

随着机器学习 (ML) 在公司核心业务中占据的份量越来越重,缩短从模型创建到部署的时间就变得越来越重要。2019 年 11 月,AWS 发布了适用于 Amazon SageMaker 的 AWS Step Functions Data Science SDK,开发人员可以通过这款开源开发工具包用 Python 创建基于 Step Functions 的机器学习工作流。现在,您可以使用与模型开发所用的同款工具创建可重复使用的模型部署工作流。您可以在 GitHub仓库的 “automate_model_retraining_workflow” 文件夹中找到此解决方案的完整手册。
本文以一个常见的使用案例“模型的定期重新训练和部署”来演示 Data Science SDK 的功能。在本文中,您将创建一个基于无服务器架构的工作流,用于训练机器学习模型、使用验证数据集检查模型的性能并在模型准确度超过设定阈值时将模型部署到生产环境中。最后,本文介绍了如何定期触发工作流。
下图演示了上述 AWS Step Functions 无服务器架构工作流。

本博文使用以下 AWS 服务:
AWS Step Functions 使您能够将多个 AWS 服务整合到一个无服务器架构工作流中。您可以设计并执行工作流,其中,一个步骤的输出作为下一个步骤的输入,并支持将错误处理嵌入到工作流中。
Amazon SageMaker 是一项完全托管的服务,可以为开发人员和数据科学家提供构建、训练和部署不同类型机器学习模型时所需的工具。
AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务。您可以将 AWS Glue 指向受支持的数据存储,它将会生成代码以从指定的存储中提取数据并加载到目标存储中。AWS Glue 在分布式 Apache Spark 环境中运行,这使您能够充分利用 Spark,而无需管理基础设施。
AWS Lambda 是一项让您在运行代码时无需预置或管理服务器的计算服务。仅当被触发时 Lambda 才会执行您的代码,并且支持自动扩展,每秒可处理数千个请求。
Amazon EventBridge 是一项无服务器事件总线服务,通过它可以轻松连接不同的 SaaS 应用程序、AWS 服务和应用程序中的数据。
SDK 概述
此 SDK 提供一种新的 AWS Step Functions 使用方式。一个 Step Function 是由多个离散步骤组成的状态机,其中,每个步骤都可以执行任务、作出选择、启动并行执行或管理超时。您可以开发单独的步骤并使用 Step Functions 来处理整个工作流的触发、协调和状态管理。在 Data Science SDK 诞生之前,您只能使用基于 JSON 的 Amazon States Language 定义 Step Functions。现在,您可以借助此 SDK 使用 Python 代码轻松创建、执行和可视化 Step Functions。
本文提供了此 SDK 的概述,包括如何创建 Step Function 步骤、使用参数、集成服务特定的功能以及将这些步骤关联在一起以创建和可视化工作流。您可以在本文中找到多个示例代码;同时,我们也为整个流程创建了详细的 Amazon SageMaker 笔记本。有关更多信息,请参阅 GitHub仓库。
步骤、参数和动态工作流
在 Step Function 中,每个步骤均会将其输出传递至下一个步骤。您可以在后续的步骤中使用这些输出来创建动态工作流。此外,您还可以在执行 Step Function 时传入参数,实现工作流的通用性,以便其支持其他项目。
