众所周知,在当下,数据科学是一个蓬勃发展的领域,为什么会蓬勃发展呢?首先是因为大数据的发展。我们现在拥有了越来越多的数据,这为数据科学的应用创造了肥沃的土壤,进而使得一个又一个奇迹的创造成为可能。拿大家都耳熟能详的 AlphaGo 作为例子。
十年以前,人们说计算机要在围棋上打败人类需要 50 年到 100 年的时间,但是 10 年内计算机就做到了这一点。为什么?就是因为可以获取的棋谱的数据逐步线上化,基于这些数据和一些更新的方法,而不是靠计算量解决这个问题。基于大数据,很多影响人们生活的技术已经被孕育出来,比如计算广告、推荐系统,现在还正在蓬勃发展的无人驾驶车等等。
在 TalkingData,我们每天都处理大量的数据。目前在我们的平台上,日活是 2.5 亿、月活是 6.5 亿。每天我们能够收到 14TB 的数据,处理 370 亿条消息,收到 35 亿个位置定位点。这么庞大的数据基础,加上和 TalkingData 的合作伙伴进行数据交换整合,我们形成了以人为中心的从里到外的三层数据,包括人的数据、基本属性、兴趣爱好,以及人经常出现的场景,在这些场景上的动作、行为。
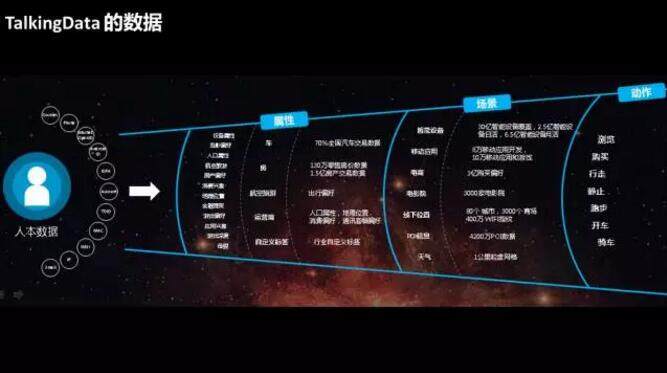
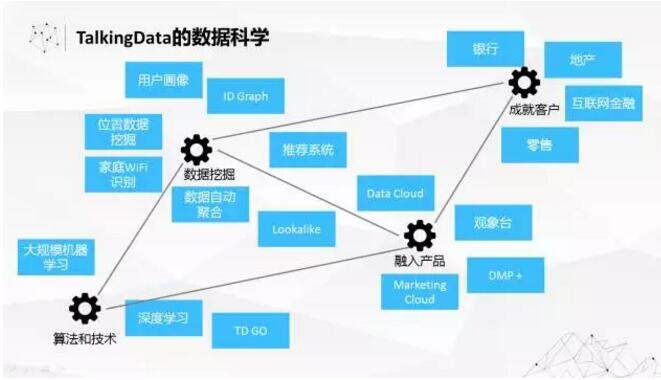
基于这样的数据海洋,我们的数据科学工作在各个层次、各个领域也是全面开花。为了支持在庞大的数据上去挖掘深度价值,我们在大规模机器学习方面做了很多工作。基于算法技术,我们支撑了很多数据挖掘的实际应用,努力把数据科学、算法的能力融入到 DataCloud、MarketingCloud 这些公司重量级战略性产品里面。
同时,我们也会基于数据挖掘的能力以及相应的应用和产品,帮助我们的客户去创造更大的价值。现在我们在银行、地产、互联网金融、零售里面都有很多成功的案例。在这里就不一一介绍了。
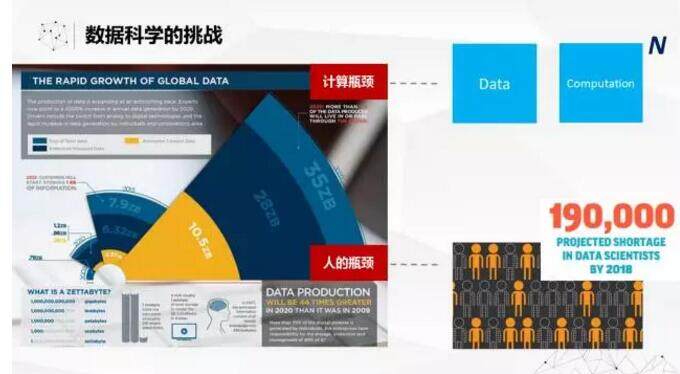
讲完了目前数据科学的现状,我们来讲讲数据科学面临的挑战。我们看到最大的挑战是数据量的迅速膨胀。看到这样一个报告:在 2015 年全球存储的数据是不到 8ZB(1ZB 相当于 100 万个 PB 的数据)。到了五年之后的 2020 年,这个数字将达到 35ZB,数据的膨胀速度是非常快的。这就带来了两个大问题,其中一个是计算的瓶颈。虽然现在一般的大数据技术已经能够处理很大的数据量了,但是在数据科学领域,很多机器学习算法有这样的特性,当数据增长一倍的时候,相应计算量要增加 4 倍或 8 倍,也就是呈几次方的速率来增长。可以想像,数据量的膨胀对于计算资源的需求是会呈几何级数的扩大的。
