

目前云驱动数据处理和分析呈上升趋势,我们在本文中来分析下,Apache Hadoop 在 2019 年是否还是一个可选方案。
从我第一次使用 Apache Hadoop 生态系统开始,围绕着“大数据”和“机器学习”两个术语,很多事情已经变得很不一样。在本文中,我们来分析下从那之后发生了什么,以及它在 2019 年与高效的托管云服务相比又如何。
历史回顾
Apache Hadoop 是提供“可靠的、可扩展的、分布式计算”的开源框架, 它基于 Google 2003 年发布的白皮书 “MapReduce:针对大数据的简化数据处理”(点击获取),在 2006 问世。接下来,越来越多的工具(如 Yahoo 的 Pig)出现,Hortonworks、Cloudera 和 MapR 主要发行版一直在发布,不断刷新性能数据 (2008/2009),Apache Hive 在 2010 年实现类 SQL 的支持, 像 YARN 这样的资源调器也开始流行(2012/2013)。
大概在 2014/2015 年,Hadoop 有很多其他平台所不具备的优势—开源,突破了基于 Java 的 Map/Reduce 程序的限制,支持 Batch 和 Real-time 应用程序,能运行在所有能找到的旧硬件上,可以在本机运行(我的 2014 Macbook Pro 仍运行有本地 HDFS、YARN 和 Hive 实例 ),也可以在 Hortonworks 的 HDP、Cloudera 的 CDH 或者 MapR 上作为企业级解决方案运行。它使公司能够收集、存储和分析任何数据,并在公司的主要生产环境中被大量使用。
很多其他工具也支持该框架——下面的表格给出了本文会提到的组件列表的基本信息。
可以看出,所有的最新发布都是在最近 6 个月内(从本文时间算起)。
不过任何事物都不可能没有缺点——如大部分开源软件一样,尤其是模块化地运行在几百个甚至成千上万台机器上是一个很大的挑战。配置、性能优化、工具选择、维护、运维和开发都需要有资深专家的指导,来让 Haoop 可以平稳运行,因为一个错误的配置都会严重降低整个系统的性能。同时,这种粒度控制的级别可以和工具的灵活度和适应性级别不匹配。
新兴的云市场

https://xkcd.com/1117/,CC BY-NC 2.5
然而,在过去的十几年中,越来越多的公司从主要的云服务,如 AWS、Google Cloud 和 Microsoft Azure 获利。这有很多好处——如大量减少了本地基础设施和管理的需求,提供灵活扩展的内存( 从几个 GB 到 TB)、存储和 CPU,按使用付费的灵活计价模型,开箱即用的机器学习模型,可以和其他非“大数据”工具进行集成。
公司可以不再维护昂贵的内部裸机柜,它可能一天中有 80%处于空闲状态,而在调度批处理运行时又导致资源受限和瓶颈,这取决于公司拥有的有领域专家或外部支持的工具,它们为大量的作业保留资源,这些作业可以在几秒或几分钟内处理 TB 数量级的数据,仅需花费几美元。
因此问题出现了——从那时起,Hadoop 发生了什么——现在是否还需要它?
生态系统的整体变化情况
在深入到各个组件之前,我们从先简要讨论下发生了什么。
2019 年早期,两大提供商(Hortonworks 和 Cloudera)宣布了两个公司大规模的合并。这次合并对于所有熟悉这项技术的软件工程师来说很有意义——两个公司都工作在几乎一样的技术栈上,都深入到开源软件,都通过便捷的管理和众多可用工具来提供对 Hapoop 栈的支持或托管。Cloudera 侧重于机器学习,而 Hortonwork 侧重于数据获取和聚合,并提供大力协作的可能性。他们在新闻稿中谈到,在过去 12 月有 7.6 亿美元的收益和 5 亿美元的现金,无负债。
这次合并的战略目标是专注于云(有句话是:“云,无处不在”)——不过是基于开源技术的云。公司的目标是如同公有云提供商做到的一样,让用户从 Hadoop 和(F)OSS(见上文)中受益。
这不是新的研发成果——Hortonwork 在 2018 年 7 月的 3.0 发布中已经包含对所有云服务的存储支持(不是严格意义上的 HDFS)。
同时,竞争者 MapR (关注专有解决方案),在2019年5月宣布裁员,并最终在 2019 年 6 月宣布出售公司的意向。该公司在业务模式货币化和大力推动原生云运营方面陷入了挣扎。
在这期间,公有云市场只有一个方向:Skywards。AWS,GCP 和 Azure 的盈利在各自公司的赢利中占很大的比例,看起来,每次新的会议都会展示在各自的技术领域的领先技术,几乎没有公司会依赖于它们的本地数据中心。
IBM仍认为 Hadoop 有价值。
从那以后开源领域发生了什么?
