

本文内容来源于一流科技首席科学家袁进辉的演讲《让 AI 简单且强大:深度学习引擎 OneFlow 技术实践》,由作者本人授权转载。
研发 OneFlow 的动机
软件 OneFlow 简介
大家经常能到人工智能浪潮的三驾马车的说法,即数据、算法、算力。具体到算力,业界更多关注的是硬件,譬如 GPU,甚至是 TPU 等 AI 专用芯片。但是,我们发现,对于大规模分布式训练,制约算力的瓶颈是软件。怎么帮助数据科学家和研究员们更轻松的把各种算法在底层硬件上跑起来,而且把那些硬件用的最充分高效,这是软件需要解决的问题。
目前,已有的开源深度学习框架对于数据并行的场景解决的比较好,但对模型越来越大的场景就没有好的解决办法。用户或者束手无策,或者只能基于开源框架做深度定制开发来满足需求。我们团队的目标是做一个通用框架自动解决这些问题,让那些即使没有超算研发能力的团队也能够享受分布式 GPU 集群带来的效率,这就是我们历时两年多研发一套全新深度学习框架 OneFlow 的出发点。
背后的动机:计算力是深度学习发展的最重要的推动力
案例 :
2015 Microsoft Resnet
2016 Baidu Deep Speech 2
2017 Google NMT
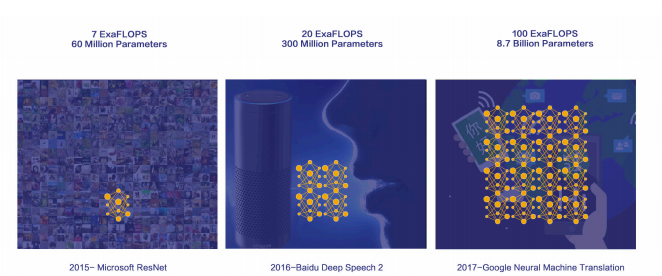
2015 年微软研究院发明的 ResNet 需要的计算量是 7 乘以 10 的 18 次方次计算(ExaFlops)。可以大概推算一下用一颗 24 核的 CPU 来计算,需要多久能完成这些计算,也可以推算用几千个核心的 GPU 来算需要多长时间。可能是需要几个月或几个星期的时间。除了计算量在增长,模型大小也在增长,譬如说 ResNet 这种 CNN 模型通常是几千万参数,需要几百兆的存储空间,百度此后研发的 Deep Speech 模型已经到了三亿参数,然后 Google 的机器翻译模型 NMT,已经到了几十亿参数,整个模型在一块 GPU 上已经放不下了。这种情况,数据并行也不能解决,需要模型并行或流水并行来解决分布式训练的问题。但是,目前还没有开源框架支持这些需求,也仅仅是巨头公司内部定制的系统才能支持这种需求。
解决问题需要一些特别的流水和模型手段

今年上半年 Facebook 发布了一个研究结果,用 35 亿张弱标注图片,使用几百块 GPU,经过接近一个月的时间,训练了一个用于图片分类的卷积神经网络模型,它能做到什么效果呢?能提高 6 个百分点的准确率。这是非常了不得的成绩,算法基本上没什么变化,仅仅是通过采用更多的数据和计算就能把 top-1 的准确率提高了 5 个百分点以上。通常,对于一个商业价值很高的场景,提高 0.5 个百分点可能是一个团队一年的 KPI。

九月份 Google 发表了 BigGAN 模型,通过提高图片的分辨率来提升效果,这就意味着 CNN 中间的 activation 和反向 gradient 会非常多,当然计算量也会大的非常多,基于 TPU 集群来完成训练。通过这个手段他同样获得了比以前的 GAN 模型好的多的效果。

