
郭炜,__ EGO 北京分会会员,2016 年加入易观,担任易观 CTO,构建易观技术团队,完成易观大数据采集、平台、数据挖掘等技术架构与体系,从无到有完成易观混合云搭建、易观 SDK 升级并发布易观秒算实时计算平台。郭炜毕业于北京大学,加入易观之前,曾任联想研究院大数据总监,万达电商数据部总经理,并曾在中金、IBM、Teradata 公司担任大数据方向重要岗位,对大数据前沿领域研究,包括视频、智能 WiFi 等大数据软硬数据处理一体技术有独特的见解。
今天跟大家分享易观大数据架构的变迁,包含三部分,第一先给大家讲易观的变化,也是易观产品技术的结果;第二是从技术角度来讲一下易观大数据技术架构的变迁;第三分享一点创新方向的心得。
(点击放大图像)

在过去,大家谈起易观,首先想到的是分析报告。现在的易观已经跟过去不一样了。我们从底层通过易观的 SDK,采集了大量数据,经过大数据平台的计算,再经过分析师、算法专家做的算法模型,形成了标签,提供给相关的产品,千帆、万像、分析师服务、流量审计、方舟、第四张报表,还有易观零壹学院。
易观的收入,过去主要是由分析师服务和分析报告组成的,去年的产品和技术收入也占到了整体收入的一半。现在的易观,已经是一家以易观系列产品为基础,提供分析师以及第一方数据服务的大数据分析公司。
(点击放大图像)

上图展示了易观的数据资源:累计覆盖 20.7 亿终端,监测 APP 200 多万,上季度末 MAU 为 4.8 亿,每秒处理 55 万条的数据。
易观大数据几乎是从零开始,是不断的随着业务增长起来的。下面给大家分享一些心得。
升级技术架构,先要革新观念,最后才是技术问题

升级技术架构,不仅仅是技术升级
说到升级架构,大家第一个都会想到,是不是对技术升级一下就可以了?
我认为不是,技术架构升级要求的是整个公司的升级。
技术架构的变化,直接映射的就是成本投入的变化。如何让其他合伙人明白你的投入是值得的?比如业务合伙人可能质疑你只花钱没有结果。所以做技术架构变化时,先给公司高管说明白,我们的目标是什么?为什么我们要做?是因为业务规模达到一定量要继续升级,还是要支持原来的产品投入?它将来的投入可能是什么样?我们现在如果不升级,会变成什么样?
这是公司的产品技术一把手应该做的。
升级技术架构,背后是人员变动
第二个,大家都会说,技术架构的变化就是升级一下技术架构呗。
其实不是。升级技术架构背后映射的是人员变动。技术架构在不断升级,有些人会跟不上技术架构的发展。怎样妥善处理这些跟不上的人员?怎样评估他对整个团队的影响?先要把未来架构的人员以及需要的底层资源准备好,再去做技术架构的升级。
技术架构变化,也要考虑节奏问题。技术的使命是什么?是打造特别牛的系统,或者特别打造特别牛的开源项目,让业界都觉得你非常牛,却可能和公司业务没有什么关系?还是要让公司的业务呈现指数级的发展,你能够升级架构支持公司的变化?我认为是后者更重要。
你的节奏有多快,步伐有多大,其实蛮有讲究。每一个做技术的小伙伴,都希望把最新最牛的技术应用到公司。当你在一把手位置的时候,你要考虑人员资源业务是不是真的能够一步到位?究竟要分几步,才能把心目的完美架构落到公司?很可能预算、人员、计划都跟不上,你冲到最前方,却把团队扔下了——这是不可取的。
所以每一个公司步伐迈多大,究竟怎样才去合适,这是每一个公司的 CTO 或者技术产品 VP 心里面要考量的问题。
升级技术架构,最后才是技术问题
技术结构的变化,到最后才是技术问题。我们会看整个架构效率怎样、扩展性如何、将来对 SLA 的影响如何?
