

在训练神经网络时,并行计算和模型并行是很常用的方法,以最大限度地利用有限的算力。然而,谷歌的一项新研究表明,数据并行并不一定总能加快模型训练速度。这是为什么呢?
过去十年多中,神经网络已经在各种预测任务中实现了最先进的结果,包括图像分类、机器翻译和语音识别等。这些成果的取得至少部分应该归功于软硬件的改进加速了神经网络训练。更快的训练速度直接使得模型质量显著提高,可以处理更多的训练数据,也让研究人员可以更快地尝试新的想法和配置。今天,像云 TPU Pod 这样的硬件开发商都在迅速提高神经网络训练的计算力,这既提高了利用额外计算的可能性,使神经网络训练速度更快,还促进模型质量得到更大改进。但是,我们究竟应该如何利用这空前强大的计算力,更大的算力是否一定意味着训练速度更快呢?
利用巨大算力最常用方法,是把算力分配到多个处理器上并同时执行计算。在训练神经网络时,实现这一目标的主要方法是模型并行,在不同处理器上分布神经网络;数据并行是指在不同处理上分发训练样例,并且并行地计算神经网络的更新。虽然模型并行使得训练大于单个处理器可支持的神经网络成为可能,但通常需要根据硬件需求定制模型架构。相比之下,数据并行是模型不可知的,且适用于所有神经网络体系结构,它是用于并行神经网络训练的最简单、最广为采用的技术。对于最常见的神经网络训练算法(同步随机梯度下降及其变体),数据并行的规模和样本大小、用于计算神经网络的每次更新的训练样本的数量相对应。但是,并行计算有什么限制?我们什么时候才能实现大幅度的训练加速?
在《测量数据并行在神经网络训练中的作用》一文中,我们在实验中使用三种不同的优化算法(“优化器”)在七个不同数据集上运行六种不同类型的神经网络,来研究样本大小和训练时间之间的关系。总的来说,我们在约 450 个工作负载上训练了超过 100K 的单个模型,发现了我们测试的所有工作负载中样本大小和训练时间之间看似普遍的关系。我们还研究了这种关系如何随数据集、神经网络架构和优化器而变化,结果我们发现,工作负载之间的差异非常大。此外,我们很开心地把原始数据分享出来,供研究界进一步分析。这些数据包括超过 71M 的模型评估,组成我们训练的所有 100K +单个模型的训练曲线,并可用于复现我们论文中提到的所有 24 个图。
样本大小与训练时间之间的普遍关系
在理想的数据并行系统中,处理器之间的时间同步可以忽略不计,训练时间可以通过训练步骤来计量(神经网络参数的更新)。在此假设下,我们在样本大小和训练时间之间的关系中观察到三种不同的缩放模式:“完美缩放”模式,其中样本加倍,达到目标样本外错误所需的训练步骤数减半;其次是“收益递减”模式;最后是“最大数据并行”制度,即使在理想的硬件环境中,进一步增加样本也不会减少训练时间。
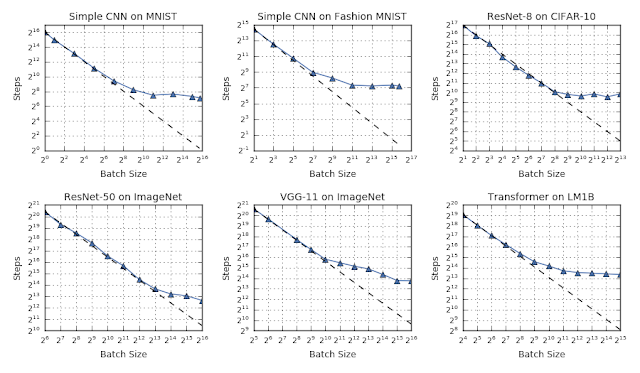
(对于我们测试的所有工作负载,我们观察到样本大小和训练速度之间的普遍关系具有三种不同的模式:完美缩放(沿着虚线),收益递减(从虚线偏离)和最大数据并行(趋近平行)。各模式之间的过渡点在不同的工作量上变化很大。)
虽然样本大小和训练时间之间的这些基本关系看似普遍,但我们发现,在不同神经网络架构和数据集上,三种缩放模式之间的转换点变化很大。这意味着,在当今的硬件条件下(如云 TPU Pod,),虽然简单的数据并行可以大大加速某些工作负载,但是另一些工作负载需要的不仅仅是简单的数据并行。例如,在上图中,CIFAR-10 上的 ResNet-8 无法从大于 1,024 的样本中受益,而 ImageNet 上的 ResNet-50 只有当样本至少增加到 65,536 才可能继续受益。
优化工作负载
如果可以预测哪些工作负载可以最大化地从数据并行训练中受益,那么我们就可以定制工作负载,以最大限度地利用可用硬件。但是,我们的结果表明这不一定行的通,因为最大化利用有用的样本在某种程度上取决于工作负载的方方面面:神经网络架构、数据集和优化器。例如,某些神经网络架构可以从比其他架构更大的样本中受益,即使在使用相同优化器对相同数据集进行训练时也是如此。虽然这种影响有时取决于网络的宽度和深度,但它在不同类型的网络之间是不一致的,并且一些网络甚至没有明显的“宽度”和“深度”概念。
虽然我们发现某些数据集可以从比其他数据集更大的样本中受益,但这些差异并不总是因为数据集的大小引起的,有时对于较大的样本,较小的数据集也可能比较大的数据集受益更多。
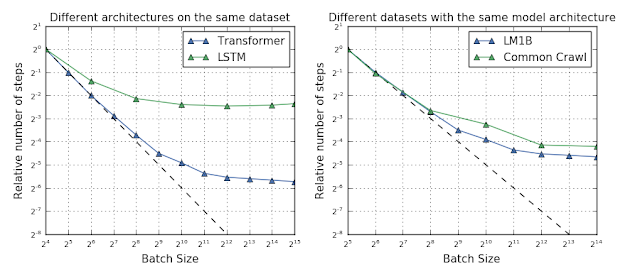
(左图: 在 LM1B 数据集上,transformer 神经网络比 LSTM 神经网络扩展到更大样本的样本。右图:Common Scrawl 数据集并不比 LM1B 数据集受益更多,尽管前者大小是后者的 1,000 倍。)
也许最让人鼓舞的发现是,即使是优化算法的微小变化,如随机梯度下降的 momentum ,也可以随着样本扩大显著改善训练。这让新优化器或测试优化器缩放属性的可能性变大,以找到可以最大限度地利用大规模数据并行的优化器。
未来的工作
通过增加样本数量,利用额外的数据并行是一种加速工作负载的简单方法,但是,我们的实验显示工作负载加速的优势由于硬件限制在逐渐减小。但另一方面,我们的结果表明,一些优化算法可能可以在许多模型和数据集中扩展完美的缩放模式。未来,我们可以用相同的方法测试其他优化器,看看现在是否存在可以将完美模式拓展应用到所有问题中的优化器。
原文链接:
https://ai.googleblog.com/2019/03/measuring-limits-of-data-parallel.html

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论