要使用此 SDK 为工作流定义所需的输入参数,请参阅以下代码:
内置服务集成
Data Science SDK 可与多项 AWS 服务集成。这些集成使您能够直接控制受支持的服务,而无需去写 API 调用代码。本文将会与 AWS Glue、Lambda 及 Amazon SageMaker 服务相集成。有关更多信息,请参阅 AWS Step Functions 服务集成。
在模型重新训练之前,您首先需要获取到最新的数据。此外,您还需要丰富原始数据,同时将其保存到 ML 模型支持的文件类型和位置。AWS Glue 用于连接大部分数据存储,也支持自定义的 Python 脚本并且无需管理服务器。作为您工作流的第一步,您可以用 AWS Glue 读取生产数据并将转换好的数据写入 Amazon S3 中。
通过 Data Science SDK 可以轻松向工作流添加 AWS Glue 作业。AWS Glue 作业本身可指定数据源位置、ETL 的 Python 代码以及目标文件存放位置。此 SDK 需要的只是 AWS Glue 作业的名称,以此作为 GlueStartJobRunStep 的参数。有关更多信息,请参阅 YouTube 上的 AWS Glue ETL 入门。
您可以使用输入参数,在运行的时候选择 AWS Glue 作业:
在提取并保存输入数据之后,您可以使用此 SDK 的 TrainingStep 来训练模型。Amazon SageMaker 会处理底层计算资源,但您需要为训练指定算法、超参数和数据源。请参阅以下代码:
上述代码中的估算器 xgb 封装了 XGBoost 算法及其超参数。有关如何定义估算器的更多信息,请参阅 GitHub仓库。
在模型训练完成之前,Step Function 工作流将一直停留在该训练步骤。在训练完成之后,需要获取训练结果,以便工作流可以根据新模型的准确度选择分支。为了查看 Amazon SageMaker 的训练作业和返回结果,可使用 Step Functions LambdaStep 来调用 Lambda 运行一个简单的 Python 函数。要通过 SDK 添加 Lambda 状态,请指定函数名称和 Payload。本文使用 JSON 路径来选择 Lambda 函数负载中的 TrainingJobName,然后,它才能知道要查询的训练作业是哪个。请参阅以下代码:
要部署训练好的模型,您可使用 SDK 中的 ModelStep 和 EndpointConfigStep 创建一个模型对象和部署配置。请参阅以下代码:
最后,工作流使用 EndpointStep 以托管 API 终端节点的形式部署新模型。通过“update”参数可以实现更新已有的 Amazon SageMaker 终端节点,而不是创建新的终端节点。请参阅以下代码:
控制流和关联状态
Step Functions SDK 的Choice状态支持基于前面步骤的输出创建分支逻辑。您可以通过添加此状态来创建复杂的动态工作流。
本文会创建一个步骤,其可根据您在 Amazon SageMaker 训练步骤中得到的结果选择分支。请参阅以下代码:
check_accuracy_step = steps.states.Choice(
‘Accuracy > 90%’
)
向步骤添加分支和分支逻辑。Choice 状态支持多种数据类型和复合布尔表达式,但是,在本文中,您只需要比较两个数值。第一个值是设置好的阈值 0.90,第二个是 TrainingStep 中的验证数据集上的模型准确度。训练结果的模型错误率计算方式为(错误数)/(总数)。因此,如果测得的错误低于 10% (0.10),则表示模型准确度高于 90%。
