

本文是 “2022 InfoQ 年度技术盘点与展望” 系列文章之一,由 InfoQ 编辑部制作呈现,重点聚焦大数据管理工具在 2022 年的重要进展、动态,希望能帮助你准确把握 2022 年大数据领域的核心发展脉络,在行业内始终保持足够的技术敏锐度。
“InfoQ 年度技术盘点与展望”是 InfoQ 全年最重要的内容选题之一,将涵盖操作系统、数据库、AI、大数据、云原生、架构、大前端、编程语言、开源安全、数字化十大方向,后续将聚合延展成专题、迷你书、直播周、合集页面,在 InfoQ 媒体矩阵陆续放出,欢迎大家持续关注。
作者:王宇飞,字节跳动数据平台开发套件技术负责人
以云数仓为中心的数据架构开始形成
数仓的发展历程
纵观整个数仓的发展历程,笔者认为大体上可以分为 4 个阶段:
第 1 阶段:传统的一体机数仓,代表产品有 Oracle Exadata、IBM Netezza 等;
第 2 阶段:基于 MPP 架构的数仓,它可以实现软硬件分离,数据不用再存储在特定的服务器上,代表产品有 GreenPlum、Vertica 等;
第 3 阶段:随着互联网发展,企业数据量迅速增长,擅长处理海量数据的 Hadoop 框架和生态得到了普及与发展,诞生了依托 Hadoop 生态的批处理等模式,代表产品有 Hive;
第 4 阶段:伴随云的发展,云上数据仓库解决方案日趋成熟,进一步降低了用户使用成本,这个阶段的代表产品有 Amazon Redshift、Snowflake 等;
尽管在当下,第 2、3、4 阶段的数仓产品仍处于共存状态——它们仍旧分别被各类企业所使用,但在企业数字化转型和企业上云的整体趋势背景下,我们有理由相信,未来处于第 4 阶段的云数仓,将会被越来越多的企业采用。
云数仓架构的核心优势
在笔者看来,云数仓架构最显著的优势在于易用性进一步提升、成本进一步降低。尤其是新一代云数仓采用 shared everything 架构,所有节点共享底层云存储资源池,计算与存储分离,让存储及计算节点都具备灵活弹性扩展的能力。此外,可以以集中化的方式解决安全信任和数据共享等方面问题。
相比基于 Hadoop 生态的数仓架构,用户不用再维护管理自己的集群,而是可以根据业务发展需要动态扩缩容。综合考虑硬件及自身维护数仓架构的研发等成本来看,云数仓也更有优势。
云数仓开始成为企业的 single source of truth
随着过往数据生态系统的发展,企业其实已经积累了非常多的数据源,包括各种数据库、SaaS 服务等。尤其在海外,SaaS 发展更成熟,多源数据问题更加凸显。
多源数据会给企业带来两方面的困扰:
数据源之间点对点集成方式形成依赖,交织成复杂的网,维持数据间的同步越发困难;
数据源之间都很孤立,形成一个个数据烟囱,数据很难整合起来发挥最大化价值。
因为云数仓的存储计算成本优势,以及随着现代数据堆栈的发展,让数据汇聚到云数仓及加工都更加便捷,这些都是企业选择云数仓作为中心存储的优势。
当云数仓成为企业的 single source of truth 后,可以帮助企业基于整合后的数据更好地做出业务决策。
数据工具更加易用与专精
数据管理成为企业基础设施增长最快的领域之一