上个月,Google 又发表了 BERT 模型,使用一种大的多的 transformer 模型,在 16 个 TPU 上训练了 4 天,然后基于这个语言模型作为主干网络去解决各种常见的自然语言处理问题,发现全面超越了以前的所有方法。很不幸,目前还没有出现在 GPU 集群上训练这种模型的办法,如果想在自己的业务里应用 BERT,只能去下载 Google 预训练好的模型,然后做少量微调来使用。即使是已经搭建了大规模的 GPU 集群的客户也无能为力,有钱也解决不了。
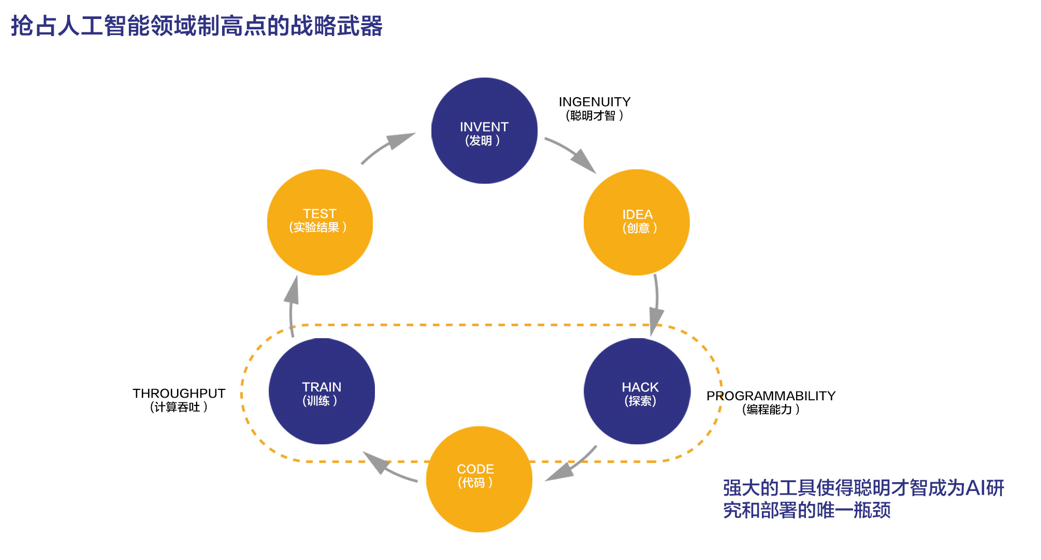
深度学习经过这几年的爆发式发展,特别引人注目的算法层面的创新越来越少了,今年比较吸引眼球的进步都来自于堆计算力,也就是人们常说的“大力出奇迹”的方式。怎么才能让更多的企业用户能享受到算力提升的红利,帮助算法科学家完成更多的 KPI, 这是我们 OneFlow 非常关心的问题。常言道,工欲善其事必先利其器,框架在深度学习研究和落地的过程中就扮演了“工具”的角色,好的工具能大大加速人工智能研发的效率,甚至可能成为行业竞争的决胜法宝。从 BigGAN 和 BERT 等例子也可以看出来,当一家公司掌握了其他人不掌握的工具时,就可以引领算法研究的潮流,反过来,当一家公司的基础设施跟不上的时候,也就没办法做前沿探索,即使是做研究也只能跟在 Google 后面,因此称深度学习框架是人工智能制高点的战略武器一点不为过。
基于纯硬件的解决思路
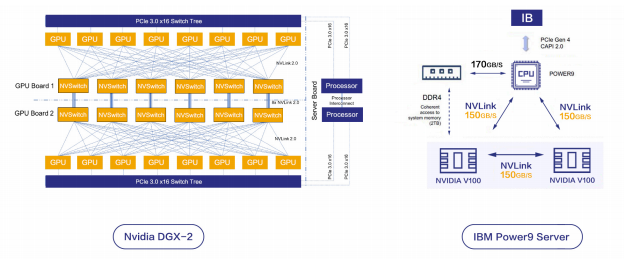
案例 :
Nvidia DGX-2
IBM Power9 Server
英伟达通过销售 GPU 成为这一波 AI 计算力红利的最大受益者,它除了把单个设备做的越来越快,还做了服务器架构方面的创新,出品了一系列超级计算盒子,每个盒子里面可以集成 8 个或者是 16 个计算力非常强的 GPU(譬如 DGX-1 是 P100,今年推出的 DGX-2 是 V100),更特别的是,这些 GPU 之间使用了非常高速的互联,能够实现 GPU 之间点对点 150GB 以上的传输带宽,比常见的 PCIe 带宽要高一个数量级。这种设计使得 DGX 服务器能够几乎使得 16 块 GPU 像一个单体芯片那样输出超强算力。
当然还有比 DGX 更特别的服务器,比如说 IBM 出的 Power9 Server,它的独特之处在于他的 CPU 使用了不同于 Intel x86 CPU 的架构,而且支持 CPU 和 GPU 之间 NV Link 互连,意味着 CPU 和 GPU 之间的数据传输也能够做到 100GB 以上的带宽。目前世界排名第一的超级计算机 Summit 就使用了类似 Power9 Server 的架构。
基于这么强的硬件就能解决计算力的问题吗?

