
数据仓库的数据体系严格、治理容易,业务规模越大,ROI 越高;数据湖的数据种类丰富,治理困难,业务规模越大,ROI 越低,但胜在灵活。
现在,鱼和熊掌我都想要,应该怎么办?湖仓一体架构就在这种情况下,快速在产业内普及。
要构建湖仓一体架构并不容易,需要解决非常多的数据问题。比如,计算层、存储层、异构集群层都要打通,对元数据要进行统一的管理和治理。对于很多业内技术团队而言,已经是个比较大的挑战。
可即便如此,在亚马逊云科技技术专家潘超看来,也未必最能贴合企业级大数据处理的最新理念。在 11 月 18 日晚上 20:00 的直播中,潘超详细分享了亚马逊云科技眼中的智能湖仓架构,以及以流式数据接入为主的最佳实践。
现代化数据平台架构的关键指标
传统湖仓一体架构的不足之处是,着重解决点的问题,也就是“湖”和“仓”的打通,而忽视了面的问题:数据在整个数据平台的自由流转。
潘超认为,现代数据平台架构应该具有几个关键特征:
以任何规模来存储数据;
在整套架构涉及的所有产品体系中,获得最佳性价比;
实现无缝的数据访问,实现数据的自由流动;
实现数据的统一治理;
用 AI/ML 解决业务难题;
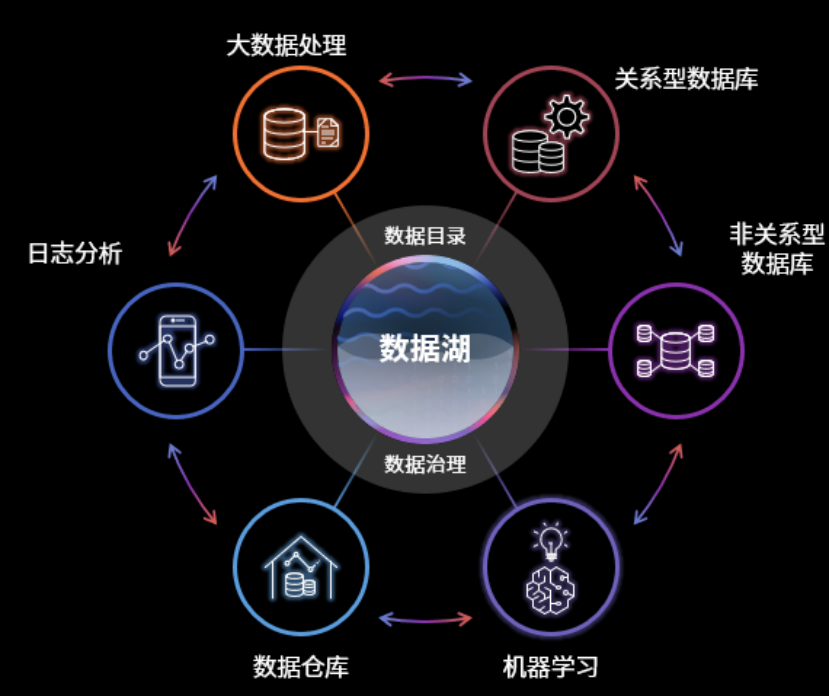
在构建企业级现代数据平台架构时,这五个关键特征,实质上覆盖了三方视角 ——
对于架构师而言,第一点和第二点值得引起注意。前者是迁移上云的一大核心诉求,后者是架构评审一定会过问的核心事项;
对于开发者而言,第三点和第四点尤为重要,对元数据的管理最重要实现的是数据在整个系统内的自由流动和访问,而不仅仅是打通数据湖和数据仓库;
对于产品经理而言,第五点点明了当下大数据平台的价值导向,即数据的收集和治理,应以解决业务问题为目标。
为了方便理解,也方便通过 Demo 演示,潘超将这套架构体系,同等替换为了亚马逊云科技现有产品体系,包括:Amazon Athena、Amazon Aurora 、Amazon MSK、Amazon EMR 等,而流式数据入湖,重点涉及 Amazon MSK、Amazon EMR,以及另一个核心服务:Apache Hudi。
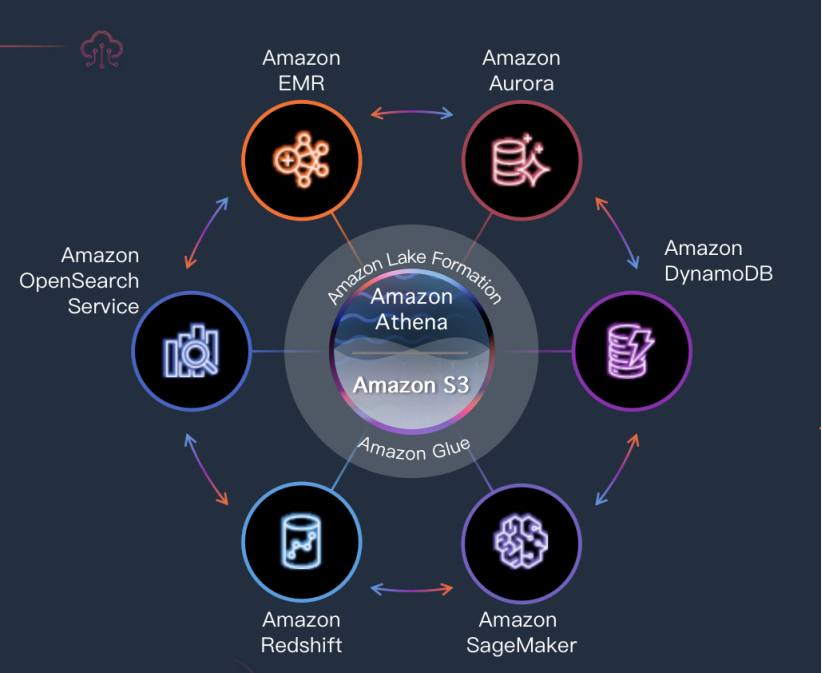
Amazon MSK 的扩展能力与最佳实践
Amazon MSK 是亚马逊托管的高可用、强安全的 Kafka 服务,是数据分析领域,负责消息传递的基础,也因此在流式数据入湖部分举足轻重。
之所以以 Amazon MSK 举例,而不是修改 Kafka 代码直接构建这套系统,是为了最大程度将开发者的注意力聚焦于流式应用本身,而不是管理和维护基础设施。况且,一旦你决定从头构建 PaaS 层基础设施,涉及到的工作就不仅仅是拉起一套 Kafka 集群了。一张图可以很形象地反映这个问题:
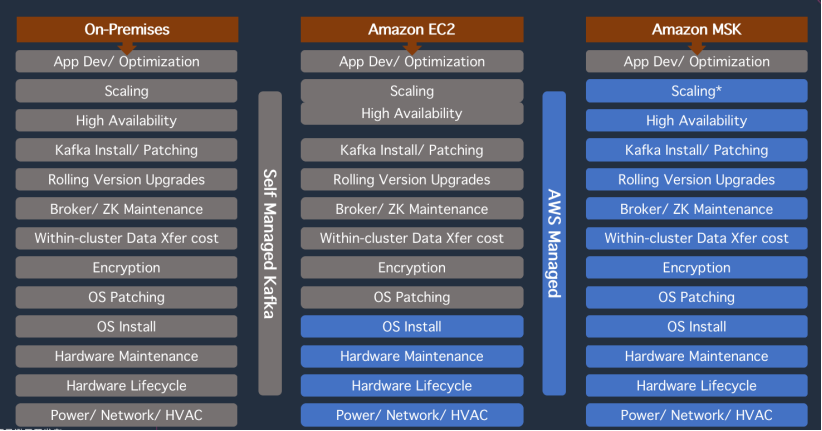
这张图从左至右,依次为不使用任何云服务的工作列表,使用 EC2 的工作列表,以及使用 MSK 的工作列表,工作量和 ROI 高下立现。
而对于 MSK 来说,扩展能力是其重要特性。MSK 可以自动扩容,也可以手动 API 扩容。但如果对自己的“动手能力”没有充足的信心,建议选择自动扩容。
Amazon MSK 的自动扩容可以根据存储利用率来设定阈值,建议设定 50%-60%。自动扩容每次扩展 Max(10GB,10%* 集群存储空间),同时自动扩展每次有6 个小时的冷却时间。一次如果一次需要扩容更大的容量,可以使用手动扩容。
这种扩容既包括横向扩容 —— 通过 API 或者控制台向集群添加新的 Brokers,期间不会影响集群的可用性,也包括纵向扩容 —— 调整集群 Broker 节点的 EC2 实例类型。
但无论是自动还是手动,是横向还是纵向,前提都是你已经做好了磁盘监控,可以使用 CloudWatch 云监控集成的监控服务,也可以在 MSK 里勾选其他的监控服务 (Prometheus),最终监控结果都能可视化显示。
