

为什么承认架构中的偏见是关键?
本文最初发表于 Towards Data Science 博客,经原作者 Mastafa Foufa 授权,InfoQ 中文站翻译并分享。
在本文中,我们想要关注一个特定的模型。最近发布了 Face-Depixelizer 模型,该模型基于《PULSE:通过生成模型的潜在空间探索实现对自监督照片上的采样》(PULSE: Self-Supervised photo upsampling via latent space exploration of generative models)。该模型可以从像素化的版本输出原始图片。更为严格地说,它将输出最接近已知的去像素化图像。

图 1:(x32) 输入(顶部)向上采样到 SR 图像(中间),而 SR 图像则缩小(底部)到原始图像。来源:原始论文
按照GitHub 仓库上的描述,给定一个低分辨率的输入图像,Face-Depixelizer 将通过搜索生成模型(此例为StyleGAN)的输出,来寻找具有真实感且适当缩小尺寸的高分辨率图像。
更为准确地说,正如这篇论文中所揭示的那样:“该方法使用了一个预训练生成模型来生成图像,该模型近似于所考虑的自然图像的分布。对于给定的输入 LR 图像,我们遍历由生成模型生成的潜在空间参数化的流形,以找到适当缩小尺寸的区域。通过这一过程,我们找到了适当缩小尺度的真实图像的示例,如图 1 所示。”
这种人工智能模型有什么问题?
如果你输入一张像素化的黑人照片,比如巴拉克·奥巴马或蒂埃里·亨利,它仍然会输出一张白人的面孔,而不管这个输入的黑人是多么出名。下面的图 2 显示了这样一个示例的 PULSE 输出。这当然意味着该模型偏向于白人的面孔。
这可以泛化到多个场景,我们将在下一篇文章中对其进行深入探讨。现在,假设你的公司正在使用一种自动招聘候选人的模型。如果这种模型是偏向白人的,那么在某些情况下,这个模型最终推荐聘用黑人的可能性就会非常小,甚至不会推荐黑人。

图 2:在一些例子中,其中 PULSE 获得了非常“遥远”的图像,作为重建的像素化输出。
这就引出了 Yann LeCun 的解释。
我们如何解决偏见?
正如下面所解释的那样,大多数情况下,我们的模型仅仅是基于本身存在偏见的数据进行训练。训练一个计算机视觉模型,如果只对狗和猫进行分类的话,它将不知道如何分类其他动物,如鲸鱼。
Yann LeCun认为:“当数据存在偏见时,机器学习系统就会存在偏见。这个人脸上采样系统让每个人看起来都像白人,因为这个网络是在 FlickFaceHQ 上进行预训练的,其中主要包含白人照片。在来自塞内加尔(Senegal,西非国家)的数据集上训练完全相同的系统,每个人看起来都会像非洲人。”
这个问题再清楚不过了。当然,数据本身是首要考虑的问题。这就是为什么预处理和数据挖掘是机器学习中至关重要的步骤。如果对数据的性质一无所知,那么训练模型就没有任何意义。如果我们的目标是我们想要分类的输入集的多样性,那么我们的数据集就需要多样性。
让我们通过查看 Face-Depixelizer 数据集的多样性来快速验证杨立昆的说法。但是,在此之前,让我们先从更广泛的角度来看这个问题。
我们能评估数据集中的多样性吗?
在很多情况下,评估你的数据集是否足够多样化,并不是一项简单的任务。然而,有一个问题需要时刻牢记在心:“我的数据真的能代表我感兴趣的人群吗?”假如我对猫和狗的分类感兴趣,那么我的猫是否有足够的多样性来显示所有可能的猫品种?对于新员工来说也是如此:如果公司要维护多样性和包容性,那么感兴趣的人群在年龄、教育程度、性别、性取向等方面是否足够多样化?
现在,在许多不同的现实世界场景中,它变得更加困难。假设你拥有一个包含客户评论的网站。人们可以在这些评论的基础上建立一个满意度评分。但是,这个满意度分数真的反映了基本人群的真实满意度吗?仅仅根据字面上的评论来评估,是一项非常困难的任务。然而,有些人对你的服务很不满,他们可能会写下很多这样的评论。
我们能评估 Face-Depixelizer 数据集的多样性吗?
Face-Depixelizer 背后使用的是StyleGAN。StyleGAN 本身可以使用许多数据集进行训练:
StyleGAN 使用 Flickr-Faces-HQ 数据集以 1024 × 1024 进行训练。
StyleGAN 使用 CelebA-HQ 数据集以 1024 × 1024 进行训练。
StyleGAN 使用 LSUN Bedroom 数据集以 256 × 256 进行训练。
StyleGAN 使用 LSUN Car 数据集以 256 × 256 进行训练。
StyleGAN 使用 LSUN Cat 数据集以 256 × 256 进行训练。
据作者介绍,Flickr-Faces-HQ(FFHQ)是一个新的人脸数据集,由 70000 张 1024 分辨率的高质量图像组成(本文图 7)。他表示,“与 CelebA-HQ 相比,这个数据集包含了更多的年龄、种族和图片背景方面的差异,以及更多的配饰,如眼镜、太阳镜、帽子等等。这些图片是从 Flickr 上抓取的(因此继承了该网站所有的偏见),并自动对齐和裁剪。”
但作者没有清楚地解释数据多样化的过程。因此,要清楚地说明多样性的程度是很复杂的。但是,他们提供了一个具有高级统计信息的视图,如图 3 所示。
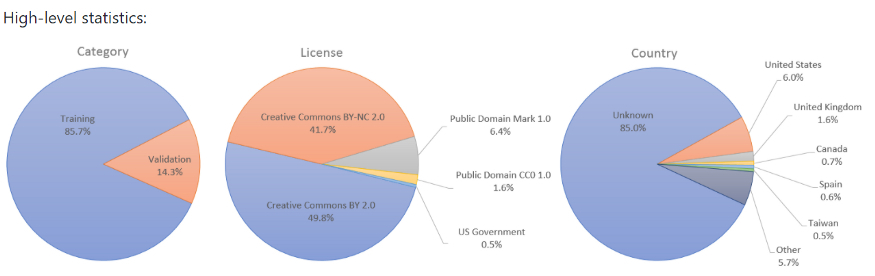
利用源数据可以作为评估多样性程度的第一种方法。对于一个多样化的人脸数据集,代表的国家越多越好。不幸的是,正如上面图 3 的高级统计所示,85% 的图像并没有指定国家,因此被指定为 Unknown(未知)。
另一种方法是建立一个以不同方式对数据进行采样的模型。因此,给定一张图片,这样的模型应该能够识别出一些关键特征,例如年龄、种族和性别。基于这些特征,它可以从基本分布中进行采样。这种模型的简化版本如下图 4 所示,其中我们对美国政坛中著名面孔进行了分类。

