

导读:随着语音交互技术的发展,对话系统已经越来越成熟。对话系统的最新进展绝大多数是由深度学习技术所贡献的,深度学习技术可以通过利用大规模数据来学习有意义的特征表示和回复生成策略,并有助于提升用户的对话体验。今天和大家分享的是 360 人工智能研究院主导的语音交互技术在 360 的落地实践,目前已在 360 智能音箱、360 儿童手表、360 安全卫士等产品上得到了深度应用。
本次分享的主要内容包括:
对话系统的基础知识
360 智能语音交互平台介绍
对话核心技术:语义理解、对话管理、QA
对话系统的基础知识
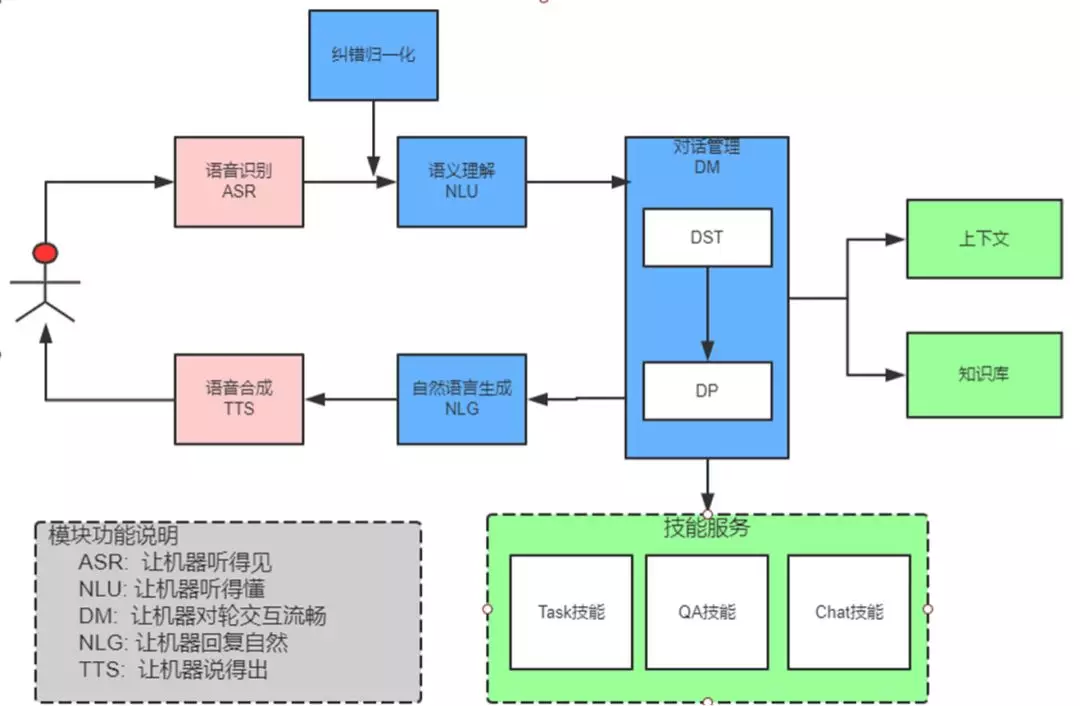
上图是目前常见的对话系统的框架,当用户和机器人聊天时,首先要让机器人能够"听懂"用户说的话,通过 ASR ( Automatic Speech Recognition,语音识别 ) 技术将声音信号转成文字,接着使用 NLU ( Natural Language Understanding,自然语言理解 ) 技术让机器人明白用户表达的意思。紧接着,NLU 模块输出处理后的信息,并传入 DM ( Dialog Manager,对话管理 ) 模块,通过引入对话上下文和知识库等方式,进行对话决策,确定使用一个策略或技能。再将结果合成文字并以声音信号的形式输出,这里主要采用 NLG ( Natural Language Generating,自然语言合成 ) 和 TTS ( Text To Speech,语音合成 ) 技术。
对话系统分类:
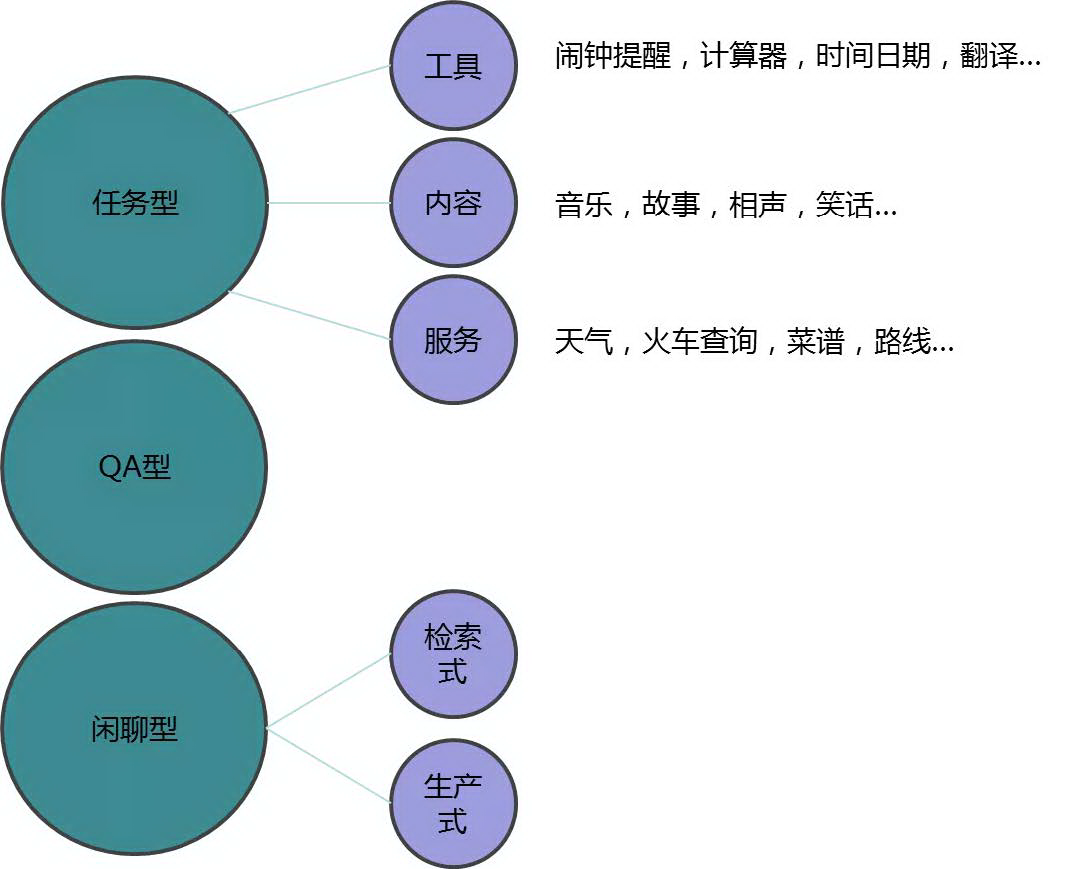
根据具体应用来划分,目前常见的对话系统可分为任务型、QA 型、闲聊型三种。任务型对话系统是为了解决特定的任务,如设定闹钟、订机票等。QA 型的对话系统主要用来解决信息检索的需求,回答用户的问题,通常在客服场景中使用比较广泛。闲聊性对话系统没有特定的规则,只要能一直和用户聊下去就好。
360 智能语音交互平台