需要注意的是,MSK 集群增加 Broker,每个旧 Topic 的分区如果想重分配,需要手动执行。重分配的时候,会带来额外的带宽,有可能会影响业务,所以可以通过一些参数控制 Broker 间流量带宽,防止过程当中对业务造成太大的影响。当然像 Cruise 一样的开源工具,也可以多多用起来。Cruise 是做大规模集群的管理的 MSK 工具,它可以帮你做 Broker 间负载的 Re-balance 。
关于 MSK 集群的高可用,有三点需要注意:
对于两 AZ 部署的集群,副本因子至少保证为 3。如果只有 1,那么当集群滚动升级的时候,就不能对外提供服务了;
最小的 ISR(in-sync replicas)最多设置为 RF - 1,不然也会影响集群的滚动升级;
当客户端连接 Broker 节点时,虽然配置一个 Broker 节点的连接地址就可以,但还是建议配置多个。MSK 故障节点自动替换以及在滚动升级的过程中,如果客户端只配备了一个 Broker 节点,可能会链接超时。如果配置了多个,还可以重试连接。
在 CPU 层面,CloudWatch 里有两个关于 MSK 的指标值得注意,一个是 CpuSystem,另一个是 CpuUser,推荐保持在 60% 以下,这样在 MSK 升级维护时,都有足够的 CPU 资源可用。
如果 CPU 利用率过高,触发报警,则可以通过以下几种方式来扩展 MSK 集群:
垂直扩展,通过滚动升级进行替换。每个 Broker 的替换大概需要 10-15 分钟的时间。当然,是否替换集群内所有机器,要根据实际情况做选择,以免造成资源浪费;
横向拓展,Topic 增加分区数;
添加 Broker 到集群,之前创建的 Topic 进行 reassign Partitions,重分配会消耗集群资源,当然这是可控的。
最后,关于 ACK 参数的设置也值得注意,ACK = 2 意味着在生产者发送消息后,等到所有副本都接收到消息,才返回成功。这虽然保证了消息的可靠性,但吞吐率最低。比如日志类数据,参考业务具体情况,就可以酌情设置 ACK = 1,容忍数据丢失的可能,但大幅提高了吞吐率。
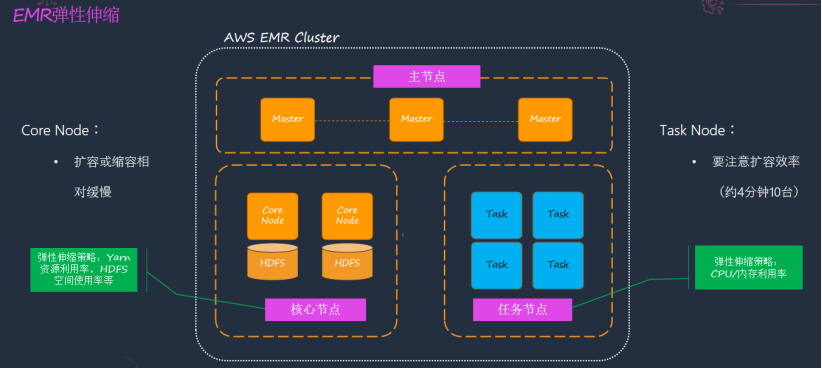
Amazon EMR 存算分离及资源动态扩缩
Amazon EMR 是托管的 Hadoop 生态,常用的 Hadoop 组件在 EMR 上都会有,但是 EMR 核心特征有两点,一是存算分离,二是资源动态扩缩。
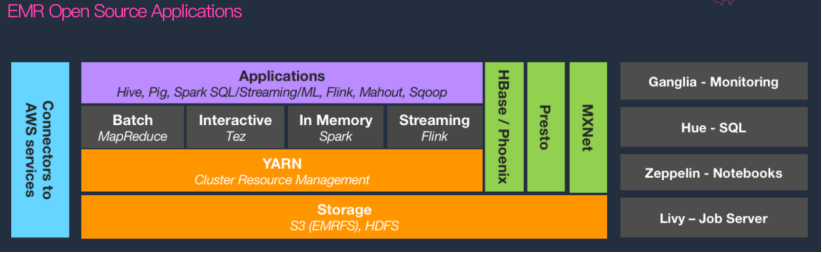
在大数据领域,存算分离概念的热度,不下于流批一体、湖仓一体。以亚马逊云科技产品栈为例,实现存算分离后,数据是在 S3 上存储,EMR 只是一个计算集群,是一个无状态的数据。而数据与元数据都在外部,集群简化为无状态的计算资源,用的时候打开,不用的时候关闭就可以。
举个例子,凌晨 1 点到 5 点,大批 ETL 作业,开启集群。其他时间则完全不用开启集群。用时开启,不用关闭,对于上云企业而言,交服务费就像交电费,格外节省。
而资源的动态扩缩主要是指根据不同的工作负载,动态扩充节点,按使用量计费。但如果数据是在 HDFS 上做存算分离与动态扩缩,就不太容易操作了,扩缩容如果附带 DataNote 数据,就会引发数据的 Re-balance,非常影响效率。如果单独扩展 NodeManager,在云下的场景,资源不再是弹性的,集群也一般是预制好的,与云上有本质区别。
EMR 有三类节点,第一类是 Master 主节点,部署着 Resource Manager 等服务;Core 核心节点,有 DataNote,NodeManager, 依然可以选用 HDFS;第三类是任务节点,运行着 EMR 的 NodeManager 服务,是一个计算节点。所以,EMR 的扩缩,在于核心节点与任务节点的扩缩,可以根据 YARN 上 Application 的个数、CPU 的利用率等指标配置扩缩策略。也可以使用 EMR 提供 Managed Scaling 策略其内置了智能算法来实现自动扩缩,也是推荐的方式,对开发者而言是无感的。