图 4:用 opencv 检测性别和年龄。来源:托管在GitHub的模型
接下来,我们使用了一个架构,它基本上做了两件事:一是检测所代表的个体的性别;二是检测所代表个体的年龄段。这样的架构可以集成在一个采样模型中。如图 4 所示,这个模型正确地预测出了性别,但却错误地预测了米歇尔·奥巴马和梅拉尼娅·特朗普的年龄。
这个问题很重要,因为这样的模型应该尽可能没有偏见。换句话说,如果要在采样过程中整合这样的模型,则应该确保正确率足够大,以避免在管道中集成偏见。
实际上,我们可以将采样模型视为机器学习管道中的一个重要模型。这种模型通过从源数据中正确采样,可以更好地表示基本人群。在下面图 5 中,我们展示了如何将这种模型集成到机器学习管道中。
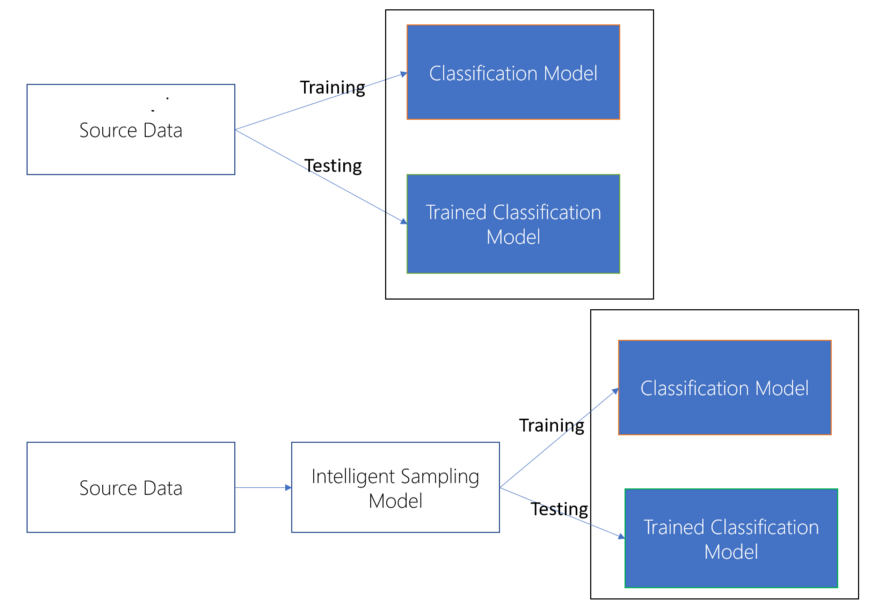
图 5:简单采样模型(上)与智能采样模型(下)。上述管道的第一步是从元数据中随机采样,得到典型的 80% 的训练数据和 20% 的测试数据。基本管道的第一步是专注于关键特征,以确保数据的多样性。例如,基于图 2 所示的模型,性别可能是一个关键特征。确保了合理的性别分布之后,我们就可以从过滤后的数据集中进行采样,并获得训练和测试数据集。
严格地说,在构建训练和测试数据集时,它们也是从基本分布中采样的。但是这样的过程并不会对样本增加任何约束,因此与数据集的偏见程度密切相关。如果你怀疑数据集存在偏见,那么在采样时遵循观测数据集上的简单均匀分布是不可取的!我最近写了一篇关于过采样以解决类不平衡的文章,其中更详细地解释了采样时均匀分布的问题,并对这个问题做了深入的探讨。
处理不平衡的数据集自然可以被视为处理有偏见的数据集。举例来说,假设你事先知道你感兴趣的人群应该是 50% 男性和 50% 女性。因此,如果训练集不能很好地代表这种分布,例如包含 70% 的男性和 30% 的女性,那么对于这篇必读论文中所解释的下游任务,通常需要进行过采样。