据美国的报道,到 2018 年整个美国可能会有 19 万数据科学家的缺口。因为我们数据膨胀很快,带来了很多新的数据的问题,也带来相应的新的探索机会。但是数据科学家的队伍的发展和培养是没有那么快的。在美国 2018 年的缺口是 19 万,以中国的体量来看,肯定会有更多、更大的缺口。
计算的瓶颈,人的瓶颈都是我们面临的挑战。我们今天就来说说 TalkingData 是怎么去解决这两个难题的。
突破计算的瓶颈

首先是怎么去突破计算上的瓶颈。刚才也谈到了计算上的瓶颈,在这里说的更细一点,为什么计算量是随着数据超线性增长的?这边引用了非常有名的 Machine Learning 一篇文章,里面总结了机器学习的十大算法的复杂度。M 是数据量,N 是数据的维度,可以看到所有的算法要么是跟维度乘平方或三次方的关系,或者是跟 M 是平方或三次方的关系。
在小数据上不太突出的问题,比如在算法上需要多次迭代,在大数据的情况下,由于必须把数据放在 HDFS 上面, I/O 的代价是非常庞大的。我们自己测算过一些,实际上真正计算的开销仅仅占到全部开销的 5% 到 10%,90% 到 95% 的时间都花在 I/O 上面。
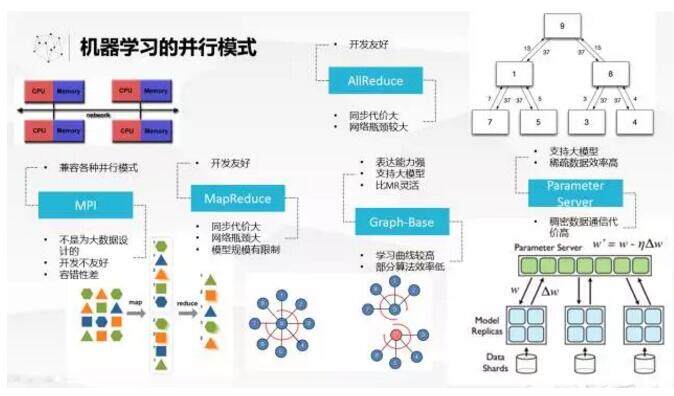
为了解决大规模机器学习问题,工业界和学习界都做了很多努力。最开始是运用 MPI,这个相对来说比较古老的并行接口来做大规模机器学习。MPI 肯定本身还是比较灵活的,但是因为本身不是为大数据、以数据为中心的计算来设计的,所以在处理做大规模机器学习的时候还是有不少问题,首先开发不够友好,学习曲线比较高。容错性也比较差,如果跑一个大规模机器学习任务,跑了很久突然出问题了就不好处理。
Hadoop 兴起后,很多人也尝试用 Hadoop 来实现机器学习算法。但是很快大家认识到在 Hadoop 上的 MapReduce 有很大的问题,一是 BSP 模式,所以同步代价很大。同时要做 Shuffle,网络瓶颈也比较大。因为单个节点上的内存限制,也不能把规模放得特别大。为了解决 MapReduce,后面又提出了 AllReduce,通过树形通信来减少通信开销,这个机制在 Spark 里面就实现了。当然还有一波人认为 MapReduce 太粗了,所以就提出了 Graph-Base 的模型,这套模型的表达能力比较强、比较灵活,也可以处理比较大的模型。我个人认为,这个模型稍微复杂了一点,对于开发者来说学习曲线相对高了一点,而且也不是对所有算法有比较好的效率。
最近几年谈到大规模机器学习的框架,经常被提起的是 Parameter Sever,它是为了解决超大规模、超大维度吸收数据的机器学习的问题。因为它很简单,就分成了 Parameter Sever 和 worker 两组的节点。Parameter Sever 可以把模型分布式在各个节点上,每个 Work 去进行算法的局部训练,然后同步地去跟 Parameter Sever 来更新模型或者获取最新的模型。这种模式,如果是稠密数据,比如有亿维度数据是密的,肯定是不可行的。为什么呢?因为中间的通信会变得非常庞大。幸运的是超大规模机器学习的问题一般是稀疏的,所以目前 Parameter Sever 解决大规模机器学习最关注的一个方向。
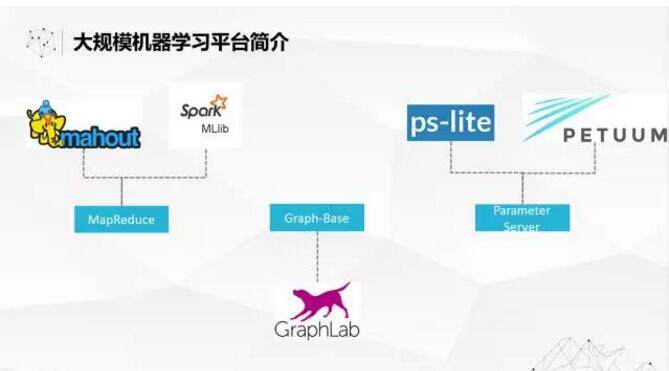
市面上开源的大规模机器学习的框架并不是特别多或特别成熟。比如基于 Hadoop Map Reduce Mahout,有很大的问题,效率很低。我曾经跑过一个算法,在几百台机器上花了 50 分钟,数据是 100+G,找了大内存机器去跑,自己写了一个算法 5 分钟就跑完了。实际上,基于 Hadoop 来做机器学习的效率非常低。后来 Spark 出现了,各种机制、调度比 Hadoop 更加优化一点。所以 MLLib 里面算法的效率是大大高于基于 Hadoop 的算法的效率。Graph-Basc 有一个项目是 Graphlab,后来基于 Graphlab 成立了一个公司叫 Dato, 前几个月刚改名 Turi,刚刚被苹果收购了。Parameter Sever 开源的有 ps-Lite,这个项目我们也做过一些调研,发现它总体来说是比较轻量级的框架,但是对于实际应用上来说,可能还不够完善。另外一个是 Petuum,在机器学习界很多人应该也知道它,我们现在也在跟他们在谈一些合作,看看怎么把 Petuum 真正带到实际应用中来。
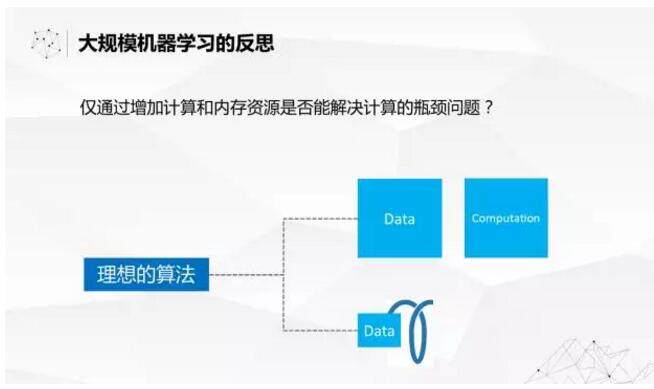
我们现在要反思一下,我们看到前面的大规模机器学习解决的路径是什么?基本上是在考虑如何能够更好地并行,提高并行的效率。然后通过增加机器,计算能力和内存资源来解决计算的瓶颈。 但是大规模机器学习的计算瓶颈是算法本身造成的问题,一个是计算量跟数据量的超线性增长带来的,一个是多次迭代带来的。如果我们的算法能够解决这两个问题,在进行大规模机器学习的时候,对系统的压力会减轻很多。我们的理想算法是什么样子的?是线性算法,而且最好是迭代一次就能够收敛并且取得很好的效果。