EMR Flink Hudi 构建数据湖及 CDC 同步方案
那么应该如何利用 MSK 和 EMR 做数据湖的入湖呢?其详细架构图如下,分作六步详解:
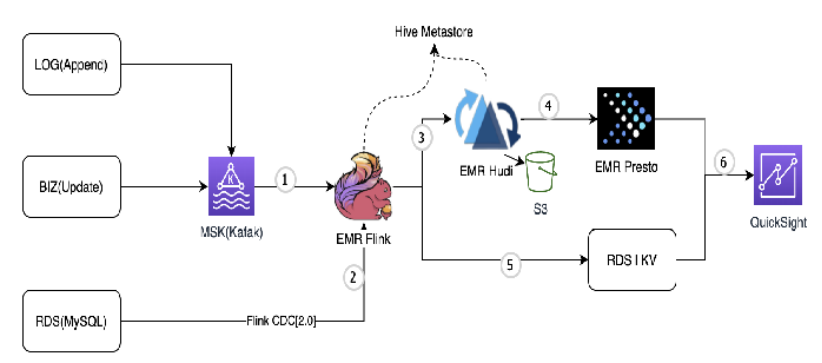
图中标号 1:日志数据和业务数据发送⾄MSK(Kafka),通过 Flink(TableAPI) 建立 Kafka 表,消费 Kafka 数据,Hive Metastore 存储 Schema;
图中标号 2:RDS(MySQL) 中的数据通过 Flink CDC(flink-cdc-connector) 直接消费 Binlog 数据,⽆需搭建其他消费 Binlog 的服务 (⽐如 Canal,Debezium)。注意使⽤flink-cdc-connector 的 2.x 版本,⽀持 parallel reading, lock-free and checkpoint feature;
图中标号 3:使用 Flink Hudi Connector, 将数据写⼊Hudi(S3) 表, 对于⽆需 Update 的数据使⽤Insert 模式写⼊,对于需要 Update 的 数据 (业务数据和 CDC 数据) 使用 Upsert 模式写⼊;
图中标号 4:使用 Presto 作为查询引擎,对外提供查询服务。此条数据链路的延迟取决于入 Hudi 的延迟及 Presto 查询的延迟,总体在分钟级别;
图中标号 5:对于需要秒级别延迟的指标,直接在 Flink 引擎中做计算,计算结果输出到 RDS 或者 KV 数据库,对外提供 API 查询服务;
图中标号 6:使用 QuickSight 做数据可视化,支持多种数据源接入。
当然,在具体的实践过程中,仍需要开发者对数据湖方案有足够的了解,才能切合场景选择合适的调参配置。
Q/A 问答
1. 如何从 Apache Kafka 迁移至 Amazon MSK?
MSK 托管的是 Apache Kafka,其 API 是完全兼容的,业务应用代码不需要调整,更换为 MSK 的链接地址即可。如果已有的 Kafka 集群数据要迁移到 MSK,可以使用 MirrorMaker2 做数据同步,然后切换应用链接地址即可。
参考文档:
2. MSK 支持 schema registry 吗?
MSK 支持 Schema Registry, 不仅支持使用 AWS Glue 作为 Schema Registry, 还支持第三方的比如 confluent-schema-registry
3.MySQL cdc 到 hudi 的延迟如何?
总体来讲是分钟级别延迟。和数据量,选择的 Hudi 表类型,计算资源都有关系。
4. Amazon EMR 比标准 Apache Spark 快多少?
Amazon EMR 比标准 Apache Spark 快 3 倍以上。
Amazon EMR 在 Spark3.0 上比开源 Spark 快 1.7 倍,在 TPC-DS 3TB 数据的测试。
参见:
Amazon EMR 在 Spark 2.x 上比开源 Spark 快 2~3 倍以上
Amazon Presto 比开源的 PrestoDB 快 2.6 倍。
参见:
5. 智能湖仓和湖仓一体的区别是什么?
这在本次分享中的现代化数据平台建设和 Amazon 的智能湖仓架构图中都有所体现,Amazon 的智能湖仓架构灵活扩展,安全可靠 ; 专门构建,极致性能 ; 数据融合,统一治理 ; 敏捷分析,深度智能 ; 拥抱开源,开发共赢。湖仓一体只是开始,智能湖仓才是终极。
re:Invent 正在拉斯维加斯同步举办,今年是 re:Invent 的第十年,今天 Keynote 上 Adam 为我们提出的从未设想过的“数据之旅”,从数据湖扩展与安全出发,发布了 Row and cell-level security for Lake Formation,实现了海量数据的精细化管理。同时,顺应云计算时代无服务器化的技术发展趋势,同时发布了四款当前云上专门数据分析工具的无服务器版本。成为了行业内全栈式无服务器数据分析的先行者。大数据分析的易用性再次提升,体验在云上操作数据举重若轻的感觉。相关发布内容可以注册观看大会直播。

