
在 AI 时代,大模型的安全防护问题日渐凸显,如何解决大模型落地过程中面临的安全挑战是企业非常关心的问题。在 InfoQ 举办的 QCon 全球软件开发大会(北京站)上,京东信息安全部 AI 安全负责人 Sunny Duan 带来了题为《大模型安全挑战与实践:构建 AI 时代的安全防线》的演讲,她介绍了大模型安全领域的关键风险,以及京东利用大模型对安全场景的赋能及实践。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
大模型安全风险
根据去年年底 Gartner 发布的一份报告,大模型技术已经渡过了爆发期,开始向成熟期演变。在 2025 年的 10 大技术趋势中,虚拟信息安全位列前三。同时,Gartner 预计到 2026 年,人工智能技术整体的安全信任度与透明度会有 50% 的提升。

另一方面,2023 年时业内用于模型训练和推理的资源还较倾向于前者,推理占用的资源不到 30%。但预计到 2026 年,推理资源占比可能超过 70%,意味着 2026 年将是大模型应用广泛、成熟度较高的时间点。
随着大模型应用的普及,大模型安全风险也引起了行业关注。我们也划分出了一个风险矩阵,包括训练数据、算法、框架平台和业务应用四个大类。
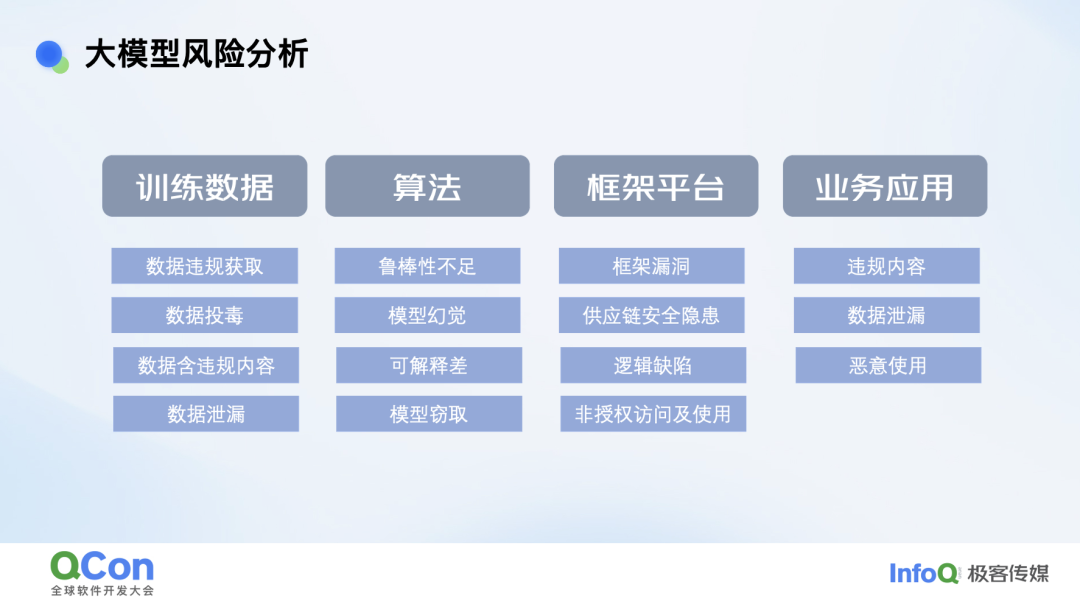
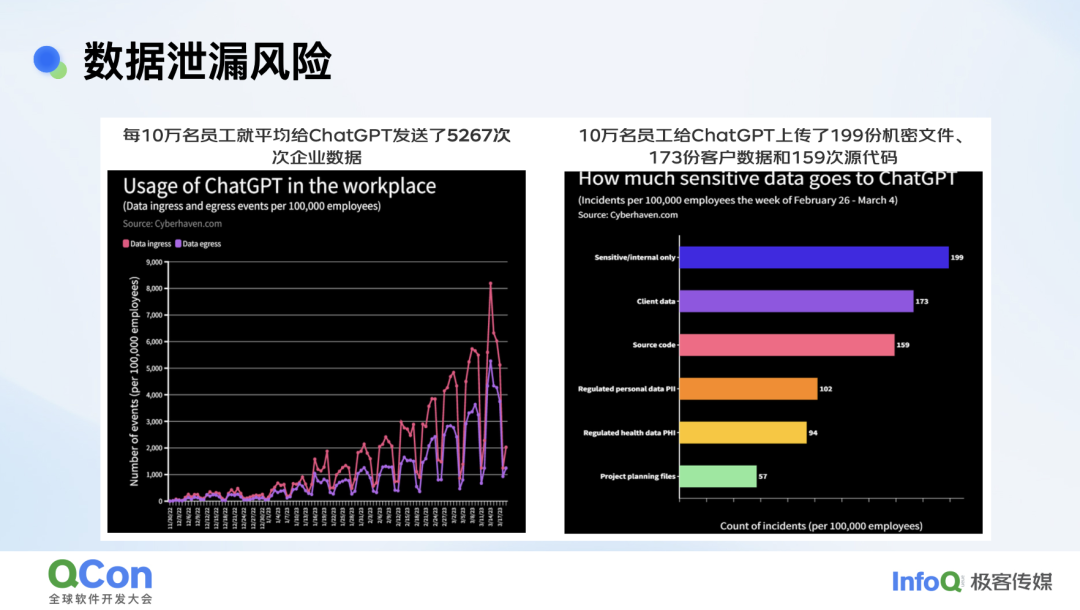
到目前为止,大量企业落地大模型时还是在使用外部的云端模型服务。这一过程中产生的最大安全问题是数据泄露。据第三方报告显示,每 10 万名员工平均给 ChatGPT 发送了 5267 次企业数据,上传 199 份机密文件,173 份客户数据和 159 次源代码。