可以将“智能采样模型”(Intelligent Sampling Model,ISM)视为一种函数,具有性别和年龄等关键特征,以及这些特征在基本人群中的预期分布情况。然后,在此基础上,ISM 可以对源数据进行采样,并确保预期分布能够在采样数据中得到紧密的表示。其他更完善的方法也可以解决,但不在本文讨论范畴内。下图 6 显示了 ISM 背后的基本概念。
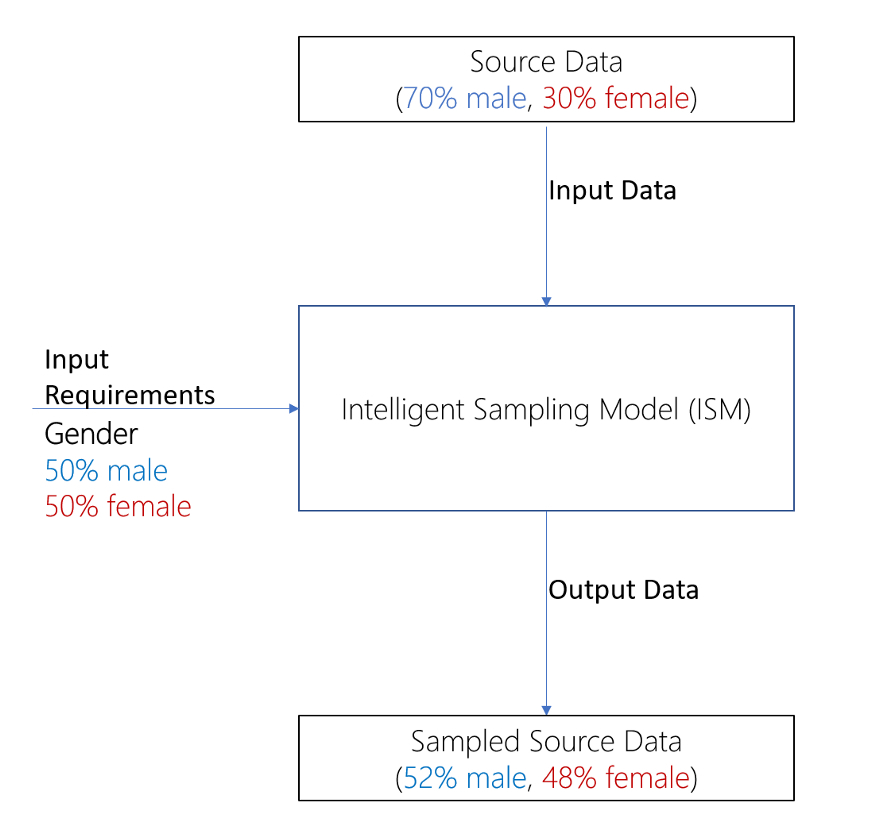
图 6:ISM 背后的基本想法。ISM 允许你根据基于关键特征(如性别)的预定义要求,对源数据进行采样。在本例中,用户对性别设置优先级,ISM 确保在其输出中紧密地表示这种分布。我们从 70% 的男性和 30% 的女性的分布变成 52% 的男性和 48% 的女性分布。
结 论
正如 Soumith Chintala 在 Twitter 上所说的:
“今天,机器学习研究人员无意中推动了一大批非人工智能公司的产品,这些非人工智能公司无知地从互联网上的预训练 BERT/ResNet/YOLO 开始。他们可能忽视了许可、自述文件、发布条款……”
认识到数据可能是存在偏见的,并以透明的方式解决这类问题,需要成为该领域日益关注的问题。
本文介绍了一种架构,这种架构很难泛化到在训练数据中显示出偏见的群体的子集。正如 FFHQ 的作者含蓄指出的,有时候偏见是很难消除的,因此 FFHQ 数据集的图片是取决于 Flickr 固有的偏见。
在所有情况下,在机器学习管道中引入智能模型(ISM)都是关键所在,正如杨立昆所建议的那样,正确的数据采样是减少数据偏见的核心优先级,因此也适用于后续的机器学习架构。总之,认识到我们的架构存在偏见是关键,并且在未来,需要越来越多的关注。
作者介绍:
Mastafa Foufa,微软数据科学家。
原文链接:
https://towardsdatascience.com/the-danger-of-bias-in-ai-c3ce68eabbcc

InfoQ记者

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论