

Spotify 是一家在线音乐流服务平台,2006 年 4 月由 Daniel Ek 和 Martin Lorentzon 在瑞典创立。目前是全球最大的流音乐服务商之一,与环球音乐集团、索尼音乐娱乐、华纳音乐集团和腾讯音乐娱乐集团四大唱片公司及其它唱片公司合作授权、由数字版权管理保护的音乐,用户规模截至 2019 年 10 月有 2.48 亿。Spotify 采用免费增值模式,基本服务是免费的,而附加功能是通过付费订阅提供。Spotify 靠流媒体订阅 Premium 用户和第三方的广告来作为其营收收入。本文介绍了 Spotify 过去一年最大一次数据流作业优化实践。
本文,我们将讨论 Spotify 如何使用 Sort Merge Bucket(排序合并桶,SMB)联接技术优化和加速 Dataflow 作业Wrapped 2019中的元素,以用于Wrapped 2020。本文介绍了 SMB 的设计和实现,以及如何将 SMB 集成到数据管道中。
引言
Shuffle 是许多大型数据转换,例如 join、GroupByKey 或其他 reduce 操作的核心构件。遗憾的是,这也是许多管道中最昂贵的一步。SortMergeBucket 是一种通过在生产者端做预先工作来减少 Shuffle 的优化。直观地说,对于经常添加到已知 key 上的常见数据集,例如,用户 ID 上包含元数据的用户事件,我们可以将其写到 bucket 文件中,并根据该 key 记录进行分桶和排序。shuffle 知道哪些文件包含 key 的子集和次序,就可以从匹配的 bucket 文件中合并排序值,从而完全消除移动 Key-value 对代价高昂的磁盘和网络 I/O。Andrea Nardelli 在2018 年的硕士论文中进行了关于 Sort Merge Bucket 的最初研究,之后我们开始研究将这个想法推广为Scio 模块。
设计与实现
Spotify 的大部分数据管道都是用Scio编写的,Scio 是Apache Beam的 Scala API,它在Google Cloud Dataflow服务上运行。我们用 Java 实现了 SMB,以更接近原生的 Beam SDK(甚至与 Beam 社区一起编写并合作了一份设计文档),和其他许多 I/O 一样, Scio 也提供了语法糖 Scala。 这个设计被模块化到以下所列的主要组件中——我们将从两个顶级 SMBPTransform开始: SortedBucketSink 和 SortedBucketSource 的写和读操作。
