

作者|董道光,喜马拉雅缓存技术专家
KV存储是喜马拉雅最重要的基础组件之一,每天承载着千亿级的请求量。面对公司成百上千的业务,我们怎样满足不同用户对不同场景下的 KV 存储需求?我们又是如何做到服务的高可用,为业务的稳定性保驾护航的?下面,我会给大家介绍下喜马拉雅的 KV 存储演进之路,主要内容包括:
喜马拉雅 KV 存储的演进历史
如何用自研+社区的方式做自己的缓存系统
该系统的运行原理及未来规划
喜马拉雅 KV 存储发展历程
Redis 主从模式
和早期的大多数互联网公司一样,喜马拉雅刚开始的缓存就是简单的主从架构模式,客户端通过 vip 连接到 master 节点,master 节点挂掉时,漂移 vip 到 slave 机器上来保证高可用。这种架构的优点是部署流程简单、易维护,但缺点也很明显,就是 QPS 和容量受限,因为单个 redis 的 QPS 一般不超过 10w,数据量一般需控制在 10GB 内(数据量大,故障重启比较耗时)。
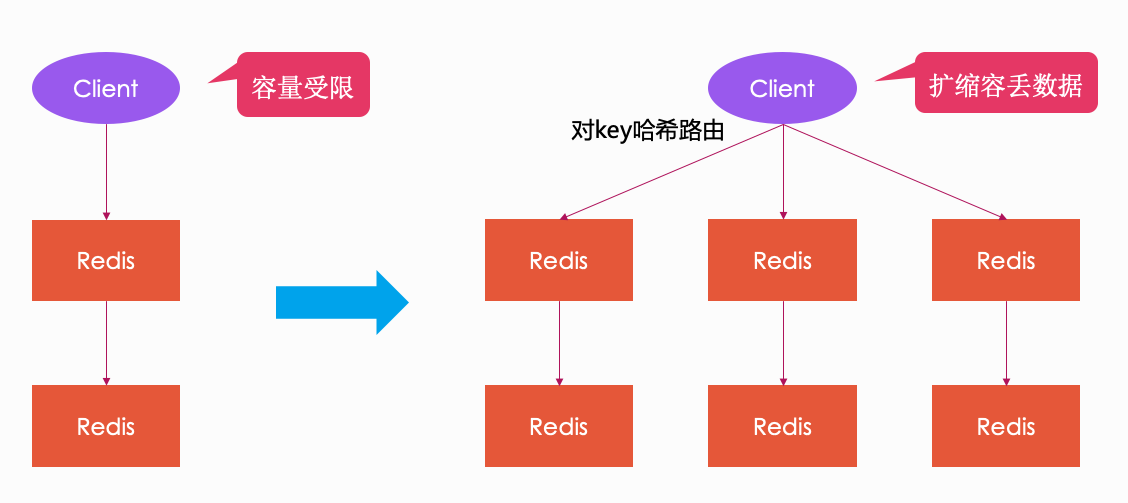
针对上面的问题,大家肯定都想到了既然一个redis不行,那就用多个 redis 一起扛,类似 mysql 的分库分表,于是之后就有了客户端 sharding 模式的架构,即在客户端对 key 做 hash 取模,然后打到后端不同的 redis 节点上。这种架构的优点是可以解决 QPS 容量受限的问题,但缺点也很致命:无法做到弹性扩容,并且增加删除节点时,客户端代码也要跟着一起改动,非常不方便。严格意义上来说,这种架构根本不能算是集群解决方案。
那么,针对上述问题,业界有没有比较好的解决方案呢?答案是有的。
集群模式选型
2016 年时,redis 的集群解决方案还不是很多,我们调研了当时业界比较流行的三种解决方案:
Redis Cluster:优点是官方正版,去中心化,组件少,部署简单;缺点是系统高度耦合,升级困难,缺少大规模生产环境验证(当时 cluster 刚出来没多久)。
Twemproxy:推特开源,proxy 代理,无法平滑扩容缩容,运维不够友好。
Codis Redis:豌豆荚开源,proxy 代理,兼容 Twemproxy,性能优于 Twemproxy。平滑扩容缩容,可视化管理界面。产品成熟,很多公司已经在生产环境使用。
基于上述分析,我们最终选择了 Codis Redis 作为 Redis 的集群解决方案。下面就让我们一起来了解下 Codis Redis。
Codis Redis