A16Z 今年发布了世界排名前 50 的数据创业公司 https://future.com/data50/ ,文章中指出:数据管理已经成为企业基础设施中增长最快的领域之一,价值预计超过 700 亿美元,2021 年数据管理支出占企业所有基础设施支出的五分之一以上。这 50 家创业公司的估值总计超过千亿美元,总融资额约 145 亿美元,其中 20 家在 2021 年晋级独角兽行列。
笔者认为,背后最主要的原因是数据使用的民主化对帮助企业快速成长起到了愈发关键的作用。这里面包括增长营销、业务诊断、结合机器学习赋能业务过程自动化等等,早已不再只是单纯的报表统计需求。
而海外云数仓的发展,尤其像 Snowflake 的发展与崛起,进一步带动了整个大数据管理工具的生态发展,形成了目前的 Modern Data Stack。Snowflake 作为云中立的数仓,可以做到足够的开放兼容,利用生态的发展增强整体数据管理链路的竞争力。从其对生态公司的投资布局也能看出,涵盖了从数据转换、元数据管理到数据安全等多领域公司。
更多细分创新领域涌现,下一代行业标准正在悄然建立
新一代数据集成系统:ETL 向 EL(T)转变
过去,整个数据开发的基础核心链路是 ETL,即数据抽取加工后导入数仓。随着硬件成本的降低与云的发展,处理模型开始向 EL(T)的方式转变。
EL(T)的优势在于把数据抽取和转换解耦,也就是 EL 和 T,各自由独立组件完成,使得抽取过程可以更自动化,大大降低了数据导入这步的使用门槛。同时,由于 EL(T)可以让数据源更低成本地集成进来,进一步加速了云数仓成为 single source of truth 的进程。
而做好一个数据集成系统主要的挑战有三点:
架构可扩展性,不光是数据源 connector 可插拔,还有不同场景的集成能力,包括批、流和 CDC;
丰富的基础功能,作为一个垂直领域,数据集成存在很多独特的问题,比如脏数据、数据源承载能力、数据源类型不一致、数据源读写延迟、任务读写监控等;
系统稳定性,这对于数据量大的企业而言是非常明显的痛点,比如如何保证几十万任务的海量数据传输;
数据质量,如何做好数据的不重不丢,及异常数据的及时发现等问题。
从行业发展来看,数据集成领域涌现了一些优秀的开源项目,每款产品都有着自身的特点,并聚焦解决其中一部分问题,以下是几种常见的解法:
将易用性以及用户体验做到极致,但架构比较简单,不支持分布式部署,容错性一般,处理能力以及场景比较受限;
提供了丰富的数据集成基础功能,并将资源使用率做到极致,架构上基于单机多线程架构,不支持分布式和实时功能,使用场景比较受限;
主打用户使用场景,支持离线、实时数据同步,并提供分布式的数据处理能力。但引擎资源开销较大,基础功能支持比较一般。
字节基于内部的复杂场景和海量数据传输等需求,自研了一套提供离线、实时、增量场景下全域数据集成解决方案引擎,在架构及功能层面的优化包括:
架构灵活性:connector 层、框架层、引擎层,每一层都采取可插拔的设计,同时 connector 层、框架层做到完全与引擎解耦,整体结构比较清晰和灵活,可扩展性较强。可以应对不同规模的数据同步场景,同时具备单机以及分布式能力,在引擎的选择上采取智能选择策略,兼顾小数据量场景的资源利用率以及大数据量场景的稳定性;