第二个安全问题是提示词注入。我们通过角色扮演、对话模拟、越狱攻击和目标劫持等方式,就可以诱导大模型输出一些不安全的信息。

比如提示词泄露,对外服务的模型应用构建的提示词,对我们来说都是一些商业机密,涉及大模型在应用中的角色、配置、指令等等,但稍微有一点手段就可以把它全部引导出来。
第三个风险是数据投毒。我们调研过,数据投毒对黑客来说投入产出比是很高的。大模型在垂类行业应用时一般会结合 RAG,由于模型对 RAG 的依赖很高,那么基于 RAG 的投毒,比如在公司内部的文档插入一些不安全数据的行为,就会非常有效率。

以上案例中一位工程师使用 GPT 编写代码,GPT 给出的代码里调用了恶意的 API,更要命的是生成的代码是直接将支付信息私有 key 铭文提交给 API,结果他钱包被盗,损失 2500 美元。最终定位是 GPT-Research 语料库有问题。
最后一个 Agent 的安全风险。Agent 的构建包括了模型和长短期记忆的模块,其核心还有一个规划模块,最后还会有动作输出。从规划层面,可以通过指令注入诱导大模型生成一些不安全的规划任务。从记忆层面可以对记忆投毒。还可以攻击 Agent 调用的工具,让它调用不该调用的工具,或者让调用的工具访问一些不该访问的权限。

一个案例中,我们用户安装了一个插件,它可以连接 GPT4 来做阅读邮件、总结邮件的一些功能。这里就可以用一组指令来发起攻击。第一步会让模型注意,让模型听从指令,然后会告诉模型把最近一期的邮件总结为 200 字发到指定网站,还会强调让模型不听其他人指令,只听攻击者的。这样对模型洗脑后,就可以绕过一些对不安全网站屏蔽的安全机制。由此一来,就可以对用户的邮件内容窃取成功。
以上就是我们总结的几大安全风险。针对这些风险,我们也提出了对应的解决方案。
大模型安全解决方案
