在利用深度学习网络进行预测性分析之前,我们首先需要对其加以训练。目前市面上存在着大量能够用于神经网络训练的工具,但 TensorFlow 无疑是其中极为重要的首选方案之一。

大家可以利用 TensorFlow 训练自己的机器学习模型,并利用这些模型完成预测性分析。训练通常由一台极为强大的设备或者云端资源完成,但您可能想象不到的是,TensorFlow 亦可以在 iOS 之上顺利起效——只是存在一定局限性。
在今天的博文中,我们将共同了解 TensorFlow 背后的设计思路、如何利用其训练一套简单的分类器,以及如何将上述成果引入您的 iOS 应用。
在本示例中,我们将使用“根据语音与对话分析判断性别”数据集以了解如何根据音频记录判断语音为男声抑或女声。
获取相关代码:大家可以通过GitHub 上的对应项目获取本示例的源代码。
TensorFlow 是什么,我们为何需要加以使用?
TensorFlow 是一套用于构建计算性图形,从而实现机器学习的软件资源库。
其它一些工具往往作用于更高级别的抽象层级。以 Caffe 为例,大家需要将不同类型的“层”进行彼此互连,从而设计出一套神经网络。而 iOS 平台上的 BNNS 与 MPSCNN 亦可实现类似的功能。
在 TensorFlow 当中,大家亦可处理这些层,但具体处理深度将更为深入——甚至直达您算法中的各项计算流程。
大家可以将 TensorFlow 视为一套用于实现新型机器学习算法的工具集,而其它深度学习工具则用于帮助用户使用这些算法。
当然,这并不是说用户需要在 TensorFlow 当中从零开始构建一切。TensorFlow 拥有一整套可复用的构建组件,同时囊括了 Keras 等负责为 TensorFlow 用户提供大量便捷模块的资源库。
因此 TensorFlow 在使用当中并不强制要求大家精通相关数学专业知识,当然如果各位愿意自行构建,TensorFlow 也能够提供相应的工具。
利用逻辑回归实现二元分类
在今天的博文当中,我们将利用逻辑回归(logistic regression)算法创建一套分类器。没错,我们将从零开始进行构建,因此请大家做好准备——这可是项有点复杂的任务。所谓分类器,其基本工作原理是获取输入数据,而后告知用户该数据所归属的类别——或者种类。在本项目当中,我们只设定两个种类:男声与女声——也就是说,我们需要构建的是一套二元分类器(binary classifier)。
备注:二元分类器属于最简单的一种分类器,但其基本概念与设计思路同用于区分成百上千种不同类别的分类器完全一致。因此,尽管我们在本份教程中不会太过深入,但相信大家仍然能够从中一窥分类器设计的门径。
在输入数据方面,我们将使用包含 20 个数字朗读语音、囊括多种声学特性的给定录音。我将在后文中对此进行详尽解释,包括音频频率及其它相关信息。
在以下示意图当中,大家可以看到这 20 个数字全部接入一个名为 sum 的小框。这些连接拥有不同的 weights(权重),对于分类器而言代表着这 20 个数字各自不同的重要程度。
以下框图展示了这套逻辑分类器的起效原理:
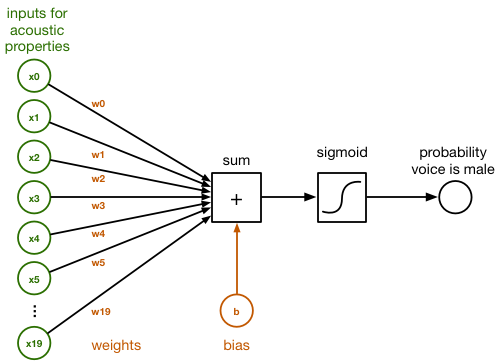
在 sum 框当中,输入数据区间为 x0 到 x19,且其对应连接的权重 w0 到 w19 进行直接相加。以下为一项常见的点积:
sum = x[0]*w[0] + x[1]*w[1] + x[2]*w[2] + ... + x[19]*w[19] + b
我们还在所谓 bias(偏离)项的末尾加上了 b。其仅仅代表另一个数字。
数组 w 中的权重与值 b 代表着此分类器所学习到的经验。对该分类器进行训练的过程,实际上是为了帮助其找到与 w 及 b 正确匹配的数字。最初,我们将首先将全部 w 与 b 设置为 0。在数轮训练之后,w 与 b 则将包含一组数字,分类器将利用这些数字将输入语音中的男声与女声区分开来。为了能够将 sum 转化为一条概率值——其取值在 0 与 1 之间——我们在这里使用 logistic sigmoid 函数:
y_pred = 1 / (1 + exp(-sum))
这条方程式看起来很可怕,但做法却非常简单:如果 sum 是一个较大正数,则 sigmoid 函数返回 1 或者概率为 100%; 如果 sum 是一个较大负数,则 sigmoid 函数返回 0。因此对于较大的正或者负数,我们即可得出较为肯定的“是”或者“否”预测结论。
然而,如果 sum 趋近于 0,则 sigmoid 函数会给出一个接近于 50% 的概率,因为其无法确定预测结果。当我们最初对分类器进行训练时,其初始预期结果会因分类器本身训练尚不充分而显示为 50%,即对判断结果并无信心。但随着训练工作的深入,其给出的概率开始更趋近于 1 及 0,即分类器对于结果更为肯定。
现在 y_pred 中包含的预测结果显示,该语音为男声的可能性更高。如果其概率高于 0.5(或者 50%),则我们认为语音为男声 ; 相反则为女声。
这即是我们这套利用逻辑回归实现的二元分类器的基本设计原理。输入至该分类器的数据为一段对 20 个数字进行朗读的音频记录,我们会计算出一条权重 sum 并应用 sigmoid 函数,而我们获得的输出概率指示朗读者应为男性。
然而,我们仍然需要建立用于训练该分类器的机制,而这时就需要请出今天的主角——TensorFlow 了。
在 TensorFlow 中实现此分类器
要在 TensorFlow 当中使用此分类器,我们需要首先将其设计转化为一套计算图(computational graph)。一项计算图由多个负责执行计算的节点组成,且输入数据会在各节点之间往来流通。
我们这套逻辑回归算法的计算图如下所示:
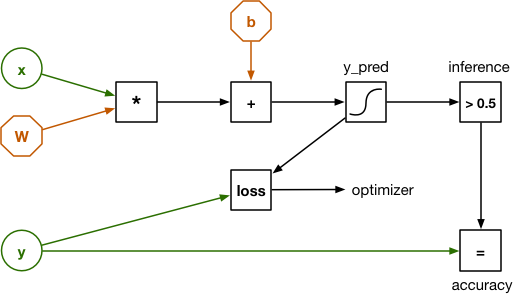
看起来与之前给出的示意图存在一定区别,但这主要是由于此处的输入内容 x 不再是 20 个独立的数字,而是一个包含有 20 个元素的向量。在这里,权重由矩阵 W 表示。因此,之前得出的点积也在这里被替换成了一项矩阵乘法。
另外,本示意图中还包含一项输入内容 y。其用于对分类器进行训练并验证其运行效果。我们在这里使用的数据集为一套包含 3168 条 example 语音记录的集合,其中每条示例记录皆被明确标记为男声或女声。这些已知男声或女声结果亦被称为该数据集的 label(标签),并作为我们交付至 y 的输入内容。
为了训练我们的分类器,这里需要将一条示例加载至 x 当中并允许该计算图进行预测:即语音到底为男声抑或是女声?由于初始权重值全部为 0,因此该分类器很可能给出错误的预测。我们需要一种方法以计算其错误的“具体程度”,而这一目标需要通过 loss 函数实现。Loss 函数会将预测结果 y_pred 与正确输出结果 y 进行比较。
在将 loss 函数提供给训练示例后,我们利用一项被称为 backpropagation(反向传播)的技术通过该计算图进行回溯,旨在根据正确方向对 W 与 b 的权重进行小幅调整。如果预测结果为男声但实际结果为女声,则权重值即会稍微进行上调或者下调,从而在下一次面对同样的输入内容时增加将其判断为“女声”的概率。
这一训练规程会利用该数据集中的全部示例进行不断重复再重复,直到计算图本身已经获得了最优权重集合。而负责衡量预测结果错误程度的 loss 函数则因此随时间推移而变低。
反向传播在计算图的训练当中扮演着极为重要的角色,但我们还需要加入一点数学手段让结果更为准确。而这也正是 TensorFlow 的专长所在:我们只要将全部“前进”操作表达为计算图当中的节点,其即可自动意识到“后退”操作代表的是反向传播——我们完全无需亲自进行任何数学运算。太棒了!