SortedBucketSink
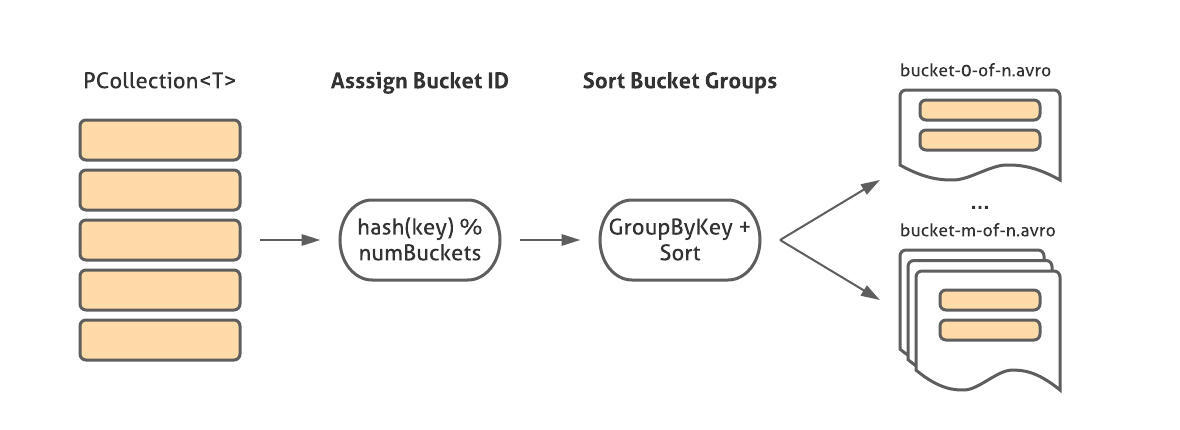
这个转换以 SMB 格式写入一个 PCollection<T>(其中 T 有一个对应的 FileOperations<T> 实例)。它首先使用BucketMetadata提供的逻辑提取 Key 和分配 bucket ID,按 ID 对 key-values 进行分组,对所有 values 进行排序,然后使用 FileOperations 实例将它们写入与 bucket ID 相对应的文件中。
除了 bucket 文件之外,还将一个 JSON 文件写入输出目录,这代表从 BucketMetadata 读取源所需的信息:bucket 的数量、散列方案以及从每条记录中提取 key 的指令(例如,对于 Avro 记录,我们可以用包含 key 的 GenericRecord 字段的名称来对该指令进行编码)。
SortedBucketSource
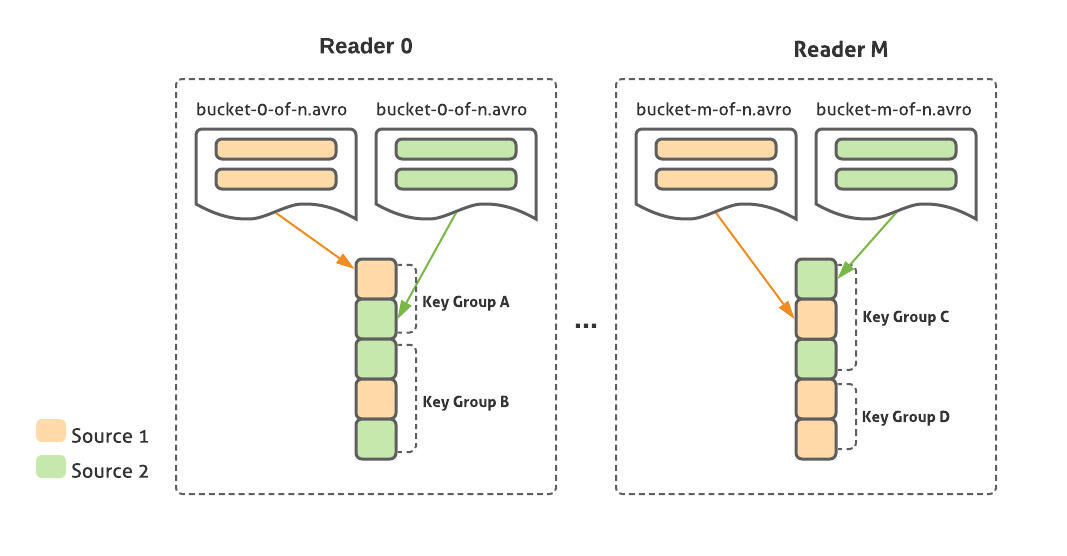
该转换是从一个或多个 SMB 格式的源读取,使用相同的 key 和散列方案编写。它打开了来自每个源的相应 bucket 的文件句柄(使用该输入类型的 FileOperations<T>),并在保持排序的同时合并它们。这些结果作为 CoGbkResult 对象在每个 key 组中发出,就像 Beam 用于常规 Cogroup 操作的类一样,这样用户就可以使用正确的参数来提取每个源的结果。
FileOperations
FileOperations 抽象化了单个 bucket 文件的读写。因为我们需要精确地控制每个文件中的元素及其顺序,因此我们无法利用现有 Beam 文件 I/O,因为它们是在 PCollection 层上操作的,元素的位置和顺序也被抽象出来。取而代之的是, SMB 文件操作是在 BoundedSource(输入)和 ParDo(输出)的 底层进行的。当前, Avro、 BigQuery TableRow JSON 和 TensorFlow TFRecord/Example 记录得到了支持。我们还打算添加其他格式,如 Parquet。
BucketMetadata
该类对元素的 keying 和 bucketing 进行了抽象,包含诸如 key 字段、类、 bucket 的数量,碎片和散列函数。在写入时,元数据与数据文件一起序列化为 JSON 文件,用于在读取 SMB 源代码时检查兼容性。
