

2021 年初,在 InfoQ 全年技术趋势展望中,数据湖与数据仓库的融合,成为大数据领域的趋势重点。直至年末,关于二者的讨论依然热烈,行业内的主要分歧点在于数据湖、数据仓库对存储系统访问、权限管理等方面的把控;行业内的主要共识点则是二者结合必能降低大数据分析的成本,提高易用性。
而此类争论,又反映了行业在大数据处理领域的核心诉求:如何通过数据湖、数据仓库的设计,有效满足现代化应用的数据架构要求。亚马逊云科技作为行业头部云厂商,也推出了与数据湖、数据仓库融合相关的“智能湖仓”。为什么“智能湖仓”可以更智能地集成数据湖、数据仓库和其他数据处理服务?“智能湖仓”架构备受关注意味着什么?在技术行业风向标的 2021 亚马逊云科技 re:Invent 大会上,我们看到了“智能湖仓”架构的现在和未来构想。
被广泛关注的“智能湖仓”架构
理解“智能湖仓”架构的现在和未来,需要先了解它的过去。早在 2017 年,“智能湖仓”架构就已初具雏形。当时,亚马逊云科技发布了 Amazon Redshift Spectrum,让 Amazon Redshift 具备了打通数据仓库和数据湖的能力,实现了跨数据湖、数据仓库的数据查询。
这件事情启发了“智能湖仓”架构的形成。在 2020 年的亚马逊云科技 re:Invent 大会上,亚马逊云科技正式发布“智能湖仓”。如果从早期的技术探索开始算起,在 2021 亚马逊云科技 re:Invent 大会上发布的 Serverless 能力,代表了“智能湖仓”架构的第 8 轮技术演进。如今,“智能湖仓”基于 Amazon S3 构建数据湖,绕湖集成数据仓库、大数据处理、日志分析、机器学习数据服务,利用 Amazon Lake Formation、Amazon Glue 等工具可以实现数据的自由流动与统一治理。
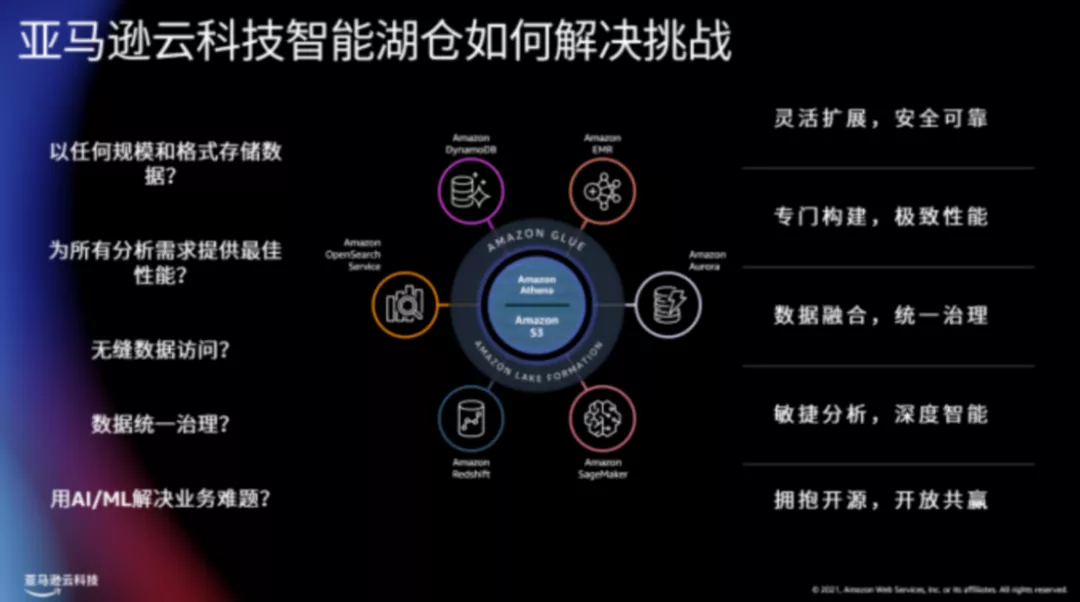
具体而言,“智能湖仓”架构下,首先需要打破数据孤岛形成一个数据湖;其次,需要围绕着数据湖,在不同应用场景为用户提供相应的分析工具;另外,需要确保数据在湖、仓以及专门的服务之间能够自由移动;此外,需要确保用统一的方式去管理湖里面数据的安全性、访问控制和审计;最终,需要能够采用低成本的方法将湖、仓各自的优势有效利用起来,并利用人工智能等创新手段进行创新。
就像 Amazon Redshift 在 2012 年发布时,引导了云原生数仓的发展方向一样,“智能湖仓”架构一经发布就引发业内广泛关注,一方面是因为亚马逊云科技作为头部云厂商的行业地位,另一方面是因为此架构在技术上的创新思路能够为行业带来一些新的思考。
“智能湖仓”更强调“架构”而非“产品”,更强调数据的自由流动与统一治理,以及基于湖仓的“智能创新”。如今,“智能湖仓”架构不是简单地将湖与仓打通,而是将湖、仓与专门构建的数据服务连接成为一个整体,让数据在其间无缝移动。面对向 TB 级、PB 级,甚至 EB 级增长的数据,“如何存”和“如何用”不再是相对孤立的话题。“智能湖仓”向行业传递了一个信号:企业需要统一数据分析工具,实现数据在整个数据平台的自由流转。
不管是企业数据管理理念的视角,还是在技术视角下,“智能湖仓”架构被广泛关注也意味着,随着数据湖和数据仓库的边界在逐渐淡化,基于两者的大数据处理体系的架构正在被重构。
“智能湖仓”架构下,重构中的大数据基础设施
这种重构大概可以分为几个维度来理解,其中最重要的是更强的数据安全、治理和数据共享能力,更敏捷的构建方式,更智能的创新手段。
