
本文最初发表于 Towards Data Science 博客,经原作者 Fabrizio Fantini 授权,InfoQ 中文站翻译并分享。
你知道吗?单是在美国,就有价值超过 2 万亿美元的库存,每售出 1 美元,就有超过 1.4 美元的库存。
这一数字至少超过了 2000 亿美元,甚至可能更多。理由如下。
商品库存通常都是容易腐烂的:有些商品会随着趋势的变化而失去价值;有些商品是季节性的,季节性对需求起着重要作用;有些商品则只是过期了或被浪费掉了;有些商品可能会在货架上存放了更长时间。一切终将消逝。并且,由于所需的财务成本,储备库存无论如何都是很昂贵的。
如今,消费者的选择范围越来越广:他们正在充分利用这种多样性,并变得比以往更有选择性。无论是在 B2B 还是 B2C,都是如此。
新的分析技术应运而生,可以将这种浪费的库存削减 10% 或更多。我已经不止一次这样做了,所以我知道它行得通;那么,这个故事中最吸引人的地方在哪里?
>最好的解决方案不只是机器学习,而是将机器学习与人类输入结合起来。
让我们继续阅读,来了解我那难以置信的经历。
回顾与展望
造成库存过剩的根本原因很简单:供应链之所以缓慢,是因为它们需要回顾。是的,即使到了 2020 年,即使暴发了新冠肺炎疫情,根本问题仍然没有改变。
许多公司仍然使用传统的目标库存水平(Target Stock Level,TSL)模型来驱动库存决策。它是一个复杂的概念,即“卖一得一”——世界补给的字面意思。此外,需求的高度不确定性要求库存管理者在安全库存利润方面高于其他必要情况。
推动库存,而不是让市场需求来拉动:这会导致大量库存无法在产品生命周期末销售,同时也会带来高昂的仓储成本。
要如何才能准确地提前设定这样的目标库存水平,并做到每日更新呢?
市场的季节性和*不可预测性*,在新冠肺炎疫情中变得尤为明显,这就需要新的模型:预测每种产品的需求,实时了解如何纳入新的市场因素,并制定相应的规则,以使其始终得到正确执行。
这些示例规则可以包括供应链调度、产品重新订购的频率、从订购时起接受新产品的预定期、最小订购数量、供应商可靠性和成本结构(生产、运输、管理)。
>现在,“回顾过去”的意思是实际地囤积过去售出过的东西。
就像去年,或者上个月。
>“展望未来”的意思是实际地储备预期将来要出售的东西。
听起来很相似,但是却有很大的不同之处。有一种情况是,管理人员需要手动设定目标并审查规则。而另一方面,客户直接通过数据和系统来推动决策。自主地进行。那管理方面呢?
利用机器学习解决 2000 亿美元的问题
关于这一问题,我了解得越多,就越意识到,没有单一的答案。太多特定于上下文的业务规则、与位置相关的变量,以及不同商品、大小、时间等之间的销售差异。因此,我不再专注于回答任何单一的问题。取而代之的是,我开始用一个动态的工具来代替传统的 TSL,它专注于动态机器学习。
为了测试,我尝试了 6 种不同的 B2C 补货方式:

假设我们知道商店之间的需求分布,并且我们为每家商店分配了 20% 的平均变化率,为了简单起见,在此期间不会有折扣或促销活动。
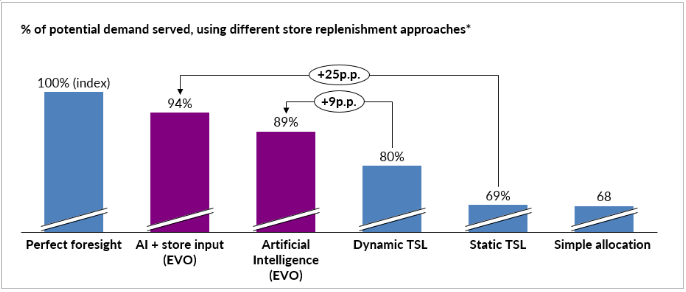
