

MIT 构建“听音识人”神经网络
当听到一个人的声音时,即使没有看到他/她的脸,我们也会在心里为这个人的长相建立一个模型。有很多研究都表明:语言和外表之间有很强的联系,这在一定程度上是语言产生机制的直接结果,一个人的年龄、性别(影响声音的音调)、嘴巴的形状、面部骨骼结构、薄嘴唇或饱满的嘴唇——所有这些都能影响我们发出的声音。此外,人们说话的方式也与外表有所关联:语言、口音、速度、发音——这些语言的特性通常在不同的民族和文化中是相同的,反过来又可以转化为共同的身体特征。
近日 MIT 发表了一篇论文,挑战了一个看似不可能的任务:从一段简单的语音片段,重建一个人的面部图像。研究人员设计并训练了一个名为 Speech2Face 的深度神经网络,利用互联网以及 Youtube 上数百万人的自然视频来完成这项任务。
项目地址:https://speech2face.github.io/
论文地址:https://arxiv.org/pdf/1905.09773.pdf
在训练过程中,研究者们让模型学习了视听、语音和面部的相关性,使得它能够生成图像,捕捉说话者的各种身体特征,比如年龄、性别和种族。据介绍,这是一种自监督的方式,利用互联网视频中人脸和语音的自然共存,不需要显式地建模属性。MIT 的重建模型能够直接从音频中获得,通过数字量化的方式进行评估,从声音中重构出的语音人脸与说话人的真实面部图像是否相似,以及如何做到相似的。

