

移动互联网时代,图像和短视频等多媒体内容爆发,基于计算机视觉的 AI 算法是多媒体内容分析的基础。在美图社区智能化发展的过程中,视频和图像分类打标、去重以及质量评估的结果,在推荐、搜索以及人工审核等多个场景下都有应用。本文主要介绍美图社区图像和短视频分析,如何减少短视频去重在美图社区误召以及 OCR 在内容审核的应用以及落地。
多媒体内容理解
美图社区和多数社区一样,包含图片、文字、音频、视频等多种形态的数据。社区内容五花八门、质量层次不齐、数据分布极度不均匀,这给内容理解带来了很大的挑战。
总体来说,多媒体内容理解的应用分为四个方向:内容审核、内容质量、内容标签和特征工程。
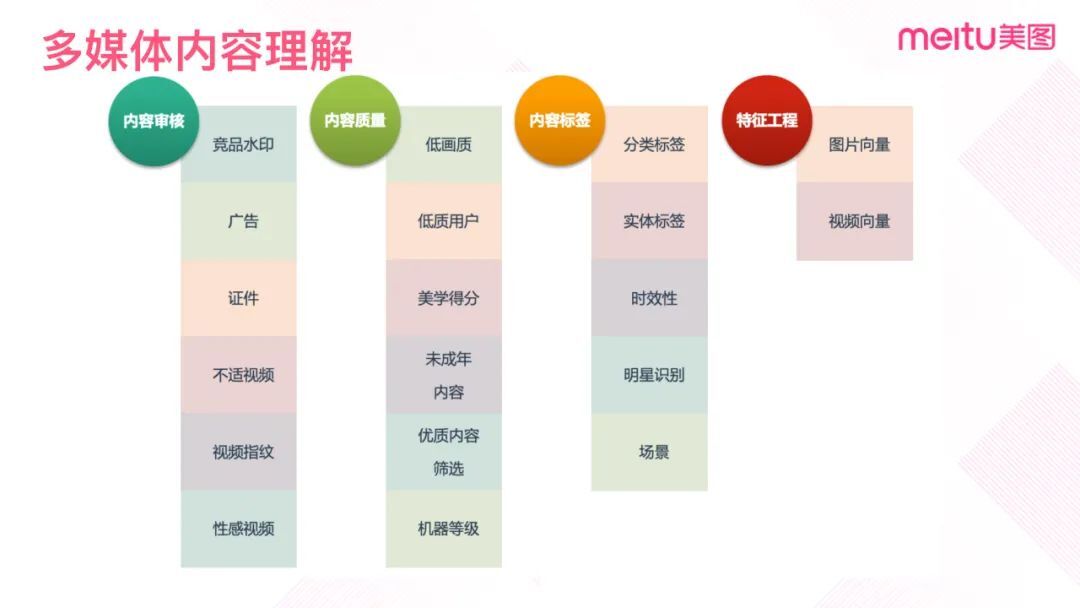
1. 内容审核
内容审核包括过滤竞品水印、广告、证件、性感视频等违规特征。但是违规过滤的特征与安全审核中涉黄涉政和反恐反暴的特征不一样,这里的关注重点是不适合曝光的内容。
2. 内容质量
识别违规内容后,通过图片的低画质识别、地址用户识别、图片美学得分,融合各质量特征的优质筛选模型,最后综合预测得到内容的质量等级。
3. 内容标签
首先通过符号化的标签和语义特征向量表示内容。符号化的标签包括粗粒度的分类标签、细粒度的实体标签、长时效 or 短时效。然后通过人脸识别分析出明星特征以及视觉场景特征等等。
4. 特征工程
特征工程主要包括图片向量和视频向量。
这里主要介绍短视频分类、视频指纹和 OCR。
短视频分类
1. 短视频分类在美图社区的应用场景

短视频分类被应用在美图旗下多款社区产品的不同场景中。比如美图秀秀的推荐信息流中使用了基于用户兴趣标签的召回、基于用户所在地域的召回;相关推荐中使用了基于视觉相似的召回等;搜索用户画像、运营后台的人工审核等也都有应用短视频分类。同时内容特征会作为排序模型的一个重要的输入特征,在实际使用过程中也起到了不错的正向效果。
2. 短视频的特点
短视频是用户在生活中用手机随意拍摄得到的,内容千变万化,类别分布不均匀,拍摄角度单一。即使在相同的结构场景下,表达的内容可能也不相同。而且拍摄者希望自己的作品与众不同,也希望自己的作品可以第一时间分享给其他用户。此外视频本身是由图片、文字、音频等多种形式组成,随着时间的推移,拍摄的风格也会随之变化。
3. 短视频分类模型的选择
在模型的选择上,在保证效率的同时,一方面希望利用文本、音频、视频等更多的特征来提升模型的性能;另一方面希望利用简单高效的方法,用尽可能少的帧数输出相对不错的效果。
① 多模态模型
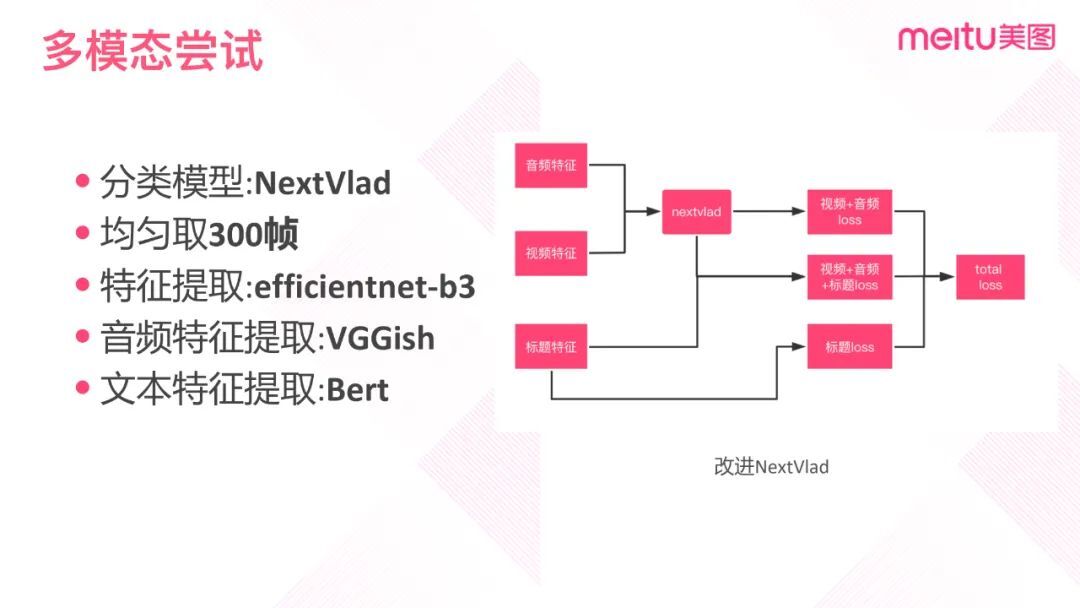
在这样的初衷下,排除 LSTM、3D CNN 和双流网络模型。我们首先尝试的是 NextVlad——第二届 YouTube 8M 短视频分类大赛第三名的论文。原有的模型基于音频和视频特征实现分类,进行标签预测。我们在此基础上做了三点不同的处理:一是添加文本特征:通过在社区下预训练的 Bert 模型提取 128 维固定长度的文本向量;二是用更好、速度更快的 EfficientNet B3 模型替代原有的特征提取模型 Inception V3;三是结合视频 loss、标题 loss 和音频的 loss,进行多任务的学习。性能比原有模型高出 3%左右。
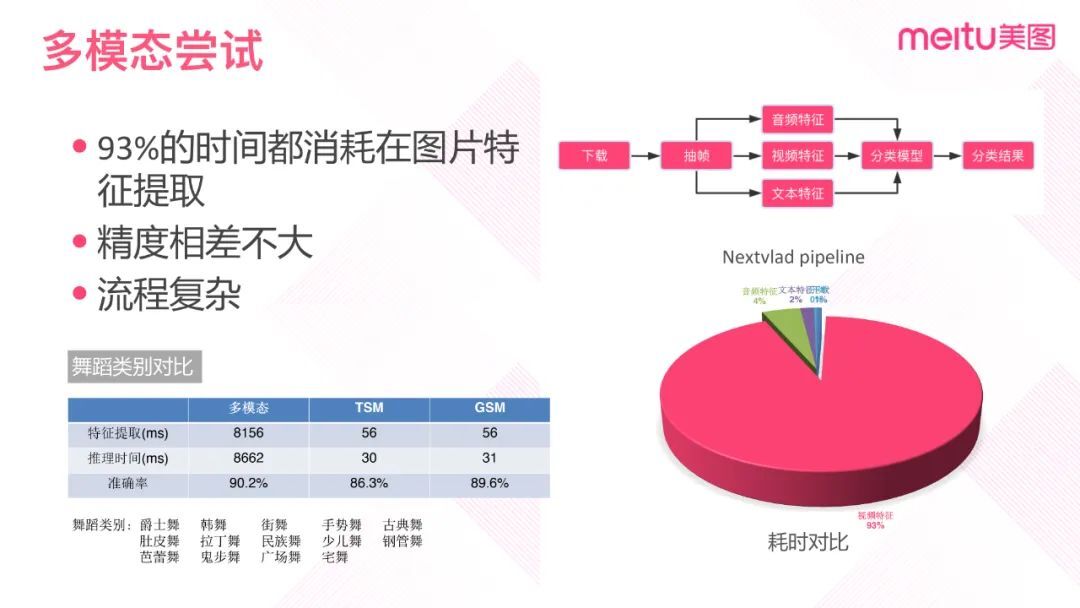
统计 NextVlad 模型运行一天的数据。在使用 GPU 的情况下,处理一个视频平均需要 8.6 秒。其中 300 帧视频的特征提取需要 8.1 秒,占整体时间的 93%。
在舞蹈类别上对 NextVlad(多模态模型)、TSM 和 GSM 三个模型进行性能和效率的对比。舞蹈类别的数据包括 14 类:爵士舞、韩舞、街舞、手势舞、古典舞、肚皮舞、拉丁舞、民族舞、少儿舞、钢管舞、芭蕾舞、鬼步舞、广场舞和宅舞。
总体来看,多模态模型的性能提升不高,与 TSM 相比仅提升 3%左右,这说明音频信息对舞蹈分类有一定的辅助作用。而 TSM、GSM 没有特征提取这一步,精度也接近 90%。所以综合来看,多模态的整体流程比较复杂且依赖过多,而且 NextVlad 和 GSM 模型精度相差不大,性价比不高。
② 单模态模型

C3D 在缺乏足够大数据集的情况下进行大规模训练,性能一般不佳。而且模型训练过程涉及大量的参数和计算量,所以在这里我们暂不考虑。TSN 则是对每帧图像进行分类,对分类结果求均值。该模型没有任何的时间编码能力,最后的预测结果也与帧的时序无关。GST 则是在分离的通道上,通过 2D 和 3D 卷积并行模拟空间和时间的相互作用。TSM 则是通过时间卷积限定在一个硬编码的时移上,这种时移可以使某些通道在时间上向前或向后移动。这种学习方法具有硬连线的连接和跨网络传输模式的结构化内核。
