

本文最初发表于 Towards Data Science 博客,经原作者 Mandy Gu 授权,InfoQ 中文站翻译并分享。
Rasa是一种开源的对话式人工智能框架,它使用机器学习来构建聊天机器人和人工智能助手。
今天,我将向大家展示如何使用 Rasa 构建自己的简单聊天机器人,并将其作为机器人部署到 Facebook messenger 上,一小时之内就可以完成。而你所需要的,只是一些简单的 Python 编程和可用的 Internet 连接。
完整的代码可以在我的GitHub 仓库找到。
我的代码是在 Python 3.7 中开发和测试的。Rasa 目前只支持 Python 3.8 以下的版本 (更新请看这里:https://rasa.com/docs/rasa/installation/)。
要构建的机器人非常简单,无需深入研究任何高级自然语言处理应用。不过,Rasa 确实提供了对更复杂应用的充分支持。
为了了解更多关于自然语言处理的知识,我推荐 DeepLearning.AI 开设的这门 Coursera 课程《基于序列模型的自然语言处理》(Natural Language Processing with Sequence Models)。
让我们开始吧
“克隆”我的仓库获取完整的代码。
依赖关系
确保所有的依赖关系都已安装。我们的简单机器人只需要两个库:
如果已经“克隆”了我的仓库,就可以运行pip install -r requirements.txt从根目录来安装这两个库。
spacy 语言模型需要在单独的步骤中安装。
仓库攻略
在展示如何训练和部署助手之前,先通过每个组件来了解它们是如何结合在一起的。
这些文件大部分可以通过运行rasa init来生成,rasa init会创建一个带有训练数据、动作和配置文件示例的新项目。
首先来看一下配置文件。
配置文件
endpoints.yml
这是助手的所有端点的位置。为了支持自定义动作(基本就是你可以编写用于调用其他 API、查询数据库或访问你构建的其他服务的自定义代码),我们需要创建动作服务器。要做到这一点,请在这个文件中包含action_endpoint。
其他端点也可以在这里定义,如,使用 Kafka 发送事件,或将对话存储在 Redis 中而不是内存中。
这就是 endpoints 文件的样子:
config.yml
配置文件定义了如何训练模型,这是你可以发挥创造力的地方。第一行用于指定聊天机器人的语言。在这里,它将是英语:
下一个组件配置自然语言理解管道。我们使用的是 Rasa 推荐的“sensible”启动管道之一。
接下来是policies。这些是 Rasa 将遵循的响应用户信息的策略。
MemoizationPolicy 会记住训练故事中的最后 X 个事件。可通过将max_history添加到策略配置来指定 X。
RulePolicy 利用我们为机器人编写的硬性规则(稍后会介绍)来生成响应。即使 RulePolicy 被指定在第二位,它也会优先于其他策略。因为 RulePolicy 在缺省情况下具有最高优先级:也可以配置这些优先级。根据策略配置,机器人首先要检查适用的规则,否则就会转向训练故事。
我们的策略还配置了默认的回退机制。当一个动作置信度分数低于core_fallback_threshold0.3 时,它将发送一个名为utter_default的预定义响应,并恢复到触发回退之前的状态。这在用户说一些完全没有意义的内容时是很有用的。
credentials.yml
如果代码托管在像 GitHub 这样的地方,你应该在发布该文件前仔细考虑。需要使用此文件进行身份验证,我们会用它与 Facebook Messenger 机器人相连。现在,我暂时隐去了密码,但是稍后会介绍如何从 Facebook 生成此文件。
注意:我的 GitHub 仓库中并没有包含此文件。你需要创建这个文件,然后用稍后生成的令牌对其进行填充。
domain.yml
来自 RASA 的官方文档:
领域定义了助手操作的范围。它指定了你的机器人应该知道的意图、实体、槽、响应、形式和动作。它还定义了对话会话的配置。
domain.yml 文件被分解为意图、实体、槽、响应、动作和会话配置。
训练机器人识别定义的意图,并根据检测到的意图采取不同的行为。
如果在管道中指定了一个实体提取器,它将提取这个文件中定义的所有实体;实体可以用来进一步控制对话流程。
槽是机器人将信息存储到内存中的键值对;槽可以在对话期间的任何时候被设置、重置和检索。
响应是预先定义的响应模板,用于机器人发送消息;当机器人达到该状态时,默认回退将始终发送与
utter_default相关联的消息。动作包括任何已定义的自定义动作。
在会话配置中,可以定义会话过期时间,以及是否应该将槽引入到新的会话中。
训练数据
将训练数据分成三个文件夹:nlu、rules 和 stories。在 nlu 文件夹中,定义了意图和实体。在 rules 文件夹中,定义了通过 RulePolicy 进行操作的规则。stories 文件夹中包含了模拟对话,这些对话被用作额外的训练数据,以了解如何管理对话。
nlu.yml
在 NLU 设置中,定义了一些非常基本的意图。下面是“greet”意图的一个例子,它使用了以下的训练数据:
官方文档更详细地介绍了如何改进 NLU 组件,例如加入实体、同义词和查找表。
rules.yml
rules 定义了机器人应该始终遵循的小型对话模式。RulePolicy 利用这些 rules 来管理对话流程。
这里定义了一个简单的规则“always greet the user”。当机器人遇到“greet”意图时(它根据上面提供的数据学习识别问候意图),它会用自定义动作action_greet来跟进。
stories.yml
stories 是“真实”对话的例子,用于进一步训练机器人的对话管理模型。它们被写成用户和机器人之间的对话交流。
我们将包括一个非常简单的故事。
自定义动作
自定义动作对于更复杂的机器人来说非常有用,它们可以用来调用其他内部自然语言处理服务或公共 API 来改善对话体验。
自定义动作存储在actions/actions.py中。
下面是自定义动作action_greet的一个例子,它可以向用户问候。
每个自定义操作都遵循一个非常标准的格式。有一个name方法返回自定义动作的名称,这个名称必须与 domain.yml 中提供的名称一致。
run方法需要接受调度器、跟踪器和域。
调度器用于生成响应(在这里,它将发出两条消息)。
追踪器指的是对话追踪器,可以利用它调出槽值、当前和过去的状态。
返回值是一个在动作结束时执行的事件列表。下面是一些我们可以包含在其中的常用事件:
SlotSet:用于设置槽值。
FollowupAction:触发一个后续行动。
Restarted:结束当前对话。
训练和启动机器人
一旦准备好以上所有的文件,就可以训练机器人了。在根目录下运行rasa train来开始这个过程。根据数据有多少,管道有多复杂,这可能需要一段时间。
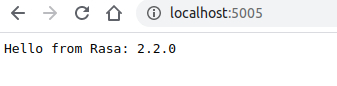
如果能够看到这条消息,就说明模型已经成功训练并保存。

