

导读:本文来自“深度推荐系统”专栏,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文将结合作者在工作中的经验总结,着重于串讲推荐召回层的模型变化。
推荐系统的基本架构并不复杂,一般由索引、召回、粗排、精排以及展控几个部分构成。而其中的召回模块(也叫 Matching、触发等)则主要负责根据用户和内容特征,从众多的内容库中找到用户可能感兴趣的内容。一般而言召回模型是多路并发存在的,各路召回模型之间互不影响。本文将重点技术在深度学习技术的驱动下,召回模型的几大类模型。
Youtube DNN 召回
但凡 Google 工业界出品,必属精品。这篇论文也不例外,自从 2016 年提出以来备受万众瞩目甚至被奉为推荐领域集算法模型与工业实践神级大作。虽然在深度学习已经成为工业界常规操作的今天回头来看这篇论文的算法架构并不觉得有特别惊艳的地方,但是仍然是工业界效果上当之无愧的主流算法与强有力的 baseline。
原始论文主要介绍了 Youtube 推荐架构的召回和精排各自相应的深度网络结构两个部分内容,因为本文着重串讲召回模型所以专注于第一部分召回层的部分。自底向上查看如下的网络结构:
特征输入层包含了三部分内容:用户观看过的 video 的 embedding 向量、用户搜索词的 embedding 向量以及用户的地理位置年龄等静态特征;这里的 embedding 向量作者是用 word2vec 类方法预先生成的。
线下模型训练阶段,三层 ReLU 神经网络之后接到 softmax 层,也就是说在这里作者建模为为用户推荐下一个感兴趣视频的多分类问题,输出是在所有候选视频集合上的概率分布。
线上预测阶段,考虑到召回的高性能需求首先通过 userId 找到相应的用户向量,然后使用 KNN 类方法找到相似度最高的 N 条候选结果返回。
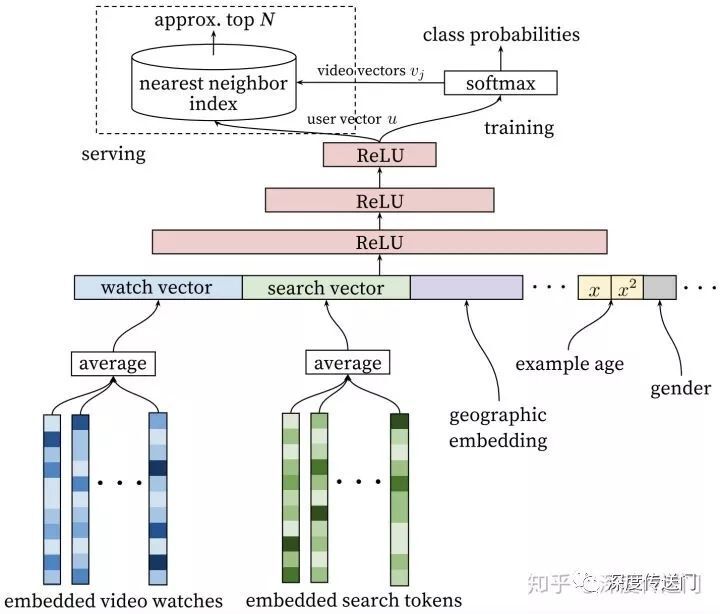
可以看出模型整体的思路可以认为是传统协同过滤思路的扩展。传统的 UCF 强调相似的用户感兴趣的物品也相似;传统的 ICF 强调对物品 A 感兴趣的用户,可能也对物品 A 相似的物品同样感兴趣。所以传统的 UCF 和 ICF 实际上是分别构造了用户向量空间和物品向量空间,在任何一个向量空间找到相似性都可以进行推荐。
而 YoutubeDNN 则学习统一的(用户、物品)向量空间来代替原来的两个独立的向量空间,使用深度网络将用户、物品映射到这个统一的低维向量空间来发现学习更高阶的用户物品相似性。
DSSM 语义召回
DSSM 模型是微软 2013 年发表的一个关于 query/ doc 的相似度计算模型,后来发展成为一种所谓”双塔“的框架广泛应用于广告、推荐等领域的召回和排序问题中。依然我们自底向上来看一下如下的网络结构:
首先特征输入层将 Query 和 Doc(one-hot 编码)转化为 embedding 向量,原论文针对英文输入还提出了一种 word hashing 的特殊 embedding 方法用来降低字典规模。我们在针对中文 embedding 时使用 word2vec 类常规操作即可;
经过 embedding 之后的词向量,接下来是多层 DNN 网络映射得到针对 Query 和 Doc 的 128 维语义特征向量;
最后会使用 Query 和 Doc 向量进行余弦相似度计算得到相似度 R,然后进行 softmax 归一化得到最终的指标后验概率 P,训练目标针对点击的正样本拟合 P 为 1,否则拟合 P 为 0;