5 附录:操作代码实施
1. 创建 EMR 集群
log_uri="s3://*****/emr/log/"key_name="****"jdbc="jdbc:mysql:\/\/*****.ap-southeast-1.rds.amazonaws.com:3306\/hive_metadata_01?createDatabaseIfNotExist=true"cluster_name="tech-talk-001"aws emr create-cluster \--termination-protected \--region ap-southeast-1 \--applications Name=Hadoop Name=Hive Name=Flink Name=Tez Name=SparkName=JupyterEnterpriseGateway Name=Presto Name=HCatalog \--scale-down-behavior TERMINATE_AT_TASK_COMPLETION \--release-label emr-6.4.0 \--ebs-root-volume-size 50 \--service-role EMR_DefaultRole \--enable-debugging \--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m5.xlargeInstanceGroupType=CORE,InstanceCount=2,InstanceType=m5.xlarge \--managed-scaling-policyComputeLimits='{MinimumCapacityUnits=2,MaximumCapacityUnits=5,MaximumOnDemandCapacityUnits=2,MaximumCoreCapacityUnits=2,UnitType=Instances}' \--name "${cluster_name}" \--log-uri "${log_uri}" \--ec2-attributes '{"KeyName":"'${key_name}'","SubnetId":"subnet-0f79e4471cfa74ced","InstanceProfile":"EMR_EC2_DefaultRole"}' \--configurations '[{"Classification": "hive-site","Properties":{"javax.jdo.option.ConnectionURL": "'${jdbc}'","javax.jdo.option.ConnectionDriverName":"org.mariadb.jdbc.Driver","javax.jdo.option.ConnectionUserName":"admin","javax.jdo.option.ConnectionPassword": "xxxxxx"}}]'2. 创建 MSK 集群
# MSK集群创建可以通过CLI, 也可以通过Console创建# 下载kafka,创建topic写⼊数据wget https://dlcdn.apache.org/kafka/2.6.2/kafka_2.12-2.6.2.tgz# msk zk地址,broker 地址zk_servers=*****.c3.kafka.ap-southeast-1.amazonaws.com:2181bootstrap_server=******.5ybaio.c3.kafka.ap-southeast-1.amazonaws.com:9092topic=tech-talk-001# 创建tech-talk-001 topic./bin/kafka-topics.sh --create --zookeeper ${zk_servers} --replication-factor 2 --partitions 4--topic ${topic}# 写⼊消息./bin/kafka-console-producer.sh --bootstrap-server ${bootstrap_server} --topic ${topic}{"id":"1","name":"customer"}{"id":"2","name":"aws"}# 消费消息./bin/kafka-console-consumer.sh --bootstrap-server ${bootstrap_server} --topic ${topic}3.EMR 启动 Flink
# 启动flink on yarn session cluster# 下载kafka connectorsudo wget -P /usr/lib/flink/lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql?connector-kafka_2.12/1.13.1/flink-sql-connector-kafka_2.12-1.13.1.jar && sudo chown flink:flink/usr/lib/flink/lib/flink-sql-connector-kafka_2.12-1.13.1.jar# hudi-flink-bundle 0.10.0sudo wget -P /usr/lib/flink/lib/ https://dxs9dnjebzm6y.cloudfront.net/tmp/hudi-flink?bundle_2.12-0.10.0-SNAPSHOT.jar && sudo chown flink:flink /usr/lib/flink/lib/hudi-flink?bundle_2.12-0.10.0-SNAPSHOT.jar# 下载 cdc connectorsudo wget -P /usr/lib/flink/lib/ https://repo1.maven.org/maven2/com/ververica/flink-sql?connector-mysql-cdc/2.0.0/flink-sql-connector-mysql-cdc-2.0.0.jar && sudo chown flink:flink/usr/lib/flink/lib/flink-sql-connector-mysql-cdc-2.0.0.jar# flink sessionflink-yarn-session -jm 1024 -tm 4096 -s 2 \-D state.checkpoints.dir=s3://*****/flink/checkpoints \-D state.backend=rocksdb \-D state.checkpoint-storage=filesystem \-D execution.checkpointing.interval=60000 \-D state.checkpoints.num-retained=5 \-D execution.checkpointing.mode=EXACTLY_ONCE \-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \-D state.backend.incremental=true \-D execution.checkpointing.max-concurrent-checkpoints=1 \-D rest.flamegraph.enabled=true \-d4.Flink SQL 客户端
# 这是使⽤flink sql client写SQL提交作业# 启动client/usr/lib/flink/bin/sql-client.sh -s application_*****# result-modeset sql-client.execution.result-mode=tableau;# set default parallesimset 'parallelism.default' = '1';5. 