
3 月 7 日,蚂蚁团队开源了两个 MoE 模型 Ling-Lite 和 Ling-Plus(中文名称为“百灵”),并发布了技术论文《Every Flop Counts》。其中 Ling-Lite 共有 168 亿参数,激活了 27.5 亿参数; Ling-Plus 共有 2900 亿参数,激活了 288 亿个参数。蚂蚁团队的研究方向是通过优化模型架构和训练过程、改进异常处理的训练方法、提高模型评估效率进一步降低模型的预训练成本。其尤为突出的一点是,使用规格相对较低的国产硬件,即可完成预训练工作,成本比使用更高规格的 NV 硬件,还要低 20%,是个非常因地制宜的技术方案。
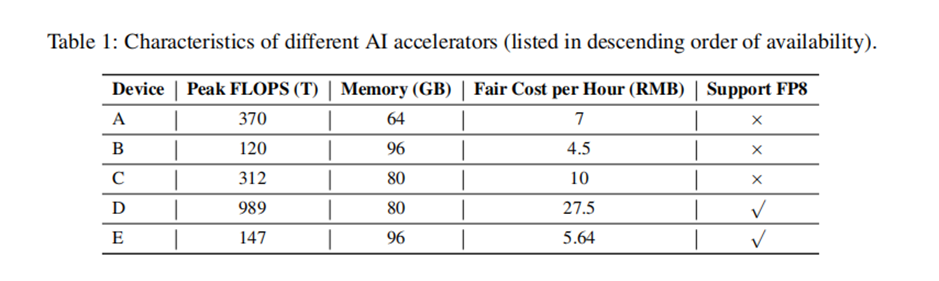
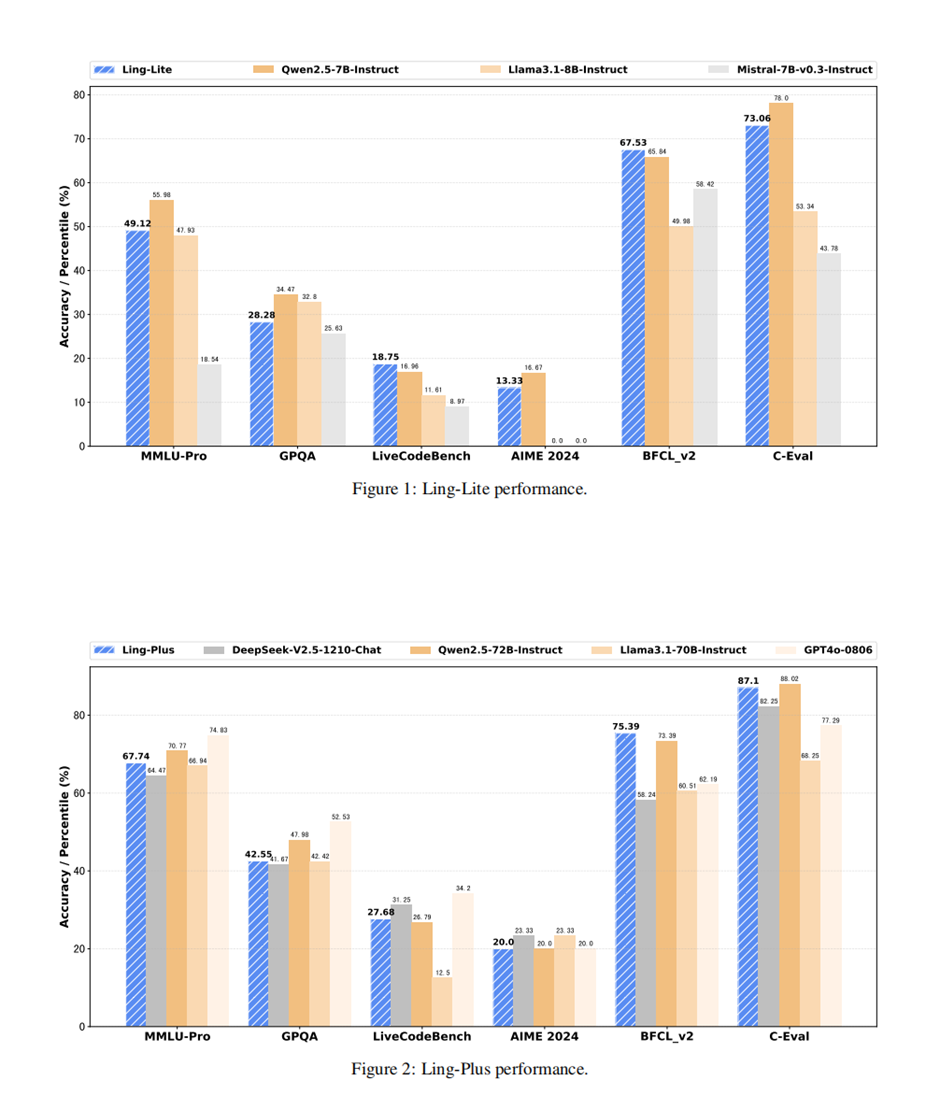
不过,当该技术论文经由外媒报道,传回国内,围绕一些关键数据,却出现了误读——有报道称 Ling-Plus 模型使用低规格硬件的预训练成本为 508 万人民币,远低于 DeepSeek。但实际上,论文中提到的成本是在训练 1T token 的前提下实现的,与消耗了 14.8T Token (技术报告口径)的 DeepSeek V3 并不匹配 。
蚂蚁团队的工程师后续也在朋友圈进行了辟谣:“我们还没有做到比 DeepSeek 低”,并在知乎发布了补充性的技术解读内容:《关于我们抠 FLOPS 的一些点滴》。另有蚂蚁团队专家对 InfoQ 表示:DeepSeek V3/R1 的成本优化,是在 NV Hopper 卡上的极致优化;DeepSeek V3 的报告里展示了用 FP8 精度软硬件协同优化,和算法配合,得到了让人印象非常深刻的单次训练成本。
而 Ling-Plus 的成本优化工作,主要反映了 AI 基础设施的工程能力,要能持续运作、减少中断。这里的成本比较是从基础设施的角度进行的,经过优化组织、加入容错机制,相比于国外硬件,能更好的配合国产卡,实现更低的工程成本。
InfoQ 也与蚂蚁 Ling 团队做了一场简单的对话,希望能在上述技术材料外,给大家更多信息参考。以下为对话原文,在保持原意的清况下,略有删改。
Q&A
InfoQ:能否帮我们简单回顾下《Every Flop Counts》论文里,我们实现的技术成绩?
Ling 团队:目前大模型研发领域比较公认的实践是,MoE 架构模型的训练与稠密模型相比,会困难很多,训练过程中的稳定性比较差,尤其是一些新架构,均衡难度较大。