优化和变体
在过去一年半的时间里,我们在 Spotify 的各种用例中采用了 SMB,并且在处理数据管道的规模和复杂性方面做了很多改进。
日期分区:在 Spotify,事件数据以小时或日分区的方式写入 Google Cloud Services(GCS)。一个常见的数据工程用例是通过管道读取多个分区:例如,计算过去七天的流计数。这在单一 PTransform 中很容易实现,可以通过使用通配符文件模式来匹配跨多个目录的文件,从而实现非 SMB 读取。但是,与 Beam 中的大多数文件 I/O 不同, SMBRead API 要求以目录而非文件模式来指定输入(因为我们需要检查目录中的 metadata. json 文件以及实际的记录文件)。另外,它必须匹配不同分区和不同源的 bucket 文件,同时确保 CoGbkResult 的输出能够正确地将来自一个源的所有分区的数据分组到同一个 TupleTag key 中。在 SMBRead API 上我们做了改进,可以为每个源接收一个或多个目录。
分片:虽然我们在 bucket 分配过程中使用的 Murmur 类散列函数通常可以确保记录在分片 bucket 时均匀分布,但在某些情况下,如果 key 空间倾斜,一个或多个 bucket 可能会不成比例地大,并且在分组和排序记录时可能会出现 OOM 错误。在这种情况下,我们允许用户指定一些碎片来进一步分片每个 bucket 文件。在 bucket 分配步骤中,每个 bundle 会随机生成一个介于 [0,numShards) 之间的值。由于这个值是与 bucket ID 完全正交计算的,所以它可以在不同文件之间拆分大的 key 组。因为每个 shard 仍然是按排序顺序写入的,所以在读的时候只需将它们组合起来就行了。
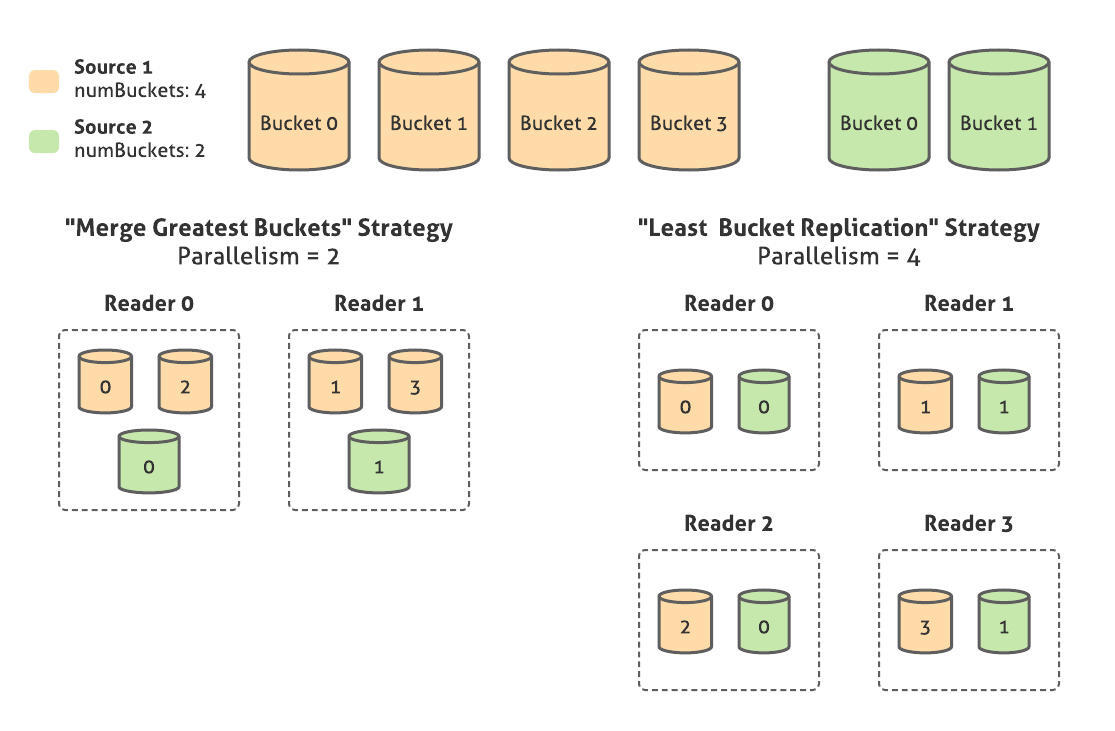
并行性:由于 SMB sink 中的 bucket 数总是 2 的幂数,所以我们可以根据用户指定的所需的并行度来制定不同 bucket 数的源的连接方案。举例来说,如果用户想用 4 个 bucket 联接 Source 1,用 2 个 bucket 联接 Source 2,则可以指定其中之一:
最低限度的并行性,或“合并最大的 bucket”策略:将创建 2 个并行的读取器。每个读取器将从源 A 读取 2 个桶,从源 B 读取 1 个桶,将它们合并在一起。因为 bucket ID 是通过取 key 的整数散列值模数所需的 bucket 数量来分配的,所以从数学上讲,合并后的 bucket 的 key 空间是重叠的。