Tensorflow 到底是什么?
在以上计算图当中,数据流向为从左至右,即代表由输入到输出。而这正是 TensorFlow 中“流(flow)”的由来。不过 Tensor 又是什么?
Tensor 一词本义为张量,而此计算图中全部数据流皆以张量形式存在。所谓张量,其实际代表的就是一个 n 维数组。我曾经提到 W 是一项权重矩阵,但从 TensorFlow 的角度来看,其实际上属于一项二阶张量——换言之,一个二组数组。
一个标量代表一个零阶张量。
- 一个向量代表一个一阶张量。
- 一个矩阵代表一个二阶张量。
- 一个三维数组代表一个三阶张量。
- 之后以此类推……
这就是 Tensor 的全部含义。在卷积神经网络等深度学习方案当中,大家会需要与四维张量打交道。但本示例中提到的逻辑分类器要更为简单,因此我们在这里最多只涉及到二阶张量——即矩阵。
我之前还提到过,x 代表一个向量——或者说一个一阶张量——但接下来我们同样将其视为一个矩阵。y 亦采用这样的处理方式。如此一来,我们即可将数据库组视为整体对其 loss 进行计算。
一条简单的示例(example)语音内包含 20 个数据元素。如果大家将全部 3168 条示例加载至 x 当中,则 x 会成为一个 3168 x 20 的矩阵。再将 x 与 W 相乘,则得出的结果 y_pred 为一个 3168 x 1 的矩阵。具体来讲,y_pred 代表的是为数据集中的每条语音示例提供一项预测结论。
通过将我们的计算图以矩阵 / 张量的形式进行表达,我们可以一次性对多个示例进行预测。
安装 TensorFlow
好的,以上是本次教程的理论基础,接下来进入实际操作阶段。
我们将通过 Python 使用 TensorFlow。大家的 Mac 设备可能已经安装有某一 Python 版本,但其版本可能较为陈旧。在本教程中,我使用的是 Python 3.6,因此大家最好也能安装同一版本。
安装 Python 3.6 非常简单,大家只需要使用 Homebrew 软件包管理器即可。如果大家还没有安装 homebrew,请点击此处参阅相关指南。
接下来打开终端并输入以下命令,以安装 Python 的最新版本:
brew install python3
Python 也拥有自己的软件包管理器,即 pip,我们将利用它安装我们所需要的其它软件包。在终端中输入以下命令:
pip3 install numpy
pip3 install scipy
pip3 install scikit-learn
pip3 install pandas
pip3 install tensorflow
除了 TensorFlow 之外,我们还需要安装 NumPy、SciPy、pandas 以及 scikit-learn:
NumPy 是一套用于同 n 级数组协作的库。听起来耳熟吗?NumPy 并非将其称为张量,但之前提到了数组本身就是一种张量。TensorFlow Python API 就建立在 NumPy 基础之上。
- SciPy 是一套用于数值计算的库。其它一些软件包的起效需要以之为基础。
- pandas 负责数据集的加载与清理工作。
- scikit-learn 在某种意义上可以算作 TensorFlow 的竞争对手,因为其同样是一套用于机器学习的库。我们之所以在本项目中加以使用,是因为它具备多项便利的功能。由于 TensorFlow 与 scikit-learn 皆使用 NumPy 数组,因为二者能够顺畅实现协作。
实际上,大家无需 pandas 与 scikit-learn 也能够使用 TensorFlow,但二者确实能够提供便捷功能,而且每一位数据科学家也都乐于加以使用。
如大家所知,这些软件包将被安装在/usr/local/lib/python3.6/site-packages当中。如果大家需要查看部分未被公布在其官方网站当中的 TensorFlow 源代码,则可以在这里找到。
备注:pip 应会为您的系统自动安装 TensorFlow 的最佳版本。如果大家希望安装其它版本,则请点击此处参阅官方安全指南。另外,大家也可以利用源代码自行构建 TensorFlow,这一点我们稍后会在面向 iOS 构建 TensorFlow 部分中进行说明。
下面我们进行一项快速测试,旨在确保一切要素都已经安装就绪。利用以下内容创建一个新的 tryit.py 文件:
import tensorflow as tf
a = tf.constant([1, 2, 3])
b = tf.constant([4, 5, 6])
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(a + b))
而后通过终端运行这套脚本:
python3 tryit.py
其会显示一些与 TensorFlow 运行所在设备相关的调试信息(大多为 CPU 信息,但如果您所使用的 Mac 设备配备有英伟达 GPU,亦可能提供 GPU 信息)。最终结果显示为:
[5 7 9]
这里代表的是两个向量 a 与 b 的加和。另外,大家可能还会看到以下信息:
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
如果出现上述内容,则代表您在系统当中安装的 TensorFlow 并非当前 CPU 的最优适配版本。修复方法之一是利用源代码自行构建 TensorFlow,因为这允许大家对全部选项加以配置。但在本示例当中,由于其不会造成什么影响,因此直接忽略即可。
深入观察训练数据集
要训练分类器,我们自然需要数据。
在本项目当中,我们使用来自 Kory Becker 的“根据语音判断性别”数据集。为了能够让这份教程能够与 TensorFlow 指南上的 MNIST 数字化识别有所不同,这里我决定在 Kaggle.com 上寻找数据集,并最终选定了这一套。
那么我们到底该如何立足音频实现性别判断?下载该数据集并打开 voice.csv 文件之后,大家会看到其中包含着一排排数字:
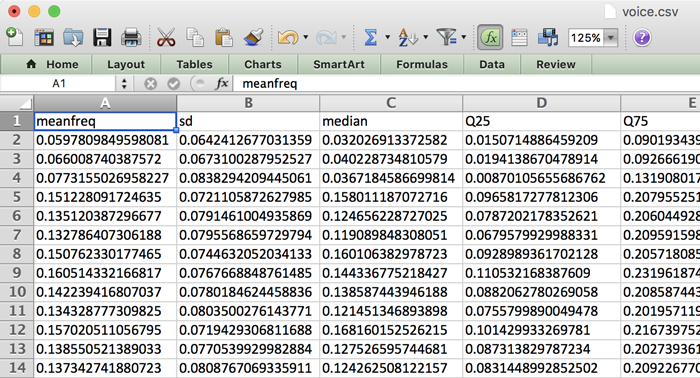
我们首先需要强调这一点,这里列出的并非实际音频数据!相反,这些数字代表着语音记录当中的不同声学特征。这些属性或者特征由一套脚本自音频记录中提取得出,并被转化为这个 CSV 文件。具体提取方式并不属于本篇文章希望讨论的范畴,但如果大家感兴趣,则可点击此处查阅其原始 R 源代码。
这套数据集中包含 3168 项示例(每项示例在以上表格中作为一行),且基本半数为男声录制、半数为女声录制。每一项示例中存在 20 项声学特征,例如:
以 kHz 为单位的平均频率
- 频率的标准差
- 频谱平坦度
- 频谱熵
- 峰度
- 声学信号中测得的最大基频
- 调制指数
- 等等……
别担心,虽然我们并不了解其中大多数条目的实际意义,但这不会影响到本次教程。我们真正需要 关心的是如何利用这些数据训练自己的分类器,从而立足于上述特征确保其有能力区分男性与女性的语音。
如果大家希望在一款应用程序当中使用此分类器,从而通过录音或者来自麦克风的音频信息检测语音性别,则首先需要从此类音频数据中提取声学特征。在拥有了这 20 个数字之后,大家即可对其分类器加以训练,并利用其判断语音内容为男声还是女声。
因此,我们的分类器并不会直接处理音频记录,而是处理从记录中提取到的声学特征。
备注:我们可以以此为起点了解深度学习与逻辑回归等传统算法之间的差异。我们所训练的分类器无法学习非常复杂的内容,大家需要在预处理阶段提取更多数据特征对其进行帮助。在本示例的特定数据集当中,我们只需要考虑提取音频记录中的音频数据。
深度学习最酷的能力在于,大家完全可以训练一套神经网络来学习如何自行提取这些声学特征。如此一来,大家不必进行任何预处理即可利用深度学习系统采取原始音频作为输入内容,并从中提取任何其认为重要的声学特征,而后加以分类。
这当然也是一种有趣的深度学习探索方向,但并不属于我们今天讨论的范畴,因此也许日后我们将另开一篇文章单独介绍。
建立一套训练集与测试集
在前文当中,我提到过我们需要以如下步骤对分类器进行训练:
向其交付来自数据集的全部示例。
- 衡量预测结果的错误程度。
- 根据 loss 调整权重。
事实证明,我们不应利用全部数据进行训练。我们只需要其中的特定一部分数据——即测试集——从而评估分类器的实际工作效果。因此,我们将把整体数据集拆分为两大部分:训练集,用于对分类器进行训练 ; 测试集,用于了解该分类器的预测准确度。
为了将数据拆分为训练集与测试集,我创建了一套名为 split_data.py 的 Python 脚本,其内容如下所示:
import numpy as np # 1
import pandas as pd df = pd.read_csv("voice.csv", header=0) #
2 labels = (df["label"] == "male").values * 1 # 3
labels = labels.reshape(-1, 1) # 4
del df["label"] # 5
data = df.values # 6
from sklearn.model_selection import train_test_split X_train,
X_test, y_train, y_test = train_test_split(data, labels, test_size=0.3, random_state=123456)
np.save("X_train.npy", X_train) # 7
np.save("X_test.npy", X_test)
np.save("y_train.npy", y_train)
np.save("y_test.npy", y_test)
下面我们将分步骤了解这套脚本的工作方式:
- 首先导入 NumPy 与 pandas 软件包。Pandas 能够轻松实现 CSV 文件的加载,并对数据进行预处理。
- 利用 pandas 从 voice.csv 加载数据集并将其作为 dataframe。此对象在很大程度上类似于电子表格或者 SQL 表。
- 这里的 label 列包含有该数据集的各项标签:即该示例为男声或者女声。在这里,我们将这些标签提取进一个新的 NumPy 数组当中。各原始标签为文本形式,但我们将其转化为数字形式,其中 1= 男声,0= 女声。(这里的数字赋值方式可任意选择,在二元分类器中,我们通常使用 1 表示‘正’类,或者说我们试图检测的类。)
- 这里创建的新 labels 数组是一套一维数组,但我们的 TensorFlow 脚本则需要一套二维张量,其中 3168 行中每一行皆对应一列。因此我们需要在这里对数组进行“重塑”,旨在将其转化为二维形式。这不会对内存中的数据产生影响,而仅变化 NumPy 对数据的解释方式。
- 在完成 label 列之后,我们将其从 dataframe 当中移除,这样我们就只剩下 20 项用于描述输入内容的特征。我们还将把该 dataframe 转换为一套常规 NumPy 数组。
- 这里,我们利用来自 scikit-learn 的一项 helper 函数将 data 与 labels 数组拆分为两个部分。这种对数据集内各示例进行随机洗牌的操作基于 random_state,即一类随机生成器。无论具体内容为何,但只要青筋相同内容,我们即创造出了一项可重复进行的实验。
- 最后,将四项新的数组保存为 NumPy 的二进制文件格式。现在我们已经拥有了一套训练集与一套测试集!
大家也可以进行额外的一些预处理对脚本中的数据进行调整,例如对特征进行扩展,从而使其拥有 0 均值及相等的方差,但由于本次示例项目比较简单,所以并无深入调整的必要。
利用以下命令在终端中运行这套脚本:
python3 split_data.py
这将给我们带来 4 个新文件,其中包含有训练救命(X_train.npy)、这些示例的对应标签(y_train.npy)、测试示例(X_test.npy)及其对应标签(y_test.npy)。
备注:大家可能想了解为什么这些变量名称为何有些是大写,有些是小写。在数学层面来看,矩阵通常以大写表示而向量则以小写表示。在我们的脚本中,X 代表一个矩阵,y 代表一个向量。这是一种惯例,大部分机器学习代码中皆照此办理。
建立计算图
现在我们已经对数据进行了梳理,而后即可编写一套脚本以利用 TensorFlow 对这套逻辑分类器进行训练。这套脚本名为 train.py。为了节省篇幅,这里就不再列出脚本的具体内容了,大家可以点击此处在 GitHub 上进行查看。
与往常一样,我们首先需要导入需要的软件包。在此之后,我们将训练数据加载至两个 NumPy 数组当中,即 X_train 与 y_train。(我们在本脚本中不会使用测试数据。)
import numpy as np
import tensorflow as tf
X_train = np.load("X_train.npy")
y_train = np.load("y_train.npy")
现在我们可以建立自己的计算图。首先,我们为我们的输入内容 x 与 y 定义所谓 placeholders(占位符):
num_inputs = 20
num_classes = 1
with tf.name_scope("inputs"):
x = tf.placeholder(tf.float32, [None, num_inputs], name="x-input")
y = tf.placeholder(tf.float32, [None, num_classes], name="y-input")
其中 tf.name_scope("…") 可用于对该计算图中的不同部分按不同范围进行分组,从而简化对计算图内容的理解。我们将 x 与 y 添加至“inputs”范围之内。我们还将为其命名,分别为“x-input”与“y-input”,这样即可在随后轻松加以引用。
大家应该还记得,每条输入示例都是一个包含 20 项元素的向量。每条示例亦拥有一个标签(1 代表男声,0 代表女声)。我之前还提到过,我们可以将全部示例整合为一个矩阵,从而一次性对其进行全面计算。正因为如此,我们这里将 x 与 y 定义为二维张量:x 拥有 [None, 20] 维度,而 y 拥有 [None, 1] 维度。
其中的 None 代表第一项维度为灵活可变且目前未知。在训练集当中,我们将 2217 条示例导入 x 与 y; 而在测试集中,我们引入 951 条示例。现在,TensorFlow 已经了解了我们的输入内容,接下来对分类器的 parameters(参数)进行定义:
with tf.name_scope("model"):
W = tf.Variable(tf.zeros([num_inputs, num_classes]), name="W")
b = tf.Variable(tf.zeros([num_classes]), name="b")
其中的张量 W 包含有分类器将要学习的权重(这是一个 20 x 1 矩阵,因为其中包含 20 条输入特征与 1 条输出结果),而 b 则包含偏离值。这二者被声明为 TensorFlow 变量,意味着二者可在反向传播过程当中实现更新。
在一切准备就绪之后,我们可以对作为逻辑回归分类器核心的计算流程进行声明了:
y_pred = tf.sigmoid(tf.matmul(x, W) + b)
这里将 x 与 W 进行相乘,同时加上偏离值 b,而后取其逻辑型成长曲线(logistic sigmoid)。如此一来,y_pred 中的结果即根据 x 内音频数据的描述特性而被判断为男声的概率。
备注:以上代码目前实际还不会做出任何计算——截至目前,我们还只是构建起了必要的计算图。这一行单纯是将各节点添加至计算图当中以作为矩阵乘法(tf.matmul)、加法(+)以及 sigmoid 函数(tf.sigmoid)。在完成整体计算图的构建之后,我们方可创建 TensorFlow 会话并利用实际数据加以运行。
到这里任务还未完成。为了训练这套模型,我们需要定义一项 loss 函数。对于一套二元逻辑回归分类器,我们需要使用 log loss,幸运的是 TensorFlow 本身内置有一项 log_loss() 函数可供直接使用:
with tf.name_scope("loss-function"):
loss = tf.losses.log_loss(labels=y, predictions=y_pred)
loss += regularization * tf.nn.l2_loss(W)
其中的 log_loss 计算图节点作为输入内容 y,我们会获取与之相关的示例标签并将其与我们的预测结果 y_pred 进行比较。以数字显示的结果即为 loss 值。
在刚开始进行训练时,所有示例的预测结果 y_pred 皆将为 0.5(或者 50% 男声),这是因为分类器本身尚不清楚如何获得正确答案。其初始 loss 在经 -1n(0.5) 计算后得出为 0.693146。而在训练的推进当中,其 loss 值将变得越来越小。
第二行用于计算 loss 值与所谓 L2 regularization(正则化)的加值。这是为了防止过度拟合阻碍分类器对训练数据的准确记忆。这一过程比较简单,因为我们的分类器“内存”只包含 20 项权重值与偏离值。不过正则化本身是一种常见的机器学习技术,因此在这里必须一提。
这里的 regularization 值为另一项占位符:
with tf.name_scope("hyperparameters"):
regularization = tf.placeholder(tf.float32, name="regularization")
learning_rate = tf.placeholder(tf.float32, name="learning-rate")
我们还将利用占位符定义我们的输入内容 x 与 y,不过二者的作用是定义 hyperparameters。