集成能力完善性:在框架层提供了丰富的基础能力,比如异构数据源类型转换、脏数据处理、流控、自动并发度推断、任务运行监控、事件时间归档等;
企业级稳定性:在特定导入场景,提供了更多的企业级特性,在性能、稳定性、成熟度上更有保障。比如 Kafka2Hive 通道,针对大数据量场景做了相关优化和重构,包括如何提升大并发场景下一致性快照成功率、提升大并发场景的容错性、兼容乱序写入场景等等。
今年 11 月,我们已经把这套数据集成引擎 BitSail 正式开源出来(https://github.com/bytedance/bitsail),希望可以把内部沉淀的经验提供给更多外部企业,同时援引社区力量,大家共同解决好数据入仓第一步的问题。
数据可观测性:概念骤热背后,数据质量和 SLA 重要性日益凸显
数据可观测性的核心是帮助企业解决更好地监控和改善企业内可交付的数据质量和效率等问题。通过持续监控、跟踪、警报、分析和故障排除事件来减少和防止数据错误或停机时间,同时能帮助用户了解组织的数据环境、数据管道和数据基础设施的健康状况。
目前,Monte Carlo 等厂商正在大力推广“数据可观测性”这一概念。
在笔者看来,数据可观测性概念背后要解决的问题——即数据质量和 SLA 治理问题,并不是全新场景问题,但其重要性正在不断提升。
核心驱动力来自两个方面:
数据链路本身的复杂程度升高:随着现代数据堆栈的发展,整个数据链路的建设需要多个不同的 SaaS 产品和服务,极大增加了数据端到端交付质量的运维和管理成本。
数据对业务的重要性上升:数据驱动决策越来越普遍,故数据不及时或数据发生错误造成的成本也变得更高。决策对数据质量和实时性的依赖越高,对数据可观测性的需求也会越高。
反向 ETL:数据进一步深入业务场景实现提效
反向 ETL 指的是将数据仓库加工好的数据同步到业务系统中,它处于数据集成(EL)的另一端,解决的是数据如何在消费端更好地发挥价值的问题。这种细分场景的出现,也是以云数仓为中心的场景扩展,意味着数据使用深度增强。
数据从之前的更多用于报表决策、分析等应用场景,开始过渡到更多地输出到企业的 CRM 等系统,帮助优化业务流程和自动化决策等场景能力。这也是数据对业务重要性提升的一个表现。反向 ETL 让用户能够以无代码、自动化等低成本的方式提升业务场景的决策效率。典型的代表公司有 Hightouch、Census 等。
DataOps 兴起,但行业标准尚未成型
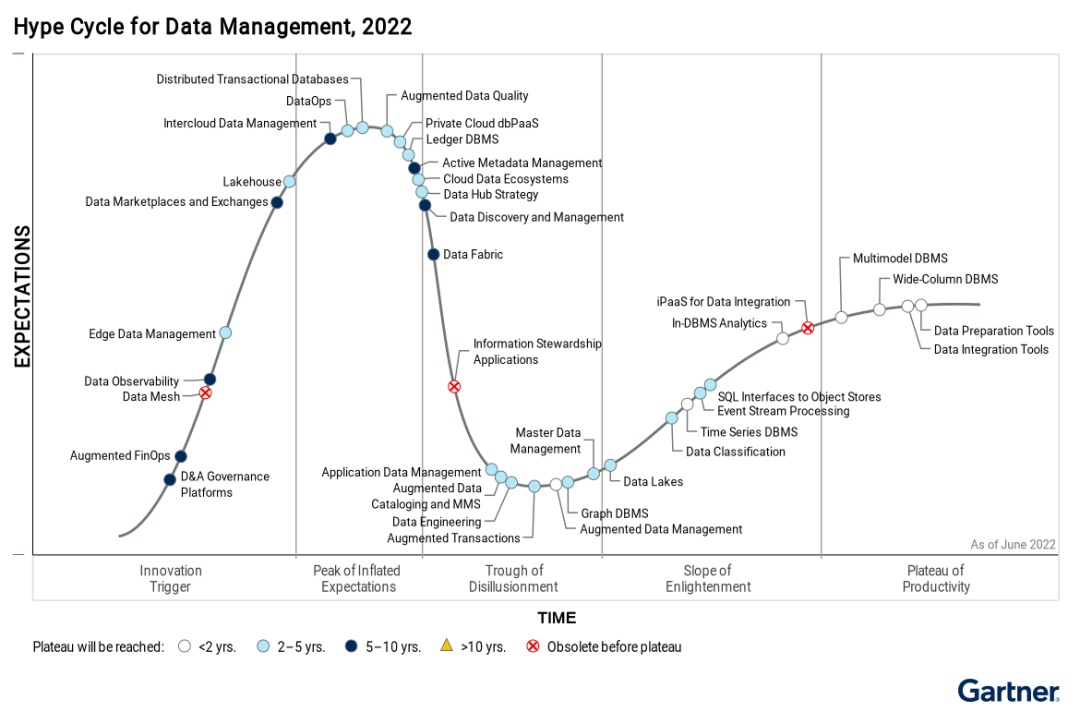
图注:Gartner 2022 数据管理成熟度模型
Gartner 对 DataOps 的定义如下:
DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts. DataOps uses technology to automate the design, deployment and management of data delivery with appropriate levels of governance, and it uses metadata to improve the usability and value of data in a dynamic environment.