上述网络的中任意一点都没有数据依赖的决策,即通过不同的分支来选择路由特征。分组和随机的模式都是在设计之初设定的,而学习如何随机具有一定的组合复杂性。所以在美图社区中使用的是 GSM。
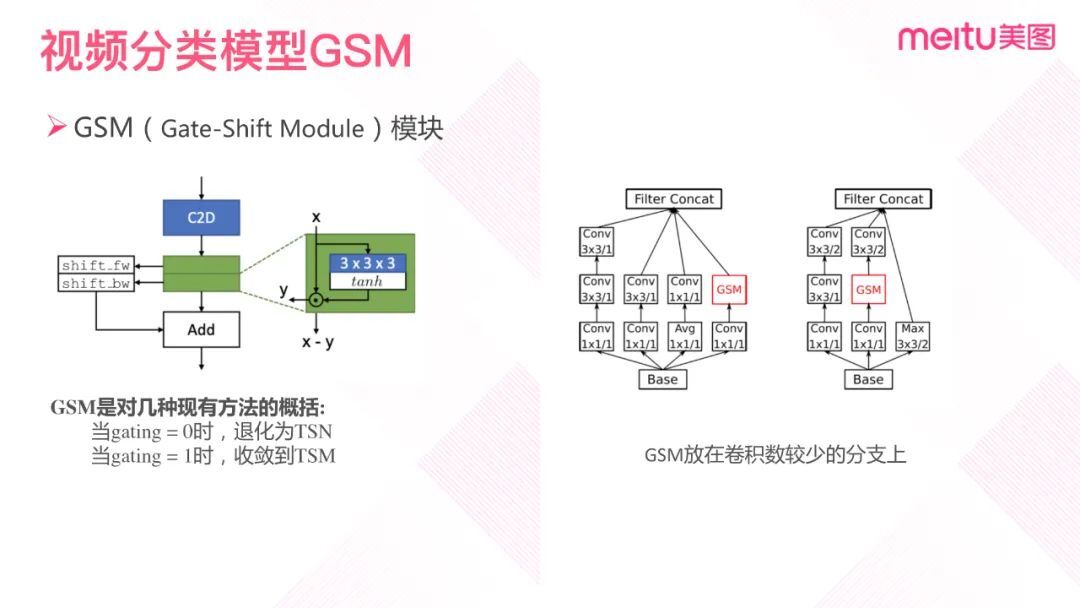
GSM 首先把输入的 2D 卷积分成两组,然后分别通过 3D 时空卷积和 tanh 激活函数,再然后经过门控单元,一组固定前移、一组固定后移,最后将输出与门控的另一个输出进行相加。GSM 通过 3D 时空卷积将 2D 卷积转化为高效的时空特征提取器。这样 2D 卷积就可以自适应地学习时间路由特性,并将它们结合起来,而且过程中几乎没有额外的参数和计算开销。GSM 模块的本质是一个 x 为输入的残差结构。这种残差结构具有一定的特征选择能力和数据路由能力。GSM 模型学习到的时空特征如果用于分类,可以提升模型性能。GSM 与其他模型的关系可以概括为:当门控输出全为零时,GSM 退化成 TSN;当其中一组门控为零、一组不为零时,GSM 收敛到 TSM。在实际应用中,GSM 被放在卷积数比较少的分支上。
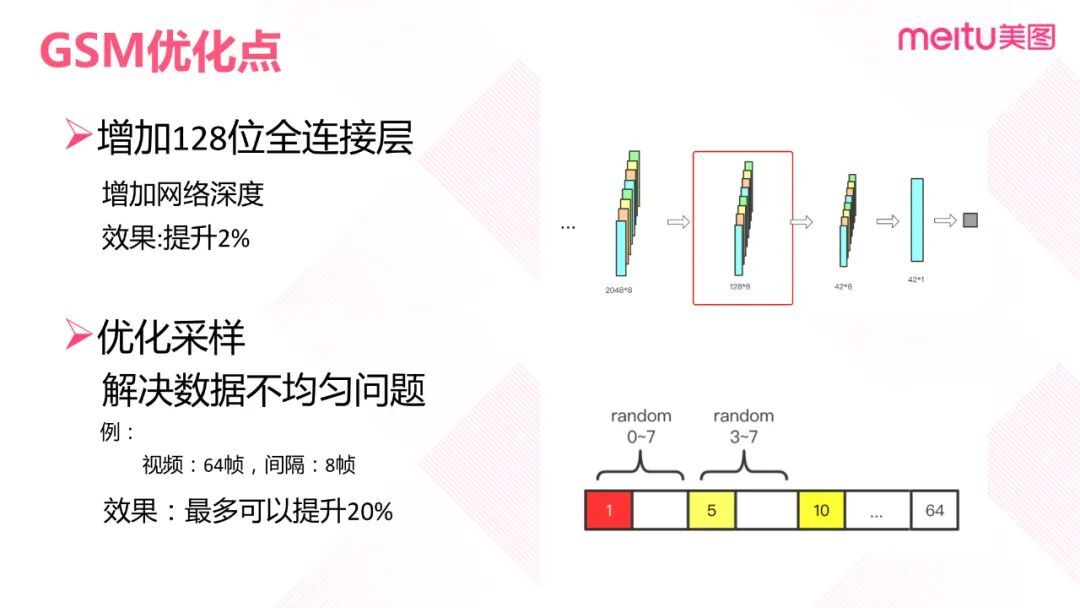
我们在原有 GSM 模型的基础上做了两点优化:一是在获取每一帧的特征之后和类别的 FC 层之前,也就是在 2048×8 和 42×8 之间添加一个 128 维的全连接层。添加全连接层,相当于在原有特征的基础上再进行一次特征聚合,进一步提取特征。同时增加了网络深度。这一优化在美图社区场景下,可提升 2%左右的精度。二是优化采样。美图社区的数据类别分布不均匀,样本最多的类别下有数万个样本,最少的仅有 100 多个样本。通过提高少数类样本的采样率使每个类别有相同数量的样本,性能基本上没有提升。GSM 的训练仅需要 8 帧的图像信息。以 64 帧视频为例,有 56 帧的信息是浪费的。所以在这里我们做了一些优化:64 帧的视频则均匀取 8 帧,间隔 8 帧。从第一帧开始,在第一帧和第八帧之间随机取一帧。从第二帧开始的话,则从当前帧到当前帧之后的第八帧之间再随机取。这里我们是从第四帧到第八帧间取第二次采样开始的帧数,避免相邻帧过度相似。
通过这种方式对少数类样本进行采样,基本上每次都可得到一个新的视频。对于数量比较少的类别,这一优化最高可提升 20%的精度。