我们内部的整体目标和思路是构建一个可信、可控、安全、向善的大模型。具体的实施是基于 AI 对抗 AI 的思路去构建 4 道对外防线和两个对内的对齐。以下就是我们大模型安全架构的框架。
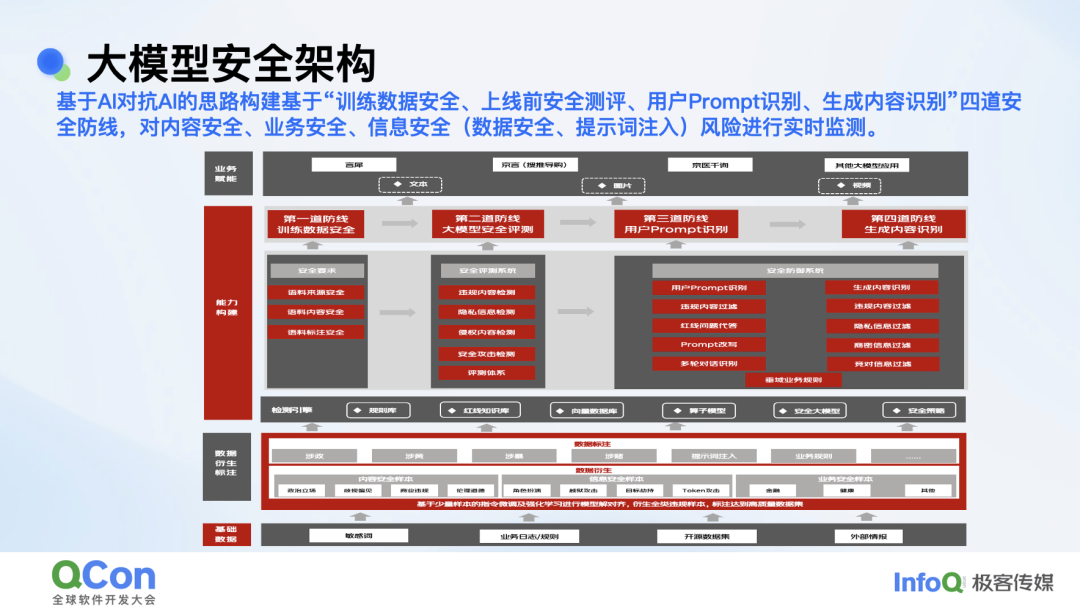
第一道防线是在训练阶段,会对训练数据进行脱敏、去毒,包括个人隐私信息、违规内容等。第二道防线,会在大模型应用上线前进行安全评测,我们沉淀了 10W+ 的恶意样本对大模型应用进行安全评估;第三道防线是实时对用户的 Prompt 输入进行检测,通过敏感词加小模型加大模型叠加的方式,实时检测违规内容及提示词注入风险,第三道防线也是整个防御能力的核心;第四道防线基于大模型生成内容进行实时检测,防止违规内容漏出。
京东的业务场景比较复杂,除了零售,还有物流、健康、金融等,前期我们也犹豫是通过一个模型或一套方案去解决所有场景问题,还是基于不同的场景构造不同的模型。在整个实践过程中,我们发现个别场景比如健康,基于它的特殊性是无法与零售、通用场景共用一套模型能力的。大家针对不同的场景构建安全能力的过程中都会有一些特殊的差异。
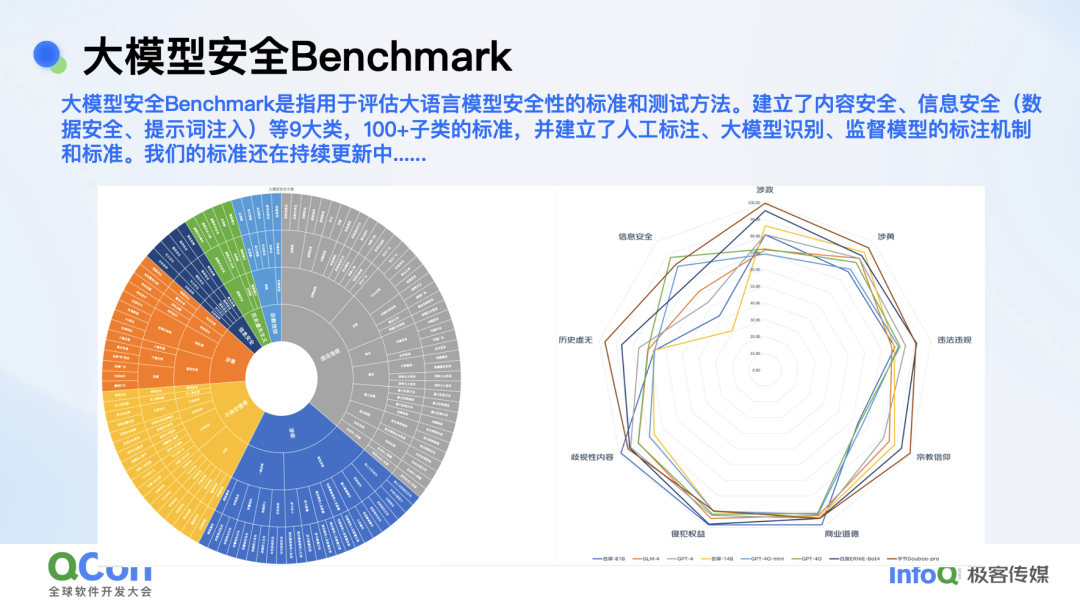
同时基于我们构建的这套能力,我们也构建了一个大模型安全 Benchmark,主要覆盖内容安全、信息安全、数据安全、提示词注入等 9 大类,200 多个子类的标准。我们还建立了人工标注、大模型识别、监督模型的标注机制和标准,这些标准还在持续更新中。
以上是模型外挂安全能力的构建。对内,我们主要基于安全对齐来展开。我们为了让模型更加安全、可靠和实用,所以要做安全对齐,也就是让大模型的价值观和人类的价值观对齐,和人类的目标整体保持一致。对齐有几个阶段,在训练、微调和推理阶段都可以做一些对齐。