进一步说明的结果表明,机器学习的性能比传统的 TSL 方法高出了 9~25 个百分点。
惊人的增加?那是因为人类管理者的输入
如果商店经理编辑他们自己的由机器生成的库存分配建议时,结果甚至会进一步得到改善。事实上,当机器和商店经理一起合作时,该模型的预测结果达到了 94% 的理论完美销售业绩。
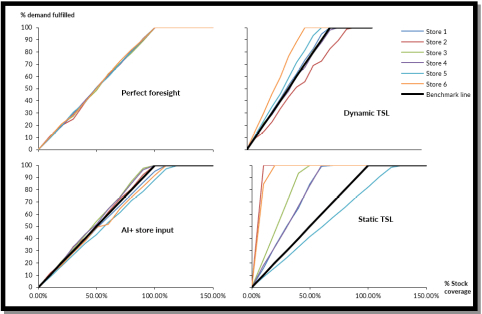
在这个实验中,下图显示了已售出商品件数所占的百分比,它取决于当时满足总需求的库存能力。
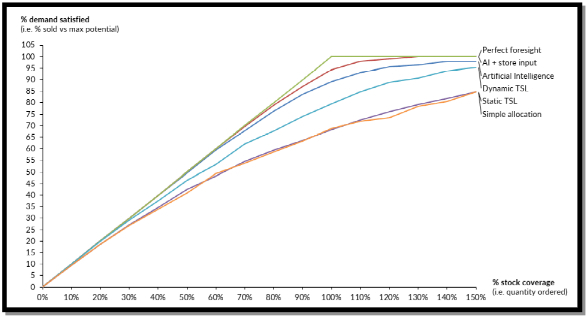
正如你在上图看到的,为了满足 100% 的需求,随着预测误差的增加,你需要更多的库存。例如,凭借完美的预测,你可以用 100% 的库存实现 100% 的潜在销售额。但是,逐渐地,较差的方法需要 120%、140% 等等。这就是为什么在美国,每 1 美元的销售额就有超过 1.40 美元的平均库存!
下图显示了在所述期间结束时的剩余数量:
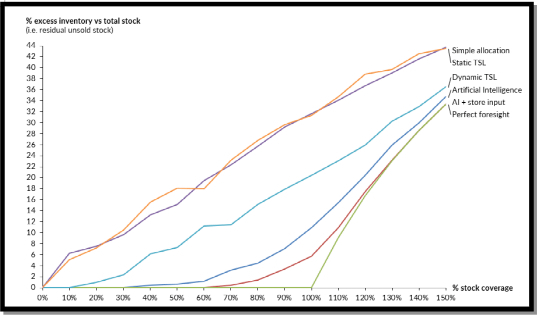
如果总可用性低于(或高于)给定期间的需求,那么动态 TSL 将在总库存覆盖率的 10% 时就会脱离总预测结果的基准曲线,从而导致缺货问题。这种偏离理想行为的情况在有人类输入的情况下发生在 60% 处,在没有人类输入的情况下发生在 30% 处,而在实施静态补货政策时,这种情况几乎是立即发生的。
预测的正确率越低,每条销售曲线的趋势就越平缓,且离二等分线越远,如下图所示,静态 TSL 会导致整体损失约 63%。
关键知识
一些真正有趣的,尽管是技术性的见解(嘿,这毕竟是 TDS!):
静态库存分配几乎从来就不是一件好事,它简直就是一件糟糕的事情。在某些地方,它很少能够满足需求,而其他地方,最终的库存量却太多。
像传统的 TSL 这样简单的预测并不足以从现有库存中获得最大的利润。生成最优库存预测的唯一有效方法是定期向模型输入新数据,这样它就能够学习并优化自己的计算。
人工智能本身并不能达到人工智能和人类专家共同合作的水平。当员工可以输入他们自己的业务规则,指定他们自己的补货结果并对结果进行评分时,人工智能的表现就非常接近于回顾中产生的“完美预见”的库存分配,从而为每家商店的每个商品带来高度优化的库存水平。
目标库存水平(TSL)创建一个固定的、定期的供应订单。但是,随着过剩的库存导致利润的浪费,其局限性也变得明显。
当你考虑到这些旧的库存管理系统使用哪些因素来确定要订购多少库存时,这样的限制就不足为奇了。简而言之,答案就是历史数据。这一切都很好,但是,它却忽略了那些非常重要的外在因素,比如市场趋势、市场竞争。以及天气(对英国人来说是众所周知的棘手话题)。
传统的库存管理解决方案使用公式来获得静态数字。但是,这真的是前进的方向吗?
依靠公式来应对需求不仅不够灵活,而且还会破坏商业价值。
这些基于公式的传统库存管理解决方案以公司为中心,并没有考虑到客户通过网络、社交媒体和竞争对手市场所表达的观点。
作者介绍:
Fabrizio Fantini,博士兼首席执行官,致力于数十亿人类的科学。
原文链接:




