

过去几年,数据库可信生态的构建情况到底如何?标准到底是什么?技术层面取得了哪些进展?这些进展又将如何与产业做结合?各行业在实践层面的最佳方法论到底是什么?如果你希望获取上述问题的答案,欢迎报名参加【2023 可信数据库发展大会】。
在瞬息万变的开源世界中,软件项目来得快、去得也快。如今获得广泛追捧的工具,很可能在短时间后就被更好的成果取代,再也无人问津。但即使在这样残酷的环境下,也有不少项目能够长期保持生命力。
PostgreSQL 数据库系统就是其中的典型,其历史可以追溯到 1986 年的伯克利 POSTGRES 项目。经过几十年的发展,作为一款跨平台、免费和开源的数据库软件,PostgreSQL 应用已经相当广泛:根据 Stack Overflow 2023 开发者调查数据显示,PostgreSQL 甚至超越了 MySQL,成为开发人员首选。
对拥有如此悠久历史的大型代码库做根本性变更绝非易事,但项目开发团队正在认真考虑这种可能性,希望让 PostgreSQL 脱离长久以来的面向进程模型。
任何 PostgreSQL 实例都是以大量协作进程的形式保持运行,其中包含一个用于所有接入客户端的进程。这些进程使用精心设计的库通过多个共享内存区域进行彼此通信,而这个库的作用就是在内存设置各异、映射地址不同的所有进程之间建立起复杂的数据结构。
多年以来,这套模型一直兢兢业业地支撑整个项目。但随着项目发展,现实世界正在发生巨大变化。因此,PostgreSQL 开发团队意识到必须尽快调整、顺应现实的潮流。
一份提案
今年 6 月初,Heikki Linnakangas 在经过一系列线下讨论之后,发布了将 PostgreSQL 转为线程模型的提案。

我觉得现在大家已经达成了强烈共识,比以往任何时候都更支持这项重大调整。实现这个目标需要投入大量精力、讨论很多细节,但团队高层对这个基本思路没有异议。
这封电子邮件的发布,就是想把这种沉默的共识变成明确的发展路线。
其中简要概括了这项迁移所涉及的种种挑战,并低调地承认转化过程“肯定无法通过单一版本彻底完成”。但邮件中没有提到推动这项重大变更的原因,好在随着讨论的进行,相关信息很快得到了补充。正如 Andres Freund(PostgreSQL Developer & Committer,EnterpriseDB 高级数据库架构师)指出的那样:
我认为原有流程模型开始产生诸多限制,这个问题在大型设备上体现得尤其明显。跨进程上下文切换所带来的开销,原本就比在同一进程内的不同线程间切换要更高——我估计这种开销还将持续提升。面对大量连接,整个体系最终一定会因 TLB 未命中而浪费*大量*时间。这是进程模型无法跨进程共享 TLB 的天然属性造成的必然结果。
他还提到,进程模型也增加了开发成本,迫使项目不得不维护大量重复代码,包括在同一地址空间内保留本不必要的多种内存管理机制。在随后的消息中,他还补充称由于线程全部运行在同一地址空间之内,因此可以更高效地实现状态共享。

