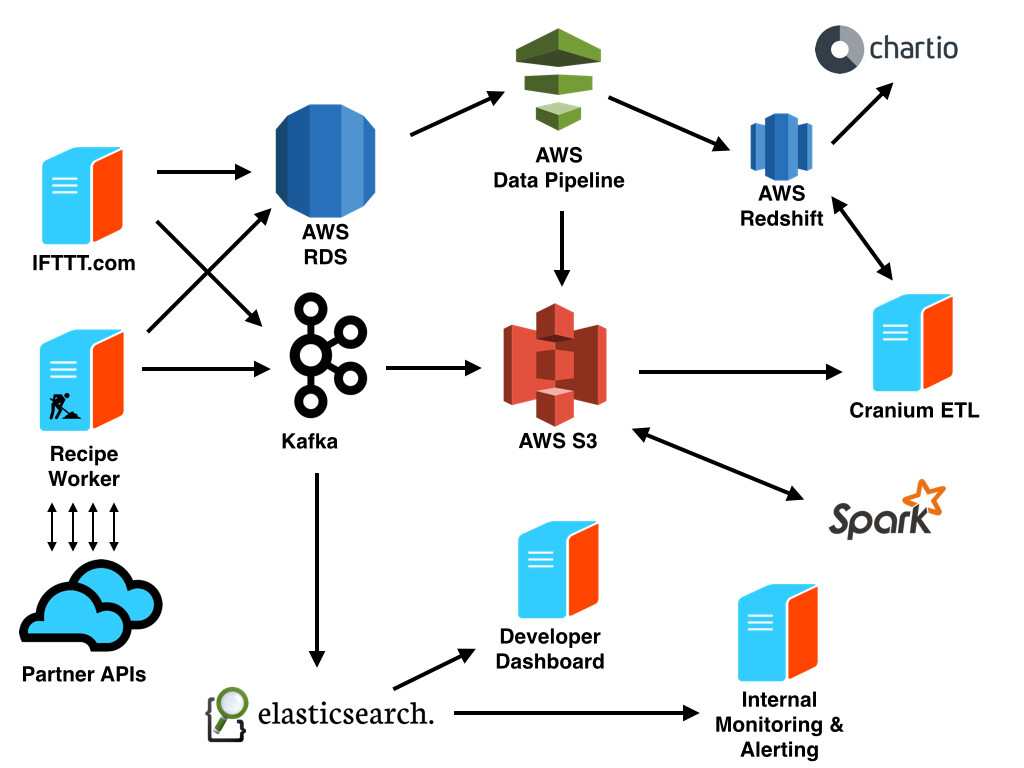
数据源
在 IFTTT,共有三种数据源对于理解用户行为和 Channel 性能非常重要。首先, AWS RDS 中的 MySQL 集群负责维护用户、Channel、Recipe 及其相互之间的关系等核心应用。运行在其 Rails 应用中的 IFTTT.com 和移动应用所产生的数据就通过 AWS Data Pipeline ,导出到 S3 和 Redshift 中。其次,用户和 IFTTT 产品交互时,通过 Rails 应用所产生的时间数据流入到 Kafka 集群中。最后,为了帮助监控上百个合作 API 的行为,IFTTT 收集在运行 Recipe 时所产生的 API 请求的信息。这些包括反应时间和 HTTP 状态代码的信息同样流入到了 Kafka 集群中。
IFTTT 的 Kafka
IFTTT 利用 Kafka 作为数据传输层来取得数据产生者和消费者之间的松耦合。数据产生者首先把数据发送给 Kafka。然后,数据消费者再从 Kafka 读取数据。因此,数据架构可以很方便的添加新的数据消费者。
由于 Kafka 扮演着基于日志的事件流的角色,数据消费者在事件流中保留着自己位置的轨迹。这使得消费者可以以实时和批处理的方式来操作数据。例如,批处理的消费者可以利用 Secor 将每个小时的数据拷贝发送到 S3 中;而实时消费者则利用即将开源的库将数据发送到 Elasticsearch 集群中。而且,在出现错误时,消费者还可以对数据进行重新处理。
商务智能
S3 中的数据经过 ETL 平台 Cranium 的转换和归一化后,输出到 AWS Redshift 中。Cranium 允许利用 SQL 和 Ruby 编写 ETL 任务、定义这些任务之间的依赖性以及调度这些任务的执行。Cranium 支持利用 Ruby 和 D3 进行的即席报告。但是,绝大部分的可视化工作还是发生在 Chartio 中。
而且,Chartio 对于只了解很少 SQL 的用户也非常友好。在这些工具的帮助下,从工程人员到业务研发人员和社区人员都可以对数据进行挖掘。
机器学习
IFTTT 的研发团队利用了很多机器学习技术来保证用户体验。对于 Recipe 推荐和问题探测,IFTTT 使用了运行在 EC2 上的 Apache Spark ,并将 S3 当作其数据存储。
实时监控和提醒
API 事件存储在 Elasticsearch 中,用于监控和提醒。IFTTT 使用 Kibana 来实时显示工作进程和合作 API 的性能。在 API 出现问题时,IFTTT 的合作者可以访问专门的 Developer Channel,创建 Recipe,从而提醒实际行动(SMS、Email 和 Slack 等)的进行。