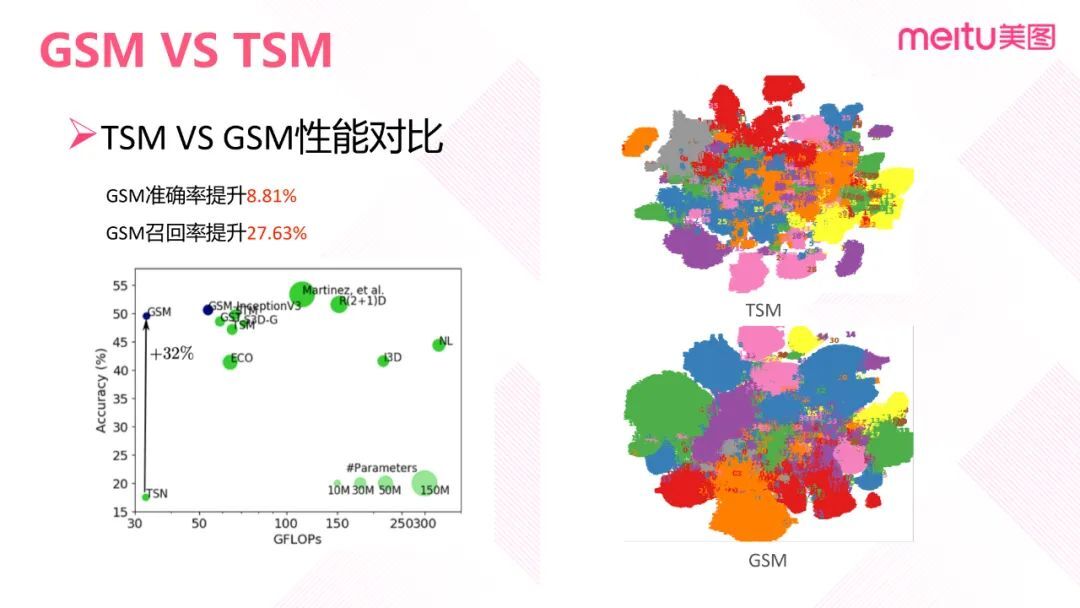
在美图社区下 42 个类别、150 万的短视频数据上进行训练,对多个模型的性能和效率进行对比。其中 GSM 的 backbone 是 Inception V3,TSM 的 backbone 是 ResNet 50。实验结果显示,在性能上,GSM 比 TSN 的精度高出 32%;比 TSM 的准确率提升 8%以上,召回率提升 27%。在效率上,GSM 和 TSM 在 GPU 上的推理速度相差不大,大约都是 30 毫秒。经过推理优化之后,GSM 在四核 CPU 上的推理速度可达到 200 毫秒左右。下图的右侧是使用 TSM 和 GSM 输出的 128 维向量在 42 个类别上的聚类图,从图中也可以看出 GSM 的聚类效果好于 TSM。
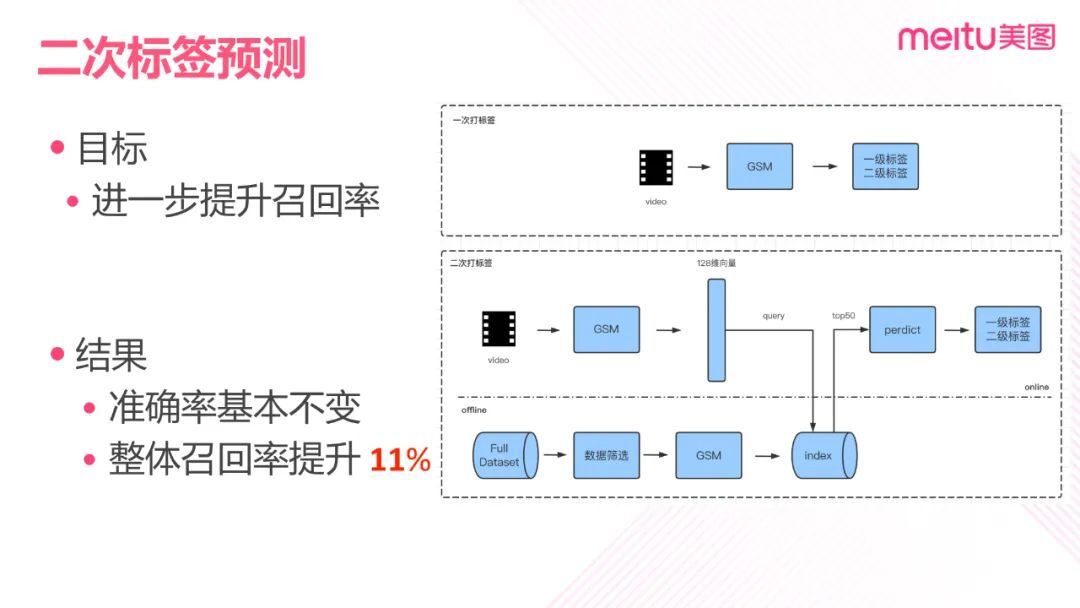
为进一步提升召回率,使标签覆盖率尽可能接近 100%,这里使用 GSM 模型添加的 128 维的 FC 层提取 128 维向量对未打标的数据进行二次打标。
这一过程包括两部分:在线(online)和离线(offline)。离线部分的主要作用是对全量数据建立索引库,在线部分的主要作用是预测新视频的标签。在离线部分中,首先对全量的视频进行策略筛选,然后使用 GSM 提取 128 特征向量,建立索引。在线部分,首先确定打标过程中由于置信度较低而没有标签的数据,然后对这一类数据进行特征提取,在索引库中检索相似视频,并取出 top50 的结果,最后对标签进行预测,得到一、二级的标签。实验结果显示,在保证一、二级标签准确率不变的前提下,整体的召回率可以提升 11%。
视频指纹
1. 视频指纹的难点
视频指纹的难点有四点:一是添加片头、片尾改变视频的时长;二是添加水印、logo 和文字。这种情况在美图社区中尤为常见;三是通过剪裁等手段改变视频分辨率;四是通过添加黑边、白边和动态模板等手段改变视频画面内容。
2. 视频指纹的 pipeline
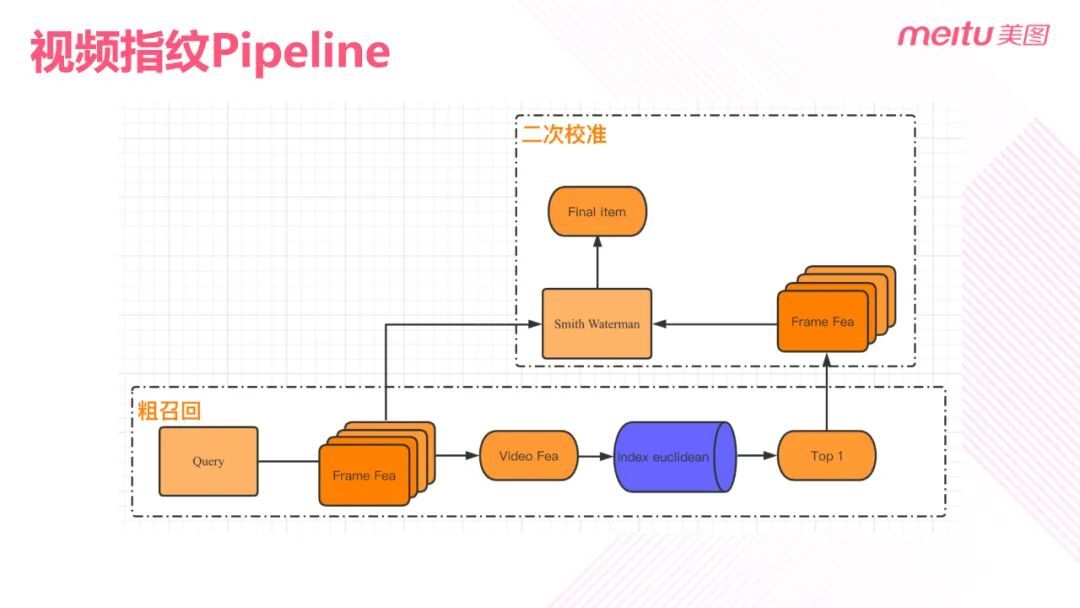
视频指纹的 pipeline 主要分为两个部分:第一部分是粗召回,主要针对视频整体特征,第二部分是二次校准,主要是对视频中帧与帧之间的相似度对比。