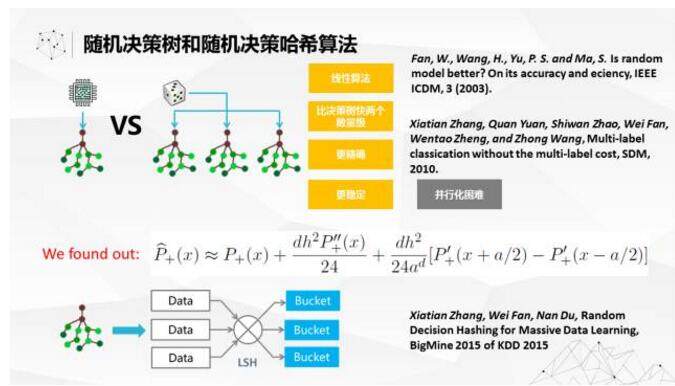
在这一块,我们也做了很多的研究工作。之前我在 IBM 做机器学习研究的时候,看到了一个很有意思的算法,就是范伟博士在 2003 年提出来的随机决策树的算法。这个算法跟一般的决策树或随机决策树有很大的不同,每一颗树的构建过程是完全随机的,随机构建空树以后,把数据灌进去,然后统计每个节点的分布。预测的时候,每个树给出一个正常的预测过程,给出一个预测的概率,然后把多颗树的结果做平均就可以了。我在 2010 年对算法的复杂度做过一些分析,应该说这是一个线性的算法,计算了跟数据量增长呈线性关系。
而且通常在单机上测的话比决策树速度要快两个数量级以上,通常跑的更精准,而且更不容易 over fitting,算是比较好的 base line 算法。但是也有一个问题,因为树结构的算法,并行化是比较困难,单机上比较好实现。怎么在构建的过程中同步树的状态,其实是非常麻烦的事情。
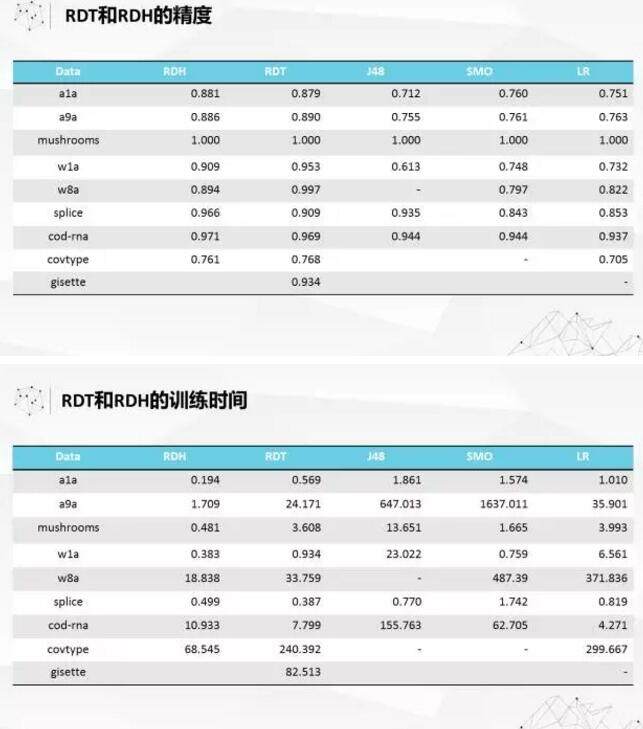
我们后来基于对随机决策树理论的研究,发现其实随机决策树起作用的不是因为用了决策树这个结构。其实随机决策树起到的作用,仅仅是把数据随机打散,每一个数据是不同的打散方式。我们想着用局部敏感哈希来代替树的功能,就提出了随机决策哈希的算法。这个文章发表在了 2015 年 KDD 的 Bigmine Workshop 上面。我们看看这两个算法的精度跟传统的算法的精度,后面三个分别是决策树, SVM 和 Logistc Regression 我们可以看到精度上面,这两个都有比较大的优势。而且和传统的算法相比,运算时间也是有很大的优势。
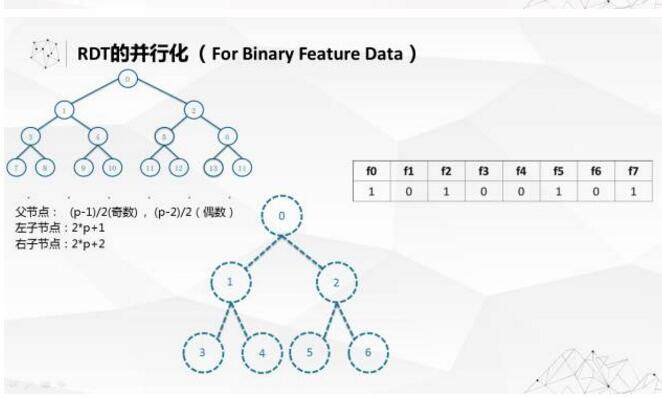
我们尝试过把随机决策树做并行化,但是发现只有在一种情况下可以做到比较好的并行。所有的数据的功能全部是二值的,这种情况下建空树,所有的空树要建成满二叉树的状态,可以用宽度优先的编码方式,可以把每个节点编码起来。中间的左右值节点有一个关系,可以通过运算方式去回溯,这样就使树在实际应用中不需要建立实体树。在实际运用过程中,运用了一些哈希,在不建实体树的情况下来保证随机决策树的算法,有一个小动画来解释基本原理。