数据安全、治理和共享,重点聚焦跨湖、跨仓库甚至跨企业的数据流通和治理,致力于实现真正意义上的数据跨域互通;更敏捷的构建方式则要将企业的敏态追求提升到极致,Serverless 能力的应用是其关键;更智能的创新手段则把 AI/ML 能力和大数据治理并入统一范畴,避免走入“为了大数据而大数据”的误区。
在 2022 年,当我们再次谈起数据湖和数据仓库的融合问题时,包含以上关键点的“智能湖仓”架构,很可能成为被业内重点参考的构建思路之一。
更强的数据安全、治理和数据共享能力
数据的安全、治理和共享,原是大数据的本职任务,但当数据达到 PB 乃至 EB 级,需要跨多个区域、组织、账户进行数据共享或数据交互时,企业有些时候并非不想细颗粒度管理数据,而是无法管理。这种颗粒度的权限控制往往比单机系统设计或者单一的分布式系统要复杂得多。所以,数据治理成为了“智能湖仓”重要的发力点。
在 2021 亚马逊云科技 re:Invent 大会上,支撑数据统一治理和自由流动能力的“智能湖仓”组件 Amazon Lake Formation 发布了多项新功能。除了之前早已支持的表和列级安全,Amazon Lake Formation 现在支持行和单元级权限,通过只限制用户对部分数据的访问权限,让限制访问敏感信息变得更加简单。
此外,Data mesh 的概念在 2021 亚马逊云科技 re:Invent 大会上也被提及。Data mesh 概念也是 Gartner 提出的十大数据技术趋势之一。在 Data mesh 模式下,“智能湖仓”能够实现领域数据成为产品、轻松启用细粒度授权、数据更容易被使用、数据调用跨企业可见和联邦的数据管控与合规。这意味着,“智能湖仓”架构下,Data mesh 可以实现跨数据湖的数据共享和计算。亚马逊云科技借助自身数据湖安全、tag 级别的访问控制和共享能力,为 Data mesh 提供了实现方式与手段,让 Data mesh 概念走向落地。
更敏捷的构建方式
除了更强的数据安全、治理和数据共享能力,更敏捷的构建方式也是绝大多数企业当下主要关注的技术创新之一。敏捷在企业间的认可度和应用程度越来越高,而“智能湖仓”原本就是敏捷的架构。在“智能湖仓”架构中,Amazon Lake Formation 能够将建立数据湖的时间从数月缩短到数天。用户可以使用像 Amazon Glue 这样的 Serverless 数据集成工具快速实现数据入湖;使用 Amazon Athena 这样的 Serverless 查询引擎直接实现基于 SQL 语言的湖上数据查询分析。无论是超大型公司还是工作室,都可以从这种敏捷的构建方式中快速获益,提取数据的价值。
为了让构建方式更敏捷,在 2021 亚马逊云科技 re:Invent 大会上,亚马逊云科技宣布推出更多数据分析服务的无服务器版,借助无服务器的能力,让用户可以更敏捷地构建自己的数据存储、分析、智能应用解决方案。
Amazon Redshift Serverless ,让数据仓库更敏捷,支持在几秒钟内自动设置和扩展资源,用户无需管理数据仓库集群,实现 PB 级数据规模运行高性能分析工作负载;
Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless ,让流式数据接入与处理,支持快速扩展资源,简化实时数据摄取和流式传输,实现全面监控、移动甚至跨集群加载分区,自动调配和扩展计算和存储资源,让用户可以按需使用 Kafka;
Amazon EMR Serverless 让大数据处理更敏捷,用户无需部署、管理和扩展底层基础设施,使用开源大数据框架(如 Apache Spark、Hive 和 Presto)运行分析型应用程序;