但有部分开发人员反映,Linnakangas 所说的“强烈共识”可能并没有那么强烈。Postgres 的主要贡献者Tom Lane 表示,“我认为这将是一场灾难,大量原有代码将受到影响。”他随后补充称,此次调整将带来“巨大”成本,产生“不止一个安全级 bug”,也无法证明其收益超过成本投入。有人提出,目前还有其他一些高优先级工作值得早做打算。也有人担心随着进程模型被淘汰,原本基于各独立进程的隔离性将被打破,导致系统的整体健壮性受到破坏。
尽管如此,大部分 PostgreSQL 开发者还是以谨慎乐观的态度支持、至少愿意尝试这一改动。EnterpriseDB 副总裁、首席数据库科学家,PostgreSQL 主要贡献者 Robert Haas 表示,PostgreSQL 在大型系统上的扩展性确实不佳,主要就是因为所有进程都在消耗资源。“其他很多数据库并不存在这个问题。如果不进行某种重大的架构变更,PostgreSQL 将无法克服这个难题。”
也许单纯转向线程模型可能还不够,但他认为这将为其他后续改进开个好头。
从提案到现实
将 PostgreSQL 服务器的核心转移至单一地址空间,几乎必然带来诸多挑战。正如 Haas 等研究人员所指出,其中最大的问题就是服务器“目前正频繁使用全局变量”。具体来讲,当每个服务器进程都拥有自己的集合时,全局变量就能良好运作;而在用线程加以替代时则会引发问题。根据 Konstantin Knizhnik 的说法,PostgreSQL 服务器目前使用约 2000 个全局变量。
开发团队随后讨论了该问题的几种解决思路。首先是将所有全局变量拉入统一的“会话状态”结构,而这套结构具备线程本地化属性。但考虑到需要创建并维护的是需要容纳 2000 个变量成员的复杂结构时,这个提议因为可行性太低而很快失去了吸引力。另一种方法是直接把所有全局变量放入线程本地存储内,这种方法倒是简单可行,但大量使用线程本地存储会导致性能损失,损耗转为线程模型带来的收益。Haas 指出,对全局变量做明确标记(包括将其放入线程本地存储)本身也有积极的意义,可说为减少全局变量的使用开了个好头。Freund 赞同这个观点,并表示即使后续没有全面转向线程模型,这项调整也将有所回报。
但 Freund 也警告称,将全局变量转移至线程本地存储只是这项工作中最简单的部分:
在此之后,重新设计 postmaster、定义如何处理扩展库、扩展兼容性、开发工具以实现线程化 postgres、在会话生命周期内建立新的内存分配和释放机制(以往是通过退出进程实现内存释放)、保证变更的可审查性和可移植性等等,全都是更加困难的工作。