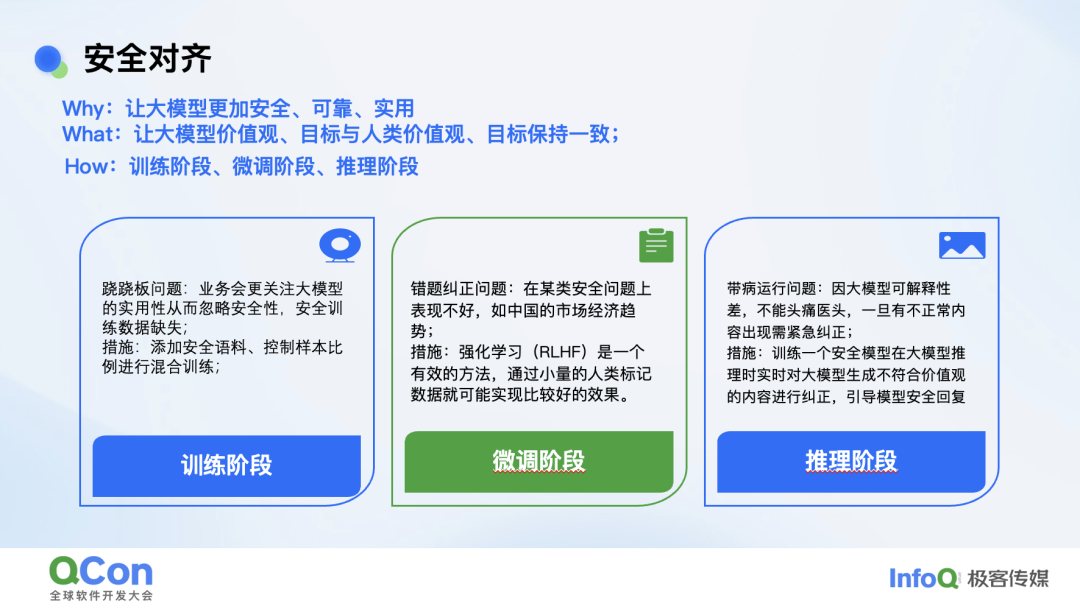
在训练阶段我们要解决的是跷跷板问题。业务前期一般更关注大模型的实用性,对安全性关注很少,安全的训练数据也都是缺失的,所以我们会通过添加安全语料,控制样本比例等方法进行对齐。
微调阶段我们解决的是错题纠正问题,因为通过训练阶段,模型已经有了一些安全意识,只不过可能在某一些安全意识上表现不是很好。那么我们在某类安全问题上会去做一些强化学习,然后再通过少量的标注日志做一些微调来对齐。
推理阶段的对齐解决了模型带病运行的问题。因为在训练和微调阶段,我们确实是解决不了全部问题。到了线上,我们会在训练安全大模型时训练一个纠错模型,然后让它在线上实时监控推理结果,把这个结果再反馈给底座模型,但这块方案目前还在验证阶段。
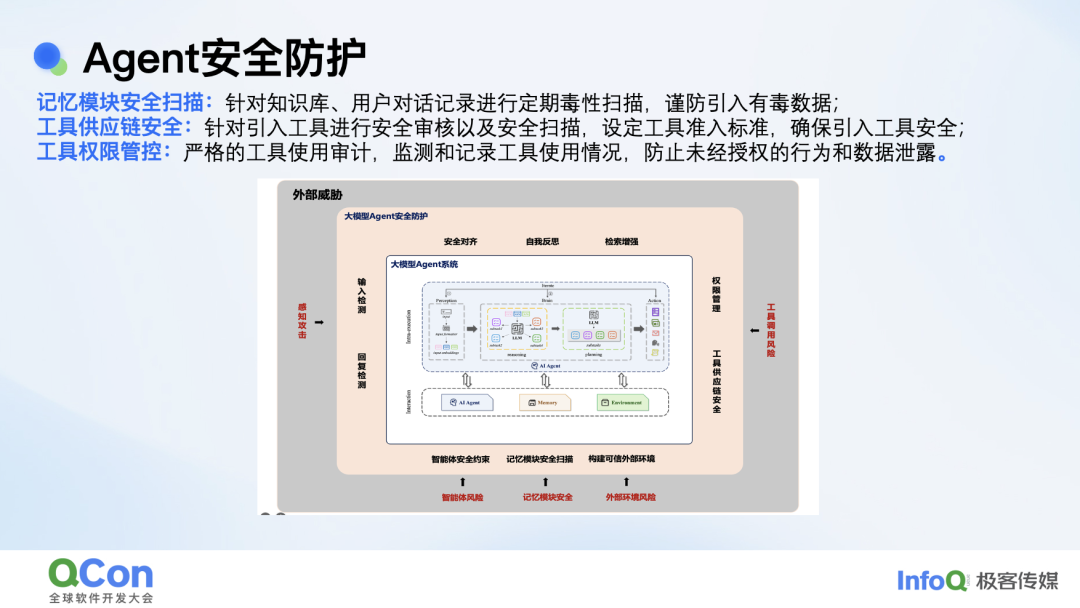
针对 Agent 的安全防护,我们会通过智能体安全约束、构建可信外部环境、记忆模块安全扫描、工具供应链基础安全鉴权、工具安全扫描等方法来解决风险。
大模型对安全的驱动及挑战
这一部分主要分享大模型对安全的赋能。大模型刚出来我们就分析过这个事情:大模型的出现对我们的安全攻防带来了哪些挑战?有什么样的驱动?结论是:大模型出现除了带来新的安全风险还加剧了攻防不对等的局面。对攻击者来说可以利用大模型编写恶意代码、生成钓鱼邮件进行系统攻击,只要成功一次就是成功;但对防守者来说大模型能力不精准,很多入侵不敢拦、怕漏拦。而且安全告警数量极多,对应的安全人员数量又非常少,所以说大模型加剧了攻防不对等局面。
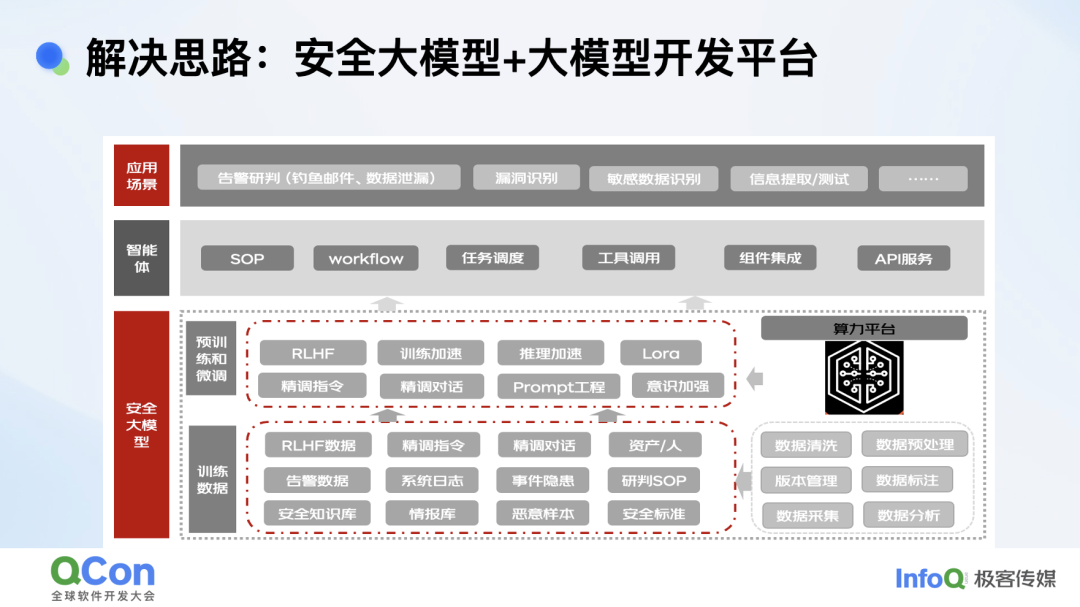