Hyperparameters 允许大家对这套模型及其具体训练方式进行配置。其之所以被称为“超”参数,是因为与常见的 W 与 b 参数不同,其并非由模型自身所学习——大家需要自行将其设置为适当的值。
其中的 learning_rate 超参数负责告知优化器所应采取的调整幅度。该优化器(optimizer)负责执行反向传播:其会提取 loss 值并将其传递回计算图以确定需要对权重值与偏离值进行怎样的调整。这里可以选择的优化器方案多种多样,而我们使用的为 ADAM:
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
其能够在计算图当中创建一个名为 train_op 的节点。我们稍后将运行此节点以训练分类器。为了确定该分类器的运行效果,我们还需要在训练当中偶尔捕捉快照并计算其已经能够在训练集当中正确预测多少项示例。训练集的准确性并非分类器运行效果的最终检验标准,但对其进行追踪能够帮助我们在一定程度上把握训练过程与预测准确性趋势。具体来讲,如果越是训练结果越差,那么一定是出了什么问题!
下面我们为一个计算图节点定义计算精度:
with tf.name_scope("inference"):
inference = tf.to_float(y_pred > 0.5, name="inference")
我们可以运行其中的 accuracy 节点以查看有多少个示例得到了正确预测。大家应该还记得,y_pred 中包含一项介于 0 到 1 之间的概率。通过进行 tf.to_float(y_pred > 0.5),若预测结果为女声则返回值为 0,若预测结果为男声则返回值为 1。我们可以将其与 y 进行比较,y 当中包含有正确值。而精度值则代表着正确预测数量除以预测总数。
在此之后,我们将利用同样的 accuracy 节点处理测试集,从而了解这套分类器的实际工作效果。
另外,我们还需要定义另外一个节点。此节点用于对我们尚无对应标签的数据进行预测:
with tf.name_scope("inference"):
inference = tf.to_float(y_pred > 0.5, name="inference")
为了将这套分类器引入应用,我们还需要记录几个语音文本词汇,对其进行分析以提取 20 项声学特征,而后再将其交付至分类器。由于处理内容属于全新数据,而非来自训练或者测试集的数据,因此我们显然不具备与之相关的标签。大家只能将数据直接交付至分类器,并希望其能够给出正确的预测结果。而 inference 节点的作用也正在于此。
好的,我们已经投入了大量精力来构建这套计算图。现在我们希望利用训练集对其进行实际训练。
训练分类器
训练通常以无限循环的方式进行。不过对于这套简单的逻辑分类器,这种作法显然有点夸张——因为其不到一分钟即可完成训练。但对于深层神经网络,我们往往需要数小时甚至数天时间进行脚本运行——直到其获得令人满意的精度或者您开始失去耐心。
以下为 train.py 当中训练循环的第一部分:
with tf.Session() as sess:
tf.train.write_graph(sess.graph_def, checkpoint_dir, "graph.pb", False)
sess.run(init)
step = 0
while True:
# here comes the training code/pre>
我们首先创建一个新的 TensorFlow session(会话)对象。要运行该计算图,大家需要建立一套会话。调用 sess.run(init) 会将 W 与 b 全部重设为 0。
我们还需要将该计算图写入一个文件。我们将之前创建的全部节点序列至 /tmp/voice/graph.pb 文件当中。我们之后需要利用此计算图定义以立足测试集进行分类器运行,并尝试将该训练后的分类器引入 iOS 应用。
在 while True: 循环当中,我们使用以下内容:
perm = np.arange(len(X_train))
np.random.shuffle(perm)
X_train = X_train[perm]
y_train = y_train[perm]
首先,我们对训练示例进行随机洗牌。这一点非常重要,因为大家当然不希望分类器根据示例的具体顺序进行判断——而非根据其声学特征进行判断。
接下来是最重要的环节:我们要求该会话运行 train_op 节点。其将在计算图之上运行一次训练:
feed = {x: X_train, y: y_train, learning_rate: 1e-2,
regularization: 1e-5}
sess.run(train_op, feed_dict=feed)
在运行 sess.run() 时,大家还需要提供一套馈送词典。其将负责告知 TensorFlow 当前占位符节点的实际值。
由于这只是一套非常简单的分类器,因此我们将始终一次性对全部训练集进行训练,所以这里我们将 X_train 数组引入占位符 x 并将 y_train 数组引入占位符 y。(对于规模更大的数据集,大家可以先从小批数据内容着手,例如将示例数量设定为 100 到 1000 之间。)
到这里,我们的操作就阶段性结束了。由于我们使用了无限循环,因此 train_op 节点会反复再反复加以执行。而在每一次迭代时,其中的反向传播机制都会对权重值 W 与 b 作出小幅调整。随着时间推移,这将令权重值逐步趋近于最优值。
我们当然有必要了解训练进度,因此我们需要经常性地输出进度报告(在本示例项目中,每进行 1000 次训练即输出一次结果):
if step % print_every == 0:
train_accuracy, loss_value = sess.run([accuracy, loss], feed_dict=feed)
print("step: %4d, loss: %.4f, training accuracy: %.4f" % \
(step, loss_value, train_accuracy))
这一次我们不再运行 train_op 节点,而是运行 accuracy 与 loss 两个节点。我们使用同样的馈送词典,这样 accuracy 与 loss 都会根据训练集进行计算。正如之前所提到,训练集中的较高预测精度并不代表分类器能够在处理测试集时同样拥有良好表现,但大家当然希望随着训练的进行其精度值不断提升。与此同时,loss 值则应不断下降。
另外,我们还需要时不时保存一份 checkpoint:
if step % save_every == 0:
checkpoint_file = os.path.join(checkpoint_dir, "model")
saver.save(sess, checkpoint_file)
print("*** SAVED MODEL ***")
其会获取分类器当前已经学习到的 W 与 b 值,并将其保存为一个 checkpoint 文件。此 checkpoint 可供我们参阅,并判断分类器是否已经可以转而处理测试集。该 checkpoinit 文件同样被保存在 /tmp/voice/ 目录当中。
使用以下命令在终端中运行该训练脚本:
python3 train.py
输出结果应如下所示:
Training set size: (2217, 20)
Initial loss: 0.693146
step: 0, loss: 0.7432, training accuracy: 0.4754
step: 1000, loss: 0.4160, training accuracy: 0.8904
step: 2000, loss: 0.3259, training accuracy: 0.9170
step: 3000, loss: 0.2750, training accuracy: 0.9229
step: 4000, loss: 0.2408, training accuracy: 0.9337
step: 5000, loss: 0.2152, training accuracy: 0.9405
step: 6000, loss: 0.1957, training accuracy: 0.9553
step: 7000, loss: 0.1819, training accuracy: 0.9594
step: 8000, loss: 0.1717, training accuracy: 0.9635
step: 9000, loss: 0.1652, training accuracy: 0.9666
*** SAVED MODEL ***
step: 10000, loss: 0.1611, training accuracy: 0.9702
step: 11000, loss: 0.1589, training accuracy: 0.9707
. . .