粗召回,query 经过下载抽帧,获取每帧的特征,通过每帧的特征获得视频级的特征,在视频指纹库中查询,取出 top1,在于 query 视频进行逐帧对比,对比成功打上重复指纹,对比不成功,分配新的指纹。逐帧比对时,使用 Smith Waterman 算法。
① 对比视频的特征提取
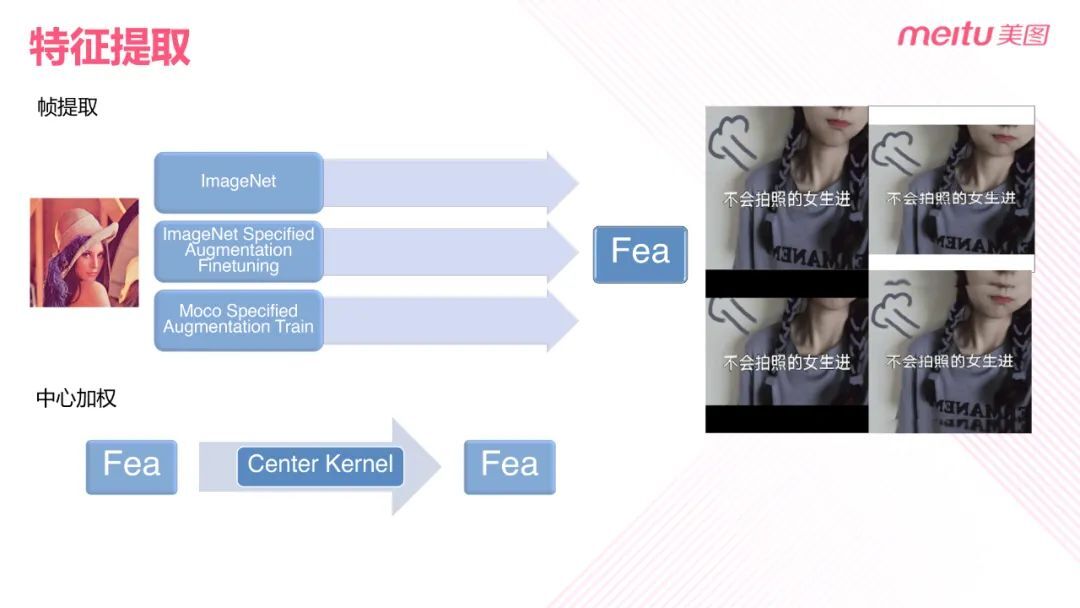
常用的视频特征提取方法有三种:第一种是直接用 ImageNet 预训练模型提取特征,并将其用作视频的整体特征;第二种是在 ImageNet 预训练模型上添加一些特殊的数据增强方法,然后在自己的数据集上进行反推理。这种做法有一定的性能提升,但是特征分布还是基于类别的特征分布。第三种做法,也就是我们的做法,使用 Moco 作为前置任务,然后通过添加剪裁、文字、logo 等数据增加方法,在自己的数据集上进行训练,得到视频的特征向量。最后使用这一特征向量作为视频帧和视频整体的特征向量。
此外,在视频指纹的场景中,添加黑边、白边后视频的主体内容其实都是中心部分。中心的像素权重应该大于黑边和白边的像素权重,所以在每帧的特征上设置了中心加权。
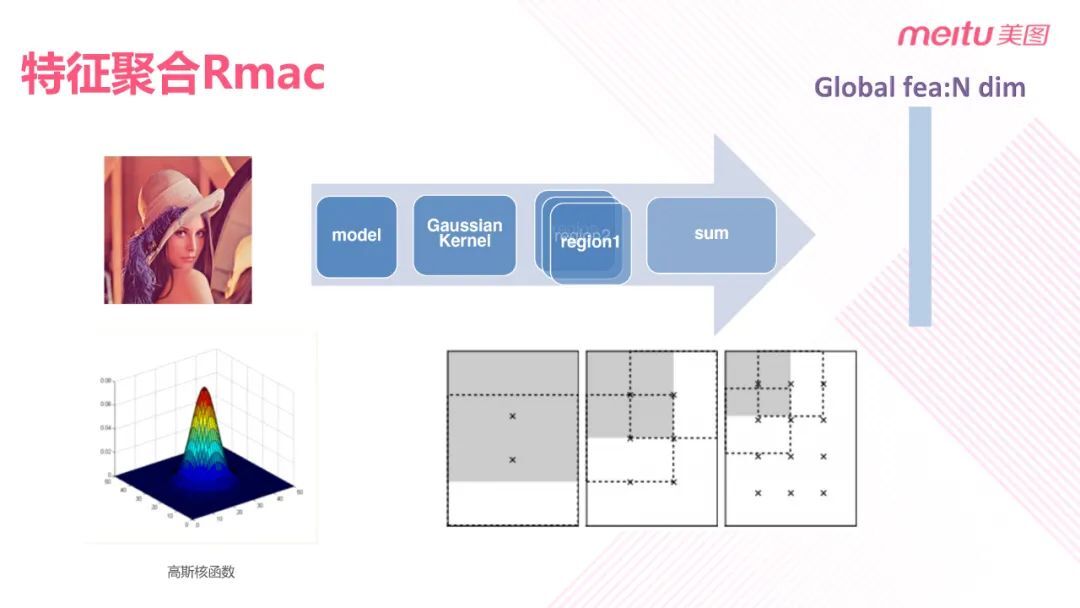
下面介绍一下中心加权是如何设置的。目前图像检索一般使用 CNN 提取特征,使用卷积特征一般会优于使用全连接层的特征。在中心加权中也是使用 CNN 中间层的特征。首先提取图片中间层的特征,然后添加高斯核函数,使用特征聚类算法 Rmac 进行中心加权。
Rmac 采用窗口滑动的方式,使用 max pooling 提取不同区域大小的 feature map。Rmac 还使用了 scale 的方法,最大区域为 1 时用于提取整张图片的特征;对于较小的区域,在取值时设置 40%的重叠域。
由于 Rmac 平等地对待每一块特征聚合的图像区域,而实际上每一块区域的特征权重并不一致,所以这里使用了区域注意力机制。根据图像显著性检测原理生成不同的区域权重,然后使用 Rmac 和区域注意力权重进行加权聚合,获得最终的图像特征。
② 视频逐帧对比方法
在获取每张图像的特征后,如何高效、准确地对比两个视频的帧序列?是用向量计算 cosine 相似度?还是借助 Face 计算欧式距离?或者是用哈希方法计算海明距离?或者还有什么其他的好办法?