到最后一步的技术问题,你是不孤独的,这时候还有总监,还有架构师,还有各种各样的技术人员;而在考虑前三点的时候,作为技术最高管理者,你是孤独的。所以对于每一位技术一把手来讲,我觉得都要明白,升级架构一定不是仅仅技术升级的事情。
下面要讲的就是,易观的整个技术架构是怎么一步步走完升级之路的。我刚刚接触易观是在2015 年,当时整个产品技术业务还没有开展,大家还在探索业务模型。究竟怎样去做整个产品?究竟哪些产品能赚钱?技术应该做成什么样?在整个公司里,大家都不知道。CEO 非常强力的支持产品技术的转型。我也被他打动了,选择加入易观。
易观大数据架构的变迁
2015 年,业务模型探索期

在 2015 年,整个易观架构都在阿里云上。当时就是在探索,有 30 多台虚拟机,用的是 Cloudera Hadoop,然后有一个简单的接收端,就只有一两个合作伙伴的 SDK 会接收上来,然后传输相关的数据。业务量很小,技术架构非常简单,技术人员十来个,大家水平也一般。这个时候公司处在业务模型探索期。
2016 年,业务模型验证期
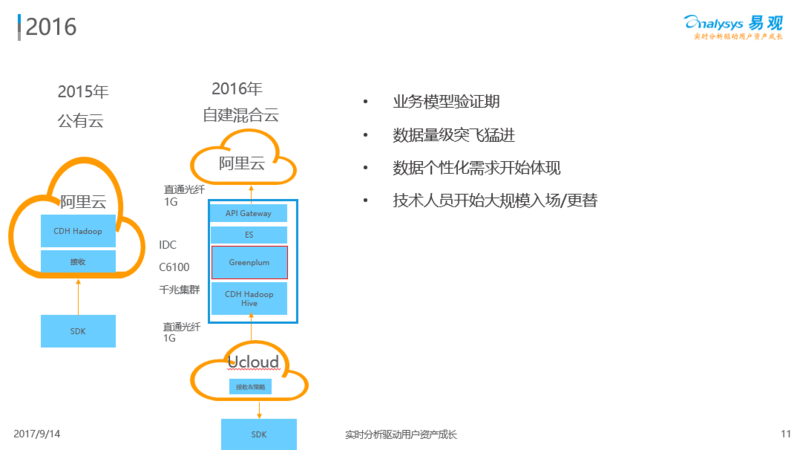
到 2016 年就不一样了。业务模型进入验证期,相关产品正式推出开始对外售卖,也有了收入。同时,易观的业务模型也驱动了合作伙伴的数据接入,数据量大概在 2015 年时间每天不到 10 亿,到 2016 年就接近百亿条了。
2016 年的时候,原来在虚拟机的 Hadoop 运作不能支持那么大的数据量加工,于是我们自建混合云,对外服务还是在阿里云上,底下的数据接收端放到 UCloud。我们自己有 IDC,在 IDC 和两个云用光纤打通,数据从 SDK 到 UCloud,在 UCloud 通过内部项目 KickerAA 打包,打包后传回大数据机房,数据加工后的产品在阿里云展现。
当时我们买了 150 多台二手机群,搭建了大概 1.8 P 的 Hadoop 集群承载我们当时的数据,用的还是 Cloudera Hadoop,主要还是 Hive。
另外,因为数据的个性化需求,我在极客邦的 QCon 大会上也介绍过,面对用户画像标签到用户行为请求的时候,我们引入了 Greenplum。易观是 Greenplum 开源版的最早期使用者之一,也用的不错。现在我们和 Pivotal 的关系也蛮好的,也非常感谢当时他们给我们的很多帮助。相对与 2015 年,我们也加了 ES 这样的简单组件。随着产品越来越多、API 调用越来越乱,我们也基于 Kong 自己推出了 API Gateway,这样就能够知道 API 的调用关系和次数。其中的整个结构是随着技术团队的更新逐步建立起来。这是 2016 年的情况。
2017 年,业务突飞猛进
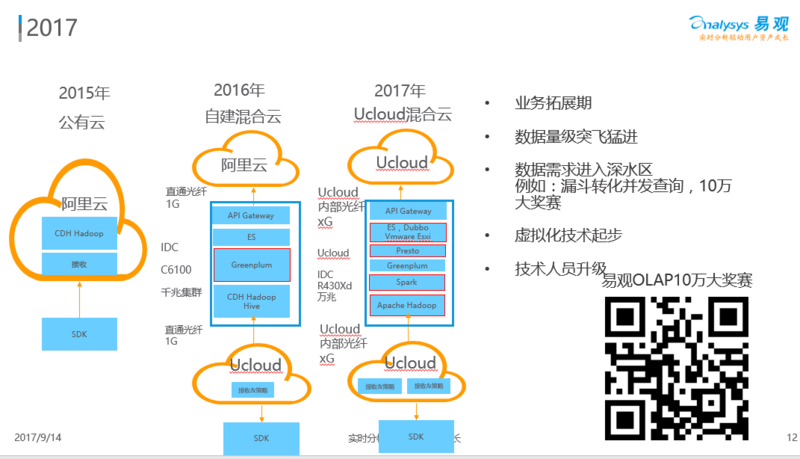
原来的服务会有光纤被挖断的问题,我们在 2017 年全部切入 UCloud 混合云,大数据集群也全部用高端的 R430XD 的机器,也引入了新的架构变化。
随着人员增加,我们引入了 Spark,继续保留 Greenplum。我们有一些更复杂的查询,而我们对 Scala 还跟不上速度,所以引入 Facebook 的开源组件 Presto。基于 Presto,我们做了产品查询,这些在后面会重写。同时应用架构也用了 Dubbo。这是 2017 年的变化。