当发现 loss 值不再下降时,就稍等一下直到看到下一条 * SAVED MODEL * 信息,这时按下 Ctrl+C 以停止训练。
在超参数设置当中,我选择了正规化与学习速率,大家应该会看到其训练集的准确率已经达到约 97%,而 loss 值则约为 0.157。(如果大家在馈送词典中将 regularization 设置为 0,则 loss 甚至还能够进一步降低。)
实际效果如何?
在完成对分类器的训练之后,接下来就是对其进行测试以了解它在实践当中的运行效果。大家需要使用未在训练中涉及过的数据完成这项测试。正因为如此,我们才在此前将数据集拆分为训练集与测试集。
我们将创建一套新的 test.py 脚本,负责加载计算图定义以及测试集,并计算其正确预测的测试示例数量。这里我将只提供重要的部分,大家可以点击此处查看完整脚本内容。
备注:测试集的结果精确度将始终低于训练集的结果精确度(后者为 97%)。不过如果前者远低于后者,则大家应对分类器进行检查并对训练流程进行调整。我们预计测试集的实际结果应该在 95% 左右。任何低于 90% 的精度结果都应引起重视。
与之前一样,这套脚本会首先导入必要软件包,包括来自 scikit-learn 的指标包以输出各类其它报告。当然,这一次我们选择加载测试集而不再是训练集。
import numpy as np
import tensorflow as tf from sklearn
import metrics
X_test = np.load("X_test.npy")
y_test = np.load("y_test.npy")
为了计算测试集的结果精确度,我们仍然需要计算图。不过这一次不再需要完整的计算图,因为 train_op 与 loss 两个用于训练的节点这里不会被用到。大家当然可以再次手动建立计算图,但由于此前我们已经将其保存在 graph.pb 文件当中,因此这里直接加载即可。以下为相关代码:
with tf.Session() as sess:
graph_file = os.path.join(checkpoint_dir, "graph.pb")
with tf.gfile.FastGFile(graph_file, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name="")
TensorFlow 可能会将其数据保存为协议缓冲文件(扩展名为.pb),因此我们可以使用部分 helper 代码以加载此文件并将其作为计算图导入至会话当中。
接下来,我们需要从 checkpoint 文件处加载 W 与 b 的值:
W = sess.graph.get_tensor_by_name("model/W:0")
b = sess.graph.get_tensor_by_name("model/b:0")
checkpoint_file = os.path.join(checkpoint_dir, "model")
saver = tf.train.Saver([W, b])
saver.restore(sess, checkpoint_file)
正因为如此,我们需要将节点引入范围并为其命名,从而利用 get_tensor_by_name() 轻松再次将其找到。如果大家没有为节点提供明确的名称,则可能需要认真查阅计算图定义才能找到 TensorFlow 为其默认分配的名称。
我们还需要引用其它几个节点,特别是作为输入内容的 x 与 y 以及其它负责进行预测的节点:
x = sess.graph.get_tensor_by_name("inputs/x-input:0")
y = sess.graph.get_tensor_by_name("inputs/y-input:0")
accuracy = sess.graph.get_tensor_by_name("score/accuracy:0")
inference = sess.graph.get_tensor_by_name("inference/inference:0")
好的,到这里我们已经将计算图重新加载至内存当中。我们还需要再次将分类器学习到的内容加载至 W 与 b 当中。现在我们终于可以测试分类器在处理其之前从未见过的数据时表现出的精确度了:
feed = {x: X_test, y: y_test}
print("Test set accuracy:", sess.run(accuracy, feed_dict=feed))
上述代码会运行 accuracy 节点并利用来自 X_test 数组的声学特征作为输入内容,同时使用来自 y_test 的标签进行结果验证。
备注:这一次,馈送词典不再需要为 learning_rate 与 regularization 占位符指定任何值。我们只需要在 accuracy 节点上运行计算图的一部分,且此部分中并不包括这些占位符。
我们还可以借助 scikit-learn 的帮助显示其它一些报告:
predictions = sess.run(inference, feed_dict={x: X_test})
print("Classification report:")
print(metrics.classification_report(y_test.ravel(), predictions))
print("Confusion matrix:")
print(metrics.confusion_matrix(y_test.ravel(), predictions))
这一次,我们使用 inference 节点以获取预测结果。由于 inference 只会计算预测结果而不会检查其精确度,因此馈送词典中仅需要包含输入内容 x 而不再需要 y。
运行此脚本之后,大家应该会看到类似于以下内容的输出结果:
$ python3 test.py
Test set accuracy: 0.958991
Classification report:
precision recall f1-score support
0 0.98 0.94 0.96 474
1 0.94 0.98 0.96 477
avg / total 0.96 0.96 0.96 951
Confusion matrix:
[[446 28]
[ 11 466]]
测试集的预测精确度接近 96%——与预期一样,略低于训练集的精确度,但也已经相当接近。这意味着我们的训练已经获得成功,且我们也证明了这套分类器能够有效处理其从未见过的数据。其当然还不够完美——每 25 次尝试中即有 1 次属于分类错误,但对于本教程来说这一结果已经完全令人满意。
分类报告与混淆矩阵显示了与错误预测相关的示例统计信息。通过混淆矩阵,我们可以看到共有 446 项得到正确预测的女声示例,而另外 28 项女声示例则被错误地判断为男声。在 466 项男声示例中分类器给出了正确结论,但有 11 项则被错误判断为女声。
这样看来,我们的分类器似乎不太擅长分辨女性的语音,因为其女声识别错误率更高。分类报告 / 回调数字亦给出了相同的结论。
在 iOS 上使用 TensorFlow
现在我们已经拥有了一套经过训练的模型,其拥有比较理想的测试集预测精确度。下面我们将构建一款简单的 iOS 应用,并利用这套模型在其中实现预测能力。首先,我们利用 TensorFlow C++ 库构建一款应用。在下一章节中,我们将把模型引入 Metal 以进行比较。
这里我们既有好消息也有坏消息。坏消息是大家需要利用源代码自行构建 TensorFlow。事实上,情况相当糟糕:大家需要安装 Java 方可实现这项目标。而好消息是整个流程其实并不复杂。感兴趣的朋友可以点击此处查看完整指南,但以下步骤也基本能够帮助大家解决问题(在 TensorFlow 1.0 上实测有效)。
这里需要注意的是,大家应当安装 Xcode 8,并确保活动开发者目录指向您 Xcode 的安装位置(如果大家先安装了 Homebrew,随后才安装 Xcode,则其可能指向错误位置,意味着 TensorFlow 将无法完成构建):
sudo xcode-select -s /Applications/Xcode.app/Contents/Developer
TensorFlow 利用一款名为 bazel 的工具进行构建,bazel 则要求配合 Java JDK 8。大家可以利用 Homebrew 轻松安装必要的软件包:
brew cask install java brew install bazel brew install automake brew install libtool
在完成之后,大家需要克隆 TensorFlow GitHub 库。需要注意的是:请确保您指定的路径不具备充足的空间,否则 bazel 会拒绝进行构建(没错,这是真的!)。我直接将其克隆到了自己的主目录当中:
cd /Users/matthijs git clone <a href="https://github.com/tensorflow/tensorflow">https://github.com/tensorflow/tensorflow</a> -b r1.0
其中的 -b r1.0 标记告知 git 克隆 r1.0 分支。大家可以随意使用其它更新的分支,或者选择使用 master 分支。
