
编译 | 华卫、核子可乐
大多数计算机遵循的冯·诺依曼架构,强调将计算与内存彼此分离。这样的架构虽然完美适应传统计算需求,但在 AI 计算时代却造成严重的数据拥堵。

AI 计算向来以消耗海量电力而闻名,部分原因就在于其需要处理的数据量极其惊人。在训练过程中,往往需要数十亿乃至数万亿条信息才能创建一套包含几十亿参数的模型。但除此之外,计算机芯片的基本构造也是能源浪费的重要原因。
现代计算处理器在执行常规离散计算方面非常高效,但在需要等待数据在内存与计算单元间往来移动的场景下,其效率则会急剧下降。这明显是设计初衷与前沿应用相互冲突的典型迹象。在 AI 计算领域,几乎所有任务均相互关联,因此一旦处理器陷入等待状态,就会长时间无事可做。
在这种情况下,处理器即遭遇所谓冯·诺依曼瓶颈,即数据传输速度不足导致计算速度受滞。过去 60 年来,几乎所有处理器均采用冯·诺依曼架构,即通过总线将处理器中相互独立的寄存器与计算单元连接起来。当然,这样的设置仍非常灵活、能够很好地适应不同工作负载,并轻松实现系统扩展与组件升级,在很长一段时间内仍将成为传统计算的首选方案。
但就 AI 计算而言,这类任务运算简单、数量庞大且可预测性高,传统处理器在等待模型权重在内存间往来传输时,会长期处于闲置状态。IBM 研究院的科学家和工程师正在研发新型处理器,例如 AIU 系统,希望采取各种策略以突破冯·诺依曼瓶颈并增强 AI 算力。
冯·诺依曼瓶颈为何存在?
冯·诺依曼瓶颈以数学家兼物理学家约翰·冯·诺依曼命名,他于 1945 年首次发表了可存储程序的计算机这一构想草案。在这篇论文中,他描述了一种包含处理单元、控制单元、用于存储数据和指令的内存、外部存储器以及输入/输出机制的计算机。他的描述并未提及任何具体硬件——这可能是出于他当时美国陆军顾问的身份,希望避免安全审查问题。当然,几乎没有哪项科学是完全由一个人完成的,冯·诺依曼架构也不例外。冯·诺依曼的工作基于 J. Presper Eckert 和 John Mauchly 的成果,他们发明了世界上第一台数字计算机——即电子数字积分计算机(ENIAC)。但在冯·诺依曼的文章发表以来,其同名架构长期成为业界标准。
IBM 研究院科学家 Manuel Le Gallo-Bourdeau 表示,“冯·诺依曼架构非常灵活,这是其主要优势所在,也使其得到广泛采用,且时至今日仍代表着主流架构的设计思路。”
内存与计算单元彼此独立,意味着我们可以做分别设计,或灵活按照所需方式进行配置。从过往经验来看,这样的计算系统设计确实更容易,也能根据应用场景选择最适合的组件方案。
即使是被集成在处理器同块芯片上的缓存,也同样可以单独升级。Le Gallo-Bourdeau 表示,“设计新缓存确实会在一定程度上影响处理器,但至少不像一体式架构那么困难。二者仍然相互独立,这样就能在缓存设计与处理器设计间保留一定的自由度。”
冯·诺依曼为何拉低效率?