2017 年我们业务突飞猛进,效果不错。现在大家都知道易观千帆能够去查排行榜,查所有 APP 的活跃情况。我们的数据量级也突飞猛进,我们过去的接收带宽从几百兆到 1 G 到现在的几个 G ,日活接近一个亿,数据需求也进入了深水区。我们最近做了悬赏 10 万块钱的开源大奖赛。大家都有有序漏斗查询的方案,我们的方案我觉得是 60 分,还不够好,已经给大家开源了。最好的商业产品能做到 90 分了。为了鼓励开源小伙伴,我们设立了 10 万元奖金,欢迎感兴趣的小伙伴扫描二维码参赛。
从虚拟化来讲,我们的技术也是逐步进步,技术人员也是随着架构在不断升级。
我们在 2016 年的时候就在长沙开始做研发中心,2017 年的时候,我们的研发一半在长沙,一半在北京。
2018 年,拥抱变化
放眼未来,2018 年到 2019 年,我还会做一些新的变化。
- 2017 年全部基于 UCloud 是有单点问题的,明年我可能会加上备份和多点接收方案。
- Presto 工具有各种各样的问题,我们的技术栈也特别长,我会浓缩技术栈,以后全部都基于 Spark。
- 明年会对 Spark 和 Scala 增强人员投入,今年我们也找到了阿里的小伙伴来加盟一起做。
- 明年我会把 VMware 这套东西全部废掉,转型到 Docker。随之我们会把 Dubbo 直接并到 Spring Cloud 架构里面,花一年时间把整个技术栈从各种各样的开源组件逐步收缩。以上是 2018 年的。
- 2019 年我们开始做双活,把 Hadoop 和 Spark 做 Docker 化。
一路走来,必须要很稳健。保证在人员投入和其他投入是线性增长的情况下,满足指数增长的收益和指数增长的需求,不能为了技术而技术,在整个布局和战略上都必须遵从公司战略,这是每一个公司 CTO 都面临的挑战。
(点击放大图像)

易观的大数据平台架构简单来看如图中所示:
- 底下是各种各样的云端数据接受策略和数据接收组件。
- 中间有一些分布式的数据流转平台、实时队列和分布式组件。再往上是提到的平台,加载了通用查询引擎,这样产品调用就不用那么痛苦了。实时这边也有 Spark 和 Storm。
- 除了分布式查询实时处理之外,还有一个调度资源管理工具叫 EAMP ,他其实是主要负责所有任务的调度、分布式资源管理和数据监控,包括批量作业的触发,包括我们现在的服务是不是有问题并发的。在数据治理服务方面也做了一些东西,像元数据的管理、数据口径的管理、数据质量的检测、数据的鉴权和审计,这个其实都是在数据治理服务的模块里面。
- 再往上是我们刚才提到的数据发布平台,也就是我们的 API Gateway,它能够调用封装好的 API,同时能够看到请求情况和次数。
- 顶层就是对外的各种服务了。
这就是易观整个的大数据平台架构。
不解释,最终要让事情发生
最后分享一个心得,其实就是这一句话:不解释,最终要让事情发生。你的决策受到各种各样资源的限制,你可以找一万个理由用来解释,用这一万个理由去不做事情。然而,作为技术和产品一把手,你不能解释,只能让事情去发生。
这也是我从总监到 CTO 的转变。CTO 找总监希望找能扛事儿的,而 CEO 找 CTO 希望找到能成事儿的。扛事儿和成事儿是两个不同的境界。大家将来成为技术产品一把手的时候,把这句话记在心里:不解释,最终要让事情发生。
(点击放大图像)