需要运行两个命令来启动机器人:一个用于动作服务器,一个用于机器人本身。在这里,我把它合并成一行。
注意:这将在本地启动机器人。稍后,将需要用 Facebook 生成的令牌来填充我们的凭据文件,以便将其部署到 Messenger。
这是我的终端在该命令运行完成后的样子。每次服务器进行对话时,都会有额外的日志。

在运行上述操作时,动作服务器将占用 5055 端口,机器人将占用 5005 端口。
可以通过 ping http://localhost:5005 来测试服务器是否在运行。
与机器人交互
有几种方式可以让你开始与机器人交互。
REST API
可以通过 REST API 与机器人进行交互。当 RASA 服务器运行时,发送这个请求,以用户身份发送消息:
sender 字段是对话的唯一 ID。当同一 sender 字段下连续发送消息时,服务器将识别它是一个对话的一部分。message 字段是要发送的文本。
RASA shell
可以运行rasa shell,通过命令行与机器人开始对话。
Facebook Messenger 设置
我对部署 Rasa 服务器的偏好是通过ngrok来完成,这将使你的本地端口暴露在公共互联网上。另外,你也可以使用像 Heroku 这样的服务,但是 Rasa 镜像的大小让它很难在大多数免费服务保持应用的运行。
ngrok 设置
创建 ngrok 账户。
按照这些说明在计算机上设置 ngrok:https://ngrok.com/download。
在单独的终端中运行
./ngrok http 5005,在端口 5005 上启动 HTTP 隧道。
确保终端在任何时候都能运行,只要终端被中止,那么隧道就会停止,机器人在 Messenger 上就会没有反应。
记下生成的 URL。需要向 Facebook 提供安全的 URL(带 https 的那个)。
在 Facebook 上创建应用程序
Facebook 机器人需要连接到 Facebook 页面。需要一个 Facebook 账户来创建一个页面。
一旦页面创建完毕,请访问 https://developers.facebook.com/apps。点击绿色的“Create App”按钮,创建一个新的应用程序。