最大限度的并行性,即“最少 bucket 复制”策略。将创建 4 个并行的读取器。每个读取器将从源 A 中读取 1 个 bucket,从源 B 中读取 1 个 bucket,在合并每个 key 组后,读取器将不得不对 key 进行最大数量的 bucket 为模数的重新散列,以避免发出重复值。因此,即使这种策略实现了较高的并行性,仍有一些计算重复值和重新散列的开销来消除重复值。
自动并行。基于 Runner 提供的运行时所需的分割大小值,在最小和最大数量之间创建若干个读取器。
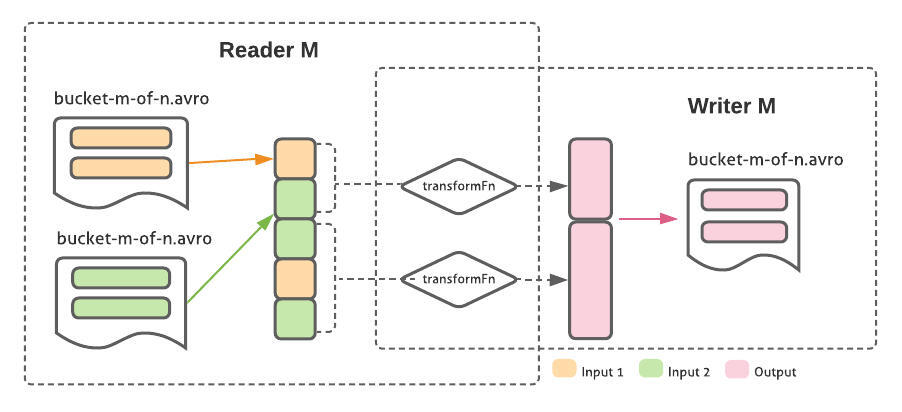
SortedBucketTransform:一个常见的使用模式是,管道丰富了现有的数据集,方法是将一个已有数据集与一个或多个其他源进行连接,然后将其写入输出位置。在 SMB 中,我们决定使用一种独特的 PTransform 对此进行专门的支持,该 PTransform 使用相同的 keying 和 bucketing 模式对输出进行读取、转换和写入。使用同一个 worker 对每个 bucket 进行读取/转换/写入逻辑操作,就可以避免对 bucket 的数据进行重新洗牌数据和计算:由于 key 是相同的,因此我们知道从输入的 bucket M 中转换的元素在输出中也对应 bucket M,与其读取顺序相同。
外部排序:我们对 Beam 的外部排序器扩展做了很多改进,包括用原生文件 I/O 替换 Hadoop 序列文件,解除 2GB 内存限制,减少磁盘使用和编码器开销。
采用核心数据生产者
因为 SMB 需要以一种特殊的方式对数据进行分类和排序,采用自然是从那个数据的生产者开始。大多数 Spotify 的数据处理依赖于几个核心数据集,它们是各个业务领域的真实数据源,例如流媒体活动、用户元数据和流上下文。为了把一年的数据转换成 SMB 格式,我们和数据集维护者一起工作。
由于 SortedBucketSink 主要通过一些额外的设置来替换 vanilla Avro sink,因此实现起来很简单。利用 Avrosink 的 sharding 选项可以控制输出文件的数量和大小。在迁移到 SMB 之后,我们没有注意到 vCPU、 vRAM 或实际时间的任何显著变化,因为分片需要一个完整的 shuffle,这与 SMB sink 的额外成本相似。我们随后还必须调整其他一些设置:
同意将 user_id 作为一个十六进制字符串作为 bucket 和排序 key,因为我们需要在所有 SMB 数据集中使用相同的 key 类型和语义。
将压缩设置为 DEFLATE,级别为 6,与 Scio 中默认的 Avro sink 保持一致。作为数据被 bucket 化并按 key 排序的一个很好的副作用,我们观察到,由于类似记录的配置,良好的压缩会使存储量减少 50%。
确保输出文件向后兼容。在 SMB 输出文件的名称中,除了“bucket-X-shard-Y”外,还包含了相同模式的记录。这样,就可以使用已有的管道,而无需更改任何代码;它们只是在某些连接情况下没有利用加速功能。
采用 Wrapped 2020
一旦核心数据集以 SMB 格式提供,我们就开始 Wrapped 2020,建立在 Wrapped 2019 活动留下的工作基础上。设计这个架构是为了可重用,这是好的开始。然而,数据源是一个大型、昂贵的 Bigtable 集群,必须进一步扩大规模以处理 Wrapped 作业的负载。通过将 Bigtable 迁移到 SMB 源,我们希望节省成本和时间。今年我们还需要处理过滤和聚合流的新的复杂需求。这样就需要在用户的监听历史中添加一个包含流上下文信息的大数据集。因为每一个联接都有很大的规模,所以这几乎是不可能的,或者至少是非常昂贵的。取而代之的是,我们试图使用 SMB 来完全消除此连接,并避免将 Bigtable 用作监听历史的源。
为了计算 Wrapped 2020,我们必须从三个主要数据源读取流媒体活动、用户元数据以及流媒体上下文。这三个源拥有我们需要的所有数据来生成每个人的 Wrapped,同时根据监听背景进行过滤。在此之前,Bigtable 中已经有 5 年的监听历史记录,并通过 user_id 进行了按 key 排序。现在,我们可以通过 SMB 从这三个源读取已经按 user_id key 进行排序的数据。然后,我们将每个 key 一年的数据进行汇总,计算出每个用户的 Wrapped。
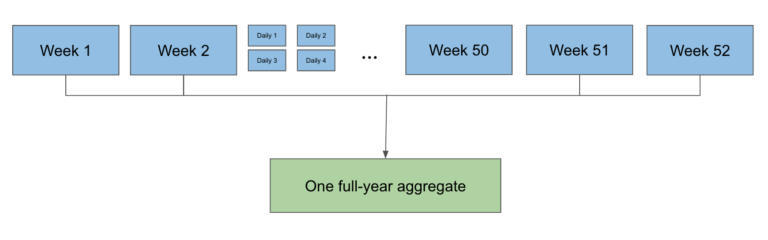
由于 3 个主要源中有 1 个是按小时分区的,而另外 2 个是按日分区的,所以在一个作业中读一年的数据是有问题的,因为按小时分区的数据源有很多并行读取。取而代之的是,我们先运行一些较小的作业,这些作业会汇总出每个用户每周或每天的播放次数、 播放毫秒和其他信息。然后,我们再把所有这些更小的分区汇总成一个数据分区,这个数据分区将保存一年。