在 Ling 这个 300B 的 MoE 模型的训练过程中,我们对此也深有体会,特别是当使用可以借鉴的材料更少的非 NVIDIA 加速卡的时候,我们“被迫”解决了很多问题。
很难说这些问题和解决方法算是成绩,但是我们分享出来的这些问题和解决方法、思路,对其他着手尝试这些加速卡的团队应该也有一定借鉴作用,大概能帮他们节省点时间。
InfoQ:具体是怎样的新思路?
Ling 团队:其实在国产卡上训练 300B 甚至更大量级的 MoE 模型,据我了解,并不只有蚂蚁一家在做,大家应该都不同程度地遇到了很多困难。
当我们看到,在不同算力平台上能跑出一模一样的 loss 曲线,我们非常兴奋。所以在我们完成一个大阶段的训练后,就第一时间把 Ling 开源了出来,同时分享了我们的一些思考、方法和经历。
我觉得这里面像 MoE 的 scaling law 分析、跨平台训练的一整套解决方案、还有一些 bitter lesson,对行业都有一定的借鉴意义。当然,无论从模型尺寸还是 benchmark 效果来看,Ling 都不是最顶尖的,业界还有很多优秀团队的模型效果值得我们去努力追赶。
当前 AI 领域的创新是以“天”记的,春节都不放假,我们对其他天才团队都很尊重。在实现 AGI 的路上,大家有竞争,但更重要的是在彼此印证、互相鼓励、共同进步。
InfoQ:如果对应着 R1 参数规模所消耗的 Token 量,Ling-Plus 的训练成本大概处于什么水平?怎么衡量?
Ling 团队:如果是在 Hopper 架构 GPU(比如 H800)上,DeepSeek V3(R1 的预训练模型)针对该架构优化得非常极致(比如 FP8 混合精度训练),再加上硬件成本也低,整体的训练成本要比 Ling 低不少。
但我觉得关于成本大家可能有一个误解,Ling 在训练上主要考虑的问题是如何实现非 Hopper 架构 GPU 上的训练,确保正确性,同时尽量降低成本,所以像 FP8 这种 Hopper 架构独有的特性,我们并没有考虑在内。在这个大的思路下,通过我们的一些技术努力,可以在国产加速卡上实现相当甚至更低的训练成本。但我个人觉得能不能训比成本高低要更重要。
另外,不管是 DeepSeek V3 还是 Ling,技术报告上提到的成本,都是参考价格和单次训练,其实并不是真实和完整开销,比如前期的技术预研,也都是巨大的投入。
InfoQ:为什么使用 NV 算力和国产算力,可以最终实现 loss 接近。通过软件优化,真的可以弥补硬件差距吗?