智能对话系统这种产品的实现一般有两种方式:一种是基于业务导向的,比如要实现智能音箱与用户的对话系统,需要针对智能音箱这个场景进行代码的实现;另一种是平台化的思路,即实现一个更大的对话系统平台,将业务逻辑与核心对话引擎解耦。我们平台化的优势很明显,包括创建技能可以流水线化,利于分工合作、架构稳定容易扩展、迁移性好等特点,可以快速支持多个产品线的业务。目前 360 智能语音交互平台已经内置了 82 个技能,在 360 智能音箱、360 儿童手表、360 安全卫士等业务上均有广泛的应用。
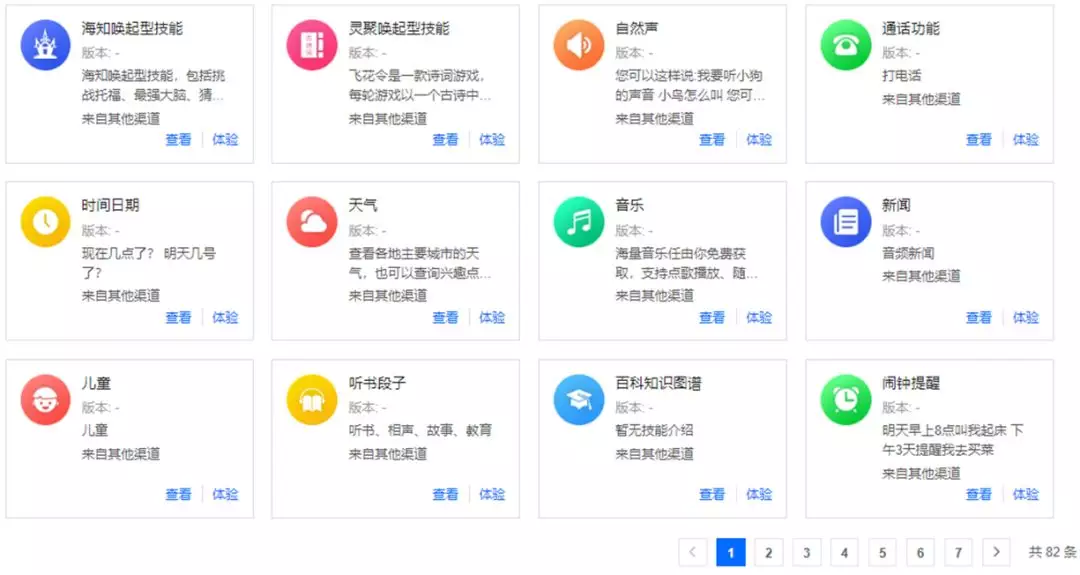
当平台建好之后,新技能的扩展就会变得很方便,一般一个新技能只需要一周就能实现,复杂的新技能也能在两周左右打造完成。
目前我们的业务架构如下:
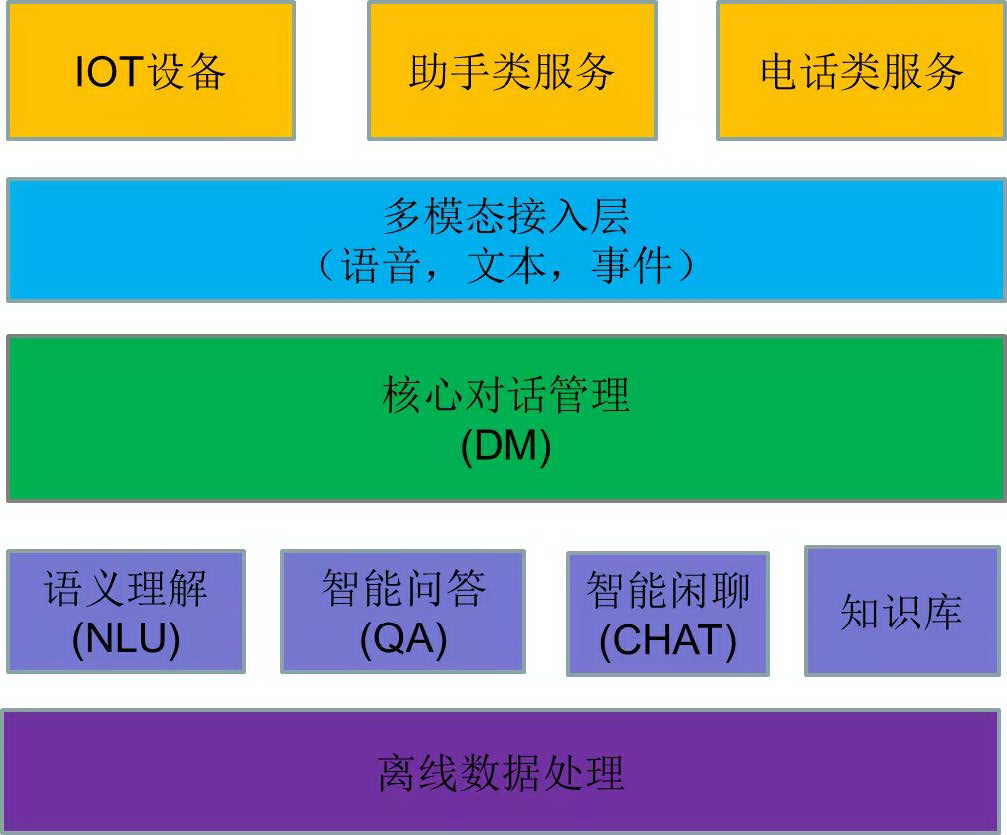
这里我们的主要创新在于"多模态接入层"中"事件"的引入。例如,如果我们支持一个智能摄像机的需求,看到一个人后判断有没有戴口罩,若没有则进行相应的提示;那么我们只要连通摄像机,根据事件触发系统对应的处理模块,监测"人没有戴口罩"这个事件有没有发生。引入"事件"后,我们系统不仅能处理自然语言,还可以处理多种多样的信息。只有系统有了"事件"的概念,我们才能说这一系统是多模态的。
对话核心技术
接下来主要介绍自然语言对话的核心技术,包括语义理解、对话管理和 QA。
1. 对话核心技术-语义理解
在对话系统中,task 型语义理解主要是将自然语言转换为"领域 ( domain )、意图 ( intent )、信息槽 ( slots )"三要素,将自然语言转换为结构化信息。这个功能直接影响后续处理,因此在对话系统中的地位非常重要。
举个例子,用户说"给我放一首周杰伦的东风破",NLU 模块应解析出领域是音乐、用户意图是播放音乐,信息槽为{“singer”: 周杰伦,“song”:东风破},即:

于是我们可以将这些信息可以传入后面的对话管理模块,由 DM 来决策出系统的反馈是做什么事情。
目前学术界对语义理解有很多方案,理想情况是采用一个模型去解决一个端到端的问题,但现实比较骨感,目前的语义理解模块并不能达到这一点。冷启动问题也很困难,我们初期并没有足够数据去训出一个理想的模型。
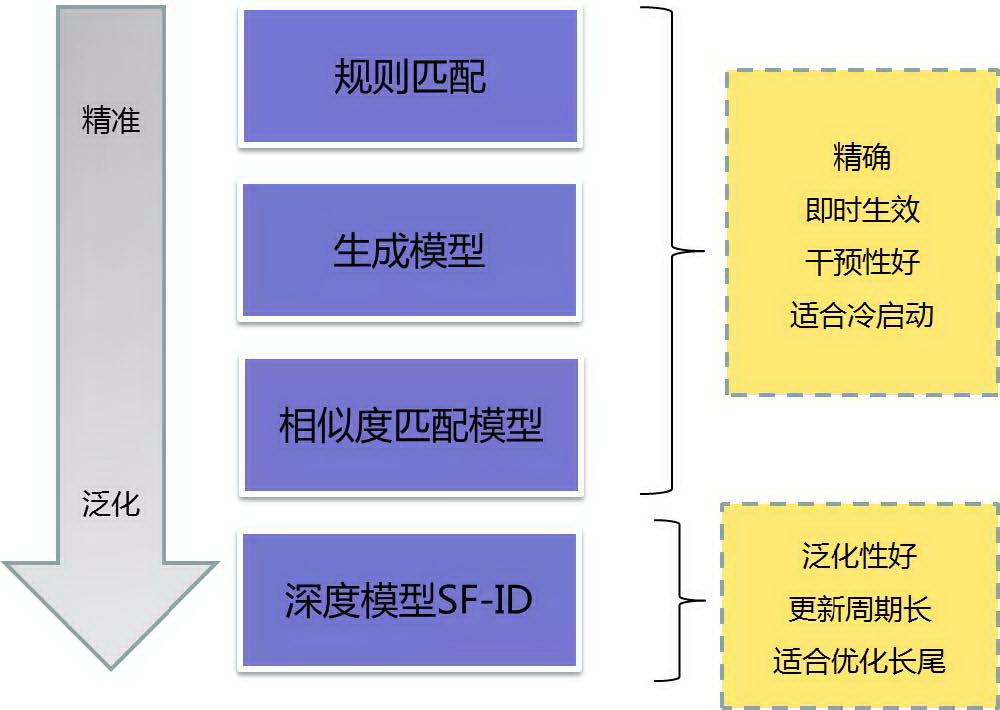
针对这些问题,我们做了以下方案:
规则匹配,也就是精确匹配,可以解决 top query,规则匹配没有泛化能力。
生成模型,基于规则匹配的泛化 ( 请注意这里生成模型是内部说法,并不是"生成式模型 ( Generative Model )"的概念 )。
相似度匹配模型,主要应用在没有槽位 ( slots ) 的语义理解,如用户说"我要听歌",我们可以找到相似的 Query,根据相似 Query 的反馈回复用户。
深度模型,我们做了 SF-ID ( Slot Filling and Intent Detection ) 联合学习的方案。
规则匹配和相似度匹配的方案大家都比较熟悉,这一节我们主要分享生成模型和深度模型。
① 语义理解-生成模型
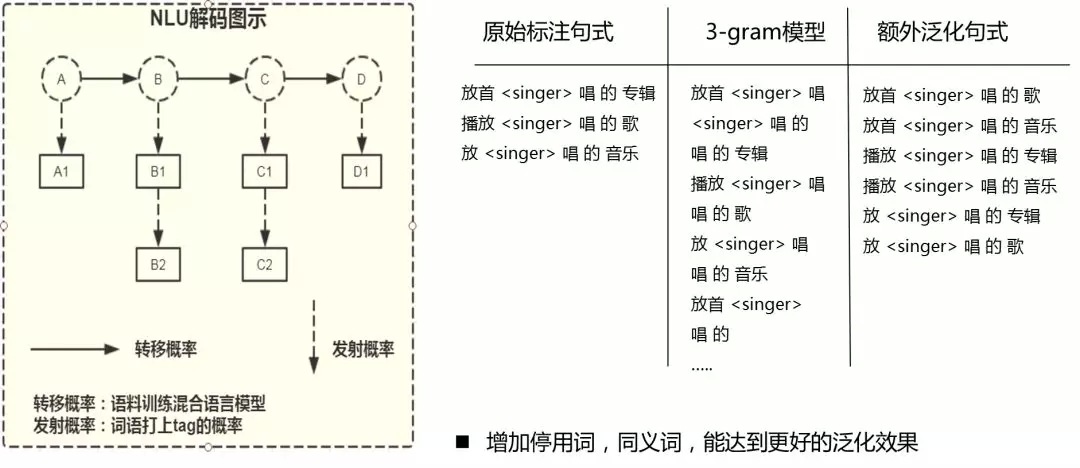
我们的生成模型是基于匹配模型的泛化,是完整精确匹配与片段式匹配的区别,类似隐马尔可夫模型,我们可以用转移序列和发射序列进行匹配。例如下图中,我们的标注人员只标注了 3 种句式,直接匹配只能匹配这三种说法。我们增加了 3-gram 模型进行匹配,将原始序列拆成三元片段,在这个基础上通过 beam search 进行解码,这样像例子中的 3 条语料,在实际匹配中可以额外泛化出 6 种句式,达到了很好的效果。
这里还可以加上三元回退、二元回退、停用词、同义词等,还可以把泛化效果做的更好。
② 语义理解-深度模型 SF-ID
业界通用型的 NLU 一般会先过意图识别模型,再将识别出的意图传给槽位识别模型进行判断。整个 Pipeline 如下:
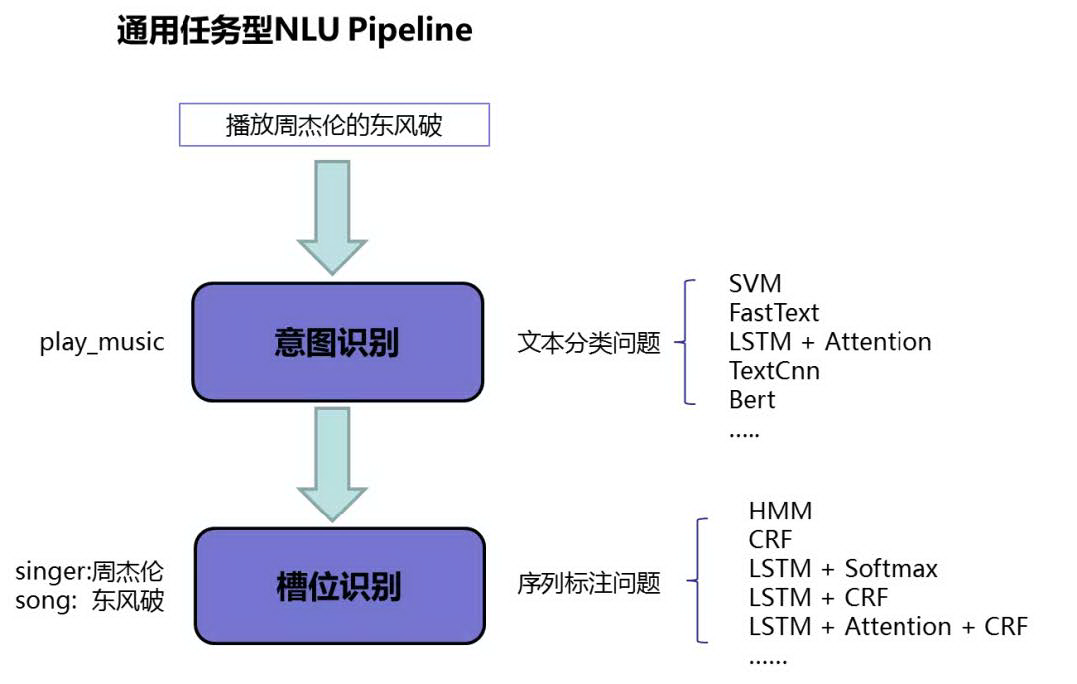
经过我们的技术分析和业务反馈,这样的流程有以下问题:
误差传递。即意图识别模型判断错误,会影响槽位识别的效果
没有引入外部知识。如"播放忘情水"的意图应该是 play_music,而"播放白雪公主"的意图应该是 play_story
OOV 问题。如用户说"播放你的酒馆打了烊",真实意图是"播放你的酒馆对我打了烊",用户说错的时候没有办法解决
我们的槽位-意图识别 ( Slot Filling – Intent Detection ) 的方案有一个演进过程,针对这些问题我们的方案如下:
首先是误差传递问题,这个问题的解法,我们有两个阶段。最开始我们的模型是 LSTM-CRF,针对它效果不好的问题,我们首先加了 Attention,并且 Softmax 和 CRF 可以互换调整。第一个比较大的提升是采用联合训练的方式,也就是 Slot Gated Modeling 这篇论文[1]的方案。
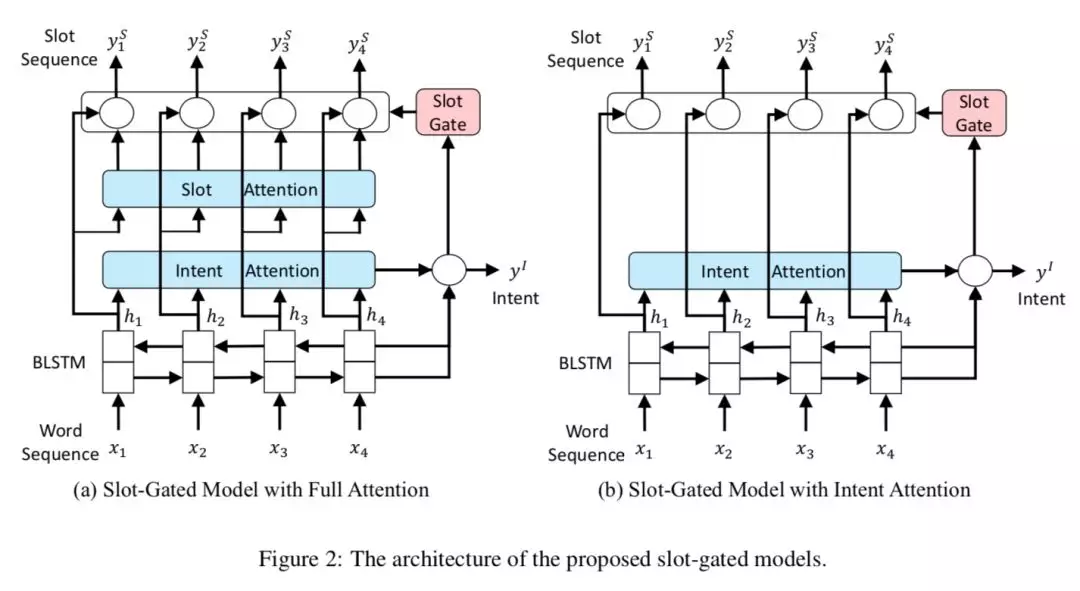
这个方案引入了 slot gate,模型在预测公式上引入了 intent 影响,论文里用的标注模型是 Softmax,但我们换 CRF 后效果会更好。有些情况 Softmax 标注的序列中,I 标注会在 B 前面 ( ps:这个是序列标注问题的标注类型,B:Begin,I:Inside,O:outside,即序列的开始、中间、结束 ),但 CRF 不会将 I 标注在 B 前面。这个可能是因为 Softmax 更专注于局部信息,但 CRF 是对全局的概率转移进行了建模。
接下来,我们又更新到了 SF-ID 模型。比较巧的是这个方案的作者当时在我们组工作,也就把这个思路带来了,后来论文[2]被 ACL 2019 发表了。这个方案和 slot gate 方案的主要区别是,slot gate 方案中只有 intent 影响 slot,slot 的结果不能对 intent 起作用,还是有误差传递的情况;新方案的 SF-ID 是两个子网络,两个子网络互相迭代训练,两个子网络互相传递信息迭代,这样就把 intent 对 slot 的单向影响变成了 intent 和 slot 互相影响。大家若有兴趣,欢迎看一下参考文献中第二篇论文。
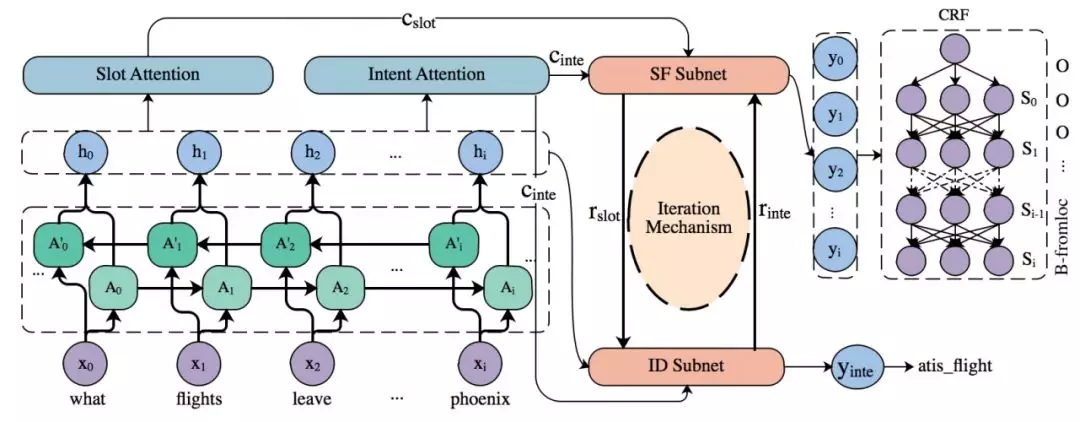
基于联合训练 SF-ID 两任务的思想,我们基本在模型层面解决了误差传递的问题。
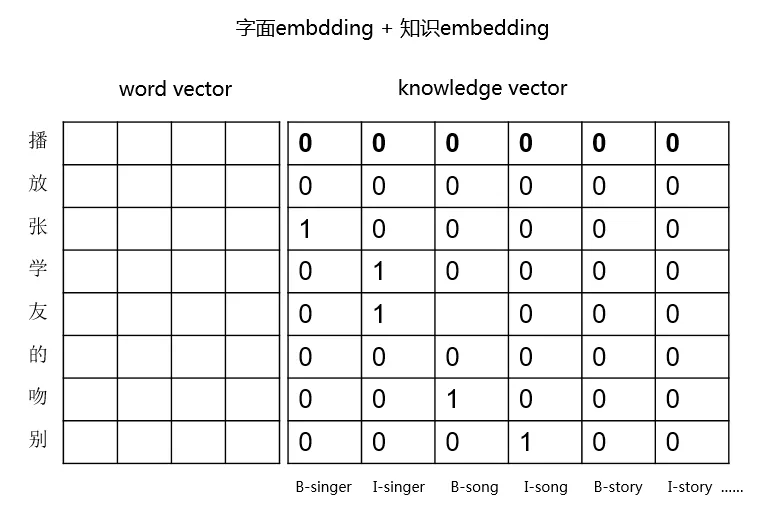
接下来我们讨论一下外部知识的引入。我们的经验是没有外部知识 ( 输入层增加 knowledge vector ),模型效果并不好。但引入外部知识之后,准确率马上提高了 15%。
举个例子,用户说"播放张学友的吻别",我们通过外部知识可以打上标签 ( 张学友:张:B-singer、学:I-singer、友:I-singer;吻别:吻:B-song、别:I-song ),于是可以在 word embedding 的基础上增加 knowledge embedding,如图所示:
再就是 OOV 问题,这个问题业务上比较困难,因为用户如果说的是"你的酒馆打了烊",但这个并不是歌名,知识库也就引不进去了。我们的做法与 NER 类似,首先学习槽位边界,提供多种解码路径,如路径 1:意图为 play_music,并给"你的酒馆打了烊"打上 like_song ( 疑似歌曲 ) 的标签;路径 2:意图为 play_story,并给"你的酒馆打了烊"打上 like_story ( 疑似歌曲 ) 的标签。接着通过知识库进行校验,我们根据编辑距离、文本相似度等策略可以判断路径 1 的置信度更高,因此选出路径 1。具体可见 Rank 策略。
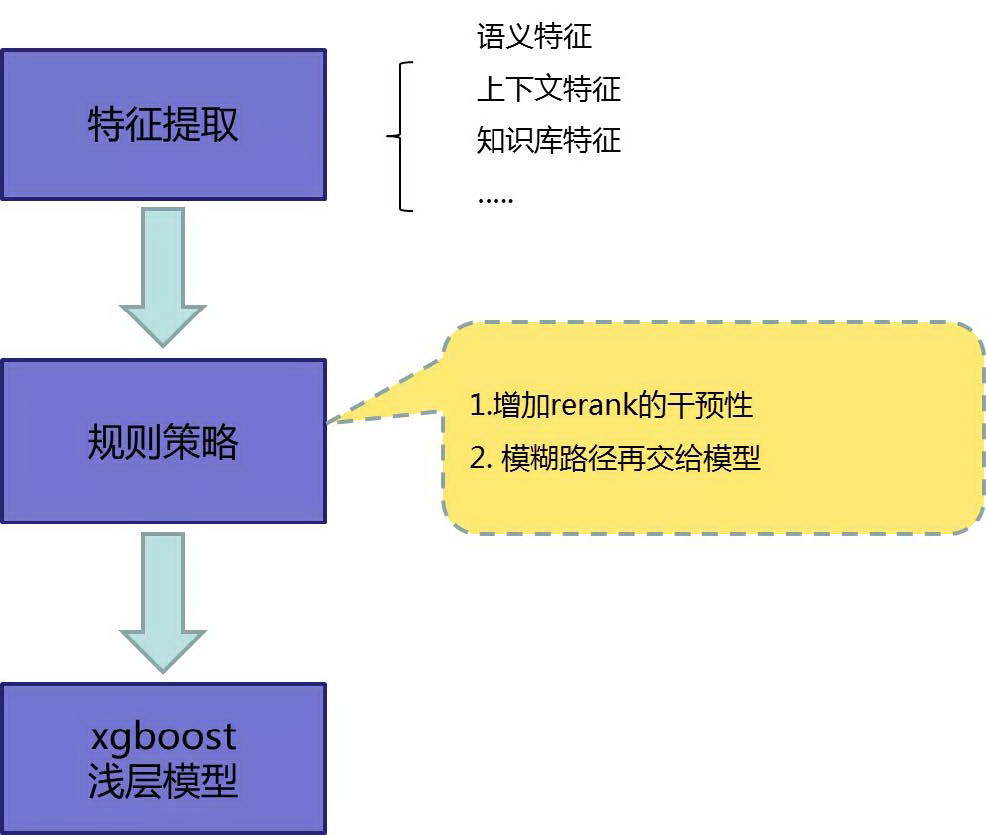
③ 语义理解-Rank
这个步骤是多路径选择消歧,即获取到多个解码路径后,我们选择一个置信度最高的,作为语义理解部分的结果。Rank 阶段我们主要采用的还是经典的 xgboost 模型+规则策略。这里规则是为了业务的可干预性,有利于产品运营人员快速解决一些业务 case。
2. 对话核心技术-对话管理
对话管理 ( Dialog Manager ) 系统分为两个部分:DST ( Dialog State Tracking,对话状态跟踪 ) 和 DP ( Dialog Policy,对话策略 ) 两个模块。
DST 主要用于状态追踪,这一模块维护对话的上下文状态、进行上下文语境的管理、意图槽位继承等。DP 是决策模块,它根据 DST 记录的当前系统状态,进行系统动作决策。
目前对话管理模块的实现主要有基于框架 ( Frame based ) 的管理、基于有限元状态机 ( FSM ) 的管理和基于 Agenda 的管理等。我们引入了其中的两种:
Frame Based:在以完成任务为导向的对话系统中,Frame Based 的系统将对话建模成一个填槽 ( slot filling ) 的过程。槽是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。例如:“告诉我去车站怎么走”,其中目的地是一个槽位,"车站"是该槽位所填充的值。目前,360 智能语音交互系统已经支持这一模式。
该方法的特点是:
输入相对灵活,用户回答可以包含一个或多个槽位信息
对槽位提取准确度的要求比较高
适用于相对复杂的多轮对话
FSM Based:这种方法主要用于特定的任务,如订票。这种方法通常将对话建模成一棵树或者有限状态机。系统根据用户的输入在有限的状态集合内进行状态跳转并选择下一步输出,如果从开始节点走到了终止节点则任务就完成了。
该方法的特点是:
提前设定好对话流程并由系统主导
建模简单,适用于简单任务
将用户的回答限定在有限的集合内
表达能力有限,灵活性不高
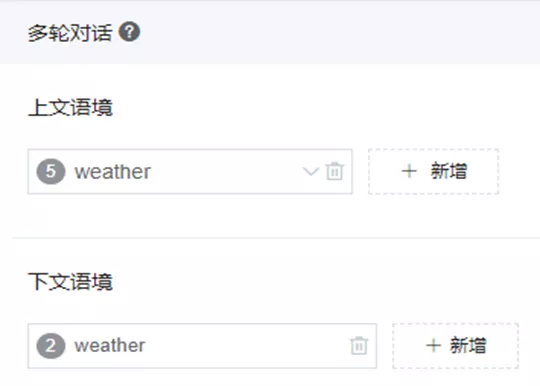
我们的创新点在于通过上下文语境实现了跨场景的信息继承,这里要引出两个概念:上文语境和下文语境。上文语境是指上文出现过的信息,主要用于信息继承;下文语境是指当前对话中要存储的信息,我们可以给不同类型的信息设置不同的继承轮数。我们可以把语境信息想象成一个银行,根据"存钱+取钱"的工作模式进行语境信息的获取与更新,并且支持基于对话轮数和事件的遗忘,这样就可以做到跨场景的继承。
对话管理的工作流程:
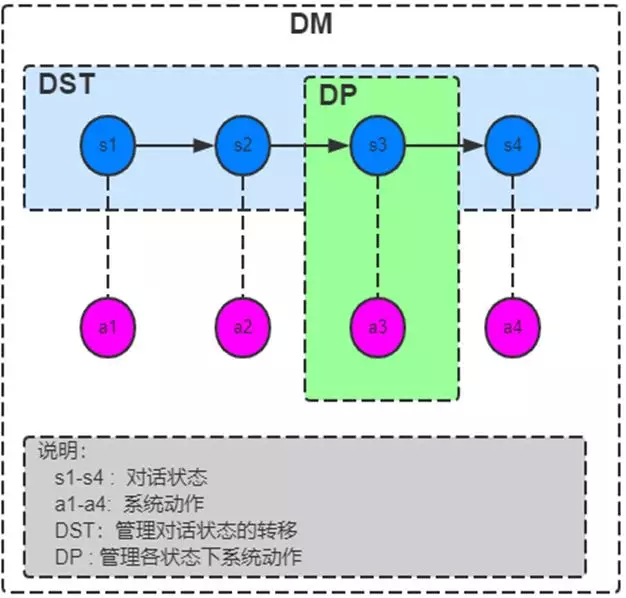
对话管理模块的工作流程和强化学习的"马尔科夫决策过程"比较类似[3]。在用户和 bot 的对话过程中,每一轮对话都有当前状态 ( state,图中为 s1-s4 ) 以及 bot 根据当前状态做出的反应 ( action,图中为 a1-a4 )。DST 做的就是追踪 state,管理对话状态的转移;DP 做的是管理各状态下的系统动作,根据当前 state 的信息,做出反应。这里 DP 可以做出的反应包括调用子功能、继续询问、澄清、兜底回答等。
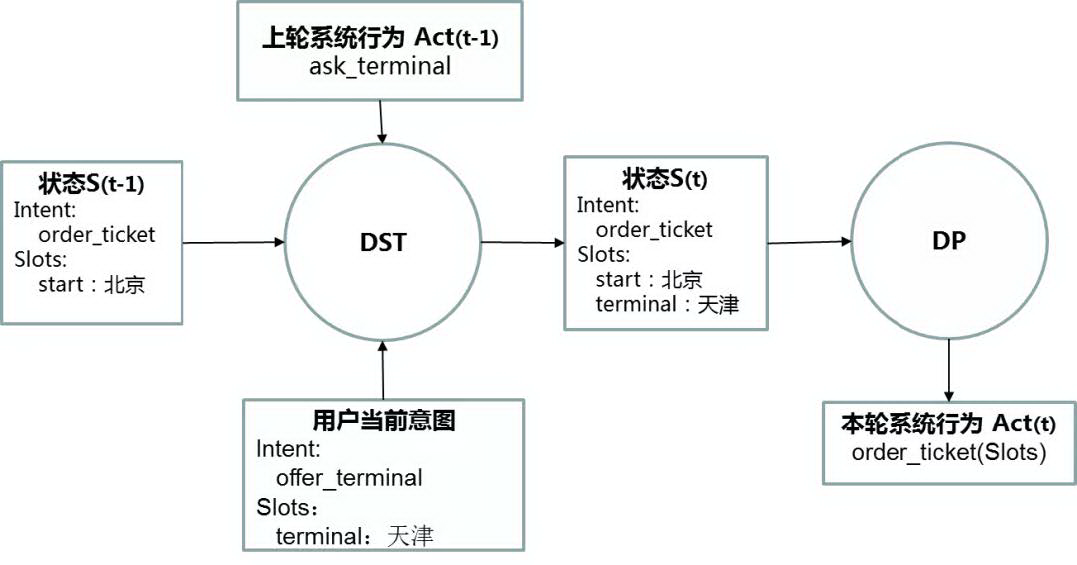
下图展示了在订票场景下的一轮对话中,对话管理系统的流程:
3. 对话核心技术-QA
最后介绍的是 QA 部分,QA 的系统很大程度上依赖相似搜索,其实和检索式闲聊系统非常相似。
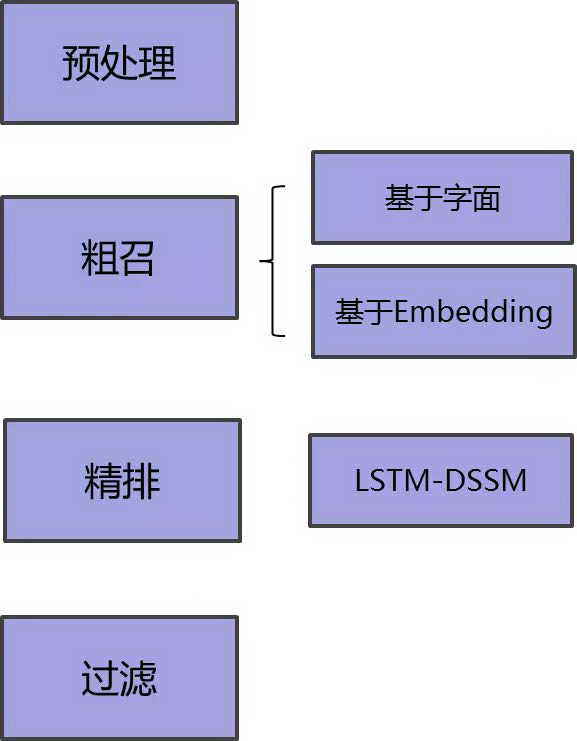