到最后,易观沉积了非常大规模的数据,现在我们有 20 多亿的用户画像,月活接近5 亿,各种各样的标签都有。我们现在抱着开放的心态,拥抱各种各样的合作伙伴。
欢迎感兴趣的小伙伴一起交流,线上线下都欢迎。我自己是很热心肠的,知无不言言无不尽,所以大家都叫我郭大侠。
今天的分享内容就是这些。谢谢大家。
问答
**1. 加入 EGO **至今,有哪些收获和感想?
每个公司,每个技术的管理者其实都是孤独的,有太多的问题需要独自承担。 EGO 是一个非常开放的大家庭,给这些技术管理人员一个平台可以交流各自的问题,有非常多的热心高等级的管理人员来帮忙解决,让大家少走弯路。我在其中遇到很多相恨见晚或是惺惺相惜的技术大咖。这是一个给技术管理人员的交流的平台,不仅可以解决独自难以解决的技术问题,也可以相互借力加速公司的业务发展。非常荣幸与开心可以加入 EGO 大家庭。
2. 是否考虑采购或外包一些算法类的工作?
我的回答是当然考虑。我们有一个原则,对所有业务问题都会问三个问题:
- 第一个问题是,能不能用技术化的自动化的手段解决?如果可以的话,我们就去研发。
- 第二个问题是,能不能采用外部专家和外包方式解决,而不动用我们的资源?因为有这种思维,我们才能保证易观一直是“最小的大公司”,最少的人可以做非常多的事情。
- 第三,前面这些都不行的时候,我们再考虑招人。我们现在 192 人维护这么庞大的体系,我们有很多合作伙伴和专家,我们非常欢迎这些方面的专家来洽谈业务。
3. 如何面对大公司的人才争夺?
要时刻面临大公司的人才抢夺,这对于小厂来说的确是很不容易的。我觉得大厂有大厂的好处,小厂有小厂的妙处。
大厂的数据分析都是后台业务,小厂就不一样,比如易观是依赖数据分析和数据产品存活的,我们在数据这一块的力度和产品迭代速度是由整个市场来推动的。人才在大厂的成长速度一定不如在小厂快,在小厂天天面对生死存亡,不把这东西做起来,客户就不买单;不把这个问题解决的话,这么大的并发数据量可能就会形成很大的技术事故。
所以我们在和大厂去 PK 人才争夺的时候,我们主要是看人才是不是真的想在这里做的专深。我觉得,面对大厂和小厂的人才争夺,人各有志,要看每个人自己的想法是怎么样。要给年轻的小伙子机会,要给中层带人的机会,用不同的策略来面对人才争夺。
4. 团队内有比你技术更牛的专家没有?如何管理他们?
团队里面当然要有比我牛的技术专家。我觉得,一个 CTO 是不是合格,就是看他能不能找到比他更牛的人。我觉得,对于牛人不能叫管理,而是看他有什么需求,然后指引他的需求和公司战略方向保持一致,他能发挥出来的价值远超过你自己一个人能够去做的事情。
我经常讲,一个牛人只能是做 × 1 的事情,一个 Leader 带领 10 个牛人那就是做 × 10 的事情。作为 CTO,你应该找 10 个 × 10 的人,那就是 × 100 的效果。
我希望团队里面每一个方向都有比我更牛的人,这样我才能放心地做想做的事情。否则我每天要做 X 1 的事情——我不是不能做,我刚加入易观的时候都在写代码——我如果每天都去写代码的话,谁去做 × 100 的事情?
5. 非巨头公司如何平衡业务/生存问题和长远技术储备问题?
中小型公司平衡业务和生存,我觉得这个真的是一个艺术的问题,很难用一句话来解决。每一个公司都不一样,每一个管理者的风格也不一样,每一个 CEO 对技术和产品的期望和投入也不一样。所以做平衡的时候,关键在于对整个公司的战略有比较深刻的了解,对公司其他合伙人和 CEO 对公司的战略布局比较清楚,你心里对整个技术架构都很清楚。
你要选择适合当前的结构和人员,为马上面临的,比如三到六个月会遇到的技术问题,开始做储备。如果你人够多,可以做一年左右的技术问题人才储备。人更多的话,可以做更长期的储备。不要一步到位,别想直接支持未来五年的业务发展。我估计这样不论是产品和技术,都很难成功吧。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论