Codis Redis 使用 Proxy 做代理,后端连接多个 Redis 分片,客户端连接 proxy,当 proxy 接收到命令时,会对 key 做 CRC32 取模,然后打到后端不同的 Redis 分片上。Codis Redis 还使用 ZooKeeper 做服务发现,当集群中新增一个 proxy 时,会自动注册到 ZooKeeper 上, Jodis 客户端会监听节点新增事件,然后更新 proxy 列表。Codis Redis 自带 web 管理页面 Codis-fe,并且支持对 sentinel 哨兵(高可用组件)的管理,所以在当时来看还是非常好用的。
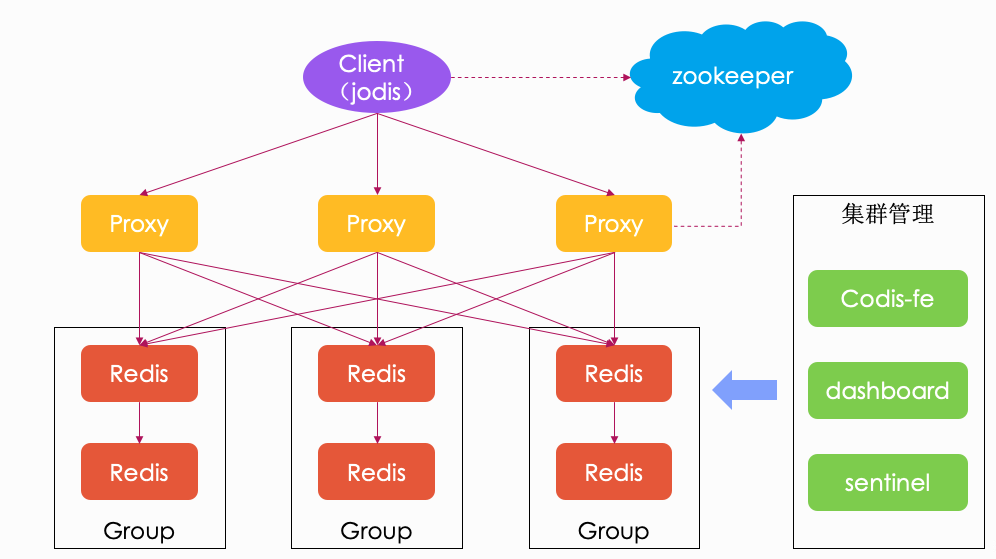
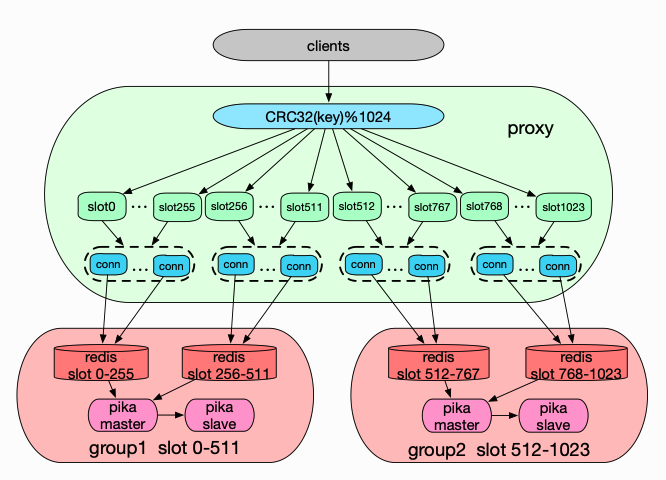
那么,Codis Redis 如何实现弹性扩容呢?Codis 将所有 key 分配到 1024 个 slot 中,每个分片负责一批 slot。如下图,当集群只有 2 个分片时,group-1 负责 0~511 的 slot,group-2 负责 512~1023 的 slot。
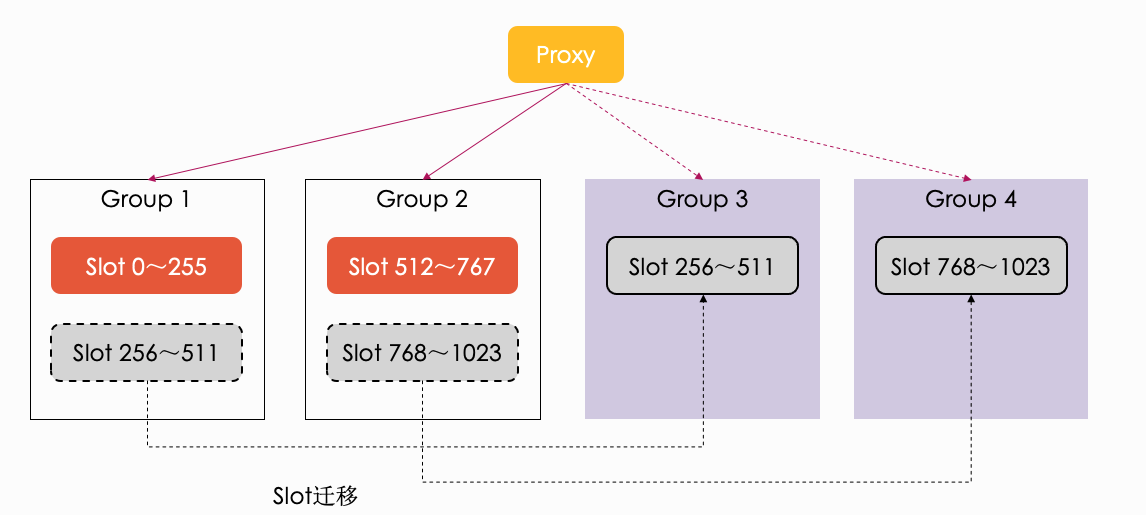
当集群需要从 2 个分片扩容到 4 个分片时,codis 首先将 group-1 中 256~511 的 slot 数据迁移到 group-3 上,然后修改 proxy 的 slot 映射表,将 256~511 的 slot 后端节点修改成 group-3,这样就可以做到平滑扩容。
我们看到 Codis Redis 既解决了单 Redis QPS 容量受限的问题,又解决了 Sharding Redis 无法弹性扩容的问题。那么 Codis Redis 是否就满足了我们所有缓存的使用场景呢?下面,我们看看 Codis Redis 存在的一些问题:
1. 数据全部存储在内存中,消耗大量内存;
2. 业务数据规模较大时,redis 实例较多,运维成本高;
3. 实例重启需要加载数据,故障恢复时间长;
4. 一主多从,主从切换代价大。
结论就是 Codis Redis 并不适合数据量大、但对延时要求不高的业务。那么,针对上述问题,业界有没有比较好的解决方案呢?答案是有的。
Codis Pika
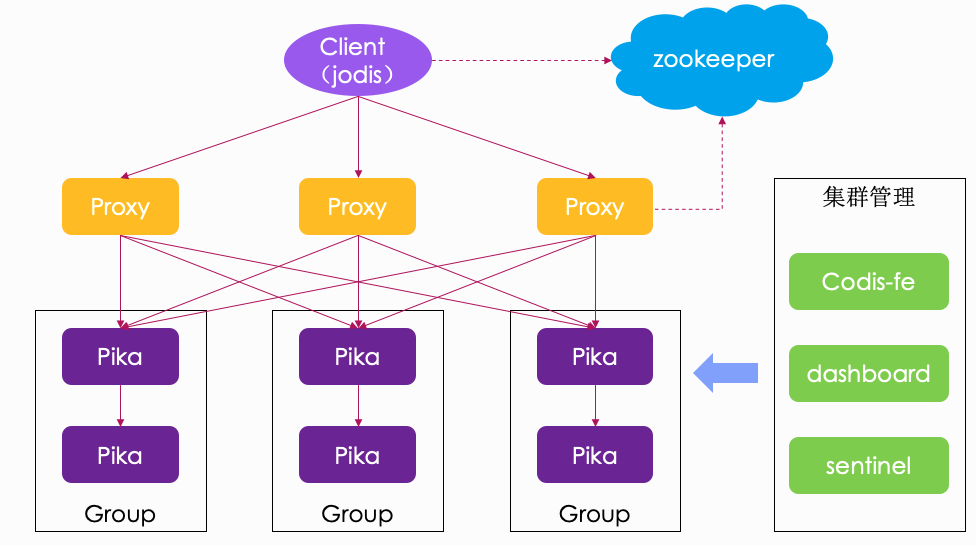
什么是 Pika?Pika 是 360 开源的一款类 Redis 的持久化 KV 存储系统,完全兼容 Redis 协议,兼容 string、hash、list、zset、set 的绝大多数接口。最重要的一点是,Pika 使用磁盘存储数据,突破了 Redis 的内存容量限制,非常适合业务数据量大,但对延时要求不是很高的业务。
我们在 Pika 上定制了类似 Codis Redis 的数据迁移接口,这样就以最小的代价支持了 Pika 的集群模式。如下图:
但是,我们在使用 Codis Pika 上也遇到了很多的问题:
1. 数据量较大时,读磁盘经常出现延时抖动;
2. 底层数据 compact 时,IO 高导致延时毛刺;
3. 基于 key 的数据迁移,扩缩容太慢;
4. 数据存在磁盘,机器内存利用率低;
5. 监控不够完善,定位问题困难。
那么,针对上述问题,业界有没有比较好的解决方案呢?抱歉,这次还真没有。
我们知道,随着公司的快速发展,业务场景的复杂度也会越来越高,很难再有合适的开源产品能很好满足我们的需求。所以,我们最终决定通过自研+社区的方式开发自己的缓存系统:XCache。

我们对 XCache 定位就是要实现容量大、高吞吐、低延时、高可用、运维完善的目标。下面就让我们一起来了解下 XCache 是如何实现这些目标的。
XCache 架构和实践
冷热数据分离
为什么要做冷热数据分离?
Pika 底层使用的是 RocksDB,数据都是存储在磁盘上,这导致机器内存有很大的浪费。另外,Pika 的复杂数据类型性能比较差,读命令经常会出现延时抖动,尤其是 range 查询。
那么该如何更好的利用机器内存来提升 Pika 的性能呢?我们想到的方案就是做冷热数据分离:将热数据缓存在内存中,冷数据存储在磁盘上,业务热数据直接查内存返回,大大降低命令响应时间。
可能有的小伙伴会问,RocksDB 本身不是已经用 block cache 来提高读性能了吗,为什么还要用 Redis 再做一层缓存,是不是多此一举?我想说的是,RocksDB 自带的缓存粒度相对来说比较粗糙,使用 Redis 可以对热数据做更精细化的管控。
如何做冷热数据分离?
那么,热数据缓存该如何加?我们当时有两种解决方案。第一种方案是在 Pika 的上层再加一层 Redis,如下图。这样的好处就是开发比较简单,对 Pika 几乎没有侵入性改动,但缺点也很明显,就是组件太多。Pika 是多线程的,我们测试发现,如果要把单个 Pika 性能打满,前面必须要挂多个 Redis,这就导致了运维成本的增加。另外,多了一层网络传输,就会有一定的性能损耗。
于是我们想到了第二种解决方案,如下图,就是将 Redis 以 lib 库的方式嵌入到 Pika 当中,这需要移植 Redis 代码,并且对 Pika 做深度定制,开发量比较大。但优点也很明显,就是 Pika 的热数据缓存在外界看来就是完全透明的,并且集群架构也不需要做任何改动。所以我们最终选择了该方案。
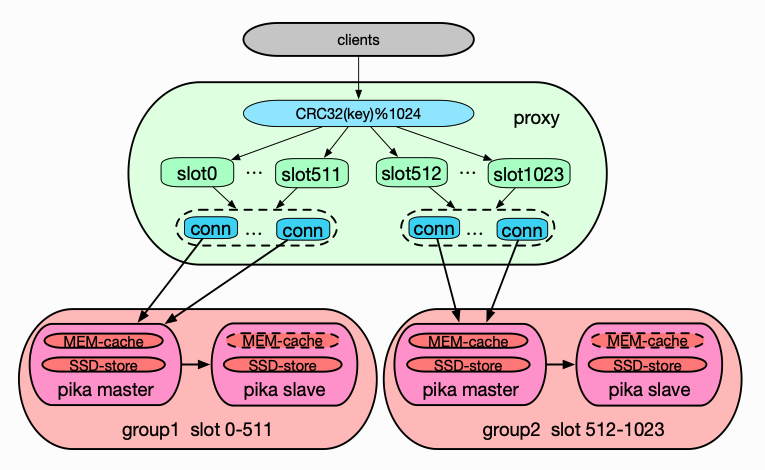
我们在做性能测试时发现,缓存命中的情况下,读的吞吐量相比 Pika 可以提升 1 倍,复杂数据类型的 TP100 延时降低了 90%以上(Pika 的复杂数据类型性能比较差)。
KV 分离存储
为什么要做 KV 分离存储?