IBM 和 Nvidia 一起搭建了世界上最强的超级计算机 Summit,一共用了 2 万多块 V100 GPU,还使用了最先进的互联技术(NvLink, Infiniband),要说最强的硬件,除了 TPU Cluster,应该没有更好的了,这是不是就够了呢?IBM 首席科学家在 ASPLOS(计算机体系结构顶级会议)上做了一个特邀报告,主题是“只有很强的硬件,没有很好的软件还是不能解决扩展问题”。现在国内拥有几千块 GPU 乃至上万块 GPU 的头部公司不在少数,但基于开源框架能训练 BERT-Large 模型吗?不行,这也是很多用户面临的软件瓶颈问题:购买了很多的硬件,但用不起来,或者说不能很好的用起来。
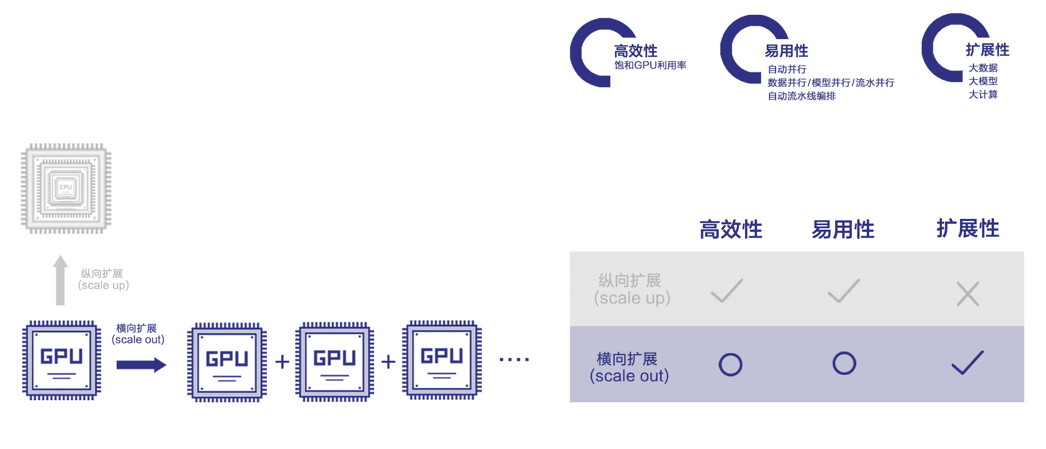
理念:纵向扩展与横向扩展
纵向扩展
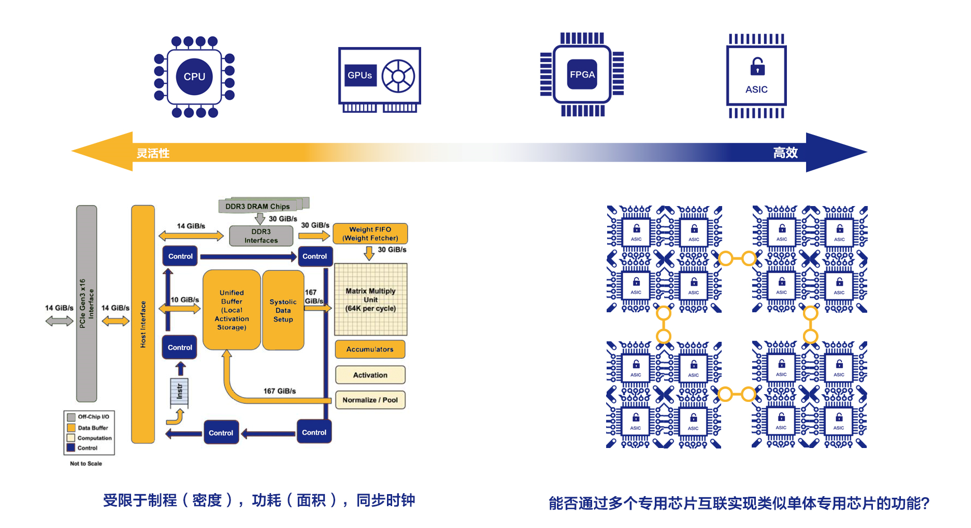
纵向扩展是通过把单个设备或者是单个机器做的越来越强,或通过编译器优化的手段让作业在一个设备上或者是一个机器内部把硬件性能发挥到极致来满足现在日益增长的计算需求。硬件从多核架构 CPU 发展到众核架构 GPU,GPU 从 P100 到 V100, 为了追求更高的效率,甚至研发 FPGA 或 ASIC 芯片来获得更高算力。
当前最知名的 AI 芯片是 Google 的 TPU,国内寒武纪,华为,阿里,百度等公司都在研发 AI 芯片。AI 芯片的主要问题是有物理限制(譬如制程,功耗,同步时钟等等约束),人们不能生产出计算力任意大的芯片。也有人把这个现象称为硅基扩展瓶颈(Silicon Scaling)。
除了提高一个芯片的吞吐率,像英伟达的 DGX 也是纵向扩展的例子,DGX 通过在一个机器内部通过高速互联手段实现芯片之间点对点极高的传输带宽,从而使得多芯片间协作起来更加高效。如果一台服务器内集成多个芯片仍不能满足需求,人们继续把多台服务器通过高速以太网或 Infiniband 连接起来组成集群来实现更高算力。理想情况下,如果能投入多少硬件资源,就得到多少计算力,那计算力瓶颈就迎刃而解了。
但是,一方面,芯片间互联带宽要比片内数据访问带宽低一到两个数量级,在芯片间搬运数据成为瓶颈,另一方面,编写在多芯片上高效运行的软件非常挑战,以深度学习为例,神经网络的结构不同,效率最高的并行方式(逻辑任务向物理计算单元的映射)也不同。这其实是横向扩展的核心挑战。
横向扩展