上面的介绍当然不会激发我们的信心,我们还应该看看在过去这些年里到底发生了什么——云服务商从数据获取一直到机器学习和分析都提供了很棒而且易用的产品,同时,(F)OSS 领域也一直在发展。
Hadoop 概述
Hadoop 3.0增加了大量的功能。
YARN 现在支持Docker容器、TensorFlow 的GPU调度、更先进的调度功能,整个平台提供对AWS S3的本地支持。
这些变化让组织可以改变 Hadoop 集群的运行方式,放弃在 YARN 上运行绝大部分批处理作业、分隔本地 ML 作业的传统方法,转而采用更现代化的基于容器的方法,利用 GPU 驱动的机器学习,并把云服务提供商集成到“混合”或原生云模型中。
HBase
Apache HBase 是我既爱又恨的事物之一——它很快,很强大,一旦理解了其基础知识,也很简单,但是一旦规模大了,它也是一头需要驯服的野兽。
建议改为:与 Spark 类似,Hbase 的主要版本也提升到了 2.x,但其变化没有 Hive 等面向终端用户的工具那么明显。HBase (开箱即用)提供基于 Ruby 的 shell 和针对不同语言的 API,它很少作为单独的工具使用——Apache Phoenix是个特别的例外,本文不会涉及。
项目主页提供了2.0.5、2.1.5、2.2.0版本的发布说明,项目的JIRA中也有提供。
这样说可能会让一些人感觉不愉快——Hbase 是一个遵循 UNIX 思想的项目——做一件事并做对它——相对很多其它项目来说,这些年它的改进并不明显。看看相关的工具、库和框架能让你有更好的总体了解。
Google云的BigTable和 Hbase 可以互操作,作为一个原生云托管服务,它可以和现有的所有 HBase 项一起使用。
Hive
Hive 的兼容性通常和Hadoop的版本绑定在一起——Hive 3.x 和 Hadoop 3.x 一起,Hive 2.x 和 Hadoop 2.x 一起,以此类推。
Hive 专注于3.x版本的分支,它从很受局限、运行也不快的 Map-Reduce 驱动的 SQL 层转为低时延、内存内驱动的强大分析框架。
Hive的LLAP(低时延分析处理)技术,在 Hive 2.0 第一次引入,它所提供的功能正如其名一样。它在 YARN 上运行一个守护程序来协调作业的运行,这样小的运行就由守护程序来进行安排,要更多资源的作业就交由成熟的 YARN 作业来完成。这种方式可以进行更快的查询,同时仍可以让用户选择运行很多需要访问大量数据的作业,从而接近大型 RDMBS 集群如 Postgres 所能提供的功能。
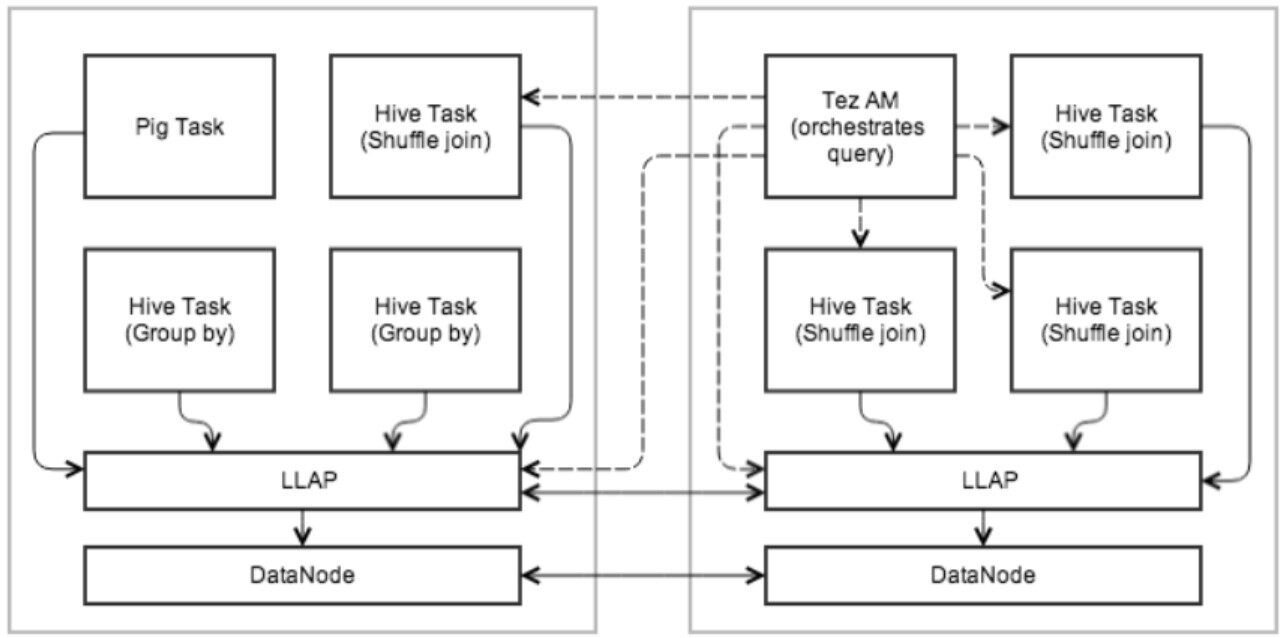
而且,它也完全支持ACID事务,对于 Hive 数据来说,这是一个很好的新功能。 Hive 旧版本依赖于不可变数据,只能使用 INSERT OVERWRITE 或 CTAS 语句来进行数据更新。