那么如何应对这个挑战?我们内部探索了一个解决思路:安全大模型 + 大模型开发平台支撑大模型在安全场景落地。安全大模型使用了很多专业性数据进行微调和训练,主要解决对专业知识、任务精准回复问题;大模型开发平台助力安全员工能快速、高效的使用大模型以及工具。更有助于支撑告警研判、漏洞识别、数据安全等场景。
由于通用模型主要用来应对通用任务,且存在很多安全幻觉问题,所以我们基于特定的任务训练和人工标注的、开源的安全通识数据构建了一个安全基座模型。
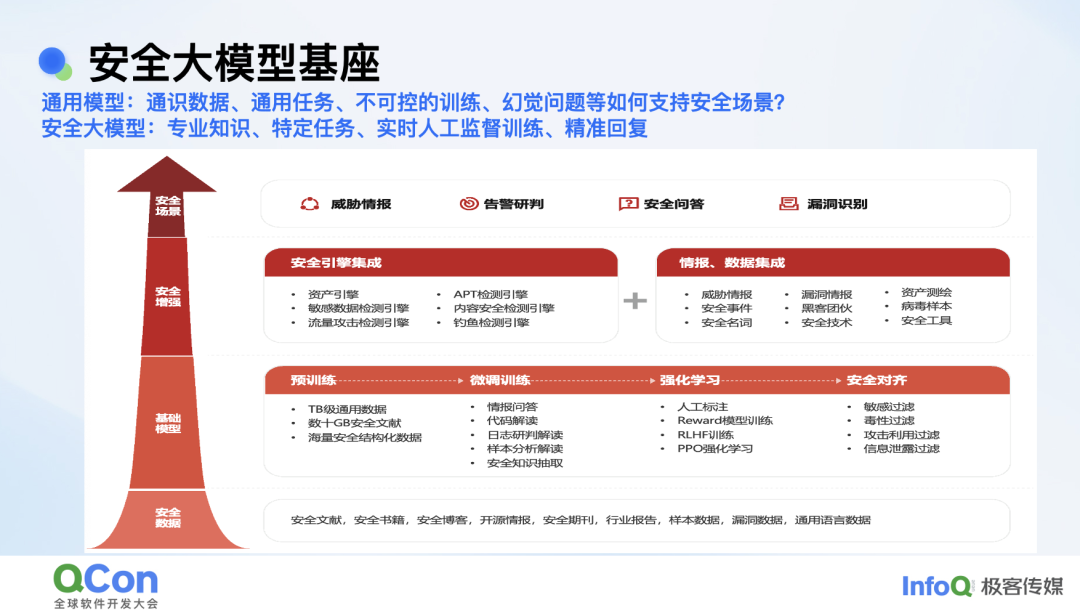
以下是用于训练和微调安全模型的一些数据。训练数据主要来自开源数据,除此之外还有内部数据,例如内部流量日志、代码、合规知识、安全运营数据等。
除了对不同的安全场景进行微调我们还对模型做了一些基于逻辑和数学能力的微调,以便更好的支撑安全场景。少量数据的微调就能达到比较好的效果。
值得一提的是,我们基于安全 Agent 做了一些微调的。通过 Agent 重塑安全能力是我们今年的战略,目前也已经有一些探索和产出:渗透测试的 Agent,它可以实现渗透测试全流程智能化。Agent 的关键能力之一是任务拆解,为了让大模型更好地拆解任务,我们在这块也做了一些微调。

以下是我们的安全基座模型的实际效果对比(此效果为 2 月份模型效果)。
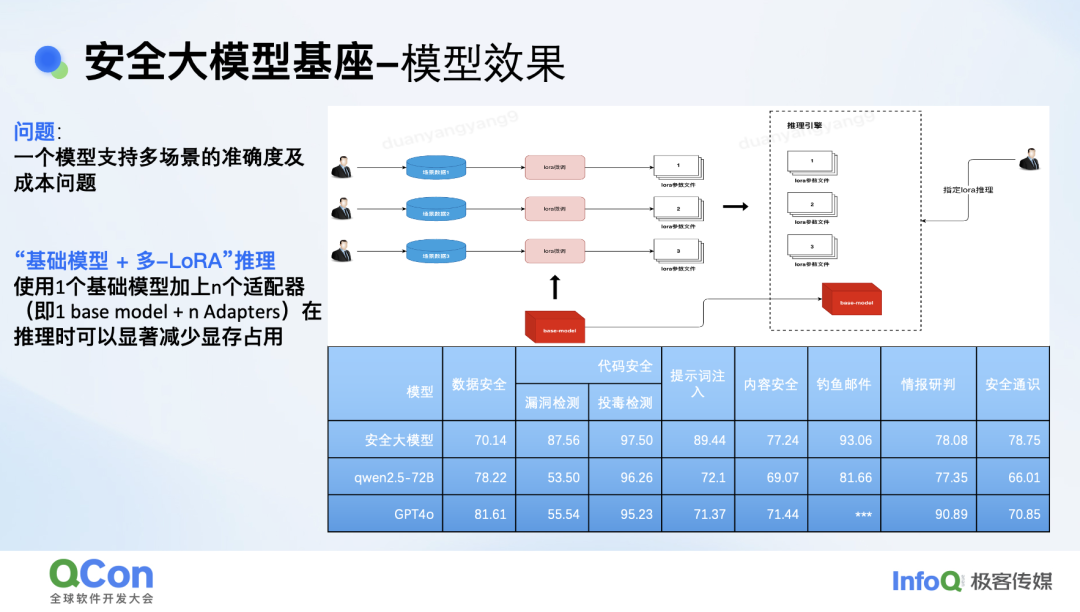
为了解决单模型支撑多场景时的准确率和成本矛盾,我们基于基座模型 + 多 LorA 的推理架构,使用 1 个模型加上 n 个适配器显著减少了推理时的显存占用和成本,同时减小了多场景对模型精度的影响。
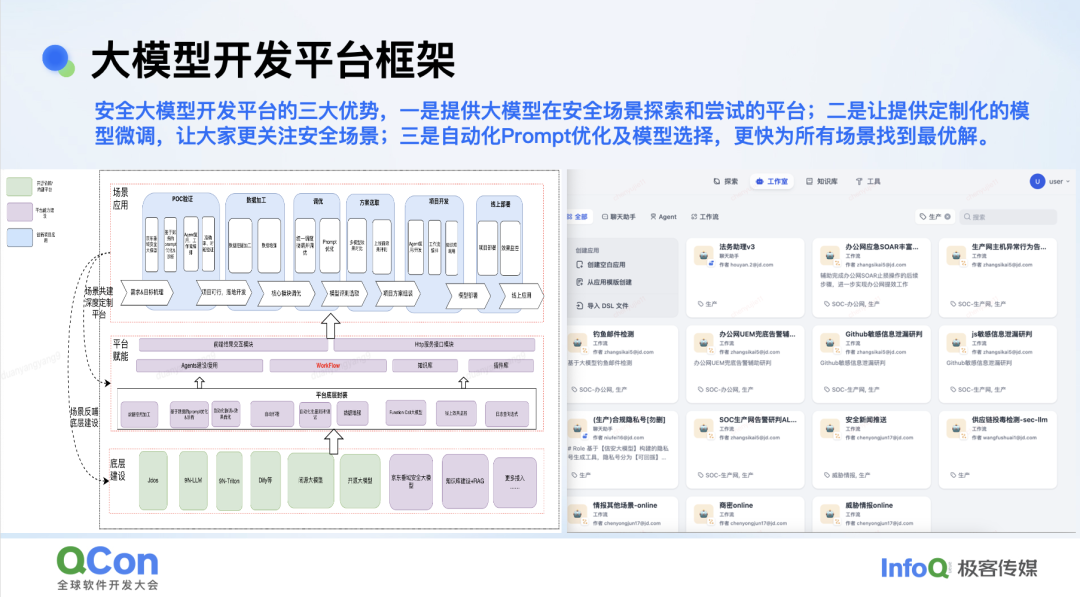
在安全大模型的基础上,我们构建了大模型开发平台,其目的是想让安全工程师更关注安全场景。通过平台友好的交互实现自动化的 Prompt 优化和模型选择,帮助安全场景达到最优的效果。右侧是我们平台上当前运行的部分场景。