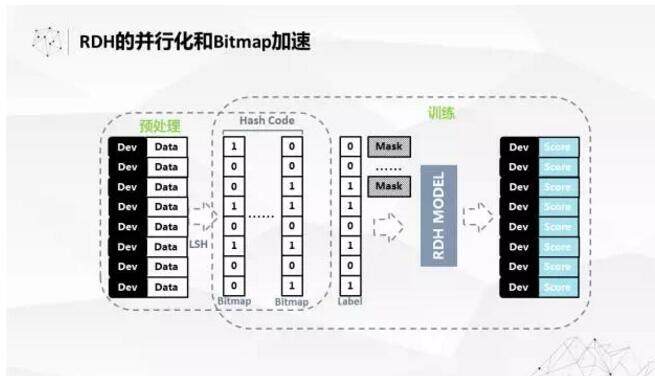
RDH 的算法是非常好并行的,也不用去考虑太多其他因素。但是我们为了进一步提高速度,因为我们做了局部敏感哈希,很多中间的过程就变成了 binary 的向量,可以用 Bitmap 表达,用 Bitmap 引擎来加速算法的运算过程。我们测过在 4 到 5 亿的数据集上,可以做到 100 秒以内,在 Spark 上并行 100 秒以内的训练过程,而且还包括了 Spark 本身的调度时间。
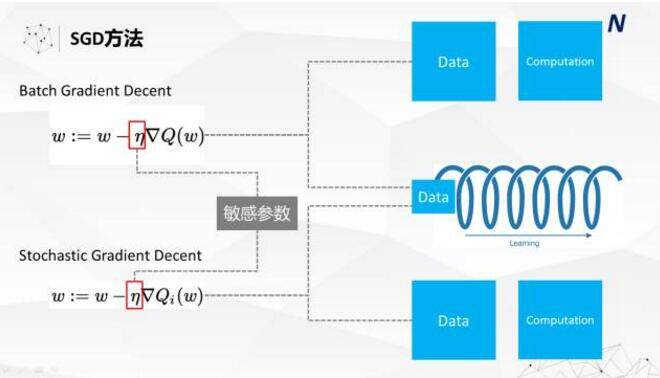
前面的方法都是非参数的方法,非参数的方法有很多的问题,一是模型建出来会比较大,应用起来没有那么方便。二是可解释性相对差一点,在很多实际应用中,我们还是希望使用更简洁的参数模型,比如说像 Logistic Regression 等算法。要求解这种方法,基本的方法是梯度下降,大规模的问题用随机梯度下降更多。我在这里简单列了一下 Batch 的梯度下降和随机梯度下降的区别。随机梯度下降最大的好处是把计算量降下来了:原来做批量随机梯度下降的话,计算量跟数据量是呈几次方的关系,但是在随机梯度下面基本上呈线性关系。但是随机梯度下降还是要进行数据的多轮迭代,因为每次只过一个数据,过数据的次数就要更多一些。
另外,在实际应用中,梯度下降方法的参数都比较难调,比如对于学习率的设置,对于不同问题、不同数据是非常敏感的。如果再考虑到正则化系数,调参就变得更加复杂。

我们对 SGD 方法也做了很多的优化,一是我们现在做到了可以无参数一次迭代收敛。主要原理是利用每一步的梯度信息,进行动态学习率改变,让模型快速收敛。这个工作还有一些理论上的小问题没有完全解决,所以还没有公布出来。随着我们机器学习项目的开源,我们也会把这个研究结果,包括算法和理论上的成果公布出来。
在大规模学习上要做稀疏正则化也是比较大的难题,我们这边采用了一些比较实用的方法,根据内存的容量动态计算可以保存高维度的模型。这样就使得在做稀疏正则化的时候不需要调参数,尽可能保证丰满的模型,同时保证要高效地把模型训练出来。
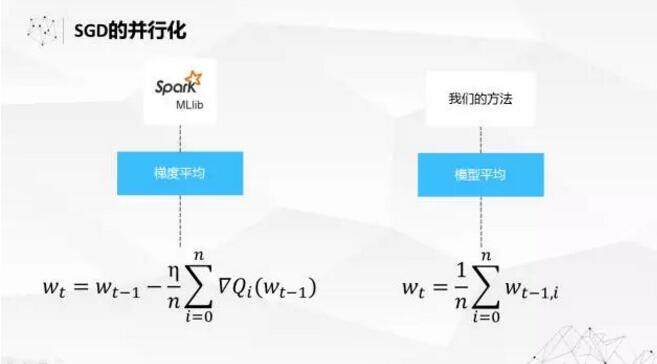