备注:在 MacOS Sierra 上,接下来即将运行的 configure 脚本会提示多项错误。为了解决问题,我不得不选择克隆 master 分支。在 OS X El Capitan 上,使用 r1.0 分支则不会引发任何错误。
在代码库克隆完成后,大家需要运行 configure 脚本。
cd tensorflow ./configure
其会提出几个问题,以下为我给出的回答:
Please specify the location of python. [Default is /usr/bin/python]:
我的回答是 /usr/local/bin/python3,因为我希望使用 Python 3.6 配合 TensorFlow。如果大家选择默认选项,则 TensorFlow 将利用 Python 2.7 进行构建。
Please specify optimization flags to use during compilation [Default is -march=native]:
在这里直接按下回车键,接下来的几个问题则全部按 n 选择否。
在其问及要使用哪套 Python 库时,按下回车以选择默认选项(即 Python 3.6 库)。
接下来的问题全部按 n 选择否。现在该脚本将下载几项依赖性项目并为构建 TensorFlow 做好准备。
构建静态库
我们可以通过以下两种方式构建 TensorFlow:
- 在 Mac 系统上,使用 bazel 构建工具。在 iOS 上使用 Makefile。
- 由于我们需要面向 iOS 进行构建,因此选择选项二。然而,我们还需要构建其它一些工具,因此也得涉及选项一的内容。
在 tensorflow 目录下执行以下脚本:
tensorflow/contrib/makefile/build_all_ios.sh
其会首先下载一些依赖性选项,而后开始进行构建流程。如果一切顺利,其将创建出三套接入应用所必需的静态库,分别为: libtensorflow-core.a、libprotobuf.a、libprotobuf-lite.a。
警告:构建这些库需要一段时间——我的 iMac 需要 25 分钟,机型较旧的 MacBook Pro 则需要 3 个小时,而且整个过程中风扇一直在全力运转!大家可能会在过程中看到一些编译器警告甚至错误提示信息一闲而过。当作没看见就好,时间一到工作自然就绪!
到这里工作还没结束。我们还需要构建其它两款 helper 工具。在终端当中运行以下两条命令:
bazel build tensorflow/python/tools:freeze_graph bazel build tensorflow/python/tools:optimize_for_inference
注意:这一过程大约需要 20 分钟左右,因为其需要再次从零开始构建 TensorFLow(这一次使用 bazel)。
备注:如果大家在过程中遇到了问题,请点击此处参阅官方指南。
为 Mac 设备构建 TensorFlow
这部分内容为可选项目,但由于大家已经安装了全部必要软件包,因此为 Mac 系统构建 TensorFlow 并不困难。其会创建一个新的 pip 软件包,大家可进行安装以取代官方 TensorFlow 软件包。
为什么不使用官方软件包?因为这样我们才能创建一套包含自定义选项的 TensorFlow 版本。举例来说,如果大家在运行 train.py 脚本时遇到了“此 TensorFlow 库无法利用 SSE4.1 指令进行编译”的警告提示,则可编译一套特殊的 TensorFLow 版本以启用这些指令。
要为 Mac 系统构建 TensorFlow,请在终端中运行以下命令:
bazel build --copt=-march=native -c opt //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
其中的 -march=native 选项用于在您的 CPU 能够支持的前提下,添加对 SSE、AVX、AVX2 以及 FMA 等的支持。
随后安装该软件包:
pip3 uninstall tensorflow sudo -H pip3 install /tmp/tensorflow_pkg/tensorflow-1.0.0-XXXXXX.whl
欲了解更多细节信息,请点击此处参阅 TensorFlow 官方网站。
“冻结”计算图
我们将要创建的 iOS 应用将利用 Python 脚本加载之前训练完成的模型,并利用其作出一系列预测。
大家应该还记得,train.py 将计算图定义保存在了 /tmp/voice/graph.pb 文件当中。遗憾的是,大家无法直接将该计算图加载至 iOS 应用当中。完整的计算图中包含的操作目前还不受 TensorFlow C++ API 的支持。正因为如此,我们才需要使用刚刚构建完成的其它两款工具。其中 freeze_graph 负责获取 graph.pb 以及包含有 W 与 b 训练结果值的 checkpoint 文件。其还会移除一切在 iOS 之上不受支持的操作。
在终端当中立足 tensorflow 目录运行该工具:
bazel-bin/tensorflow/python/tools/freeze_graph \
--input_graph=/tmp/voice/graph.pb --input_checkpoint=/tmp/voice/model \
--output_node_names=model/y_pred,inference/inference --input_binary \
--output_graph=/tmp/voice/frozen.pb
以上命令将在 /tmp/voice/frozen.pb 当中创建一套经过简化的计算图,其仅具备 y_pred 与 inference 两个节点。其并不包含任何用于训练的计算图节点。
使用 freeze_graph 的好处在于,其还将固定该文件中的权重值,这样大家就无需分别进行权重值加载了:frozen.pb 中已经包含我们需要的一切。而 optimize_for_inference 工具则负责对计算图进行进一步简化。其将作为 grozen.pb 文件的输入内容,并写入/tmp/voice/inference.pb作为输出结果。我们随后会将此文件嵌入至 iOS 应用当中。使用以下命令运行该工具:
bazel-bin/tensorflow/python/tools/optimize_for_inference \
--input=/tmp/voice/frozen.pb --output=/tmp/voice/inference.pb
\ --input_names=inputs/x --output_names=model/y_pred,inference/inference
\ --frozen_graph=True
iOS 应用
大家可以在 github.com/hollance/TensorFlow-iOS-Example 中的VoiceTensorFlow文件夹内找到我们此次使用的 iOS 应用。
在 Xcode 当中打开该项目,其中包含以下几条注意事项:
- 此应用利用 Objective-C++ 编写(其源文件扩展名为.mm)。在编写时尚不存在面向 TensorFlow 的 Swift API,因此只能使用 C++。
- 其中的 inference.pb 文件已经包含在项目当中。如果需要,大家也可以直接将自有版本的 inference.pb 复制到此项目的文件夹之内。
- 此应用与Accelerate.framework相链接。
- 此应用与我们此前已经编译完成的几套静态库相链接。
前往 Project Settings(项目设置)屏幕并切换至 Build Settings(构建设置)标签。在 Other Linker Flags(其它链接标记)下,大家会看到以下内容:
/Users/matthijs/tensorflow/tensorflow/contrib/makefile/gen/protobuf_ios/lib/ libprotobuf-lite.a /Users/matthijs/tensorflow/tensorflow/contrib/makefile/gen/protobuf_ios/lib/ libprotobuf.a -force_load /Users/matthijs/tensorflow/tensorflow/contrib/makefile/gen/lib/ libtensorflow-core.a
除非您的名称同样为“matthijs”,否则大家需要将其替换为您 TensorFlow 库的实际克隆路径。(请注意,这里 tensorflow 出现了两次,所以文件夹名称应为 tensorflow/tensorflow/…)
备注:大家也可以将这三个.a 文件复制到项目文件夹之内,如此即不必担心路径可能出现问题。我个人并不打算在这一示例项目中采取这种方式,因为 libtensorflow-core.a 文件是一套体积达 440 MB 的库。
另外请注意检查 Header Search Paths(标题搜索路径)。以下为目前的设置:
~/tensorflow ~/tensorflow/tensorflow/contrib/makefile/downloads ~/tensorflow/tensorflow/contrib/makefile/downloads/eigen ~/tensorflow/tensorflow/contrib/makefile/downloads/protobuf/src ~/tensorflow/tensorflow/contrib/makefile/gen/proto
另外,大家还需要将其更新至您的克隆目录当中。
以下为我在构建设置当中进行了修改的其它条目:
Enable Bitcode: No
Warnings / Documentation Comments: No
Warnings / Deprecated Functions: No
Bitcode 目前尚不受 TensorFLow 的支持,所以我决定将其禁用。我还关闭了警告选项,否则在编译应用时会出现一大票问题提示。(禁用之后,大家仍然会遇到几项关于值转换问题的警告。大家当然也可以将其一并禁用,但我个人还是希望多少了解一点其中的错误。)
在完成了对 Other Linker Flags 与 Header Search Paths 的变更之后,大家即可构建并运行我们的 iOS 应用。
很好,现在大家已经拥有了一款能够使用 TensorFlow 的 iOS 应用了!下面让我们看看它的实际运行效果。
使用 TensorFlow C++ API
TensorFlow for iOS 由 C++ 编写而成,但其中需要编写的 C++ 代码量其实——幸运的是——并不多。一般来讲,大家只需要完成以下工作:
- 从.pb 文件中加载计算图与权重值。
- 利用此计算图创建一项会话。
- 将您的数据放置在一个输入张量内。
- 在一个或者多个节点上运行计算图。
- 从输出结果张量中获取结果。
在本示例应用当中,这一切皆发生在 ViewController.mm 之内。首先,我们加载计算图:
- (BOOL)loadGraphFromPath:(NSString *)path
{
auto status = ReadBinaryProto(tensorflow::Env::Default(), path.fileSystemRepresentation, &graph);
if (!status.ok()) {
NSLog(@"Error reading graph: %s", status.error_message().c_str());
return NO;
}
return YES;
}
此 Xcode 项目当中已经包含我们通过在 graph.pb 上运行 freeze_graph 与 optimize_for_inference 工具所构建的 inference.pb 计算图。如果大家希望直接加载 graph.pb,则会得到以下错误信息:
Error adding graph to session: No OpKernel was registered to support Op ‘L2Loss’ with these attrs. Registered devices: CPU], Registered kernels:
[[Node: loss-function/L2Loss = L2Loss[T=DT_FLOAT ]]
这是因为 C++ API 所能支持的操作要远少于 Python API。这里提到我们在 loss 函数节点中所使用的 L2Loss 操作在 iOS 上并不适用。正因为如此,我们才需要利用 freeze_graph 以简化自己的计算图。
在计算图加载完成之后,我们使用以下命令创建一项会话:
- (BOOL)createSession
{
tensorflow::SessionOptions options;
auto status = tensorflow::NewSession(options, &session);
if (!status.ok()) {
NSLog(@"Error creating session: %s",
status.error_message().c_str());
return NO;
}
status = session->Create(graph);
if (!status.ok()) {
NSLog(@"Error adding graph to session: %s",
status.error_message().c_str());
return NO;
}
return YES;
}
会话创建完成后,我们可以利用其执行预测操作。其中的 predict:method 会提供一个包含 20 项浮点数值的数组——即声学特征——并将这些数字馈送至计算得意洋洋发中。
下面我们一起来看此方法的工作方式:
- (void)predict:(float *)example {
tensorflow::Tensor x(tensorflow::DT_FLOAT,
tensorflow::TensorShape({ 1, 20 }));
auto input = x.tensor<float, 2>();
for (int i = 0; i < 20; ++i) {
input(0, i) = example[i];
}
其首先将张量 x 定义为我们需要使用的输入数据。此张量为{1,20},因为其一次提取一项示例且该示例中包含 20 项特征。在此之后,我们将数据由 float * 数组复制至该张量当中。
接下来,我们运行该项会话:
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs = {
{"inputs/x-input", x}
};
std::vector<std::string> nodes = {
{"model/y_pred"},
{"inference/inference"}
};
std::vector<tensorflow::Tensor> outputs;
auto status = session->Run(inputs, nodes, {}, &outputs);
if (!status.ok()) {
NSLog(@"Error running model: %s", status.error_message().c_str());
return;
}
这里得出了类似于 Python 代码的内容:
pred, inf = sess.run([y_pred, inference], feed_dict={x: example})
只是不那么简洁。我们需要创建馈送词典、用于列出需要运行的全部节点的向量,外加一个负责容纳对应结果的向量。最后,我们告知该会话完成上述任务。
在会话运行了全部必要节点后,我们即可输出以下结果:
auto y_pred = outputs[0].tensor<float, 2>();
NSLog(@"Probability spoken by a male: %f%%", y_pred(0, 0));
auto isMale = outputs[1].tensor<float, 2>();
if (isMale(0, 0)) {
NSLog(@"Prediction: male");
} else {
NSLog(@"Prediction: female");
}
}
出于演示需求,只需要运行 inference 节点即可完成对音频数据的男声 / 女声判断。不过我还希望查看计算得出的概率,因此这里我也运行了 y_pred 节点。
运行 iOS 应用
大家可以在 iPhone 模拟器或者实机之上运行这款应用。在模拟器上,大家仍然会看到“此 TensorFlow 库无法利用 SSE4.1 指令进行编译”的提示,但在实机上则不会出现这样的问题。
出于测试的目的,这款应用只会进行两项预测:一次为男声示例预测,一次为女声示例预测。(我直接从测试集中提取了对应示例。大家也可以配合其它示例并修改 maleExample 或者 emaleExample 数组当中的数字。)
运行这款应用,大家应该会看到以下输出结果。该应用首先给出了计算图当中的各节点:
Node count: 9
Node 0: Placeholder 'inputs/x-input'
Node 1: Const 'model/W'
Node 2: Const 'model/b'
Node 3: MatMul 'model/MatMul'
Node 4: Add 'model/add'
Node 5: Sigmoid 'model/y_pred'
Node 6: Const 'inference/Greater/y'
Node 7: Greater 'inference/Greater'
Node 8: Cast 'inference/inference'
需要注意的是,此计算图中仅包含实施预测所必需的操作,而不包括任何与训练相关的内容。
此后,其会输出预测结果:
Probability spoken by a male: 0.970405% Prediction: male Probability spoken by a male: 0.005632% Prediction: female
如果大家利用 Python 脚本尝试使用同样的示例,那么结果也将完全一致。任务完成!