RocksDB 的存储引擎采用的是 LSM-tree 架构,这种存储引擎有个缺点,就是存在写放大的问题。写放大就是 RocksDB 为了控制每层数据大小以及删除过期数据,会进行 compact 操作,因此导致大量的 key 和 value 被多次重写,当 value 很大时,写放大的问题会更加明显。写放大会通常会带来以下问题:
1. compact 时磁盘 IO 过高,读写命令产生延时,极端情况下,会导致 flush 速度变慢。当写入速度大于 flush 速度时,有可能触发 rocksdb 的 Write Stall,甚至 Write Stop,产生秒级别的延时。
2. 大大缩短 SSD 的使用寿命。因为 SSD 不支持覆盖写,必须先擦除再写入,而每个 SSD block(block 是 SSD 擦除操作的基本单位) 的平均擦除次数是有限的。
如何做 KV 分离存储?
RocksDB 写入时先写 WAL,然后再写 MemTable,当 MemTable 写满后,会等待后台线程 flush 到磁盘上,可以在 flush 的时候做 KV 分离存储。在 flush 的过程中检测 value 的大小,如果小于设定的阈值(比如 4KB),就不做分离,将 key 和 value 都写到 sst 文件中。如果 value 大于设定的阈值,则将 value 写到 blob 文件中,然后再将 key 和 value 在 blob 文件中的索引写到 sst 文件中。当需要读大 value 时,会先查 sst 文件,然后再通过索引找到对应的 value。如下图:
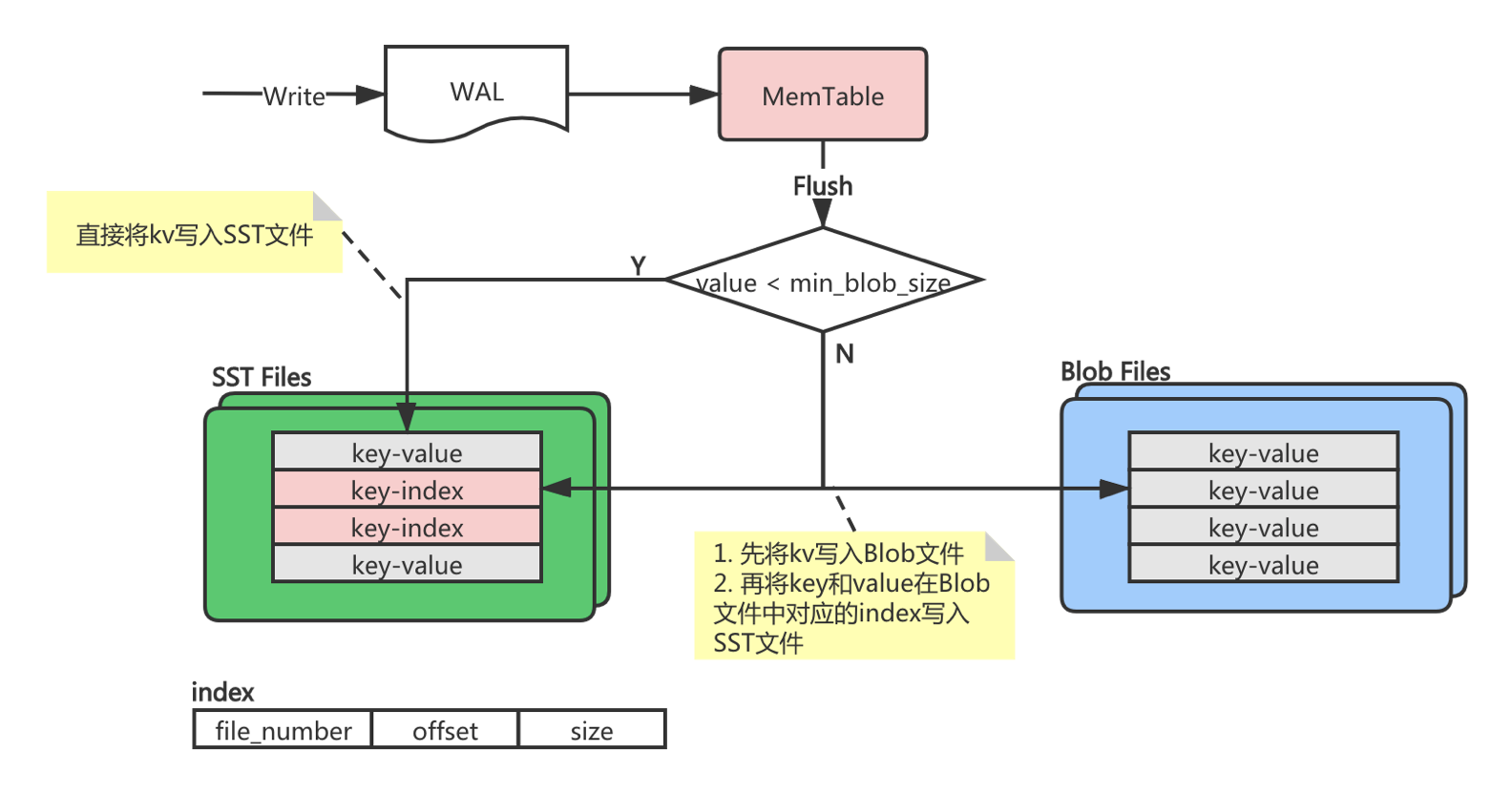
KV 分离存储后,LSM-tree 的体积会非常小,因为只存了 key 和索引。每次 compact 只需要重写 key 和索引,索引长度是固定的,key 一般来说也都比较小,这样重写的数据量就会大大降低。
但是,KV 分离存储需要解决另外一个问题,就是如何清理 blob 文件中的垃圾数据。sst 文件通过 compact 机制清理,那么 blob 文件也需要有自己的 GC 机制。我们当时参考了 Tikv 的存储引擎 Titan 的设计思路,在 compact 时候触发 blob 的 GC。但在线上环境测试中,我们发现还是存在很多问题:
GC 速度很慢,导致数据量持续上涨。GC 任务依赖 compact 触发,并且当有 GC 任务正在执行时,其它的 compact 触发的 GC 事件都会被丢弃。这就导致 compact 了很多次,但 GC 任务却只执行了一次。我们给出的优化方案是添加 GC 任务队列,每次 compact 完后,生成一个 GC 任务 push 到 GC 任务队列中。每次 GC 完后,判断队列中是否还有 GC 任务,如果有就继续执行 GC 任务。
GC 时会涉及到很多文件的读写,因此会产生大量的磁盘 IO。在服务请求高峰期时,如果磁盘 IO 负载过高,会造成读写请求的延时。我们的优化方案是采用 RocksDB 自带的限速器,GC 时对磁盘读写进行限速,避免大量磁盘 IO 对在线请求造成影响。
快慢命令分离
为什么要做快慢命令分离?
我们发现线上很多执行本应该很快的命令也会经常超时,原因是早期的 Pika 线程模型是通过 Dispatch 线程分发客户端连接请求给 worker 线程,然后 worker 线程负责同步处理命令请求。这就带来两个问题:
1. 如果一个客户端的命令阻塞,那么这个 worker 线程上所有客户端发起的命令都会被阻塞。
2. worker 线程负载不均衡。假如有多个客户端,但只有一个大流量的客户端发送命令,那么底层也只有一个 worker 线程处于高负载状态,其它 worker 线程则都处于低负载状态,发挥不了 Pika 多线程的优势。
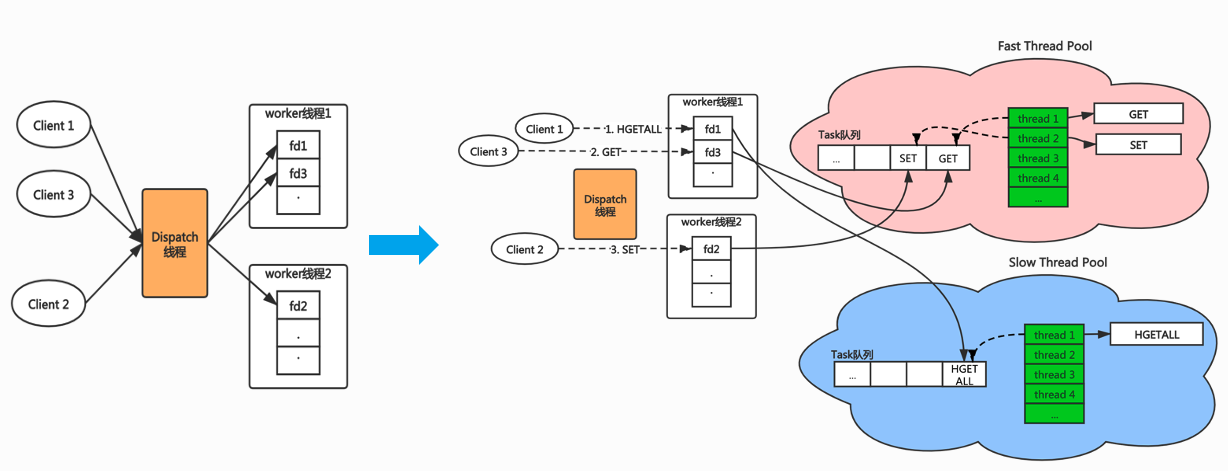
针对上述问题,其实大家很容易想到使用线程池模型,但光线程池模型也不能完全解决问题。举个例子,假如有一个客户端执行的都是比较耗时的命令(如 HGETALL),这时候线程池中的线程还是全都会被耗时的命令阻塞,那么那些执行快的命令也会被阻塞。所以,我们想到的解决方案是采用快慢双线程池模型。
如何做快慢命令分离