在机器学习算法并行化方面,有三种可以考虑的方法:梯度平均,模型平均,还有结果平均。结果平均就是 Ensemble,这里不讨论。对于梯度平均而言是 Spark Mllib,包括很多基于 Parameter Server,用每一个数据或者每一个小批量的数据去产生一个对模型系数的更新量,然后把更新量汇集起来统一对模型进行更新,然后再把模型发送到所有节点,这是一个梯度平均的过程。另外一种方法更简单一点,就是在每个数据分片上跑自己的模型,把所有数据分片的模型做平均。我们看过一些文献,从理论上来说梯度平均的收敛性、理论保证会比模型平均更好一点。但是我们在实际中做了大量的测试,至少现在我们的方法跟 MLlib 对比有压倒性的优势。
我们把在前面参数和非参数模型上做的工作集合了起来,把它放到了即将开源的项目中,我们把这个项目叫做 Fregata。Fregata 是军舰鸟的名字,TalkingData 内部的项目不管是开源还是非开源的都是用鸟来命名。为什么将机器学习的这个项目命名成军舰鸟呢?因为它是世界上飞行速度最快的鸟,可以超过 400 公里每小时。另外,它非常轻,只有 3 斤重,却又两米长的翼展,在全球分布很广。这也是我们对项目的期许:轻量级,可以承载大规模的机器学习任务,效率高,同时又能适应非常广的机器学习算法库。
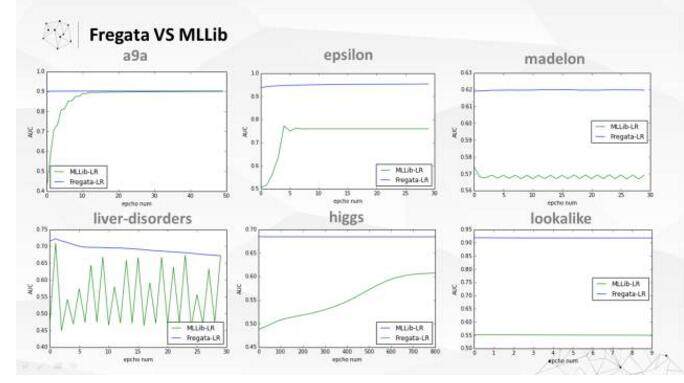
这就是 Fregata 与 MLLib 的 LR 算法比较,蓝色的线都是 Fregata 的算法,绿色的是 MLlib 的算法,每个图的横坐标是数据扫描的次数,纵坐标是精度判断指标 AUC。我们可以看到,不管是精度、收敛速度和稳定性,Fregata 都是远远强过 Mllib 的。基本上每一次都可以一次就达到最高的精度水平,或者非常接近最高的精度水平。

这是 Fregata 的配置和接口。配置只有一行,非常简单。最简单的训练代码也就 5 行,因为我们不需要去设置参数,所以代码就变得非常简洁。
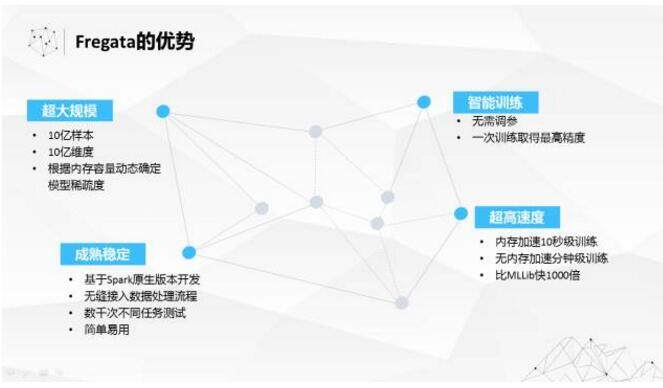
总结一下 Fregata 的特点。首先是对大规模问题的支持。我们实际测试过,处理超大规模 10 亿级样本,是完全没有问题的。对于超大规模维度的问题,Fregata 能根据内存容量动态确定稀疏度的方式解决,而且速度非常快,如果内存加速的话,可以在亿级别的数据上做到 10 秒级别的速度;无内存加速的话,也能达到分钟级训练。据我了解,国内互联网公司里面非常昂贵的机器学习平台上面的速度,可能至少要比我们这个慢一个数量级。
我们跟 MLlib 做过对比,在某些情况下能够快 1000 倍,一般情况快个 10 倍以上也是很正常的。由于我们的开发是基于 Spark 原生版本,所以能非常容易的融入数据处理流程。因为不需要解决调参的问题,所以可以做一个标准组件,比较容易嵌入数据处理流程。