横向扩展是比纵向扩展更有前景的工作方向,但实现横向扩展的技术挑战更大。一个理想的横向扩展方案,不管底层实际使用了多少松散耦合在一起的芯片,在上层用户眼里就像在使用一个专门为一个任务打造的巨大的单体芯片一样,编程就像在单设备上编程,任务运行时能把底层每一个独立的芯片都利用充分。解决这个问题是软件框架的职责。
逻辑任务到物理拓扑之间的最优映射复杂多变
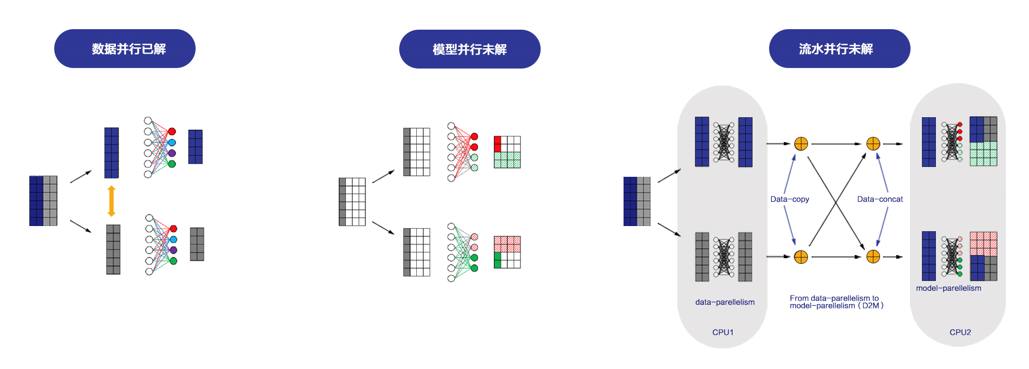
给定一个特定的神经网络模型和一批计算资源,有很多种映射方法都可以完成计算,但不同的映射方案运行效率不同,最优的映射方案依赖于作业本身的特性,也取决于底层硬件的拓扑。
神经网络由很多局部计算(通常称为 kernel)搭建组成,每一个局部计算是采用数据并行,还是模型并行取决于这个局部的计算传输比。现在业界讨论比较多的卷积运算参数量很小,但中间结果量大,最经济划算的方法是对数据进行切分,不同的设备处理不同的数据,在设备之间偶尔进行参数同步,这就是数据并行,这基本上是一个已经被解决的问题。还有一些运算,中间计算结果相对于参数量更少,就适合模型并行。还有一些网络参数量很大或中间计算结果都很大,可能采用流水并行(也就是接力的形式)是最优的。
模型并行和流水并行中通信的数据路由要比数据并行复杂,同时,怎么重叠计算和传输从而提高设备利用率也非常挑战,现有开源框架对这些更复杂的并行模式的支持还很初级。。
通信密集,延迟敏感
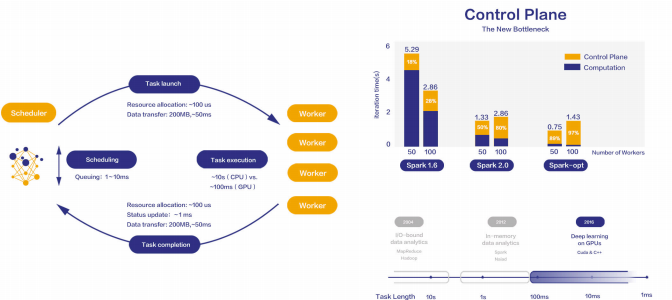
左图展示了一个常见的大数据处理引擎的架构,集群中的计算资源一般分成用于中心调度的 Master 节点和用于处理数据的 Worker 节点。
Master 节点以有向无环图的方式管理整个作业的进度,同时监控所有 Worker 的资源使用状况,在合适的时机把一个子任务(Task)分配给某个 Worker 去做,某个 Worker 在完成一个子任务之后,会向 Master 节点汇报,等待 Master 分配新的任务。
在传统大数据处理中,一个 Worker 执行一个子任务的时间量级一般在几十秒钟或数分钟,一般发生在 Master 节点那里的排队开销,Master 和 Worker 之间对话的时间开销,以及数据传输开销都是数十毫秒,相对于 Worker 的工作时间可以被忽略。
但是在像深度学习训练一样的流式计算任务里,数据处理时间越来越短,每个子任务可能是几百毫秒就完成了,在这种情况下,几十乃至几百毫秒的开销就非常显著,如果不能通过技术手段把这些开销消除或掩盖掉,整个系统的性能就非常低。