这里还有一个讨论热度不高、但却非常有趣的观点,即 Knizhnik 已经完成了 PostgreSQL 的线程端口。他说全局变量的问题并不是那么难以解决。他在配置数据、错误处理、信号等方面遇到的麻烦还更多。另外,支持由外部维护的扩展也是个重大挑战。可尽管如此,他还是认可转向线程模型所带来的一系列显著回报,只是提醒项目决策层在采取任何行动之前,务必要认真做好研究分析。
PostgreSQL 开发团队还想到了另一个复杂问题,即是否可能同时支持基于进程和基于线程两种模式。在继续支持进程模式的同时引入线程架构不仅极为困难,而且会显著增加项目的总体维护负担。但 Haas 坚持认为,PostgreSQL 绝对不可能彻底放弃对进程模式的支持。毕竟线程在一部分用例中的性能反而更差,也有不少重要扩展无法在线程模式下正常运行。他强调称,只有在确认线程架构运行良好之后,才可能认真讨论要不要彻底放弃进程支持。
目前无论是从邮件讨论还是从社交媒体平台投票结果来看,大多数 PostgreSQL 开发者认同架构转换的理论收益。
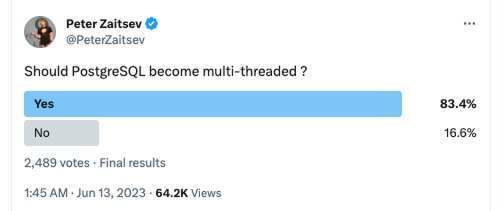
并且,数据库管理系统 Peloton 早在 2015 年就已经尝试让 PostgreSQL 多线程化了。至于 PostgreSQL 本身,从讨论到具体实施落地还有很长的路要走,更重要的是,需要有人主动请缨、表示愿意投入时间来推进这项工作。
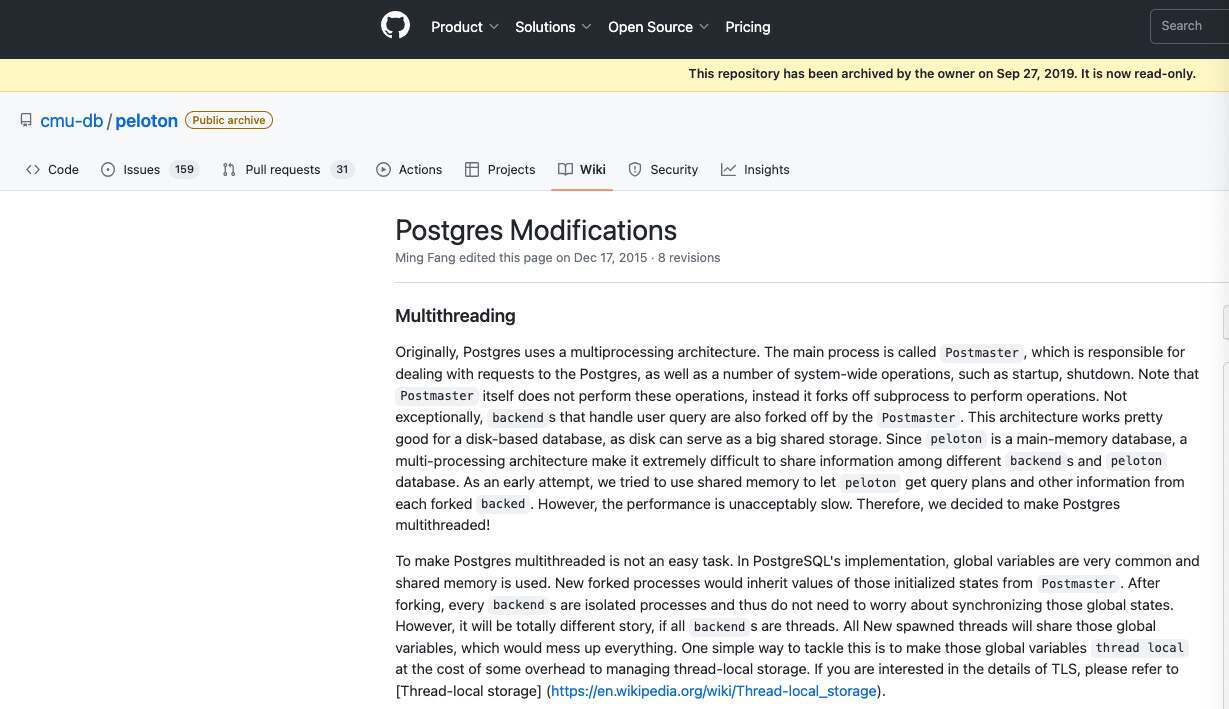
Peloton 的《Postgres 架构变更公告》:
最初,Postgres 采用的是多进程架构。其中主进程名为 Postmaster,负责处理 Postgres 接收到的请求,以及启动、关闭等系统层面的操作。请注意,Postmaster 本身并不执行这些操作,而会派生出子进程来执行操作。再有,处理用户查询的 backend 也是由 Postmaster 分叉而来。这种架构非常适合基于磁盘的数据库,因为磁盘可以作为大容量共享存储。由于 peloton 充当主内存数据库,多进程架构导致不同后端和 peloton 数据库间的信息共享变得极其困难。在早期的尝试中,我们曾考虑用共享内存让 peloton 从每个分叉的 backend 处获取查询计划和其他信息。但结果证明其性能慢得令人无法接受,因此我们最终决定将 Postgres 转为多线程架构!
参考链接:
https://news.ycombinator.com/item?id=36393030
https://lwn.net/SubscriberLink/934940/3abb2d4086680b78/
https://github.com/cmu-db/peloton/wiki/Postgres-Modifications
相关阅读:
PostgreSQL 2022 调查结果发布:全球排名第四的背后是开源的力量

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论