于 AI 计算而言,冯·诺依曼瓶颈会在两方面拉低效率:其一是需要移动的模型参数(或权重)数量,其二则是需要移动的距离。IBM 研究院科学家 Hsinyu Sidney Tsai 表示,模型权重越多代表存储空间越大,通常对应着存储距离越远。“由于模型权重数量极大,系统根本不可能长时间持续保存,因此需要不断丢弃并重新加载。”
AI 运行时的主要能耗就来自数据传输,即模型权重在内存和计算单元间的往来移动。相比之下,计算本身的能耗反而较低。例如,在深度学习模型中,运算大多是相对简单的矩阵向量乘法问题。Tsai 表示,计算能耗在现代 AI 工作负载中仅占 10%左右,虽然也不容忽视,“但与传统计算形式不同,它不再是决定能耗和延迟的主导因素”。
Le Gallo-Bourdeau 表示在大约十年前,冯·诺依曼瓶颈还不是什么问题,毕竟当时的处理器和内存效率本就不高,数据传输的能耗相对没这么夸张。但多年以来,数据传输效率的提升幅度明显不及处理器和内存。这就导致在数据被冯·诺依曼瓶颈卡死的同时,本可以更快完成计算任务的处理器只能白白闲置。
内存距离处理器越远,数据传输所消耗的能源就越多。从最基础的物理效应来看,一根铜线充电代表传输 1、放电代表传输 0.充电和放电所消耗的电力与线缆长度成正比,因此线缆越长消耗的电力就越多。而线缆越长,电荷消散或传输所需要的时间也更长,所以延迟会更大。
虽然单次数据传输的时间和能源成本都不高,但在大语言模型的使用场景下,系统会频繁从内存中加载多达数十亿条权重。这可能对应着一张或多张其他 GPU 的 DRAM(单张 GPU 无法提供足以容纳所有权重的内存)。在将数据下载至处理器后,处理器会执行计算,再将结果发送至另一内存位置以做进一步处理。
Tsai 介绍称,除了消除冯·诺依曼瓶颈之外,“整个行业也在努力改进数据本地化。”IBM 研究院的科学家最近就公布了新方案:一种用于共封装光学器件的聚合物光波导模块。该模块将具备极高传输速度与带宽密度的光纤放置在芯片边缘,增强了芯片的连接性,进而大幅降低模型的训练时间与电力成本。
但在现有硬件条件下,特别是有限的数据传输能力下,训练一套大模型仍然需要几个月时间,且消耗的电力也远超典型美国家庭在同等时间内的水平。此外,模型训练完成后系统仍需要消耗电力执行推理,而推理过程的计算需求类似,意味着冯·诺依曼瓶颈仍在阻碍系统运行。
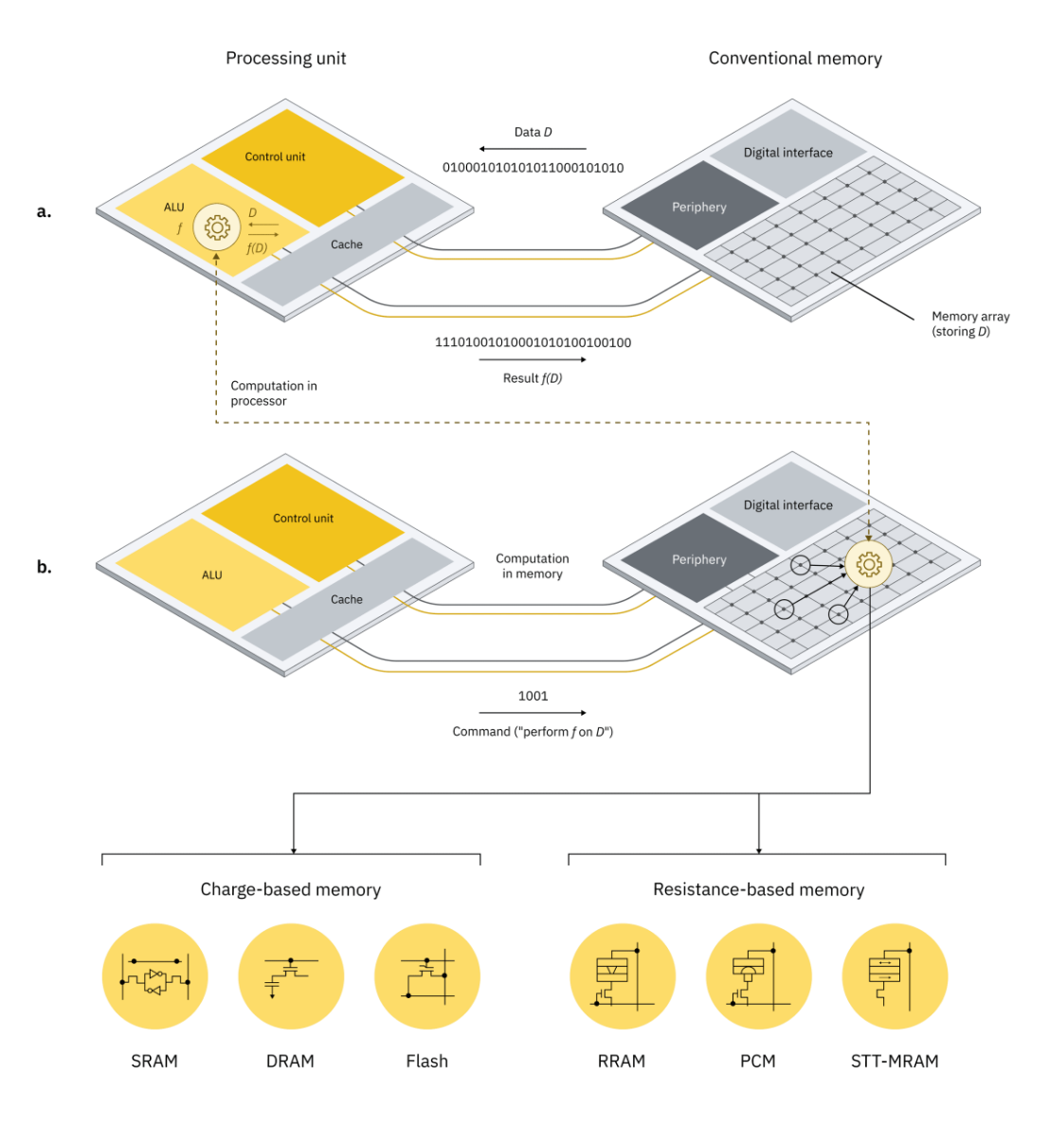
a.在传统计算系统中,当对数据 D 执行运算 f 时,必须将 D 移入处理单元,这会导致显著的延迟和能耗成本。b.在内存内计算的情况下,f(D)利用存储设备的物理属性在计算内存单元内执行,因此无需将 D 移入处理单元。计算任务在内存阵列及其外围电路的范围内执行,也就无需解密各个内存单元的内容。基于电荷的内存技术(例如 SRAM、DRAM 和闪存)以及基于电阻的内存技术(例如 RRAM、PCM 和 STT-MRAM)都可以作为此类计算内存单元的实现要素。来源:《自然·纳米技术》