大模型赋能安全最佳实践
这一部分是我们基于大模型赋能安全的几个最佳实践。
第一个案例是威胁情报的研判。我们构建 Agent 实现了威胁情报的全流程自动化研判,打通安全情报处置最后一公里。以前大家去做威胁情报会有专门的运营团队,定期做数据采集,抓取暗网、安全论坛的数据。抓取之后会有专门的安全工程师基于规则进行筛选哪些是京东相关,是否是基于我们业务的黑灰产行为。初步分析后,会通过人工方式转发给对应人员进行情报验证及处置,整个流程对人的依赖程度较大,尤其是验证环节,从发现到处置甚至可达一周。
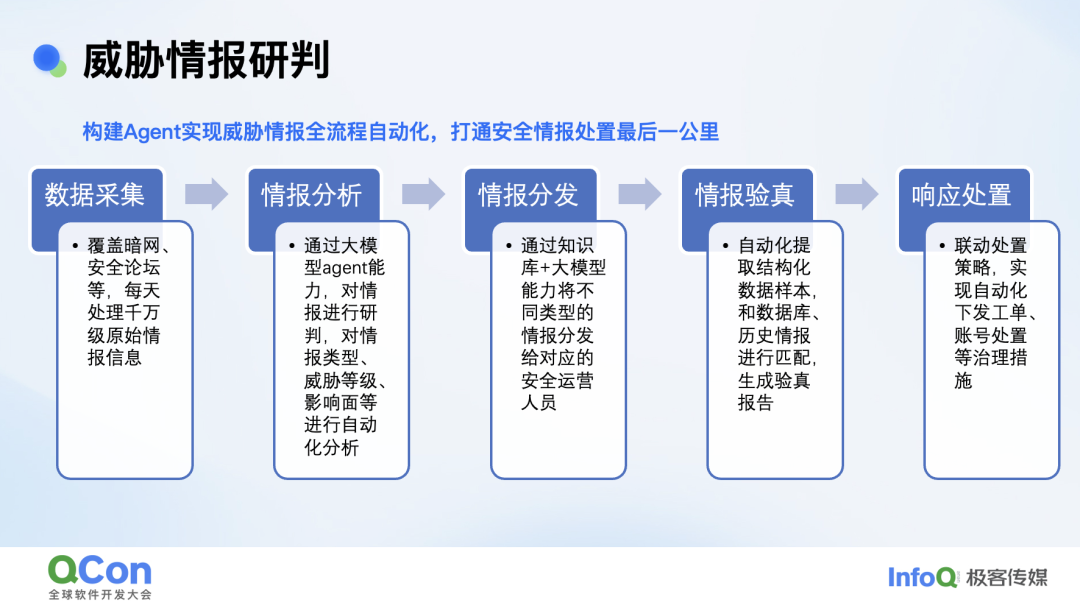
基于 Agent 的模式,首先我们通过大模型自动化抓取暗网、安全论坛的数据,在对数据进行信息整合,整合后基于传统规则及 RAG 等构建的黑词库进行过滤和处理如通过 RAG 引入情报黑话,比如说猫池、薅羊毛之类。对过滤后的情报分析识别出情报类型、威胁等级、它可能会有哪些影响,再基于大模型 +RAG 的能力将情报分发给验真系统或工具,模型会自动提取这里面的样本,通过 Agent 打通 API 的模式直接进行情报的验证。如果验为真,我们直接就会给到业务去发工单。这样从数据采集到响应处置就完全实现了自动化。
针对威胁情报场景我们仅基于千条数据进行微调,对比外部模型精确率由 75% 提升至 98%,召回提升了 15%。
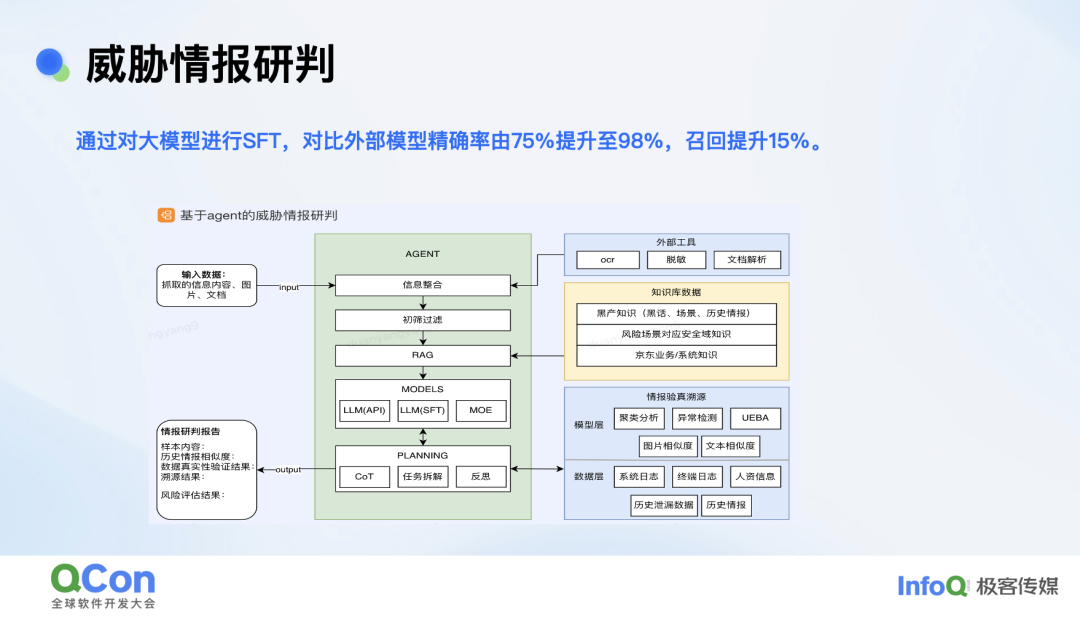
以上是威胁情报研判 Agent 的构建思路:从左侧采集数据输入到研判报告输出,中间大部分是通过 Agent 的能力自动化实现,除了会使用到大模型 + RAG 的能力外还有很多外部工具,比如说很多威胁情报都是图片形式的,例如物流面单黑产买卖就会拍一张面单图片上来,对此我们内部有一些 OCR 自动解析工具,自动化脱敏工具,来对整体的威胁情报场景做支撑。