备注:这里要提醒大家,此项演示项目中我们对数据进行了“伪造”(即使用了提取自测试集中的示例)。如果大家希望利用这套模型处理真正的音频,则首先需要将对应音频转化为 20 项声学特征。
iOS 平台上 TensorFlow 的优势与缺点
TensorFlow 是一款出色的机器学习模型训练工具,特别是对于那些不畏数学计算并乐于创建新型算法的朋友。要对规模更大的模型进行训练,大家甚至可以在云环境下使用 TensorFLow。
除了训练之外,本篇博文还介绍了如何将 TensorFLow 添加至您的 iOS 应用当中。对于这一部分,我希望概括这种作法的优势与缺点。
在 iOS 之上使用 TensorFlow 的优势:
- 使用一款工具即可实现全部预期。大家可以同时利用 TensorFlow 训练模型并将其引用于设备之上。我们不再需要将自己的计算图移植至 BNNS 或者 Metal 等其它 API 处。在另一方面,大家则必须至少将部分 Python 代码“移植”为 C++ 形式。
- TensorFlow 拥有众多超越 BNNS 或 Metal 的出色功能特性。
- 大家可以在模拟器上对其进行测试。(Metal 要求用户始终利用实机进行测试。)
在 iOS 上使用 TensorFLow 的缺点:
- 目前其尚不支持 GPU。TensorFlow 确实能够利用 Acclerate 框架以发挥 CPU 的向量指令优势,但在原始处理速度上仍无法与 Metal 相提并论。
- TensorFLow API 为 C++,因此大家需要使用 Objective-C++ 自行编写代码。
- 大家无法直接利用 Swift 使用 TensorFLow。C++ API 相较于 Python API 存在更多局限性。这意味着大家无法在设备之上进行数据训练,因为反向传播所需要的自动梯度计算尚不受设备支持。但这并不是什么大问题,毕竟移动设备的硬件本身就不适合进行大规模数据集训练。
- TensorFlow 静态库的加入会令应用体积增加约 40 MB。大家可以通过减少受支持操作的数量对其进行瘦身,但具体过程相当麻烦。另外这还不包含您模型本体的体积,这可能会让应用尺寸进一步膨胀。
就个人来讲,我认为在 iOS 上使用 TensorFlow 并没有什么性价比可言——至少就目前而言是如此。其优势根本无法抵消致命的缺点。不过作为一款年轻的产品,我相信 TensorFLow 未来会得到进一步改善……
备注:如果大家决定在自己的 iOS 应用当中使用 TensorFlow,则应意识到人们完全可以直接从应用包中复制计算图的.pb 文件以窃取您的模型。虽然这个问题不仅存在于 TensorFlow 当中,但由于“冻结”计算图文件中同时包含模型参数与计算图定义,因此对方能够轻松完成逆向工程。如果您的模型将作为应用本身的核心竞争优势存在,那么请务必想办法对其加以保护以避免受到恶意窥探。
在 GPU 上运行:使用 Metal
在 iOS 之上使用 TensorFLow 的一大缺点在于,其运行在 CPU 之上。虽然对于数据与模型规模较小的 TensorFlow 项目而言,CPU 的处理能力已经完全足够,但对于较大的模型、特别是深度学习项目而言,大家无疑需要利用 GPU 进行相关运算。而在 iOS 系统上,这意味着我们必须选择 Metal。
大家仍然需要在自己的 Mac 设备上利用 TensorFlow 进行训练——或者使用其它拥有强大 GPU 的 Linux 设备甚至云资源——不过运行在 iOS 上的引用代码则可使用 Metal 而非 TensorFlow 库。
在对必需的学习参数进行训练之后——即 W 与 b 值——我们需要将其导出为 Metal 可以读取的格式。幸运的是,我们只需要将其作为二进制格式保存为一份浮点数值列表即可。
现在我们需要编写另一套 Python 脚本:export_weights.py(点击此处查看完整版本)。其内容与我们之前用于加载计算图定义及 checkpoint 文件的 test.py 非常相似。不过这一次,我们使用以下内容:
W.eval().tofile("W.bin") b.eval().tofile("b.bin")
W.eval() 负责计算 W 的当前值并将其返回为一个 NumPy 数组(过程与执行 sess.run(W) 完全一致)。此后,我们使用 tofile() 将该 NumPy 数据保存为一个二进制文件。好了,就是这么简单:-)
备注:对于我们的示例分类器,W 是一个 20 x 1 的矩阵,即一份简单的 20 项浮点数值列表。对于更为复杂的模型,大家的学习参数可能属于四维张量。在这种情况下,大家可能需要对其中的部分维度进行顺序调整,因为 TensorFlow 存储数据的顺序与 Metal 的预期存在差异。大家可以直接使用 tf.transpose() 命令实现这一目标,但再次重申,我们的这一示例项目并不需要这些过程。
下面来看我们这套逻辑分类器的 Metal 版本。大家可以点击此处在其源代码的 VoiceMetal 文件夹中找到对应的 Xcode 项目。此项目以 Swift 语言编写而成。
大家应该还记得,这里的逻辑回归算法采用了以下方程式进行计算:
y_pred = sigmoid((W * x) + b)
其计算过程与神经网络当中完全连接层的执行过程相同。因此为了利用 Metal 实现我们的分类器,只需要使用一个 MPSCNNFullyConnected 层。首先,我们将 W.bin 与 b.bin 加载至 Data 对象当中:
let W_url = Bundle.main.url(forResource: "W", withExtension: "bin"
let b_url = Bundle.main.url(forResource: "b", withExtension: "bin"
let W_data = try! Data(contentsOf: W_url!)
let b_data = try! Data(contentsOf: b_url!)
此后,我们创建该完全连接层:
let sigmoid = MPSCNNNeuronSigmoid(device: device)
let layerDesc = MPSCNNConvolutionDescriptor(
kernelWidth: 1, kernelHeight: 1,
inputFeatureChannels: 20, outputFeatureChannels: 1,
neuronFilter: sigmoid)
W_data.withUnsafeBytes { W in
b_data.withUnsafeBytes { b in
layer = MPSCNNFullyConnected(device: device,
convolutionDescriptor: layerDesc,
kernelWeights: W, biasTerms: b, flags: .none)
}
}
由于输入内容为 20 个数字,我决定将完全连接层的设定为一套 1 x 1 且包含 20 条输入通道的维度“图像”。而结果 y_pred 仅为单一数字,这样该完全连接层将仅拥有一条输出通道。作为输入与输出数据驻留所在的对象,MPSImage 同样拥有这些维度:
let inputImgDesc = MPSImageDescriptor(channelFormat: .float16,
width: 1, height: 1, featureChannels: 20)let outputImgDesc = MPSImageDescriptor(channelFormat: .float16,
width: 1, height: 1, featureChannels: 1)
inputImage = MPSImage(device: device, imageDescriptor: inputImgDesc)
outputImage = MPSImage(device: device, imageDescriptor: outputImgDesc)
由于使用的是应用中的 TensorFlow 版本,因此其中的 predict 方法将获取用以构建单一示例的 20 条浮点数值。以下为完整的方法内容:
func predict(example: [Float]) {
convert(example: example, to: inputImage)
let commandBuffer = commandQueue.makeCommandBuffer()
layer.encode(commandBuffer: commandBuffer, sourceImage: inputImage,
destinationImage: outputImage)
commandBuffer.commit()
commandBuffer.waitUntilCompleted()
let y_pred = outputImage.toFloatArray()
print("Probability spoken by a male: \(y_pred[0])%")
if y_pred[0] > 0.5 {
print("Prediction: male")
} else {
print("Prediction: female")
}
}
这即为 Metal 当中的运行会话版本。其中 convert(example:to:) 与 toFloatArray() 方法属于 helper,负责将数据加载进 / 出 MPSImage 对象。就是这么简单,我们已经成功完成了 Metal 版本的应用成果!大家需要在实机之上运行此应用,因为 Metal 并不支持模拟器运行机制。
Probability spoken by a male: 0.970215% Prediction: male Probability spoken by a male: 0.00568771% Prediction: female
需要注意的是,这些概率与 TensorFlow 提供的预测结果并不完全一致。这是因为 Metal 会在内部使用 16 位浮点数值,但二者的结果仍然相当接近!
鸣谢
本示例当中使用的数据集由 Kory Becker 构建并下载自 Kaggle.com。感兴趣的朋友亦可参阅 Kory 的博文与源代码。
其他作者亦发布了与在iOS 系统之上使用TensorFlow 相关的文章,我本人也从中得到了大量启发并引用了部分代码示例,具体包括:
《在iOS 上使用Deep MNIST 与TensorFlow:上手指南》,由 Matt Rajca 撰写。
《利用Metal Performance Shaders 实现TensorFlow 加速》,同样来自 Matt Rajca。《Tensorflow Cocoa 示例》,由Aaron Hillegass 撰写。
TensorFlow 资源库中的《TensorFlow iOS 示例》。
原文链接: http://machinethink.net/blog/tensorflow-on-ios/
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