ACID 遇到了自身的挑战和限制,它让 Hive 和传统的 RDMBS 或 Google 的 BigQuery (提供有限的更新支持)越来越相似。
Sqoop
Sqoop 是个强大的工具,它允许从不同的 RDMB 种获取数据到 Hadoop。看起来似乎这是个不重要的任务,这项操作通常由 Informatica 或 Pentaho ETL 来完成。
和 HBase 一样,它主要对内部进行改进。可以参考刚刚和 HDP 3.1 一起发布的1.4.7的发布说明。
要特别说明的是,大部分云服务商缺乏比较工具。Sqoop 和数据库进行交互,不管通过增量集成或整个加载,或自定义 SQL 的方式,然后存储数据在 HDFS 上(如果需要,也会存储在 Hive)。这样,从可操作源系统中获取没有经过分析或 ETL 加载的数据就变得直接和简单。事实上,AWS EMR 支持使用 Sqoop 将数据加载到 S3。
这点也存在争议,我很愿意研究其他 FOSS 工具,和存储组件(S3、GCS 等)一样,这些工具能给大型托管的、类似 SQL 的云服务提供类似的功能。
Spark
Apache Spark(现在和 Hadoop 结合的不是很紧密,以后会这样)从版本 1.6x 到2.x,有个主版本的变更,即修改了 API 并引入了很多新的功能。
2.x 和后续的版本针对不同平台提供了更全面的 SQL 支持,大幅提高了 SQL 在 DataFrames/DataSets 上的操作性能(2-10 倍),对底层文件格式(ORC、Parquet)有了更多的支持,2.1 版本提供对 Kafka 的本地支持,2.2 上流数据处理更先进可靠,支持 Kubernetes,更新了 History server,2.3 版本加入了新的数据源 API(如本地读取 CSV 文件),2.4 版本支持机器学习/”深度学习”中先进的执行模式、高级函数等。
Java、Scala、Python 和 R 中可以使用 Spark,从而为有 SME 的组织提供多种流行语言的支持。
而且,Spark 框架从 Hadoop 剥离后,可以用在AWS EMR、Google Cloud Dataproc和 Azure HDInsights上,开发者可以直接把现有的 Spark 应用程序直接迁移到完全托管服务的云上。
这样可以使公司不仅可以重用现有的 IP,还可以对单个的外部服务提供商提供相对的独立性。尽管我在以前发表的文章中曾高度评价过 GCP,这种独立性可以成为一个战略优势。
TEZ
Apache TEZ 允许 Hive 和 PIG 运行 DAGs,而不能运行 M/R 作业。虽然它是一个 Hadoop 专有的组件,仍值得我们深入了解一下。
TEZ 的变更有时是用户会接触到的,如0.9.0版本上的新 TEZ 界面,但大多数还是内部修改,以获取比旧版本更好的性能和可扩展性。它最大的优势在于提供针对 M/R 作业的附加性能和监控能力。
结论是什么呢?
我们花了很长的篇幅来谈论了 Hadoop 的发展和相关的工具。但这意味着什么呢?
有件事很清楚——在数据中心的裸机上运行一个开源技术栈有它的缺点,也有其优点。你拥有自己的数据,自己的技术栈,有能力把代码提交到这个生态系统,来为开源做贡献。你也有能力完成所需的功能,而不必非依赖第三方。
这种相对于云服务提供商的独立性让公司对他们的数据有自主权,这样不用受带宽限制和监管限制(即自有软件,没有“不合规”的问题)。
Hadoop 的新功能和稳定性的提升让平台和工具(还包括所有我们在本文中没有涉及到的)使用越来越方便和强大。ML 领域的发展,尤其是 Spark(ML)和 YARN,为更多逻辑分析、更少的聚合和传统的数据库建模奠定了基础。
云驱动的数据处理和分析稳步上升,Hadoop的关注有所下降,可能会让人觉得这是一个“非黑即白”的状态——要么在云上,要么在本地。
我不赞同这种观点——混合方法可以将这两个领域中最好的东西带给我们。我们可以维护一个本地 Hadoop 实例,将它提交到,比如说一个托管的机器学习服务,如 BigQuery 上的Google Cloud AutoML上, 可以携带部分不含个人验证信息的数据。
我们也可以将现有的 Hadoop 负载迁移到云,如 EMR 或 Dataproc,利用云的可扩展性和成本优势,来开发可在不同云服务上进行移植的软件。
我能看到 Cloudera/Hortonwork 在以后采用的方式和上面第二种方法大致相同——利用 FOSS 的优势,使用公有云服务提供的大量专有技术和高效的解决方案。
在某些情况下,如果没有成熟的、多年的迁移经验,想把遗留系统迁移到云上并不可行——比如有 20 年或 30 年(或更早)历史的管理企业日常运作的数据库系统。不过,结合用户自定义软件和开源软件的优势,根据企业实际情况进行裁剪,是很有价值的。
最后,要看实际情况——Hadoop 当然不会消亡,但是来自 Amazon、Google 和 Microsoft 的持续投资在未来可能会改变。
.
作者介绍:
Christian Hollinger:写过很多大数据、云、分析方法和 UNIX 相关的文章,他是所有数据相关需求的高级顾问,对 Google Clound、Hadoop、Apache Storm、Heron、HBase、Kafka、Spark 等均有了解,对 Kerberos 知之甚少。
原文链接:
https://chollinger.com/blog/a-look-at-apache-hadoop-in-2019/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论