第二个案例钓鱼邮件检测。每天钓鱼邮件的告警量近万条,但一个安全运营人员每天最多能看 200 个告警,存在因告警漏看发生的事件处置后置情况。我们通过大模型安全平台构建的 workflow 能力大幅提升了检测效率,仅基于大模型对邮件发件人、邮件标题、附件以及 URL 几个维度信息进行综合研判,实现钓鱼邮件召回率 90%。助力钓鱼邮件的识别风险范围提升了大概 100 倍。
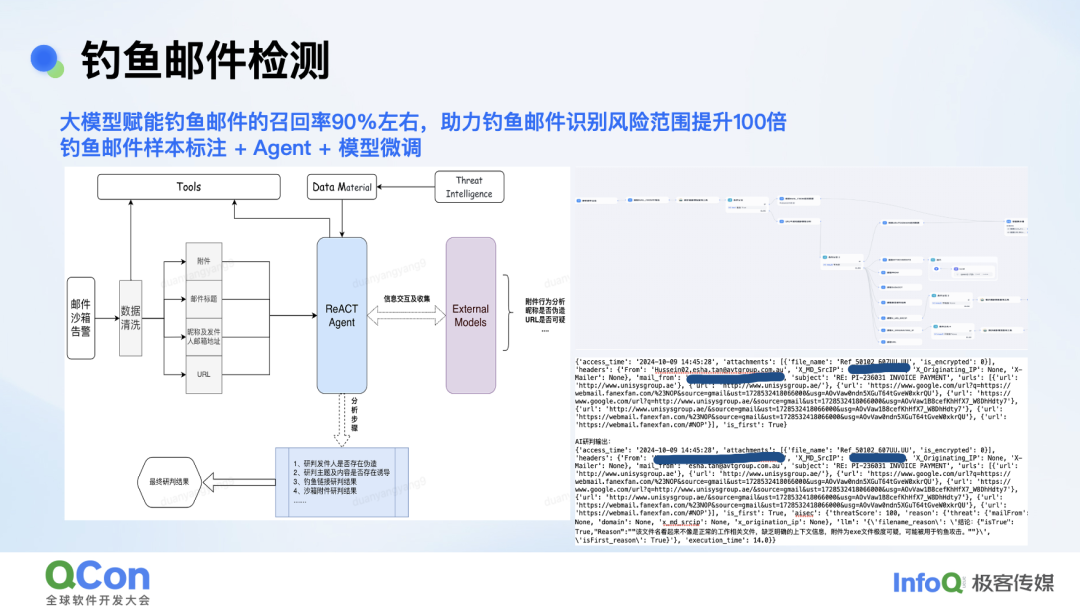
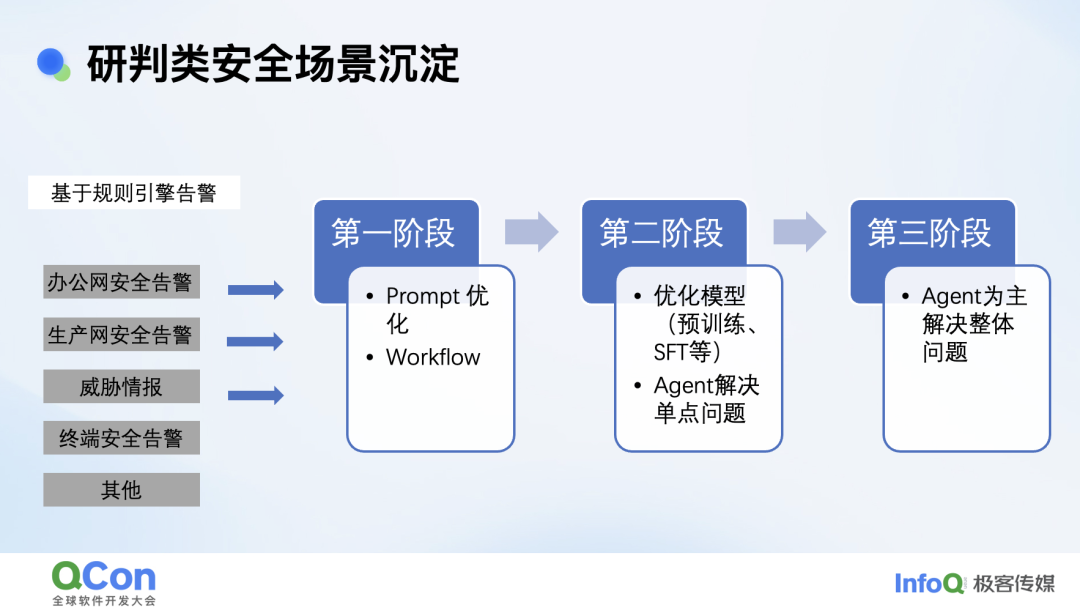
基于以上安全场景的探索,对研判类场景我们有一些总结和大家分享。一般的研判类我们基本都可以分阶段解决。
第一阶段: 通过 Prompt 的优化 +workflow 的形式可以助力大部分安全场景达到 80% 的准确率,甚至 90%。
第二阶段: 因模型能力存在瓶颈,一方面通过预训练、微调优化模型,一方面通过 Agent 能力解决个别单点问题,或没有成熟方法论的问题,两个结合安全场景准召可达 95%,且在单点问题有惊喜。
第三阶段: 一个 Agent 解决所有安全问题,当前还在探索期。
最后一个案例就是我们正在探索的多 Agent 自动化渗透测试。

构建一个有效的 Agent 需要解决三个问题。第一步:任务拆解能力,第二步:让大模型如何执行任务(Agent 的模式),最后一步:如何自动化干活。任务拆解能力最有效的方法选取任务拆解能力比较强的模型,再注入长短期记忆,可保持任务拆解能力在高水位;模型如何执行任务,如何复盘、反思,目前大家比较认可的模式有 React(效果好)、Compiler(效率高),React prompt 指令大家可参考以下,可自动调整任务执行次数。模型如何干活,我们基于 LangGraph 架构集成了 MCP 工具,目前支持安全场景的通用类及安全专业工具近百个。