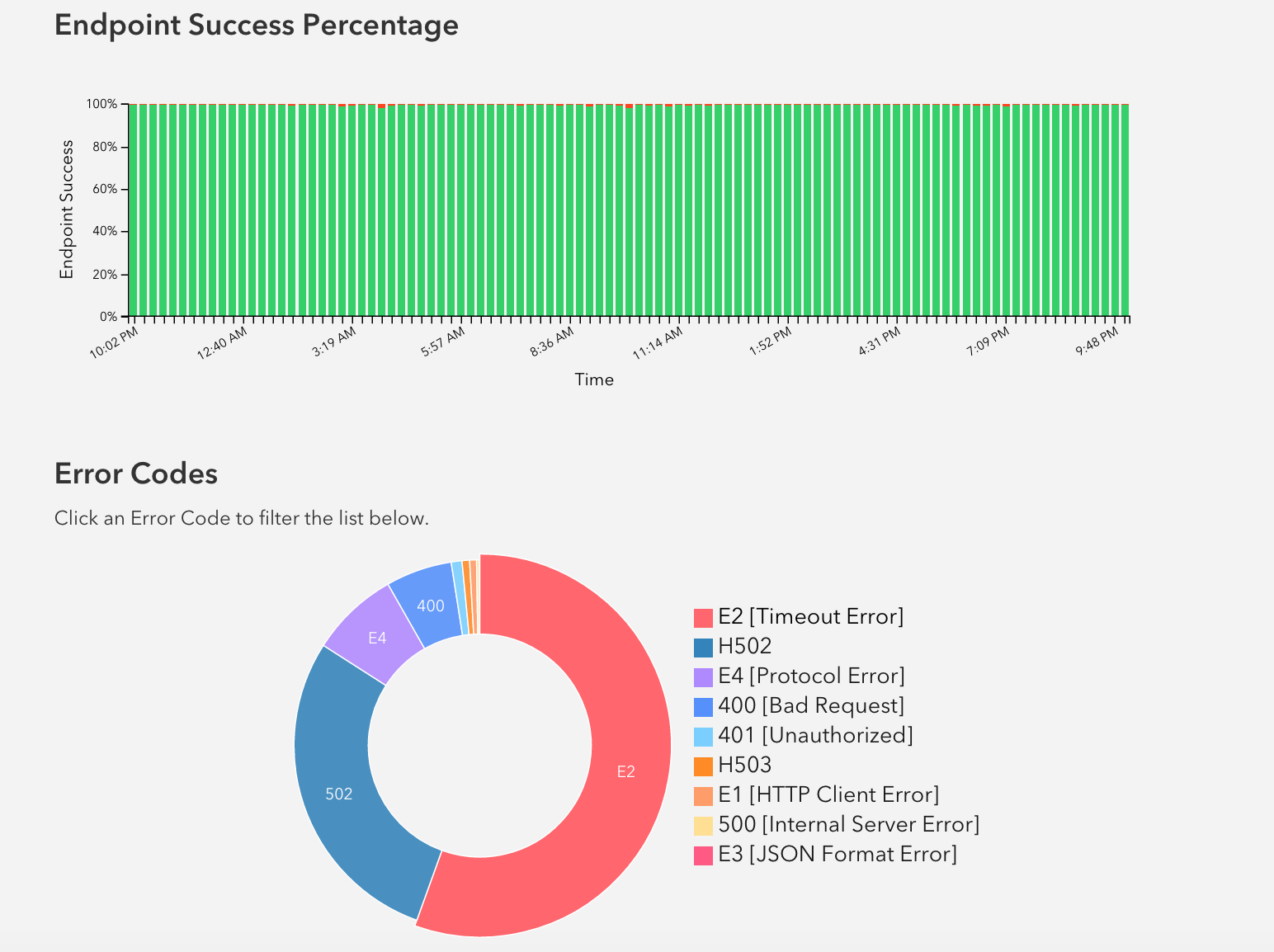
在开发者视图内,合作者可以在 Elasticsearch 的帮助的帮助下访问 Channel 健康相关的实时日志和可视化图表。开发者也可以通过这些有力的分析来了解 Channel 的使用情况。
经验与教训
最后, Anuj 表示,IFTTT 从数据架构中得到的教训主要包括以下几点:
- 通过 Kafka 这样的数据传输层实现的生产者和消费者的隔离非常有用,且使得 Data Pipeline 的适应性更强。例如,一些比较慢的消费者也不会影响其他消费者或者生产者的性能。
- 从一开始就要使用集群,方便以后的扩展!但是,在因为性能问题投入更多节点之前,一定要先认定系统的性能瓶颈。例如,在 Elasticsearch 中,如果碎片太多,添加更多的节点或许并不会加速查询。最好先减少碎片大小来观察性能是否改善。
- 在类似的复杂架构中,设置合适的警告来保证系统工作正常是非常关键的!IFTTT 使用 Sematext 来监控 Kafka 集群和消费者,并分别使用 Pingdom 和 Pagerduty 进行监控和提醒。
- 为了完全信任数据,在处理流中加入若干自动化的数据验证步骤非常重要!例如,IFTTT 开发了一个服务来比较产品表和 Redshift 表中的行数,并在出现异常情况时发出提醒。
- 在长期存储中使用基于日期的文件夹结构(YYYY/MM/DD)来存储事件数据。这样存储的事件数据可以很方便的进行处理。例如,如果想读取某一天的数据,只需要从一个文件夹中获取数据即可。
- 在 Elasticsearch 中创建基于时间(例如,以小时为单位)的索引。这样,如果试图在 Elasticsearch 中寻找过去一小时中的所有 API 错误,只需要根据单个索引进行查询即可。
- 不要把单个数据马上发送到 Elasticsearch 中,最好成批进行处理。这样可以提高 IO 的效率。
- 根据数据和查询的类型,优化节点数、碎片数以及每个碎片和重复因子的最大尺寸都非常重要。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。
立即免费注册 AWS 账号,获得 12 个月免费套餐:点击注册
有云计算问题?立刻联系 AWS 云计算专家:立即联系

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论