选择第一个选项,然后按照说明创建应用程序。
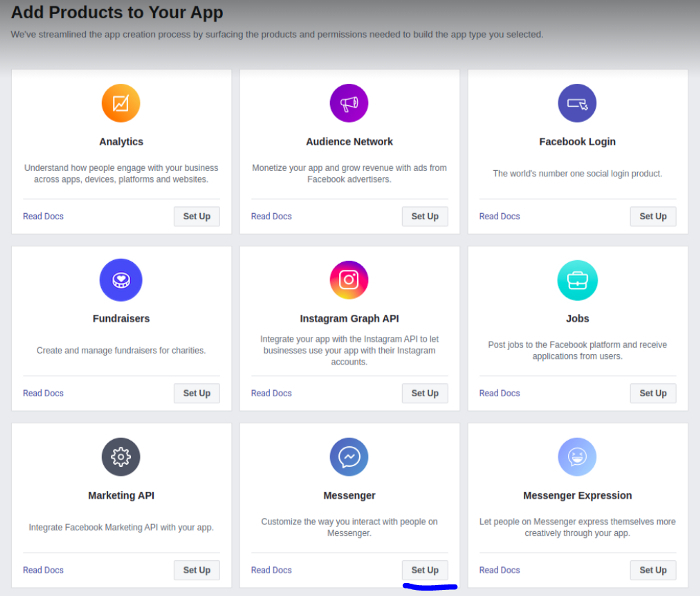
点击下方的“Set Up”按钮,将“Messenger”添加到应用中。
在 Facebook 上设置应用程序
一旦应用程序被创建,它应该引导你到 Messenger 下的“Setting”页面。如果没有自动进入那里,请导航到应用程序仪表板,然后进入“Messengers”→“Settings”。
首先,将 Facebook 页面链接到应用程序。

在链接页面旁边,添加订阅允许 messages。
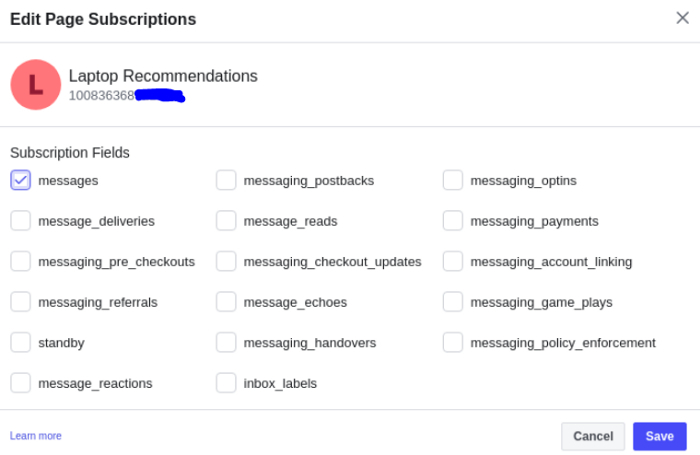
一旦页面被链接,点击页面旁边的“generate token”。追踪这个令牌(token),因为它将需要包含在你的 Rasa 项目中。我们将此标记称为“页面访问令牌”.
接下来,在仪表板上导航到 settings→basic,找到应用密码(app secret)。

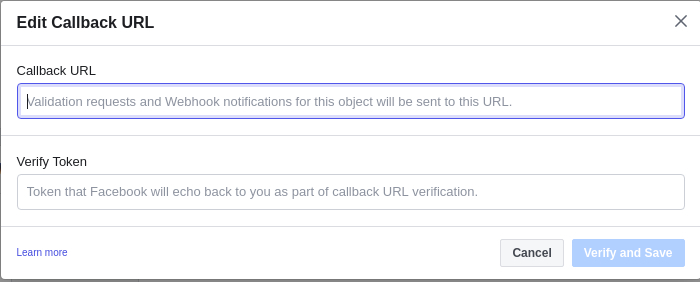
然后,向下滚动到“webhooks”来添加一个新的回调 URL。

在填写回调细节之前,在 Rasa 项目中创建 credentials.yml。这个文件应该是这样的:
下面是如何填充字段:
verify:创建一个你选择的安全验证令牌。
sectet:这是应用程序的密码,从 basic settings 中获取。
page-access-token:使用之前为页面生成的页面访问令牌。
通过运行以下命令再次启动 Rasa 服务器。这与之前的命令略有不同,因为我们现在利用了凭据标志。
取出作为 credentials.yml 一部分创建的验证令牌,并在 Webhooks 部分的回调 URL 一起输入。
回调 URL 是 https://{ngrok_url}/webhooks/facebook/webhook。
注意:在任何时候,如果 ngrok 隧道停止,都必须重新启动它,并更新 Facebook 上的回调 URL。
验证应用程序是否已启动并运行
导航到你的页面并尝试给机器人发消息。
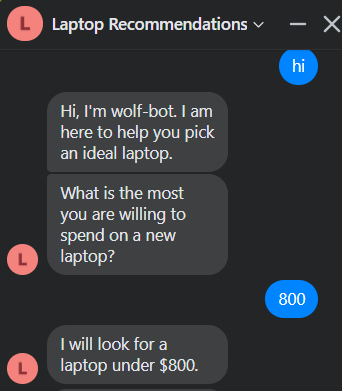
太棒了,都准备好了!实际上,在目前的状态下,机器人并不会就笔记本计算机的推荐话题做出有意义的对话……也许有一天它会 😆
作者介绍:
Mandy Gu,Wealthsimple 数据科学家。
原文链接:

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论