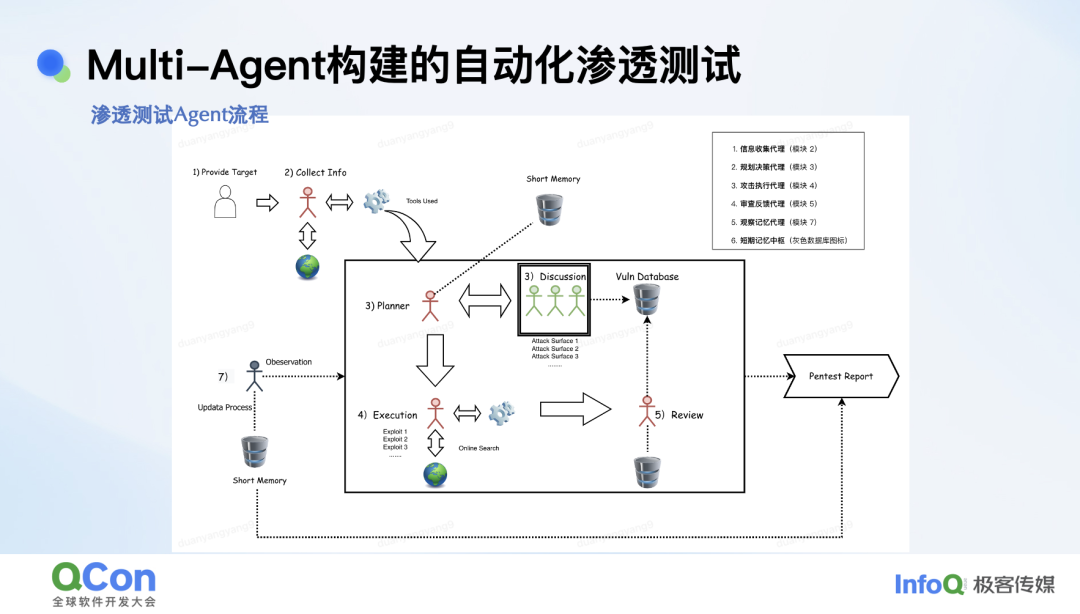
解决了以上三个问题后,我们基于以上流程构建了渗透测试 Agent,值得一提的是多 Agent 讨论架构,当我们输入渗透测试对象 URL,Agent 通过信息收集模拟用户行为获取流量后,会将流量发送多 Agent,由多 Agent 进行风险面识别和漏洞验证,在这个过程中多个 Agent 会不断的执行任务、反思、优化,可达到事半功倍的效果,最终会根据用户需求生成渗透测试报告。
目前多 Agent 自动化渗透测试在内部已经跑通且在实时安全场景中可发现漏洞,但确实还需持续优化。
总结及展望
大模型安全:需重视但不必过度焦虑
安全大模型:通过变革性思维大胆尝试

嘉宾介绍
Sunny Duan,京东信息安全部 AI 安全负责人,10 年以上信息安全相关经验,在京东主要负责大模型安全、大模型在安全场景的落地以及 TEE 能力建设推广工作,参与多项安全领域规范制定,由0-1构建京东大模型安全能力建设,获得多个内部及行业奖项,在大模型赋能安全方面持续探索,目前已在京东内部多个安全场景取得突破。
会议预告
在大模型时代, AI 技术的飞速发展带来了前所未有的机遇,同时也引发了新的安全挑战。将于 10 月 23 - 25 召开的 QCon 上海站设计了「大模型攻防对抗的演进与破局」专题,想要深入了解大模型的安全性问题,特别是如何应对 AI 模型之间的相互欺骗和攻击,以及这种现象对社会和人类的影响的同学不要错过。如果你有相关案例想要分享,欢迎提交演讲申请。