消费 Kafka 写⼊Hudi
# 创建kafka表CREATE TABLE kafka_tb_001 (id string,name string,`ts` TIMESTAMP(3) METADATA FROM 'timestamp') WITH ('connector' = 'kafka','topic' = 'tech-talk-001','properties.bootstrap.servers' = '****:9092','properties.group.id' = 'test-group-001','scan.startup.mode' = 'latest-offset','format' = 'json','json.ignore-parse-errors' = 'true','json.fail-on-missing-field' = 'false','sink.parallelism' = '2');# 创建flink hudi表CREATE TABLE flink_hudi_tb_106(uuid string,name string,ts TIMESTAMP(3),logday VARCHAR(255),hh VARCHAR(255))PARTITIONED BY (`logday`,`hh`)WITH ('connector' = 'hudi','path' = 's3://*****/teck-talk/flink_hudi_tb_106/','table.type' = 'COPY_ON_WRITE','write.precombine.field' = 'ts','write.operation' = 'upsert','hoodie.datasource.write.recordkey.field' = 'uuid','hive_sync.enable' = 'true','hive_sync.metastore.uris' = 'thrift://******:9083','hive_sync.table' = 'flink_hudi_tb_106','hive_sync.mode' = 'HMS','hive_sync.username' = 'hadoop','hive_sync.partition_fields' = 'logday,hh','hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.MultiPartKeysValueExtractor');# 插⼊数据insert into flink_hudi_tb_106 select id as uuid,name,ts,DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy?MM-dd') as logday, DATE_FORMAT(CURRENT_TIMESTAMP, 'hh') as hh from kafka_tb_001;# 除了在创建表是指定同步数据的⽅式,也可以通过cli同步hudi表元数据到hive,但要注意分区格式./run_sync_tool.sh --jdbc-url jdbc:hive2:\/\/*****:10000 --user hadop --pass hadoop --partitioned-by logday --base-path s3://****/ --database default --table *****# presto 查询数据presto-cli --server *****:8889 --catalog hive --schema default6.mysql cdc 同步到 hudi
# 创建mysql CDC表CREATE TABLE mysql_cdc_002 (id INT NOT NULL,name