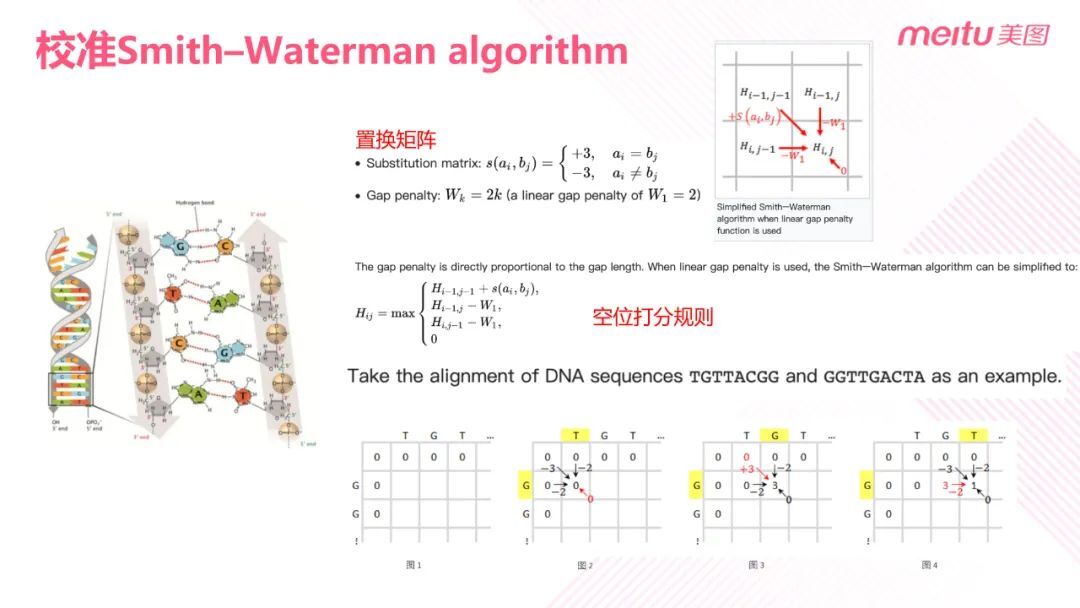
在这里我们使用的是生物信息工程中的 DNA 对比算法——Smith Waterman 算法。它是一种局部序列对比的算法,作用是找出两个视频序列之间的相似区域。
具体做法是定义一个置换矩阵。置换是指如果两帧匹配则加 3 分,反之减 3 分。如上图所示,W 是指空位罚分,初始值为 2。
算法则分为三个步骤:
① 初始化矩阵。其中首行、首列的元素值均为零;
② 计算得分。得分来自三个方向(见上图),最后的得分取三个方向上的得分和 0 之间的最大值。以 DNA 序列为例(见上图 3),该图展示了前三个元素的打分过程。黄色区域表示当前正在考虑的两个碱基,红色代表这个位置的一个得分来源。以图三为例,对应元素的左上角为零分,但是对应的横方向和纵方向都是 G,是匹配的,所以斜方向得分为 0+3 分;对应元素的左方和上方是不匹配的,所以左方和上方的得分均为 0-2 分。所以最后这个位置的三个方向上的得分为 3、-2、-2。取这三个值和 0 中的最大值,也即 3,作为当前元素的得分。其他元素的得分以此类推。最终得到一个划分矩阵,划分矩阵就如下图所示。
③ 回溯蓝色区域。
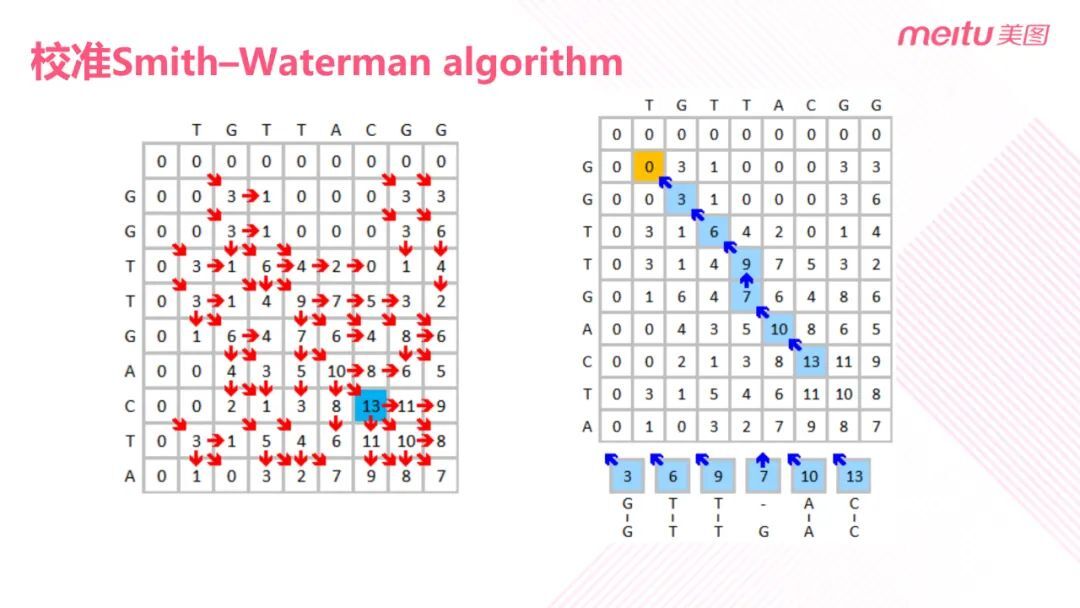
蓝色区域代表最高得分的元素位置。从最高分的元素开始回溯,直至回溯到 0。局部最相似的序列是从最高分回溯到 0 的过程中自右向左产生的序列。需要注意的是在回溯过程中,某些位置可能有不止一种方向,这样可能会产生多个分支。如果多个得分方向上有相同的最高分,则应当考虑每一个最高分的回溯。此外在回溯的过程中还有可能出现一种情况:相同格会有多个最大值的得分方向。这时优先级按照左上角、上边、左边的顺序进行回溯。
最终仅需计算局部相似序列中相似的特征个数。如果小于某个值,则认为两个视频不匹配,反之则认为它是匹配的。

上图是视频指纹的效果示例。对于改变视频本身内容的,如剪裁、添加黑边,可以看到效果不错。对于添加文案的,同样会有不错的效果。该方法与哈希的方法相比,准确率提升 3.1%,召回率提升 24.4%。
OCR
1. OCR 的业务需求
在美图社区中,OCR 的主要业务场景是对社区中的图片或者视频中的内容进行文字提取和识别。基本需求包括内容特征的补充,如基于封面图给无标题的内容添加标题、利用图片中的信息给商品添加描述。进阶需求包括三个方面:一是商品名和作品名的识别,比如影视作品、电影作品;二是内容质量,比如对广告文案进行广告识别;三是安全审核的需求,如命中敏感词、过滤敏感词。
2. OCR 的业务难点
OCR 的业务难点包括三个方面:一是标注成本巨大,字符种类繁多,如简体中文、繁体中文、英文、数字、英文花体字、中英文广告字体;二是文字方向不一;三是通用的 OCR 算法存在一些问题。如识别率低、对社区内的字体识别差、对背景复杂的图片泛化能力不好、倾斜的文字无法检测、会将一些符号误识别成文字。
3. OCR 解决方案
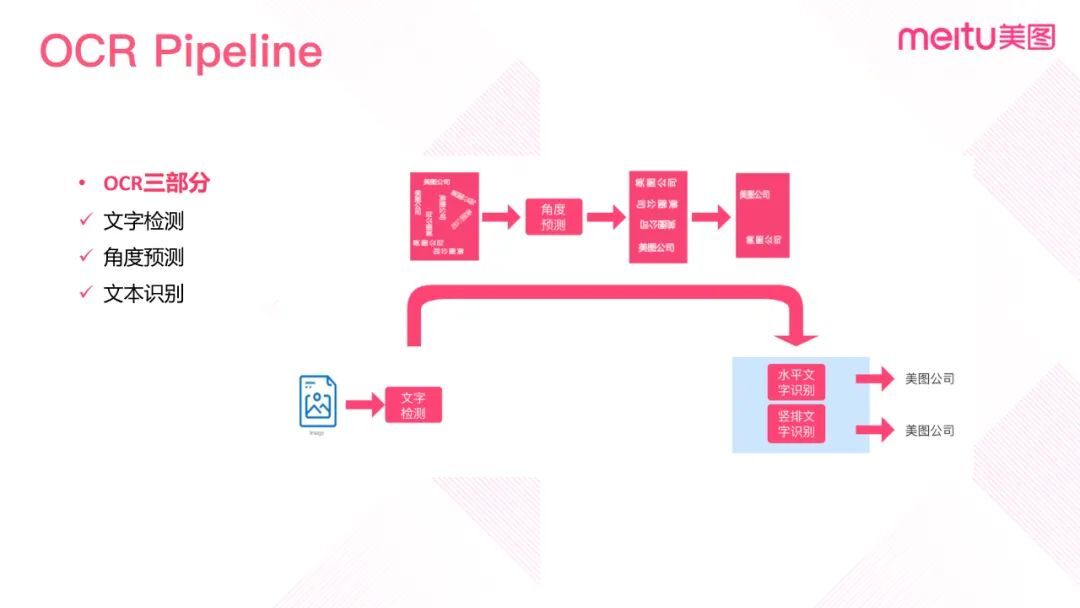
美图则是使用数据合成的方式,用社区的图片和语料训练适合美图社区的文字检测模型和文字识别模型。
在文字检测框送入识别模型之前,对文字检测框进行角度预测和矫正,用于提高识别的准确率。文字检测时可以识别不同角度横排、竖排的文字以及带有弯曲角度的文字。经过文字检测后,文字检测框是多种多样的。对文字检测框进行最大外接矩阵和仿射变换后,将其输入角度预测模型,会得到 0°、90°、180°和 270°四个分类结果;然后根据预测的结果进行旋转,将文字检测框归并为水平文字和横排文字;最后再输入水平和竖排文字的识别模型,得到识别结果。
① 文字检测
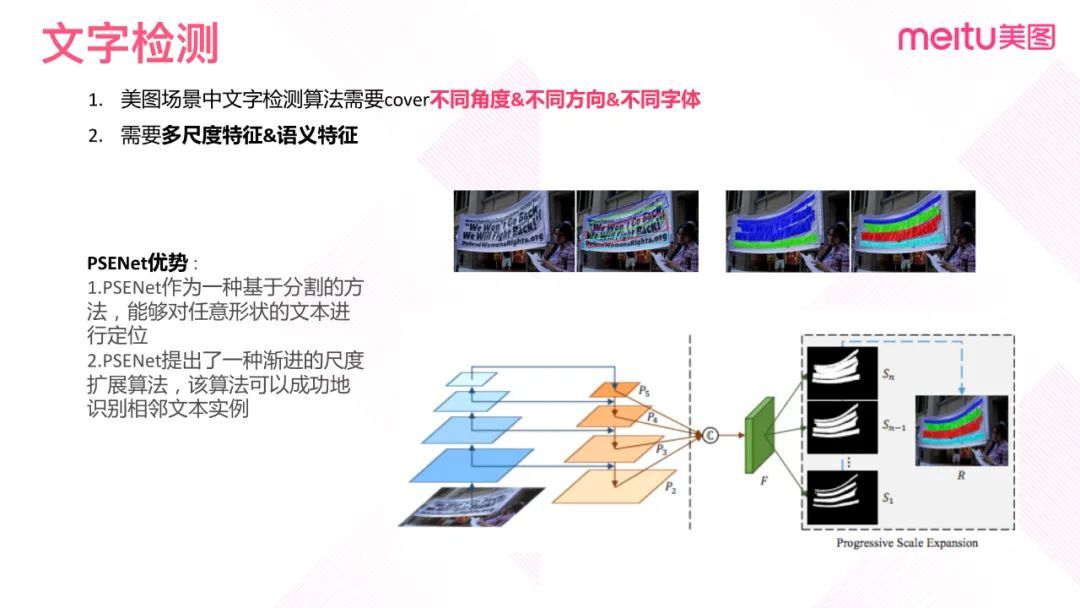
在社区环境下,不仅有自然场景下的文字,还有广告字体和一些复杂背景的文字符号。Ctpn 这种利用 bounding-box 回归方法对弯曲的文字检测不准确,无法检测竖排文字,还会经常把一些符号误识别成文字,无法检测靠近文字。所以我们使用 PSENet。
PSENet 具有两大优势:首先它是一种基于分割的方法,能够对任意形状的文字进行定位;其次它是一种渐进的尺度扩展算法,该算法能够解决相邻文本定位不准确的问题。
PSENet 受 FPN 启发,采用 U 型的网络架构,将网络提取出的特征进行融合;然后利用分割的方式将提取出的特征进行像素分类;最后利用像素分类结果,通过一些后处理的方式得到文本检测结果。该方法可以解决现有 bounding-box 回归方法对弯曲文字检测不准确的问题,也能相对减少对符号的错误识别。
② 文字识别
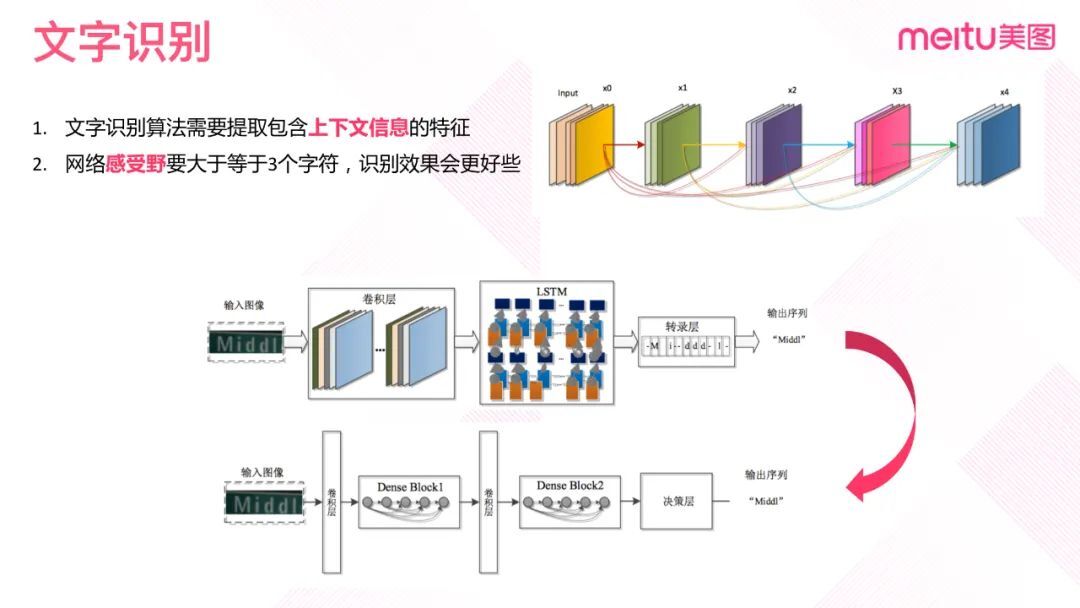