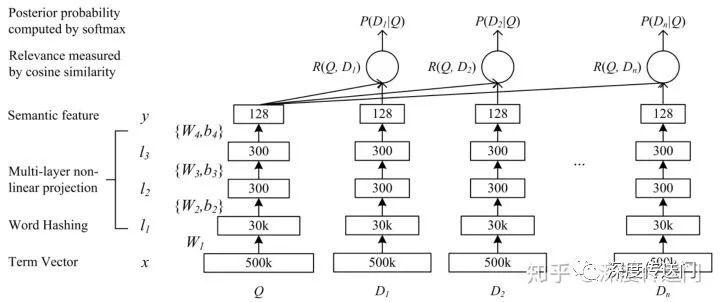
可以看到 DSSM 的核心思想就是将不同对象映射到统一的语义空间中,利用该空间中对象的距离计算相似度。这一思路被广泛应用到了广告、搜索以及推荐的召回和排序等各种工程实践中。
RNN 序列召回
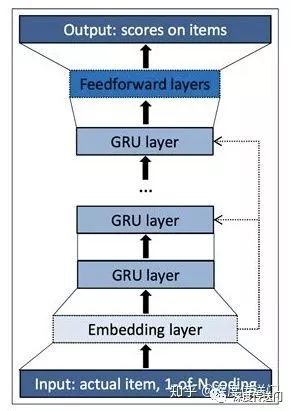
基于用户 session 中的点击序列进行建模召回有很多种方式,其中使用 RNN 深度网络结构来刻画是其中比较有代表性的一种。相应的网络结构其实很简单,如下图所示。使用用户 session 中的点击序列作为模型输入,输出则为用户下次点击的 item 相应的得分。
首先,输入点击序列中的每一个 item 都被 one-hot 编码,然后紧接 embedding 层,再然后是 N 层的 GRU 单元,经过最后一层全连接层得到用户下次点击的 item 相应的概率。详细的 Demo 代码可以参见:github.com/Songweiping/
TDM 深度树匹配召回
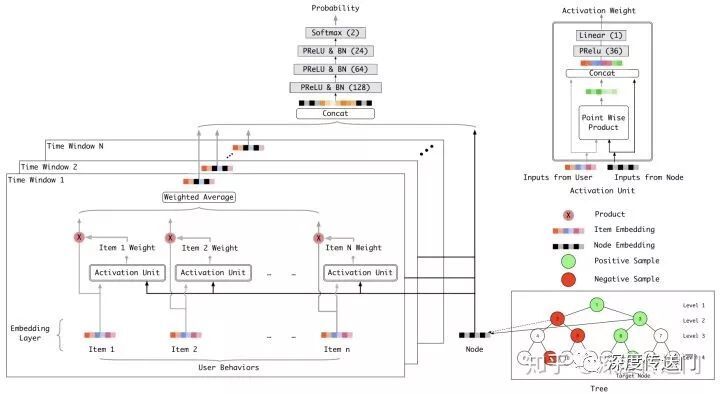
TDM 模型是阿里巴巴于 2018 年提出的新一代深度召回模型,试图通过结合树结构搜索与深度学习模型来解决召回的高性能需求与使用复杂模型进行全局搜索与之间的平衡。它将召回问题转化为层级化分类问题,借助树的层级检索可以将时间复杂度降到对数级。即认为用户对某节点的兴趣是大于等于其叶子节点的,所以只需在每层选出 topk,且在下一层仅计算上一层选出来的节点相应子节点的兴趣,对于规模为 M 的语料库,只需要遍历 2 * k * logM 个分支就可以在完全二叉树中找到 topk 的推荐结果。
这样使用树层级检索的好处就是打分模型可以尽可能的复杂对用户兴趣进行精准建模。论文中使用的深度网络将用户历史行为按时间进行切分,分为多个时间窗口。每个时间窗口内的每一个 item 都与树节点计算关联性权重,得到 attention 分布,然后每个时间窗口内再计算平均权重,接着将多个时间窗口得到的特征拼接起来,通过三层全连接层以及一层 softmax 层得到用户对这个节点感兴趣的概率。
训练过程是首先固定 TDM 树,训练深度网络得到新的节点向量;然后使用新的向量又可以通过聚类等方法重新构建一个 TDM 树;然后再固定 TDM 树重新训练深度网络,如此迭代优化,最终可以得到一个高性能且稳定的模型。
参考文献
Deep Neural Networks for YouTube Recommendations
重读 Youtube 深度学习推荐系统论文,字字珠玑,惊为神文
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
Session-based recommendations with recurrent neural networks
Learning Tree-based Deep Model for Recommender Systems
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/p/63343894

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...












评论