STRING,create_time TIMESTAMP(3),modify_time TIMESTAMP(3),PRIMARY KEY(id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = '*******','port' = '3306','username' = 'admin','password' = '*****','database-name' = 'cdc_test_db','table-name' = 'test_tb_01','scan.startup.mode' = 'initial');# 创建hudi表CREATE TABLE hudi_cdc_002 (id INT ,name STRING,create_time TIMESTAMP(3),modify_time TIMESTAMP(3)) WITH ('connector' = 'hudi','path' = 's3://******/hudi_cdc_002/','table.type' = 'COPY_ON_WRITE','write.precombine.field' = 'modify_time','hoodie.datasource.write.recordkey.field' = 'id','write.operation' = 'upsert','write.tasks' = '2','hive_sync.enable' = 'true','hive_sync.metastore.uris' = 'thrift://*******:9083','hive_sync.table' = 'hudi_cdc_002','hive_sync.db' = 'default','hive_sync.mode' = 'HMS','hive_sync.username' = 'hadoop');# 写⼊数据insert into hudi_cdc_002 select * from mysql_cdc_002;7. sysbench
# sysbench 写⼊mysql数据# 下载sysbenchcurl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudobashsudo yum -y install sysbench# 注意当前使用的“lua”并未提供构建,请根据自身情况定义,上述⽤到表结构如下CREATE TABLE if not exists `test_tb_01` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(155) DEFAULT NULL,`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,`modify_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;# 创建表sysbench creates.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1 run# 插⼊数据sysbench insert.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=500 --time=0 --threads=1 --skip_trx=true run# 更新数据sysbench update.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1000 --time=0 --threads=10 --skip_trx=true --update_id_min=3 --update_id_max=500 run# 删除表sysbench drop.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1 run