OneFlow 技术突破
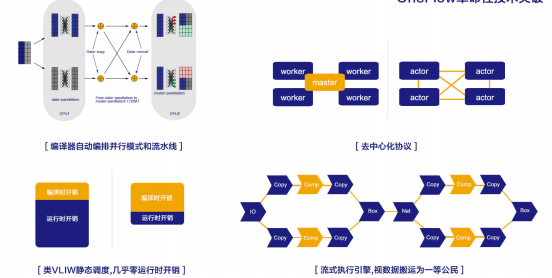
为了对任一给定作业和资源都达到类似巨大单体专用芯片的效果,OneFlow 首创了静态调度(左图)和流式执行(右图)的深度学习框架。
静态调度是什么思路呢?它来自于计算机体系结构。
我们熟知的 CPU 芯片中大部分面积在做乱序执行,流水线和缓冲区的管理,真正做算术运算只占很小的一片。学界和工业界很久以前就开始探索怎么让芯片的有效面积尽可能多的做算术运算,静态调度应运而生,基本思路是把流水管理指令排布之类的工作从硬件转移至编译器,这样硬件复杂度就大幅降低,当然相应的编译器肯定复杂度会提高很多。有一个叫 VLIW(超长指令集架构)的指令集就采用了这种思路。
OneFlow 的静态调度体现在两方面,首先,编译器自动解决从逻辑任务到硬件资源的映射问题,包括数据并行,模型并行,流水并行的设备分配以及数据路由方案,这样就大大降低了分布式编程的复杂度,用户只需要关心任务的逻辑结构以及本次任务可使用的硬件资源,而不用去编程管理数据在硬件资源中的流动;其次,静态调度把所有能在静态分析阶段提取出来的调度策略,资源管理策略等问题都在编译阶段解决,运行时就不需要在线求解最优的调度方案,可以大大降低运行时开销。
经过静态编译,每个设备负责运行的子任务是预先可知的,每个子任务的上下游依赖也预先可知,在运行任务时,就不再需要中心调度器,只需要实现上下游任务之间局部的握手信号即可,即生产者向消费者发送的请求以及消费者向生产者发送的确认,整个系统以全链路异步的方式运行。这个思路也来自于芯片设计里一种叫异步电路的技术。
OneFlow 另一个区别于其它深度学习框架的特色是视数据搬运为一等公民,在静态分析阶段就把磁盘 IO,主存和设备之间数据搬运,节点间数据搬运看作和计算同等重要的任务,在代价分析和调度策略里作为一等公民进行建模,只有这种显式建模分析,才能得到重叠传输和计算的最优方案。OneFlow 编译器相当于网络的控制平面,用于获取数据计算和转发策略,运行时相当于网络的数据平面,执行体依照控制层面的策略去转发和处理数据。
竞品对比
OneFlow 历经两年的研发,2018 年 10 月份才推出 1.0 版本,还是一个很年轻的系统,目前正在客户的生产环境里面试用和迭代。实事求是的讲,我们在模型的丰富程度,易用性,多语言支持等方面还有比较大的提升空间。但是,不谦虚的讲,OneFlow 在大规模,企业级应用上是最领先的,分布式最容易使用,用户在写程序的时候是感受不到多机和单机的区别的。OneFlow 支持数据并行,模型并行和流水并行,而其它框架只支持最容易支持的数据并行。OneFlow 在分布式训练时的扩展能力,加速比是最优秀的。这些特点也正是 OneFlow 作为企业级深度学习框架比已有开源深度学习框架优秀的地方。

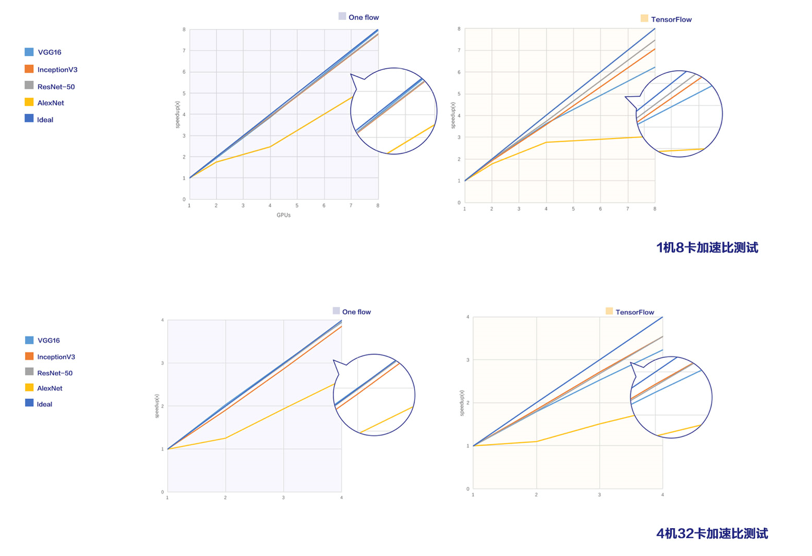
卷积神经网络(CNN)作为最容易解决的一个问题,经常被拿来评测深度学习框架性能。有的公司用数据并行方法,对于 ResNet 已经可以用数千块 GPU 做到几分钟就训练好 ImageNet 上的模型。在日常工作中,上层使用 Horovod,底层使用 Nvidia NCCL 已经可以做到很漂亮的结果。
需要注意的是,以前社区有一个错误认识是 TensorFlow 并行做的不好,速度比其它框架慢,实际上今天已经不是这样了,TensorFlow 有一个 benchmark 项目(https://github.com/tensorflow/benchmarks )针对 CNN 做了很多优化,做数据并行已经是开源框架里最优秀之一了。我们使用完全一样的算法和硬件(V100 GPU, 100Gbps RDMA 网络),和 TensorFlow benchmark 对比会发现,无论是基于单机多卡,还是多机多卡都是比 TensorFlow 快。上图左边是 OneFlow,右边是 TensorFlow,除了 AlexNet 遇到硬件瓶颈,OneFlow 都能做到线性加速,TensorFlow 在单机多卡和多机多卡上与 OneFlow 还是有一定的差距。
阿姆达尔定律
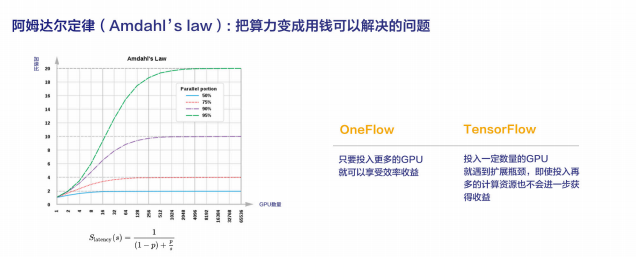
上面的评测结果中,在 32 卡时,OneFlow 仍是线性加速,当卡数增加到一定程度,譬如几百或者是上千时迟早会遇到天花板。并行效率不同的系统,只是遇到天花板时间早晚的问题,这是阿姆达尔定律所揭示的规律。
比如说上图绿色曲线表示一个并行度(parallel portion)为 95%的任务,什么时候遇到天花板呢?可以计算出来,加速到 20 倍的时候就到了天花板了,后面再投入再多的资源进去它也不可能再加速了。
假设系统的并行度不随卡数变化,在卡数少时,大部分系统还是比较接近线性的,各个系统之间差别很小,但当卡数增多时,系统迟早会遇到天花板,即使增加再多的 GPU 也不会进一步提升吞吐率。
这表明,在卡数比较少时实现线性加速比不一定能在卡很多时还能实现线性加速,但在卡数较少时就实现不了线性加速,在卡数更多时肯定距离线性加速更远。由此可见,把系统的运行时开销优化到极致,对于大规模集群训练效率是至关重要的。
人无我有,分布式训练 BERT-Large 模型
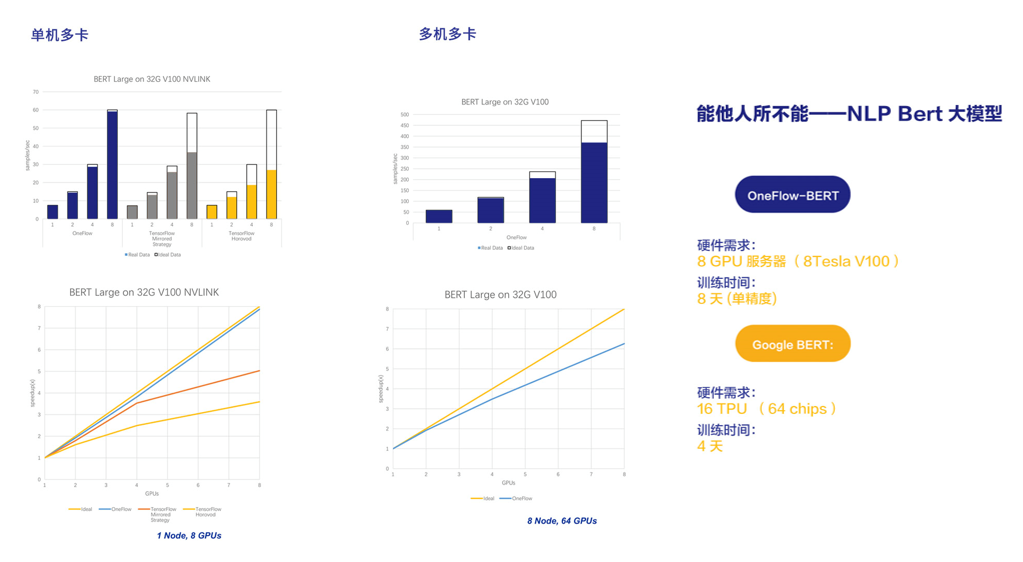
BERT-Large 是谷歌最近推出的一个学习语言模型的大型神经网络,基本上在常见的自然语言处理任务上都做到了 state of the art,显著超越了以前的一些方法。
BERT-large 有 24 层,整个的模型大概 1.3G,每一层中间结果都蛮大的,如果不做内存优化,对于 32GB 显存的 V100,一次也就处理八九个句子。这个模型可以说是个大杀器,但客户想基于自己语料重新训练一个 BERT-Large 模型,却不可能。
谷歌在 TPU Cluster 上用 16 个 TPU 训练 BERT-Large 需要 4 天时间。没有 TPU 的用户,只能使用 GPU,即使几十块 V100 也需要半个月时间,而且现在还没有开源的分布式解决方案,谷歌放出来 TensorFlow 代码只支持单 GPU 卡,如果用户做一些定制去支持分布式,很遗憾,加速比也很不理想。
如左上角图所示,即使是在有 NVLink 互联的单机八卡服务器上,TensorFlow 也只能实现四五倍的加速,按这种加速比去推算一下,即使是使用几十块 V100 也是需要一个月以上的时间。
在 Google BERT 论文发表后不久,我们团队就基于 OneFlow 实现了和 TensorFlow BERT 一样准确率的实现,在单机八卡服务器上数据并行接近线性加速,在八机 64 卡的配置下,也能跑到 50 倍以上的加速比,这还不是线性加速比,我们正在做一些优化工作,不久以后对于 BERT-Large 在多机多卡也能实现线性加速比。
OneFlow 现在的实现在单精度条件下只需要 8 天就能训练出来 BERT-Large 模型,如果加上半精度支持,时间会再缩短一半,只需要三四天。需要指出的是,Google BERT 的词典只有 4 万个单词,当词表达到几十万或上百万级别时,embedding 层就无法用数据并行计算了,必须做模型并行,而后续的层次可以继续使用数据并行,也就是混合并行,OneFlow 可以很方便的支持起来。
最近,我们已经开始为几家头部互联网公司提供 BERT 训练服务,在客户自己的数据集上训练 BERT-Large 模型。
除了最近推出的 BERT,业界实际上还有很多大模型的问题,不幸的是,还没有开源深度学习框架可以支持模型并行和流水并行。以训练安防领域的大规模人脸识别模型为例,当人脸类别达到百万级时,最后的 Softmax 层必须使用模型并行,要解决这个问题,用户就必须深度的 hack 已有开源框架,此时会面临易用性和高效性的难题。
词嵌入和广告/推荐系统领域也存在许多大模型的问题,模型容量可达几十 GB 甚至几百 GB 乃至 TB,也只有少数头部企业不计研发成本才能做一些定制开发来支持这些需求。OneFlow 可以很方便高效的支持这些需求,大大节省用户成本,帮助用户完成以前搞不定的事情。
总 结
我们认为框架领域最重要最难的问题是横向扩展,从研发 OneFlow 之初,就立下解决这个业界公认难题的目标,我们历时两年多,探索出一条区别于其它框架的路径,解决了一系列技术难题,实现了比其它开源深度学习框架效率高很多的分布式深度学习框架,我们深信现在 OneFlow 的技术路线是解决深度学习横向扩展难题的必由之路。我们看到技术社区其它团队已经开始探索我们描述的这种技术路线。
一路走来,我们深切体会了“do right things, do things right”如此重要。真正有价值的事都是长跑,除了技术因素,情怀和坚持也必不可少
作者介绍
袁进辉,北京一流科技有限公司创始人,任首席科学家。
2010 年负责研发的斯诺克比赛“鹰眼”系统打败来自英国的竞争产品,服务于各项国际大赛,并被中国国家队作为日常训练的辅助系统。
2012 年作为早期成员加入 360 搜索创业团队,一年后产品上线成为国内市场份额第二的搜索引擎。
2013 年加入微软亚洲研究院从事大规模机器学习平台的研发工作。
2014 年发明了当时世界上最快的主题模型训练算法和系统 LightLDA,只用数十台服务器即可完成以前数千台服务器才能实现的大规模主题模型,该技术成功应用于微软在线广告系统,被当时主管研究的全球副总裁周以真称为“年度最好成果”。
2015 年至 2016 年底,专注于搭建基于异构集群的深度学习平台,项目荣获微软亚洲研究院院长特别奖。
2017 年创立北京一流科技有限公司,致力于打造分布式深度学习平台的事实工业标准。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论