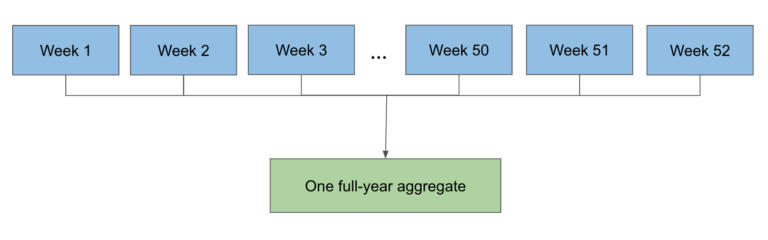
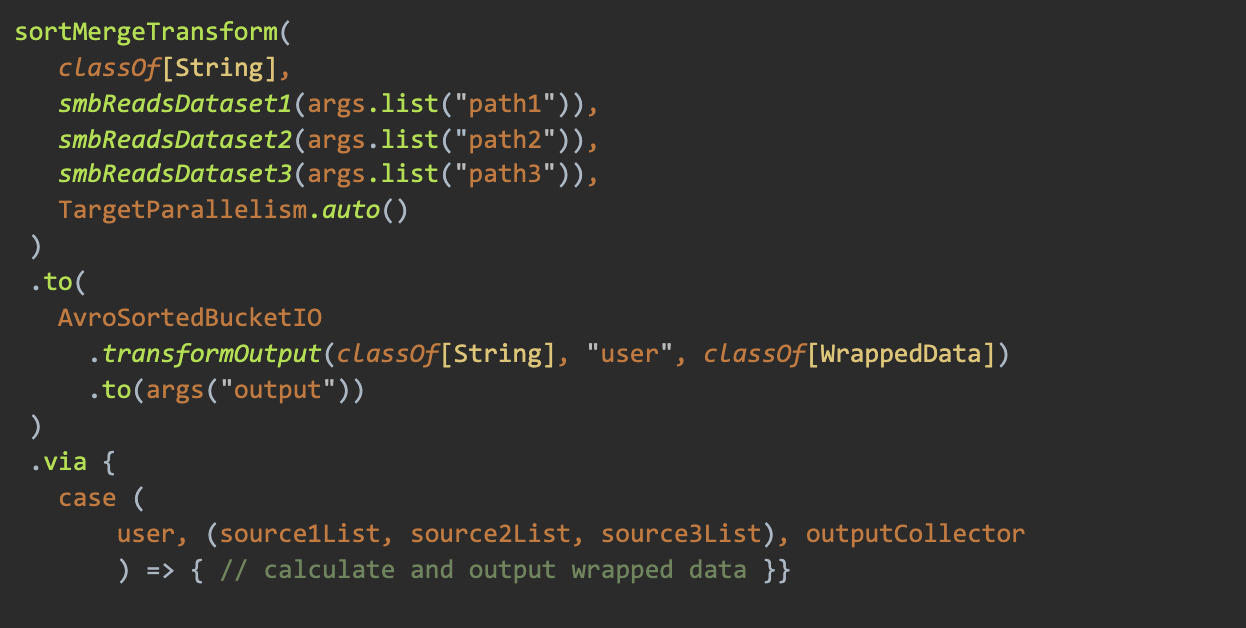
SMB 让这一切变得相对简单。利用 sortMergeTransform,我们可以将三个数据源结合起来,分别读取每个按 user_id key 排序的数据,并以 SMB 格式写入 Wrapped 输出(播放次数、播放毫秒、播放上下文等等)。
最后,我们运行聚合作业,使用 sortMergeGroupByKey 读取 SMB 的所有 Wrapped 周分区,合并一年的数据,然后将结果写到输出中,以便以后的作业计算剩余的 Wrapped。此处的灵活性的关键之处在于,聚合作业可以采用任何周和日分区的混合形式,这在运行它们时具有很大的逻辑意义。在实践中,最终结果如下:
在今年的 Wrapped 项目中,这最终为我们节省了很多成本。通过利用 SMB,我们可以在不使用传统的 shuffle 或 Bigtable 的情况下,成功连接了大概总共 1PB 的数据。据我们估计,与往年基于 Bigtable 的方法相比,今年的 Dataflow 成本降低了 50%左右。另外,为了支持繁重的 Wrapped 作业,我们避免将 Bigtable 集群的容量增加到普通容量的两到三倍(峰值时可以达到 1500 个节点左右)。这在今年的活动中是一个巨大的胜利,因为我们能以一种比以往更经济的方式带来精彩的体验。
结语
通过采用 SMB,我们能够执行以前无法实现或成本高昂,或需要像 Bigtable 这样的定制工作方案的超大规模连接。在节省成本的同时,我们也开创了更多优化工作流程的方法。我们还需要做大量的工作。我们期望将更多的工作流迁移到 SMB,同时还可以处理更多的边缘情况,比如数据偏移、复合 key 以及更多的文件格式。
作者介绍:
本文作者为 Neville Li、Claire McGinty、Sahith Nallapareddy、Joel Östlund。
原文链接:
Https://engineering.atspotify.com/2021/02/11/how-spotify-optimized-the-largest-dataflow-job-ever-for-wrapped-2020/

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论