超越个人的智慧
简单再讲讲 TalkingData 怎么在解决人的瓶颈。因为我们的数据科学家团队并不是特别大,这样一个比较小的团队,面临着这么大量的数据,靠自己是很难完成的。
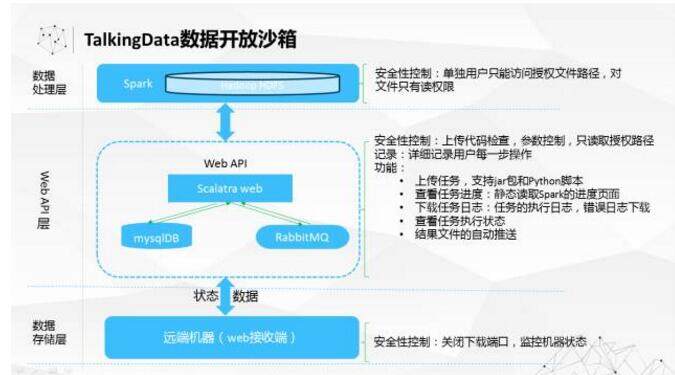
我们 TalkingData 作为一个中立的数据平台,愿意把数据开放出去。但是在开放数据创造更大价值,跟保护数据的安全隐私的全方位怎么平衡呢?今年上半年我们做了一个 TalkingData 的数据开放沙箱,在沙箱里可以向指定的人开放指定的数据。数据科学家可以在沙箱里探索数据、创造价值,同时保护原始数据不能够被拿出沙箱来保证数据的安全,来确保利用数据创造价值和保护数据安全的平衡。

沙箱的应用上,有比较成功案例。一是我们向 Thasos 开放了 8TB 的数据,二是我们跟清华大学合作的课程开放了 100GB 的数据,他们在上面做了很有意思的工作。
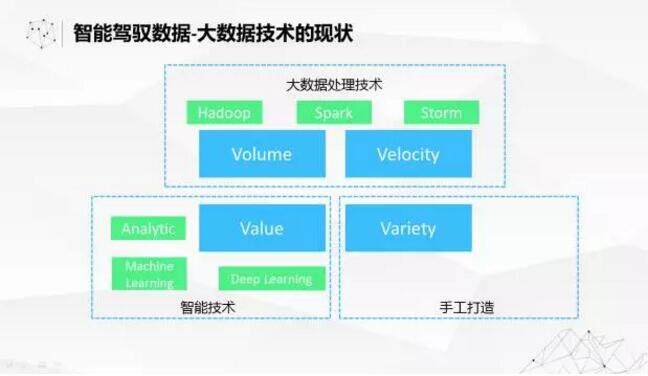
即使把数据开放出去引入全球的数据科学人才,也不能完全解决人的问题。刚才也看到了全球的人才是比较有限的。现在再看大数据四个 V 的支撑技术做的什么样,在速度跟体量上面,有很多大数据技术解决得不错了。在价值方面,我们有很多的人工智能的方面的发展也是非常迅速的。但是解决数据来源的复杂性是很难的,我们内部有数据管理员的团队,他们就是每天纯手工来做数据标准化清洗的工作,目前来说是整个大数据里面最短的一版,所以现在我们也在努力尝试把智能的方法引入到数据准备、数据清洗的工作中来。
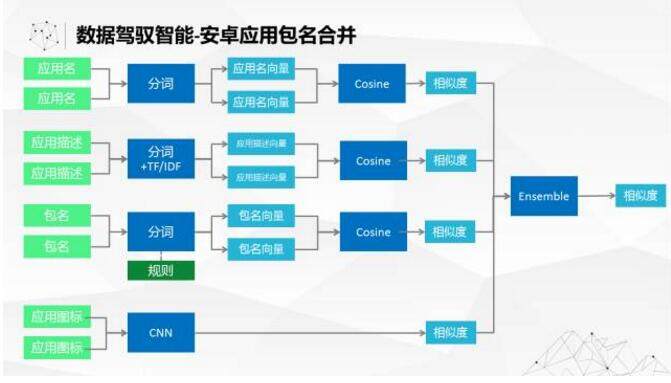
我们未来希望能够用智能做数据的自动关联,希望把几十个来源不同的数据源、不同格式的扔进去,就可以很快地把数据关系梳理清楚,相似、相同的数据下表达方式不同的也能够迅速聚集在一起。
在这个方面我们已经做了很多工作,比如在 android 的和包方面用了深度学习技术、文本技术,把各种技术集合在一起来判断多个不同的包是不是属于一个应用。
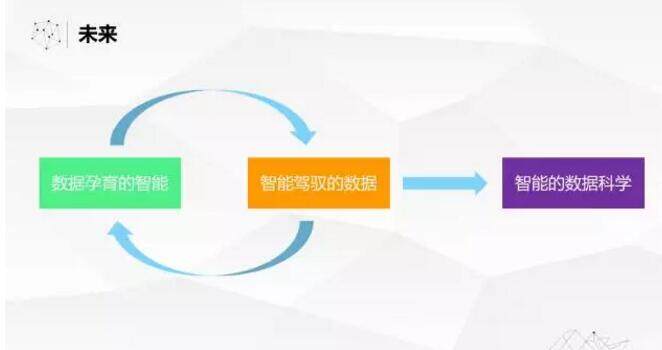
让我们来畅想一下未来,前面提到了在大数据上孕育了非常多的智能奇迹。如果在把这些智能运用在驾驭数据,可以形成非常好的正循环,使得数据科学发展变得越来越快的加速螺旋上升的过程,为我们创造更好的未来。
Q&A
Q1:如何访问 talking data 的沙箱?