Amazon Kinesis Data Streams on Demand 让流式数据分析与实时数据场景搭建更敏捷。每分钟可以处理数 GB 的写入和读取吞吐量,而不必预置与管理服务器、存储,在成本和性能之间取得平衡且变得更加简单。

来自亚马逊云科技的数据显示,现在每天有数以万计的用户每天在使用 Amazon Redshift 处理超过 2EB 的数据。全球最大的制药公司之一罗氏制药(Roche)首席云平台和机器学习工程师 Yannick Misteli 博士表示:“Amazon Redshift Serverless 可减轻运营负担,降低成本,并帮助罗氏制药规模化实践 Go-to-Market 策略。这种极简的方式改变了游戏规则,帮助我们快速上手并支持各种繁重的分析场景。”
更智能的创新手段
正如 Yannick Misteli 提到的一样,近些年来,底层的技术创新推动业务层的改变,而业务层的诉求也倒逼底层技术的进步。游戏规则正在技术升级中改变。如今,“智能”是绝大多数技术的演进目标。在亚马逊云科技的“智能湖仓”架构中,也将“智能”提到了一个相当重要的位置。
“智能湖仓”架构下,数据库服务与人工智能和机器学习深度集成。在具体的产品上,亚马逊云科技提供了 Amazon Aurora ML、Amazon Neptune ML、Amazon Redshift ML 等诸多数据库原生的机器学习服务。
同时,在“智能湖仓”架构中,还有云原生人工智能平台 Amazon SageMaker ,它提供了多类机器学习库和开发工具包,帮助用户快速构建人工智能应用。当用户需要面对大量数据处理场景时,可以使用 Amazon SageMaker 内置的工具轻松快速连接到 Amazon EMR 集群进行大数据处理。而 Amazon EMR Serverless,也帮助人工智能相关的数据处理与分析变得足够敏捷。
在 Gartner 2021 年发布的报告《Magic Quadrant for Cloud Database Management Systems》中,亚马逊云科技连续 7 年被评为“领导者”,这项报告面向的主要是对各大厂商提供的云数据库、云数据分析工具进行全景评估,并给出最终位置的“测评报告”,含金量可见一斑。亚马逊云科技参与评测的产品均为“智能湖仓”架构中的代表产品,这个“领导者地位”背后代表的技术成熟度不言自明。
我们可以看到,“智能湖仓”提供的每一款服务工具的迭代,都在向更敏捷、更安全、更智能的数据架构目标迈进。数据架构作为企业数字化转型的最底层,也是应用现代化的底层动力。“智能湖仓”带来的数据管理方式的变革,也承载着亚马逊云科技对应用现代化的构想。
写在最后
回到文章开篇提到的问题,目前行业内已经形成了数据湖和数据仓库的融合必将降低大数据分析成本的共识,主要分歧点在于数据湖、数据仓库对存储系统访问、权限管理等方面的把控。在这些方面,亚马逊云科技的“智能湖仓”架构围绕这些问题都提供了相关的工具或服务。
无论是在数据基础架构、统一分析还是业务创新上,从连接数据湖和数据仓库到跨数据库、跨域共享,“智能湖仓”在实际的业务场景中并非孤立存在,而是与应用程序紧密相连。
底层数据架构的现代化演进,也将为企业乃至全行业带来更大的价值。数据,作为与土地、劳动力、资本、技术并列的“第五大生产要素”,重要性不言而喻。如今,亚马逊云科技“智能湖仓”架构在企业中的实践,已经为企业构建现代化数据平台提供了一条可供遵循的路径。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论