有关更多信息,请参阅Choice规则。
添加以下比较规则:
工作流中的 Choice 规则需要设定当条件被满足时要执行的下一个步骤。到目前为止,您已创建了多个步骤,但尚未设定他们的执行顺序。您可以借助 SDK 以两种不同的方式将步骤关联在一起。
方式一:使用 next() 方法为单独的步骤指定下一个步骤,代码如下:
方式二:使用 Chain() 方法一次将多个步骤关联在一起,代码如下:
工作流创建
在确定好所有步骤的定义及执行顺序之后,使用以下代码创建 Step Function:
创建工作流之后,workflow.render_graph() 将返回工作流的示意图,与您在 Step Functions 控制台中看到的类似:
现在,您已准备就绪,可随时运行新的部署流程。您可以使用 SDK 中的 execute() 方法来手动运行模型,也可以通过自动化的方式执行此任务。
使用 EventBridge 触发器安排工作流
您可以使用 EventBridge 触发器设置工作流的执行计划。本文介绍了如何在 EventBridge 中创建一个规则,以按计划调用 Step Function。有关更多信息,请查阅创建一个由AWS 资源产生的事件触发的 EventBridge 规则。
请执行以下步骤:
在 AWS 管理控制台的服务下,选择 Amazon EventBridge。
选择规则。
选择创建规则。
在名称和描述下,对于名称,输入规则的名称。本文输入的名称为
automate-model-retraining-trigger。对于描述,可以输入步骤的描述,也可以留空。
对于定义模式,选择计划。
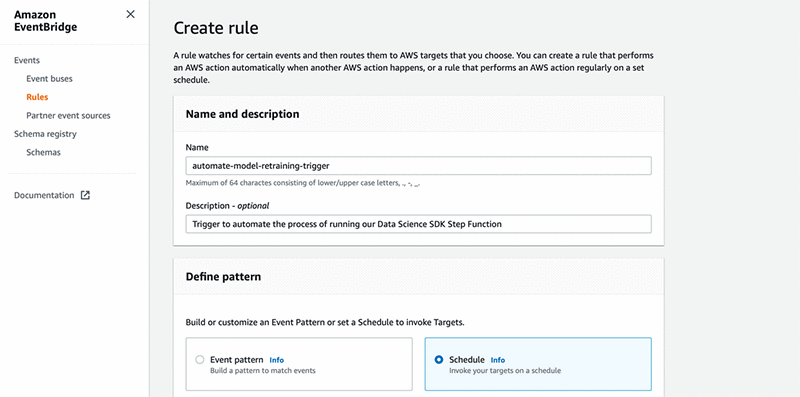
7. 对于固定匹配为每隔,选择 1 小时。
8. 在选择事件总线下,选择 AWS 默认事件总线。
9. 选择启用 在选定的事件总线上启用该规则。
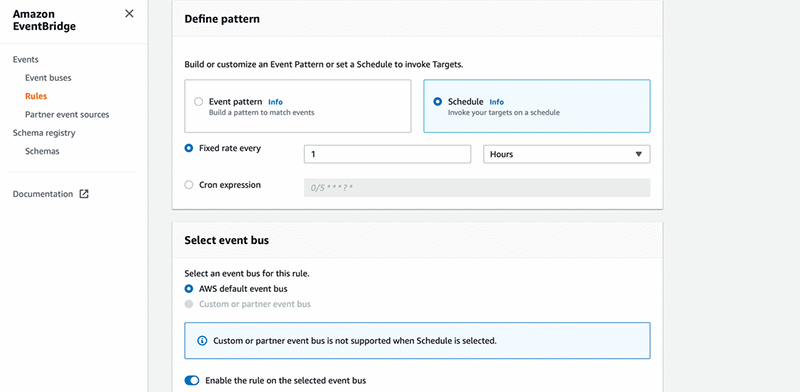
10. 在选择目标下,对于目标,选择 Step Functions 状态机。
11. 对于状态机,选择您的状态机。
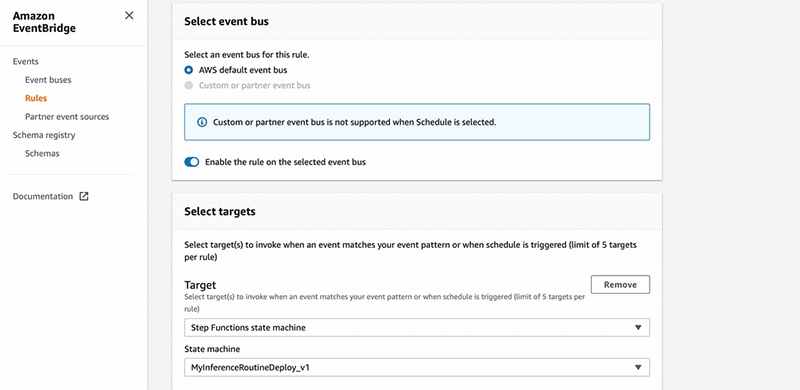
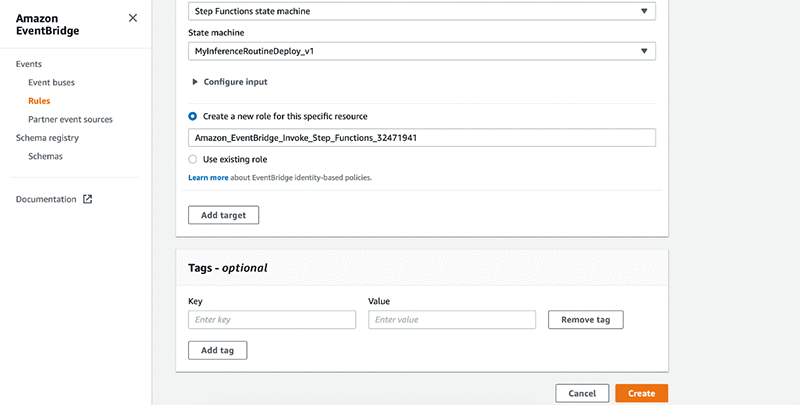
12. 依次选择配置输入、常量(JSON 文本)。
13. 以 JSON 文本的形式为工作流输入输入参数。
14. 选择为此特定资源创建新角色。
15. 输入角色名称。如果已有角色,则选择使用现有角色。
16. 选择创建。
总结
本文介绍了适用于 Amazon SageMaker 的 AWS Step Functions Data Science SDK,并展示了使用 Python 创建可重复使用的模型部署工作流的过程。该工作流中包含:用于提取和转换数据的 AWS Glue 作业、使用新数据训练您的机器学习模型的训练步骤、通过 Lambda 查询训练结果的步骤、创建模型构件的步骤、用于定义部署参数的终端节点配置步骤和部署新模型到现有终端节点的步骤。最后,演示了使用 EventBridge 实现定期触发工作流的方法。
如需与此 SDK 相关的其他技术文档和示例手册,请参阅适用于 Amazon SageMaker 的 AWS Step Functions Data Science SDK 公告。
本文转载自 AWS 技术博客。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论