
Anthropic 开源了一款用于追踪大语言模型在推理过程中内部活动的工具。该工具包含了一个环路追踪Python库,可用于任何开放权重的模型,以及托管在 Neuronpedia 上的前端,可通过图形界面探索库的输出。
正如 InfoQ报道的,他们揭示 LLM 内部行为的方法是用另一个模型替换实际的模型,这个模型使用跨层 MLP 转码器的稀疏活跃特征,而不是原始神经元。这些特征通常可以代表可解释的概念,从而可以通过移除不影响正在调查输出的所有特征来构建归因图。
Anthropic 的环路追踪库能够从指定模型中识别替代环路,并使用预训练的转码器生成归因图。
它计算每个非零转码器特征、转码器错误节点和输入词元对其他非零转码器特征和输出 logit\【注:模型在应用 softmax 等概率函数之前为每个可能的输出分配的原始(非归一化)分数】的直接影响。
正如 Anthropic 的一名研究人员在 Hacker News 上指出的那样,归因图揭示了模型在采样标记时所经历的中间计算步骤,这为理解模型行为提供了宝贵的见解。基于这些见解,我们可以有目的地操纵转码器特征,并观察模型输出的相应变化。
Anthropic 已经使用环路追踪器对 Gemma-2-2b 和 Llama-3.2-1b 中的多步推理以及多语言表示进行了深入研究。以下是为提示词“Fact: The capital of the state containing Dallas is(事实:包含达拉斯的州的首府是)”生成的归因图。
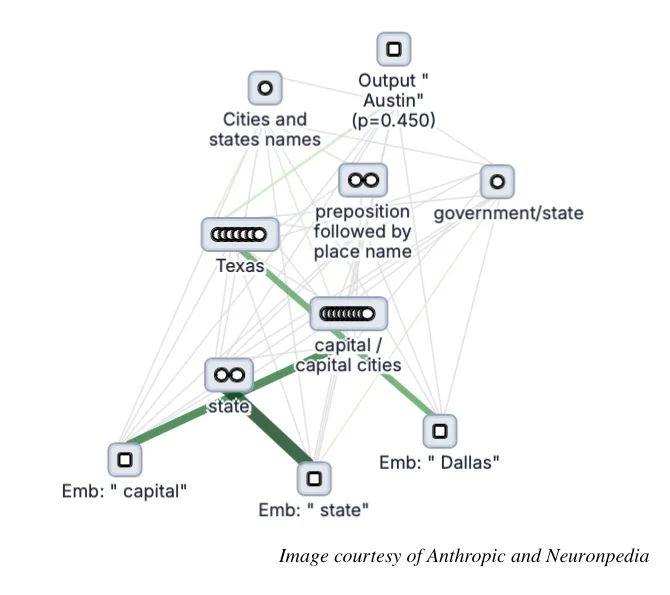
在 Dwarkesh Patel 主持的一场播客节目中,Anthropic 的 Trenton Bricken 和 Sholto Douglas 解释了 Anthropic 对环路追踪的研究如何成为 LLM 机制可解释性的关键贡献,即努力理解 LLM 内部的核心计算单元是什么。这项工作对先前使用玩具模型、稀疏自编码器以及初步环路的研究基础进行了扩展。
现在,你正在识别模型各层中协同合作以执行复杂任务的各个特征。通过这一过程,你可以更深入地洞察模型究竟是如何进行推理并做出决策的。
这一领域仍处于起步阶段,随着大语言模型的安全应用变得越来越重要,其重要性也日益凸显:
鉴于人工智能的发展速度以及我们现有工具的状况,我们或许无法从一开始就证明一切都是安全的。但我认为这无疑是一个极具价值的目标。当我们意识到自己只是整个人工智能安全体系中的一部分时,这一目标显得尤为有力且令人安心。
你可以通过 Anthropic 的教程运行环路追踪库。或者,你也可以在Neuronpedia上使用它,或在本地安装。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2025/06/anthropic-circuit-tracing/