突破瓶颈
Le Gallo-Bourdeau 表示,在大多数情况下模型权重是固定不变的,而 AI 计算则以内存为中心、而非计算密集型任务。“相当于面对一组固定的突触权重,且只需通过它们传播数据。”这样的特性让模拟内存内计算成为可行的潜在方案,即将内存与处理集成在一起,利用物理效应来存储权重。其中一种方法是相变存储器(PCM),即使用硫属化物玻璃的电阻率存储模型权重,再通过施加电流来改变电阻率。
Le Gallo-Gourdeau 表示,“这样我们就能减少数据传输所消耗的电力,同时缓解冯·诺依曼瓶颈。”但除了内存内计算,冯·诺依曼瓶颈似乎还有其他解法。
AIU NorthPole 是一款将内存纳入数字 SRAM 的处理器。它的内存与计算功能虽不像模拟芯片那样交织在一起,但各核心均可访问本地内存,因此也可算作近内存计算的典型案例。实验已经证明该架构拥有强大的功能和前景。在最近基于 IBM Granite-8B-Code-Base 模型开发的 30 亿参数大模型推理测试中,NorthPole 的处理速度达到能效第二高的 GPU 的 47 倍,而能效则为延迟第二低的 GPU 的 73 倍。
更值得注意的是,冯·诺依曼硬件上训练出的模型必须能够在非冯·诺依曼设备上运行。这一点对于模拟内存计算而言至关重要。PCM 设备的耐用性不足以承受权重数据的反复变更,因此更适合用于部署由传统 GPU 训练完成的模型。相比之下,SRAM 内存可无限重写的特性,成为其在近内存/内存内计算中的一大比较优势。
冯·诺依曼计算并不会消亡
尽管冯·诺依曼架构成为 AI 计算的瓶颈根源,但对于其他应用场景,其仍然非常合适。除了模型训练和推理等少数用例,冯·诺依曼架构在计算机图形处理及其他计算密集型流程中的表现无人能敌。对于需要 32 位或 64 位浮点精度的任务时,内存内计算的低精度也还无法胜任。
Burr 解释称,“对通用计算而言,冯·诺依曼仍然是最强大的架构方案。就像在一家品类多样的速食店,有人可能会点萨拉米肠、意大利辣香肠或者其他肉食,店员则可以在不同食材间灵活切换,快速制作出好几个三明治。”相比之下,专用计算则类似为一份订单制作几千个金枪鱼三明治——这就是 AI 计算的特点,需要传递大量静态模型权重。
当然,在构建内存内 AIU 芯片时,IBM 研究人员也会使用一些常规硬件以实现必要的高精度运算。
Le Gallo-Bourdeau 总结道,尽管科学家和工程师们正努力探索能消除冯·诺依曼瓶颈的新方法,但专家们一致认为未来这两种硬件架构将并存、而非相互替代。“合理的方案是混合使用冯·诺依曼与非冯·诺依曼处理器,让它们各自承担擅长的运算任务。”
原文链接:
https://research.ibm.com/blog/why-von-neumann-architecture-is-impeding-the-power-of-ai-computing