如下图,创建两个线程池,快慢命令根据不同业务场景可灵活配置,假设一个用户执行的都是 get/set 比较快的命令,另一个用户执行的都是类似 hgetall 很慢的命令,那么两个命令会分发到不同的线程执行,即使 hgetlall 命令导致执行的线程池阻塞,也完全不会影响 get/set 命令的响应时间。这样就降低了快慢命令之间的互相影响。
集群秒级扩容
有状态的服务扩容往往都伴随着数据迁移,而数据迁移往往又比较耗时。我们线上的 Pika 实例数据少则几十 GB,多则五六百 GB,扩容迁移数据的时间成本非常高。我们线上遇到过集群负载过高、业务超时严重的问题,由于集群本身数据量非常大,无法做到快速扩容,导致业务长时间无法恢复,只能降级。
针对上述问题,我们想到了一个秒级扩容的解决方案。线上的集群分片都是主从两个实例,当集群从 2 个分片扩到 4 个分片时,直接将 group-1 的 slave 实例转移到 group-3,group-2 的 slave 实例转移到 group-4,然后修改 proxy 的 slot 路由信息,中间不需要迁移任何数据,这样就做到了集群的秒级扩容,如下图:
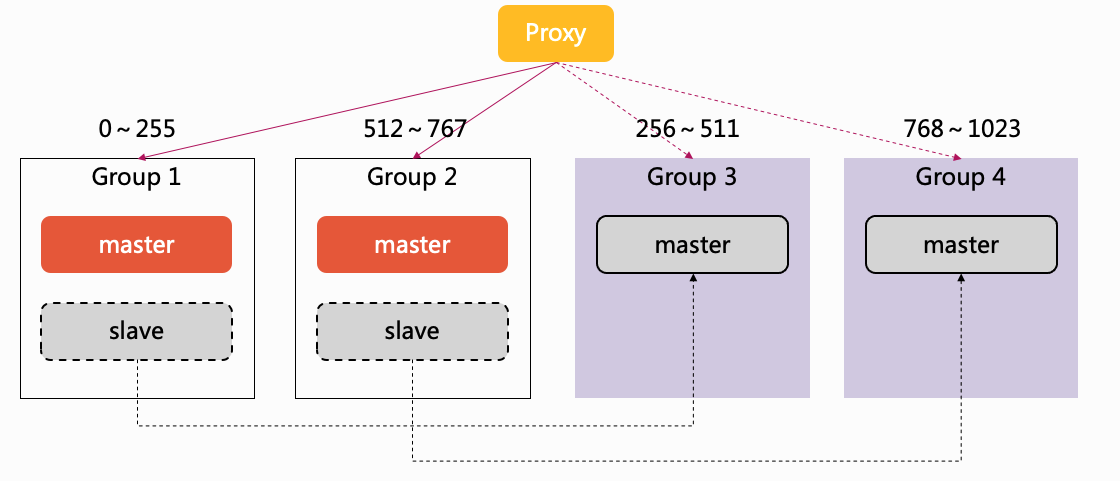
这种扩容方案是很快,但也有缺点,就是扩容后,所有分片都只有一个实例,存在单点的风险,这个需要根据实际场景做权衡。比起服务完全不可用,这种扩容方案在紧急情况下还是可以救命的。
EHash 数据类型
我们有很多在线业务都有个需求就是 hash 结构的 field 可以设置过期时间。Pika 默认只有 key 可以设置过期时间,那么如何让 filed 也支持设置过期时间呢?我们新增了一种 ehash 数据类型。
我们设计的整体思路是 hash 对应的每条 field 记录中加入过期时间,每次获取到 field 后先判断是否已经过期,如果已经过期则删除该记录并返回空,如果没有过期则返回 field 对应的 value;删除过期 field 时间时需要将删除操作写入 binlog,并传递到 slave。下面可以先看下数据结构的存储设计。
原有的 hash 结构在 pika 中的存储方式
每个 hash 表的 meta_key 和 meta_value 的落盘方式:

hash 表中 data_key 和 data_value 的落盘方式:

支持 field 过期 Hash 结构的存储
每个 hash 表的 meta_key 和 meta_value 的落盘方式不变:
hash 表中 data_key 和 data_value 的落盘方式,在原有的 data_value 前增加过期时间的一个时间戳字段:

这种结构需要注意的一点就是,HLEN 命令可能会不精准,因为 HLEN 命令直接读的 meta_key 中 size,此时有的 field 可能已经过期了,但 meta_key 中的 size 并没有被及时更新。如果要统计出精准的 HLEN 数量,就只能扫描 hash 下所有的 filed,性能会比较差。
大 key 大请求检测熔断
大 key 大请求一直都是导致线上故障的一个顽疾,虽然我们制定了很多缓存使用规范,但还是无法完全避免线上出现大 key 大请求的情况。针对这种问题,我们的解决方案就是监测+熔断机制。
在 proxy 层,我们做了大 key 大请求的检测,在业务请求命令时检测是否存在大 key 大请求,如 string 数据类型,业务 set 或 get 的 value 大于 monitor_max_value_len 则判定为大 key;如 list 数据类型,业务 push 元素后会返回 list 的长度,如果大于 monitor_max_batchsize 也判定为大 key;还有像 range 查询范围大于 1000,hgetall 查全量的命令则判定为大请求。
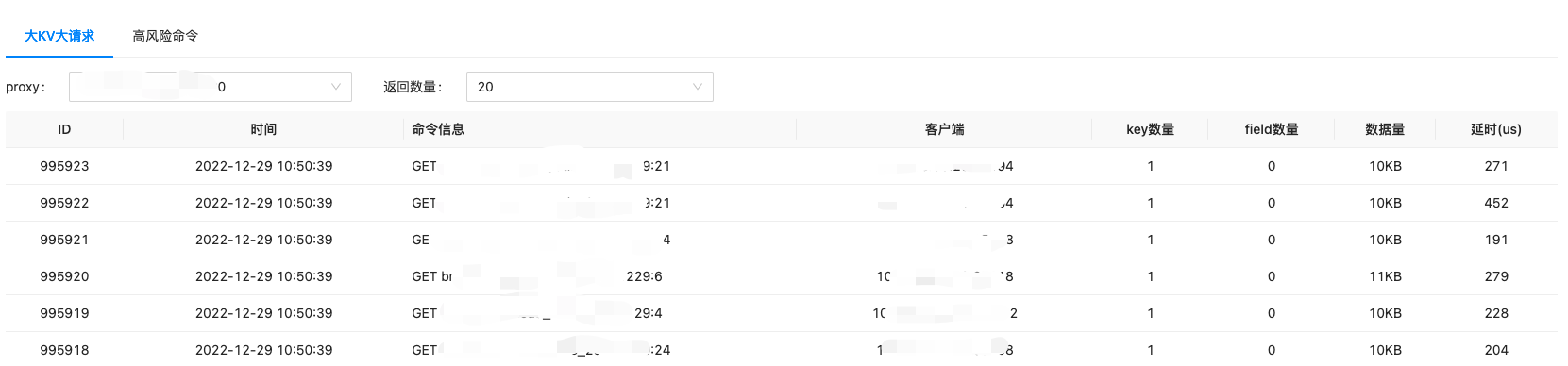
当检测到大 key 大请求后,我们支持配置不同的熔断策略。比如按 key 熔断,比如,只因为某个大 key 拖慢了集群,那么可以将这个 key 添加到黑名单中,后续对该 key 的访问都会直接返回错误。我们还支持按命令熔断,比如 hgetall 查全量数据的命令。另外,我们还支持设定熔断比例,比如熔断比例设定为 50%,那么业务请求的命令只有一半会被拒绝,这样可以保证集群尽可能在不挂的情况下响应业务请求。