在 360 智能语音对话平台上,QA 系统通过预处理 -> 粗召 -> 精排 -> 过滤的流程得到最接近的答案并输出给用户。下面详细介绍一下这个流程:
Query 预处理:这部分是对输入 Query 进行归一化,方法和业界比较通用,不再赘述
粗召:分为基于 keyword 的召回和基于 Embedding 的召回。基于 keyword 召回是利用 ElasticSearch 实现,找出字面相似的结果;基于 Embedding 的召回是我们将所有候选 Answer 建立了 Faiss 索引,通过 Query 的深度语义 Embedding 进行语义相似性的检索,这样可以召回字面不同但实际含义相似的结果
精排:主要用的是我们训练的 LSTM-DSSM 模型,将 Query 和粗召结果做相似性打分,根据相似度由高到低排序
过滤:根据业务逻辑的过滤,最终输出符合条件的相似度最高的候选
这里重点讲一下我们的 LSTM-DSSM 模型,模型示意如下:
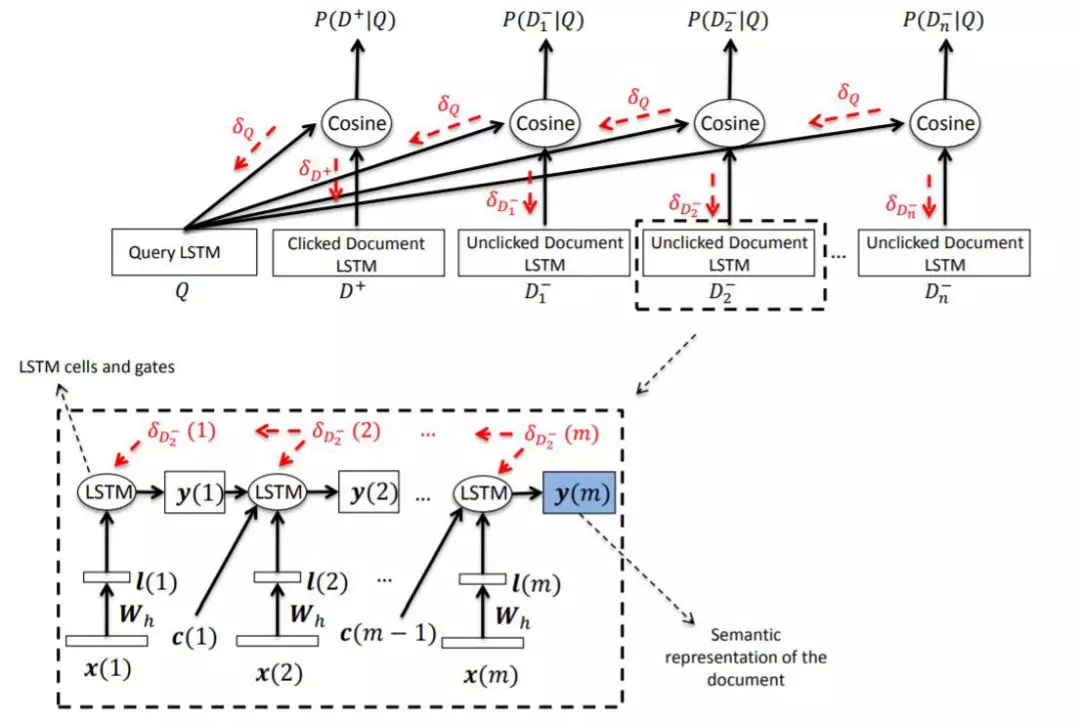
文本相似度问题的传统解法有 BM25、TF-IDF、编辑距离、Jaccard 相似度等,使用的时候可以多个距离都算出来,用一个模型拟合各个距离的权重,进行加权求和。基于深度学习的方法主要有 DSSM 的各种变种 ( 增加卷积层、增加 LSTM 等 ),近年来还有基于 BERT 的相似度计算。
DSSM 模型[5]最早是微软提出来的,通过 Bing 搜索引擎的点击日志数据训练,它非常适合拟合搜索 Query 和 Document 的文本相似度。而公司有 360 搜索的搜索日志,每天都有亿级别的点击行为正负例出现,给我们的模型训练提供了丰富的语料,这是我们的优势。尝试了不同模型后发现,在我们的业务场景下,LSTM-DSSM 模型比其他模型效果都要好,甚至比 BERT 更好,而且计算量更低。
总结
本文首先介绍了语音交互系统的基本知识和系统流程;然后介绍了 360 智能语音交互平台,重点分享了我们的业务架构;最后讲解了对话系统的核心技术,包括语义理解的 SF-ID 模型、对话管理系统和 QA 的技术架构。
本次分享就到这里,谢谢大家。
参考资料
[1] Goo C W, Gao G, Hsu Y K, et al. Slot-gated modeling for joint slot filling and intent prediction[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018: 753-757.
[2] Haihong E, Niu P, Chen Z, et al. A novel bi-directional interrelated model for joint intent detection and slot filling[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 5467-5471.
[3] Zhou L , Gao J , Li D , et al. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot[J]. 2018.
[4] Palangi H, Deng L, Shen Y, et al. Semantic Modelling with Long-Short-Term Memory for Information Retrieval[J]. Computer Science, 2014.
[5] Huang P S , He X , Gao J , et al. Learning deep structured semantic models for web search using clickthrough data[C]// Proceedings of the 22nd ACM international conference on Conference on information & knowledge management. ACM, 2013
作者介绍:
龚小春,360 高级算法专家。
本文来自 DataFunTalk
原文链接:
https://mp.weixin.qq.com/s/ACURDfwamImA70UPXrY8IA

《研发效能 100 问》上册
第一本研发效能领域的问答工具书,集结来自腾讯、字节、自如等企业的专家,解答研发效能领域高频问题。













评论