张夏天:目前访问 TalkingData 的数据沙箱需要向 TalkingData 提出申请,明确使用数据范围,用途, 并签订 NDA 以后(如果涉及商业用途还需要签订商业合同)后,TalkingData 会为申请者提供访问帐号。
Q2:也就是一个新版的 mllib?
张夏天:可以这么认为。我们在实际使用中,发现 MLLib 的问题还是比较多的,无论是训练速度还是精度都不能满足我们的需要。因此我们自己实现了一些 Spark 上的机器学习算法。
Q3:大数据应用的最新挑战是什么?
张夏天:目前来说我们认为最新的挑战是把数据处理流程如何智能化。现在大数据应用最大的一个短板就在于应用的成本很高,而很大一块以成本就在于基础的数据处理过程,需要投入大量的人力来完成,限制了大数据应用的规模化快速复制。因此我们认为未来应该应用数据科学,人工智能的先进技术和方法来解决数据处理过程过于繁琐和笨重的问题,降低大数据应用的成本。
Q4:fetegata 基于 spark 实现的,他是如何做到性能比 spark 高很多倍。另外我们用它不需要调整参数就可以得到很好的效果,具体是怎么做到的?
张夏天:最根本的原因就是提高了算法的收敛速度和稳定性,使得在一般情况下,只需要扫描一次数据,极大降低 IO 开销。关于 Fregata 是如何做到这点的,大家可以耐心等待几周,我们很快将把 Fregata 开源出来,同时会在 arxiv 网站上 publish 相关论文,届时欢迎到家试用和批评指正。
Q5:lib 库的一个特点是根据内存大小,自动调整维度么?
张夏天:是的。因为 Spark 平台本身的限制,参数并行很困难,因此单个节点的内存大小就限制了模型的大小。在面对超大维度问题时,通过稀疏正则化可以降低模型的规模,使得能够在单个节点的内存中存储。但是一般的稀疏正则化方法的稀疏度是依赖于 L1 正则化项的系数的,并不能精确控制模型的稀疏度。我们在很多实践中发现,做模型稀疏度越高其精度也会越低,所以我们希望算法能够把模型的规模降到内存刚好装下的规模,取得精度和效率之间最好的平衡。
Q6:您好,fregata 的功能确实很强悍,目前是开源的吗,普通用户怎么能够体验到?
张夏天:10 月份之内会开源,到时候会发布到 Github 上,所有人都能使用。我们将采用 Apache 2.0 的 License。
Q7:在优化过程中,模型平均是否受数据分布倾斜的影响,比梯度平均较大?你们工作中,比 spark 的梯度平均好的原因,是不是因为你们的数据分布较均衡?这是不是算是极端情形,而不能看做一般情形?
张夏天:应该不是。我们的测试不仅是基于我们自己的数据,我们还测试了很多公开数据集。有大数据集,也有小数据集,有低维度密集数据,也有高维度系数数据。测试的结果都是类似的。
讲师介绍
张夏天:TalkingData 首席数据科学家,12 年大规模机器学习和数据挖掘经验,对推荐系统、计算广告、大规模机器学习算法并行化、流式机器学习算法有很深的造诣;在国际顶级会议和期刊上发表论文 12 篇,申请专利 9 项;前 IBM CRL、腾讯、华为诺亚方舟实验室数据科学家;KDD2015、DSS2016 国际会议主题演讲;机器学习开源项目 Dice 创始人。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