Ling 团队:实现 loss 非常接近,是软硬件一体的事情。国产算力在 TFLOPS 上虽然不如 NVIDIA 最高端的芯片,但至少在我们使用的这些平台上,硬件的计算精度本身都是没有问题的。而硬件稳定性来看,国产算力确实也还有差距。因此我们做了不少技术努力,比如训练监测框架 XPUTimer、loss 和 grad 尖刺监控机制等,来努力确保训练的稳定。
再看软件,国产算力的软件生态相比 NVIDIA 也有明显差距,在我们完成 loss 对齐的过程中,确实需要付出很多努力来进行算子、框架等的对齐,也非常庆幸最后努力没有白费。
InfoQ:各型号加速卡测试下来,综合体验如何?
Ling 团队:我们不方便点名所有用到的卡,但在训练过程中,我们确实尝试了不同厂家的不同型号的加速卡,具体限制很多,但这个限制也让我们体验到了国产加速卡的进步,作为模型研发团队,我们的首要目标肯定是训练出能力更强、效能更高的模型,既然异构问题客观存在,就要克服这些问题。
InfoQ:在 loss 对齐工作上,我们之前提到,团队曾定下了严苛标准:“基础算子(除符合预期的精度误差)完全对齐 + 分布式训练框架前后向计算完全对齐 + 大规模训练长跑 loss 差异低于 0.1%”,读者应该怎么形象地理解这个指标的严苛程度?
Ling 团队:把 MacOS 改成 Windows?我也不知道应该怎么比喻。实际就是把算子和训练框架几乎所有细节都摸了个遍。我在知乎文章也有提到,同时我们在做的 scaling law 研究发现:不训练直接预测 loss 的误差都能做到 0.5%以内。这一定程度上说明 LLM 的 loss 是一个非常确定的东西,这么看的话,0.1% 也没有很苛刻吧。
InfoQ:AReaL 也开源了,能否简单聊聊 AReaL ?与《Every Flop Counts》的工作相比,该怎么衡量 AReaL 工作的重要性?
Ling 团队:AReaL 是蚂蚁和清华团队合作的一项工作,是使用强化学习方法进行推理模型训练的工作,之前开源了 0.1 版,0.2 版本正在研发中,应该很快也会发出。强化学习的方法也是最近很火的 DeepSeek-R1 的方法。非常理解大家想看一个简单的相互 PK,但在整个 AI 的历史进程中,使用优质数据(答案)的训练,和使用奖励机制的强化学习方式经常是交替被采纳的,没有预训练推进到一定程度,强化学习模型就很难取得成果,但一旦训练数据达到瓶颈的时候,强化学习方法就又回归视线,人的学习可能也是这样一个过程,从复读式学习,到从得到的正负反馈成长。
InfoQ:该如何描述大模型发展和高端算力的关系?目前 LLM Arena 里排名靠前的模型,还是靠着大规模 N 卡集群训练出来的。
Ling 团队:其实用国产算力做后训练和推理还是比做预训练要成熟不少的,Ling 的后训练也是在国产算力上完成的。
峰值算力、显存量、卡间互联带宽、还有一些新特性,比如低精度支持等,肯定都是多多益善,对提升训练效率或者训练成本都是非常有用的。
整体来看,NVIDIA GPU 的生态目前确实还是领先的,这个领先不仅体现在硬件性能更优秀,很大程度也体现在软件生态更成熟,以及相关的尝试经验更多。
这次我们开放出来的 Ling 就是国产万卡集群训练的结果,随着时间积累,相信很快就会有更多基于国产大规模集群的成果开放出来,这些经验的交流和累积,对于生态的成熟应该会有巨大帮助,这也是开源的意义之一。
InfoQ:团队接下来还有什么进一步规划?
Ling 团队:Ling 团队接下来在下一代基座模型、推理模型、多模态大模型上都会持续投入,我们近期就会开源一个基于 Ling-lite 蒸馏训练得到的长推理模型。
在基座模型方面,虽然目前 Ling 开源的模型最大尺寸是接近 300B,但实际上,更大尺寸的模型在国产卡上也是可以训练的。我们希望可以尽快可以跟大家分享新的基座模型成果,比如更高效的模型架构、更低成本的训练方法、更大尺寸的模型等等。