文字识别模型一般需要上下文信息特征。如 Inception、ResNet 这类 CNN 网络,如果需要有上下文信息的 CRNN,就需要添加 LSTM。通常的文字识别模型由 CRNN、LSTM 和 CTC 组成。LSTM 训练的时候较难收敛,推理速度较慢。出于对易于训练和加速推理速度的考虑,我们使用的是 ResNet。该模型可在不需要 LSTM 学习上下文的同时提升推理速度。在解码方面上使用添加 FC 层的 CTC:利用 FC 层输出的特征,通过决策层进行解码,然后输出一个正确的文本识别结果。另外我们计算并实验了感受野大于或等于 3 个字符的情况,识别效果是最好的。
4. OCR 线上效果
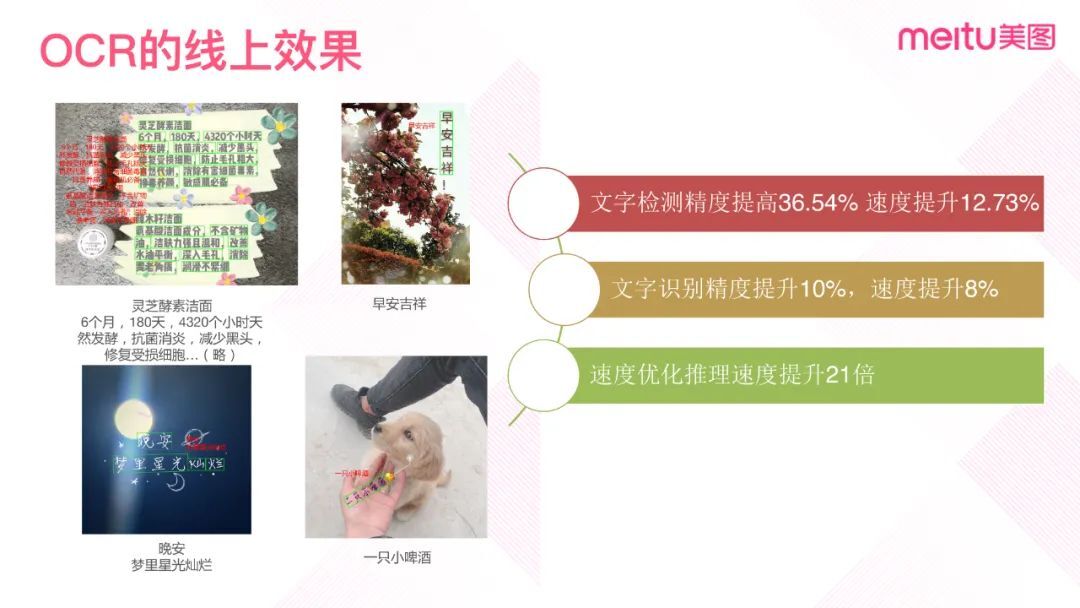
上图是 OCR 模型的线上效果示例。对于长文本的广告,基本上能做到 100%的识别,且没有丢字或者重复字的情况。竖排文字、变形文、变形字体以及各种角度的文字识别都有着不错的效果。
整体上文字检测的精度比 CDPN 提高 32.54%,速度提升 12.73%。文字识别的精度比 CRNN 提高 10%,速度提升 8%。由于做了网络的瘦身,整体速度优化推理速度也提升 10%。
总结与展望
总的来说,通过实验得出以下结论:
① 多模态是有效的:通过多模态的融合,精度可以稳步提升 2%到 3%。
② 一个好的预训练模型非常重要:不仅对视频指纹有所帮助,对于视频的分类也有帮助。
③ 算法需要与业务深度结合。需要结合实际的业务场景,对算法的性能和效率权衡利弊。
虽然已经开展了一些工作,但是还有很多方面需要完善和改进。
① 视频标签仍需要不断的细化和完善,模型性能、模型优化效率、迭代周期和成本仍有可改善的空间。
② 需要在多模态这一方向深耕细作。视频由多种模态组成,仅从视觉角度提取标签具有一定的片面性。只有更好地利用文本、视频、音频的信息,三者相辅相成,才能用标签更好地表达视频内容。
③ 在完善技术模型的前提下,尝试做出一些能吸引眼球的玩法。如视频智能剪裁、智能封面图等。这些有意思的功能和效果可用于提升用户体验、丰富产品。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
付超,北京美图之家资深视觉算法工程师,长期从事基于计算机视觉的内容理解工作。目前在美图负责美图社区的内容标签、内容质量、OCR 等多媒体内容理解工作。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:多媒体内容理解在美图社区的应用实践

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论