简单来说,DataOps 结合了软件工程 DevOps 理念,来解决数据端到端交付过程中的质量与效率问题,它是一套方法论,而不是单指某项技术或工具。2018 年,Gartner 开始推 DataOps 这个概念,2022 年 DataOps 进入到期望膨胀期,即越来越多的企业开始宣传和投资这个概念。
在笔者看来,DataOps 出现的核心驱动力还是数据对业务的影响和价值越来越大,所以需要更科学、更精细化的方式融入到整个数据开发、生产到交付的全链路中。而 DevOps 已经发展多年,里面很多成熟的理念可以迁移到数据的开发交付链路中,比如持续集成、持续测试、持续监控等等。
但行业整体还处于发展初期,大家对这个概念本身的理解也有差别,还没有真正形成基于普遍认可的业务实践达成的行业标准。从 Gartner 的 Hype Cycle 曲线也可以看出,DataOps 仍需要 2-5 年才能发展得相对成熟。如何在 Data 场景下将 Ops 最优化落地,仍需各个厂商积极探索和完善。从字节的场景需求来看,眼下有以下两方面的问题是大数据管理套件 DataLeap 在持续投入改进的。
研发质量
这方面的痛点包括如何把口头研发规范应用到开发平台、如何降低由于代码问题或误操作等带来的数据事故,以及如何保障数据 SLA 链路的可观测性等问题。随着一个个场景的问题被解决,沉淀到产品上的能力一定程度上就是软件工程实践的场景迁移。比如,基于数据开发场景结合好 CICD、数据测试、版本管理等。
研发效率
一方面是要制定合理的 DataOps 研发流程,另一方面是如何用更加自动化的方式把各领域工具很好地串联在一起,比如数据建模、数据质量监控、资产管理等目前都是不同的独立产品组件,并没能很好地串联起来。笔者认为海外的现代数据堆栈也有这类问题,虽然每个细分场景有独立产品支撑,提升了单场景易用性,但整体链路串联在一起反而提升了复杂度。目前已经有一些创业公司在尝试解决这个场景的问题,比如 Dataops.live 等。
AI 能力进一步融入,释放更多人力
数据管理工具结合 AI 能力,在笔者看来是必然趋势。究其原因,一方面是人力成本日益攀升,而 AI 可以释放人力,让人力聚焦到更复杂的业务问题上、做更能激发创造力的事情;另一方面是随着数据的民主化,企业收集和处理的数据量远超之前,尤其大型互联网公司的数据规模通常都能达到 EB 级,这种规模的数据管理运维复杂度也急剧攀升,完全靠人来处理好是比较难的,而 AI 可以完全托管或协助管理。
对于数据管理领域,AI 可以在很多方面发挥作用。比如在数据治理方向,自动检测相似任务、利用 NLP 技术生成数据质量规则、冷热数据分级等;在数据开发方向,自动推断 Join 字段及代码片段等;在安全合规方向,智能审批及异常访问检测等。
从发展阶段来说,AI 在数据管理领域的应用还处于偏早期,大多数场景起到的是锦上添花的作用,仍有很大空间等待探索和挖掘。
结 语
当前国内外大数据管理工具的发展现状还存在明显差异,具体体现在:
国内的数据管理产品偏 all in one 形式,而国外现代数据堆栈在各领域都有细分的工具支持。以数据集成为例,国外数据转换和任务调度编排等每个领域都有独立的针对这个场景的厂商支持,国内则通常是一个厂商把几个领域场景的问题都解决了。整体上国内更重交付,产品力的打磨相比国外的细分 SaaS 产品存在一定劣势。
国内私有化场景交付更多,而国外 SaaS 发展更成熟。国外 SaaS 产品的标准化程度更高,因此用户选择不同细分 SaaS 产品拼接组合的成本也更低。
核心原因是国内外云的发展阶段不同,云的渗透率相差比较大,这也导致国内数据工具生态还没有发展起来。而现阶段国内企业做数字化转型,需要有 all in one 的产品解决方案来支持。未来随着国内云的进一步发展,尤其是云数仓的崛起,笔者相信会有更多优秀的细分领域 Data SaaS 工具涌现。
这给我们带来的挑战和机遇是如何加速企业上云和数字化转型的过程,让企业有机会跳过工具能用的阶段,直接到好用。
如果你对本文感兴趣,欢迎在文末留言,或加入 InfoQ 写作平台话题讨论:https://xie.infoq.cn/
【2022年度技术盘点与展望】专题已上线,添加进收藏夹,精彩不错过。
同时,InfoQ 年度展望直播周将于 2023 年 1 月 3 日首场开播,并持续输出精彩内容,关注 InfoQ 视频号,与行业技术大牛连麦~
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论