图:上层图像为现实中的发音者,下层图像为 Speech2Face 模型产生的几个结果。MIT 在论文中特别指出:“我们的目标不是重建一个准确的人的图像,而是恢复与输入语音相关的物理特征。
研究人员设计了一种以短语音段的复杂谱图为输入,预测人脸特征向量的神经网络模型。更具体地说,设计者使用一个经过单独训练的重建模型,将预测的面部特征解码成人脸的标准图像。为了训练模型,MIT 使用了 AVSpeech 数据集,它由来自 YouTube 的数百万个视频片段组成,有超过 10 万人的语言数据。Speech2Face 是通过自我监督的方式训练的,只在视频中使用语音和人脸数据,不需要额外的信息,比如人类的注释。
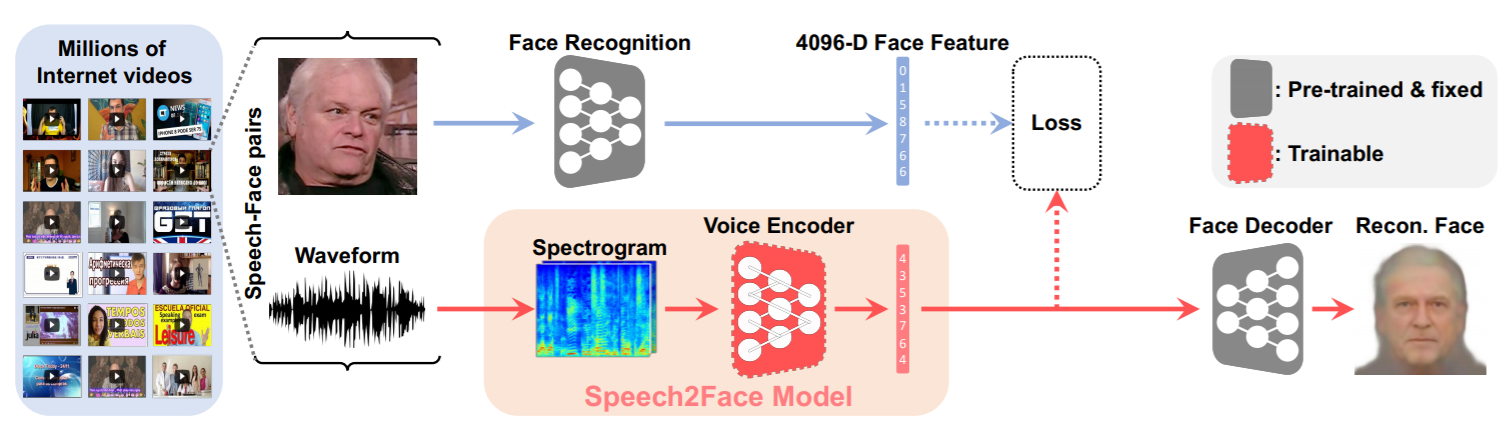
图:语音-人脸模型和训练管道。神经网络的输入是一个复杂的声谱图,由说话人的短音频段计算而成;输出是 4096-D 人脸特征,使用预先训练的人脸解码器网络将其解码为人脸的规范图像,训练的模块用橘黄色做了标记。研究人员让训练网络回归到真实的人脸特征计算,将一个人的图像(视频中的代表性帧)输入到人脸识别网络中,并从其倒数第二层提取特征。
以前,通过语言预测年龄和性别已经得到了广泛研究,通过输入的声音首先预测人的声音的一些属性(例如年龄、性别等),然后从数据库图像中获取最适合预测的一组属性,或使用属性来生成一个图像。
然而,这种方法有几个限制:首先,从输入信号预测属性依赖于健壮而准确的分类器,通常需要地面真值标签进行监督。例如,通过语音预测年龄、性别或种族需要构建专门训练的分类器来捕捉这些属性。更重要的是,这种方法将预测的人脸限制为只与预定义的一组属性相似。
而 MIT 的目标是研究一个更普遍、更开放的问题:什么样的面部信息可以从言语中提取?
研究人员直接从语音预测完整的视觉外观(例如,一张人脸图像)的方法来探索这个问题,而不受限于预定义的面部特征。
具体来说,已有的实验展示了重建的面部图像可以作为一个“代理人”来传达“真实人”的视觉属性,包括年龄、性别和种族。除了这些主要特征,重建模型还揭示了颅面部特征(如鼻子结构)和声音之间不可忽视的相关性,并且是在没有先验信息或存在这些类型的精细几何特征的精确分类器的情况下实现的。此外,研究者认为:直接从语音预测人脸图像可能会有更加广泛的应用,例如,根据说话者的语音将生成一张有代表性的人脸,用以追踪犯罪分子等等。
伦理与隐私问题
虽然这是一个纯学术的调查,但 MIT 方面认为,由于面部信息的潜在敏感性,在论文中明确讨论一系列伦理问题的考虑是很重要的。
隐私问题
Speech2Face 神经网络模型不能从一个人的声音获取此人的真实身份(即面部精确图像),这是因为模型被训练来捕捉许多个体共有的视觉特征(与年龄、性别等相关),而且前提是:在有足够的证据将这些视觉特征与数据中的语音或言语属性联系起来的情况下。因此,该模型只会生成模糊的的面孔,且仅具有与输入语音相关的特征视觉特征,并不会生成特定个体的图像。
语音-面部相关性和数据集偏差
据介绍,Speech2Face 模型旨在揭示训练数据中面部特征与说话者声音之间存在的统计相关性,所使用的培训数据是从 YouTube 上收集的教育视频,并不代表全世界的人口外貌特征,因此,与任何机器学习模型一样,该模型也受到数据分布不均匀的影响。
更具体地说,如果一组说话者可能具有在数据中相对不常见的声音和视觉特征,那么针对这种情况,模型重构的质量可能会下降。例如,如果某一种语言没有出现在训练数据中,模型的重构就不能很好地捕捉到可能与该语言相关的面部特征。
MIT 在博客的文章着重强调:“我们预测的面部特征中有一些甚至可能与语言没有物理联系,例如头发的颜色或风格。然而,如果训练集中许多说话方式相似的人(例如,说同一种语言)也有一些共同的视觉特征(例如,共同的头发颜色或风格),那么这些视觉特征可能会出现在预测中。”
基于上述原因,MIT 表示希望对这项技术的任何进一步调查或实际应用进行仔细测试,以确保培训数据能够代表预期的用户群体。如果情况并非如此,则应广泛收集更具代表性的数据。
未来研究
根据 MIT 的文章介绍,这个项目仍然存在一些限制,需要在未来的研究中继续提升。
以下图为例,一个亚洲男性用英语和汉语说同一句话,有时候生成的是不同的人脸;另一个例子,即使一个亚洲女孩说的是英语,且没有明显的口音,模型仍然能够成功地提取出核心,重构出一张具有亚洲特征的脸。研究者表示,需要更彻底的检查来确定:模型生成的结果到底在多大程度上依赖于语言。
更多案例详见补充材料:
https://speech2face.github.io/supplemental/index.html

更普遍地说,从语言中捕捉潜在属性的能力,如年龄、性别和种族,取决于几个因素,如口音、语调或音高,在某些情况下,这些声音特征与人的外表并不匹配。几个典型的语音人脸不匹配例子如下图所示:

图:失败案例。(a)高音调的男性声音,例如孩子的声音,可能会生成具有女性特征的面部图像;(b)语言与种族不符;(c+d)年龄不匹配。


Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论