同城多活
随着喜马拉雅的高速发展,我们的业务已经扩大到单个数据中心撑不住、主要机房已经不能再加机器,但业务却不断要求加扩容。所以,我们需要一个方案能够把服务器部署到多个机房。
另外,还有一个更重要的原因是,整个机房级别的故障时有发生,每次都会带来严重的后果。因此,我们需要在发生故障时,能够把一个机房的业务全部迁移到别的机房,保证服务可用。整体架构如下图:
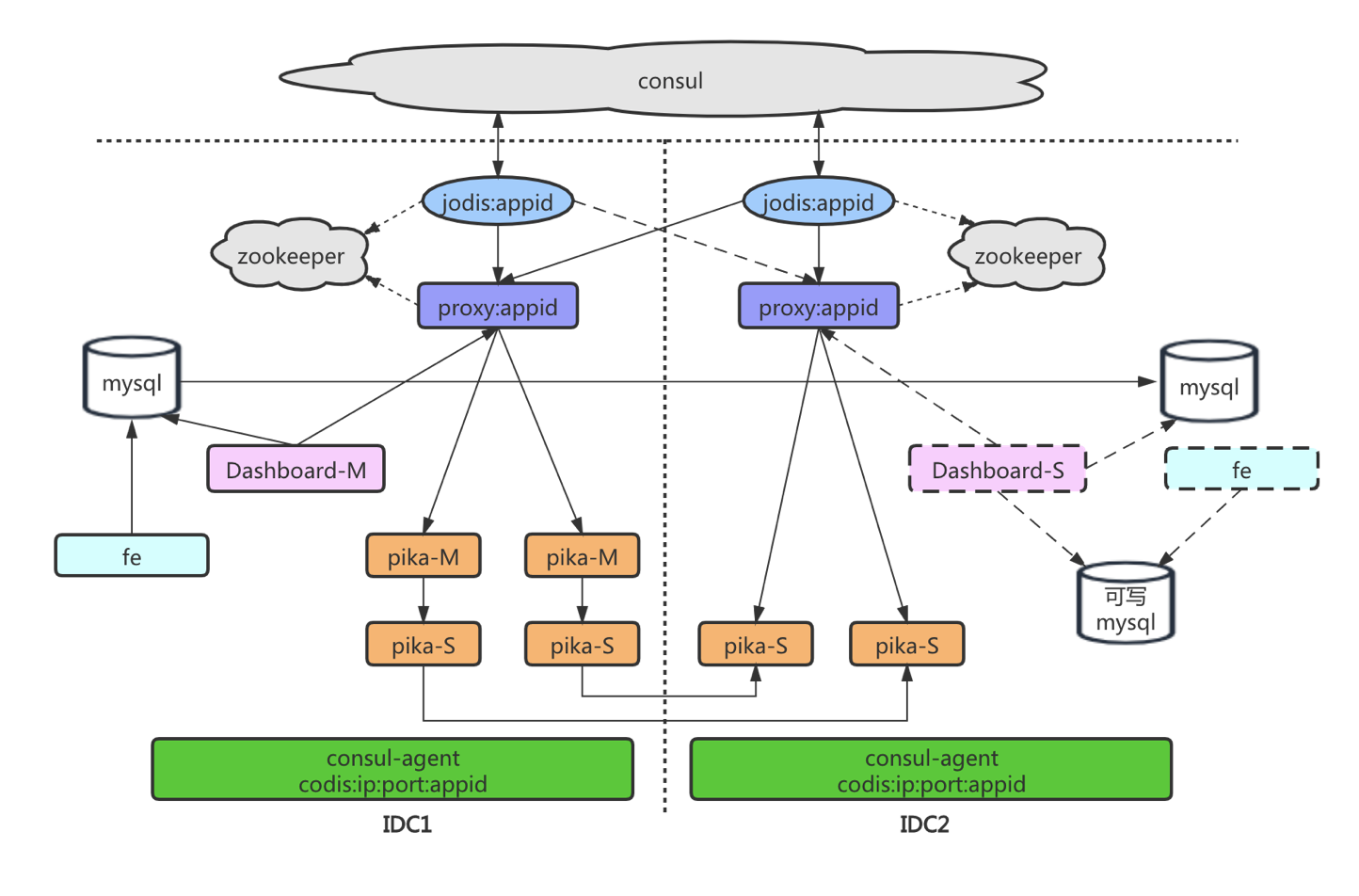
主机房故障切换到备机房流程:
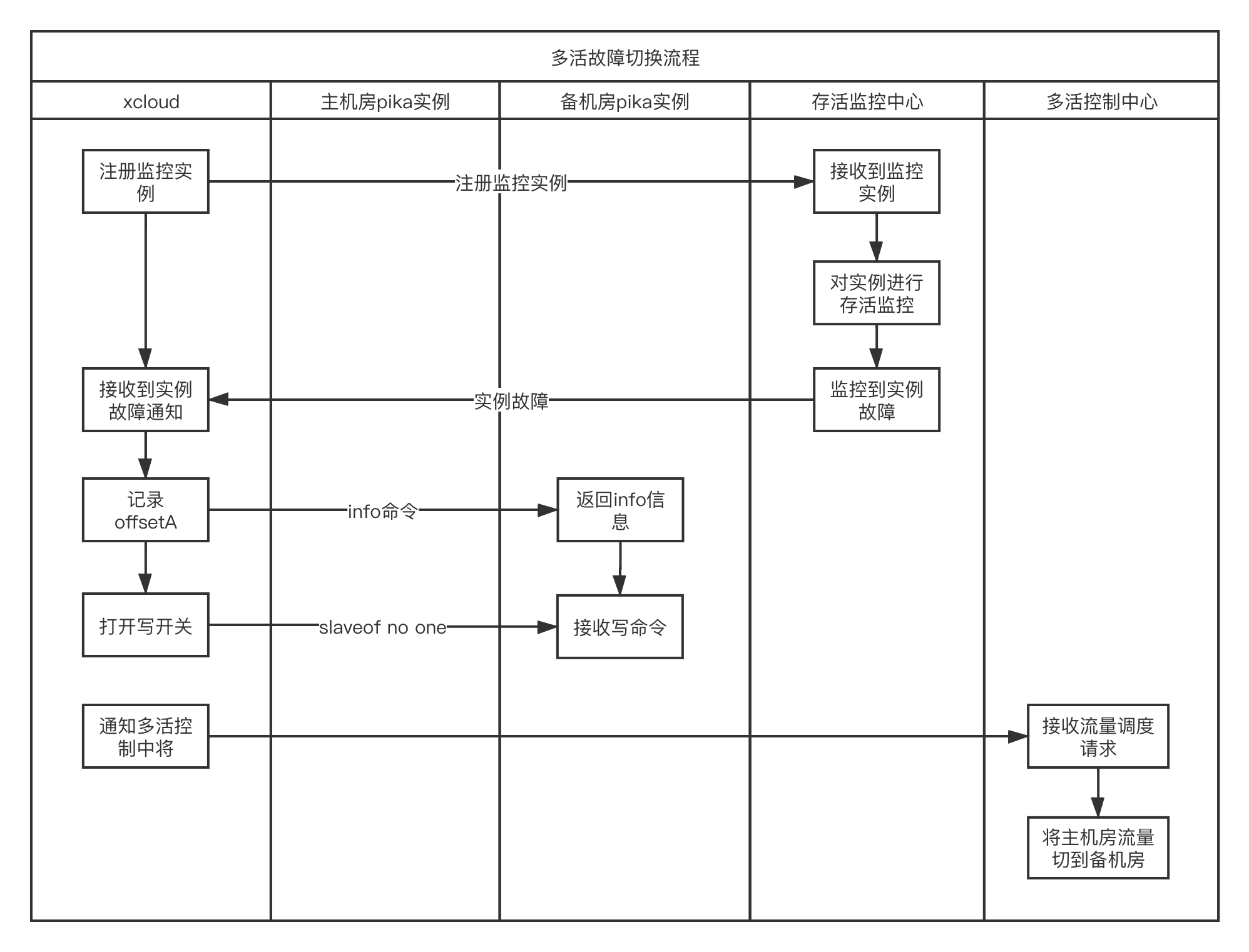
我们的架构方案只实现了多活的双读模式,就是主备机房都有读流量,写流量只在主机房,故障时流量切换到备机房也是只保证读流量不受影响,未来我们计划做到同城多活的双写模式。
除了上述讲到的一些特性,XCache 还做了很多定制优化,包括性能提升、运维效率提升及高可保障等多个方面,这里就不一一列举了。目前 XCache 已经在喜马拉雅线上大规模使用,实例数量 2500+,数据量 120TB+,承载了每天千亿级的业务请求量。
未来发展规划
XCache 的未来发展规划主要有以下几个方向:
1. 功能增强。XCache 目前还有很多来自业务方以及我们自身的需求,如 Lua 和事务的支持、数据强一致性、多租户、bulk load 离线数据导入、multi get 性能优化、热点 key 检测、静态数据分析等等。
2. 云原生化。随着公司的发展,集群的数量也在持续增长,如果全部依赖人工调度,运维工作也会变得异常繁重。所以我们也想利用云上的弹性调度能力,做到集群的自动化部署,弹性扩缩容。
3. 支持智能化运维。谷歌 SRE 里有句话我非常认同,就是任何需要人工操作的事情都只会延长恢复时长。所以我们希望未来的运维是以数据驱动,并能根据机器学习和专家经验来自我作出决策,最后根据决策来自动进行任务编排,执行决策。另外,随着 ChatGPT 的大火,我们也在思考如何将 AI 与缓存的发展相结合。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 4 条评论