文 | 吕亚霖、莫仁鹏、郑颖
背 景
在传统的单体架构应用中,由于系统规模相对较小,服务调用链路简单,追踪系统的建设和使用相对容易。但随着微服务架构的流行,服务之间的交互和调用复杂度急剧增加。此时,传统的追踪系统已无法满足对多服务、跨系统的全链路追踪需求,因此需要引入分布式追踪系统。
分布式追踪系统可以帮助实现对全链路的完整追踪和监控,跟踪服务之间的调用关系和数据流动,帮助发现潜在问题和优化性能。同时也可以帮助快速定位跨服务的调用问题,缩短故障排查时间,提高系统可用性。
作业帮的分布式追踪系统与云原生建设相伴相生,支撑着全公司的云原生微服务体系,一套优秀的分布式追踪系统应当满足以下几点要求:
低开销:追踪系统对运行服务的影响需要微乎其微,在一些高性能要求的服务中,即使是很小的监控开销也会对服务产生额外的性能负担,并且可能迫使部署团队关闭追踪系统。
应用透明:应用的开发者不需要关注追踪系统,尽量以非侵入或最小侵入的方式去进行追踪。
可扩展性:随着企业发展业务规模也在不断扩大,这要求追踪系统能够随着集群规模的增长,支持快速横向扩展。
低延迟:追踪数据产生后可以快速导出数据进行分析, 在最短时间内定位系统异常。
成本优势:能够以较小的机器预算支撑起全公司大规模追踪数据的处理与存储落地,且性能表现良好。
作业帮追踪体系现状
目前作业帮线上有数万个活跃服务,调用链路错综复杂,在业务高峰期,每秒产生的追踪跨度 (spans) 数据量超过 1000 万,平均每天新增的追踪数据写入量达到 20TB,并随着业务规模的不断扩大持续增长。
这种数据规模给追踪系统建设带来了巨大的挑战,需要追踪系统必须具备强大的数据实时处理能力,从采集到可检索的延迟需控制在分钟级以内,以保障故障排查的时效性;同时也需要对成本和收益进行权衡,将成本控制在合理范围内。
为应对以上挑战,作业帮选择基于 Jaeger 构建分布式追踪系统,采用以下技术方案:
Jaeger:作为追踪体系的核心组件,其多语言支持特性能够完美适配作业帮混合技术栈,且与云原生技术栈深度集成,易于部署管理、按需扩展。
Kafka:充当数据缓冲中枢,利用 Kafka 强大的吞吐能力,确保数据在高峰期间不丢不漏。
ClickHouse:作为一种高性能的列式数据库,其灵活的的索引和分区策略,使其非常适宜作为作业帮大规模追踪数据的存储,能够为追踪系统提供高效、可靠的数据存储和查询能力。
Prometheus:用于存储和分析链路及拓扑数据,Prometheus 强大的监控能力结合智能告警机制,能够实现系统异常分钟级感知。
目前该体系已稳定运行超过 2 年,并成功支持多次业务大促活动。在保障系统稳定性的同时,我们也在探索追踪数据与 AIops 的结合应用,在根因分析(故障传播链挖掘)、异常预测(多维指标关联预警)等场景实现智能化突破。
作业帮追踪系统实践
作业帮的追踪系统是伴随其云原生架构的发展而逐步建立完善的,属于服务治理体系的一个重要组成部分。截至目前,作业帮已有 97%+ 的服务完成了容器化改造,统一采用了基础架构提供的服务网格及各种基础组件。此外,主流开发语言均已成功接入公司内部的应用框架,确保了底层技术栈的高度一致性和标准化。这种统一的底层架构设计,不仅促进了内部资源的有效整合,更为构建企业级的分布式链路追踪系统奠定了坚实的基础。
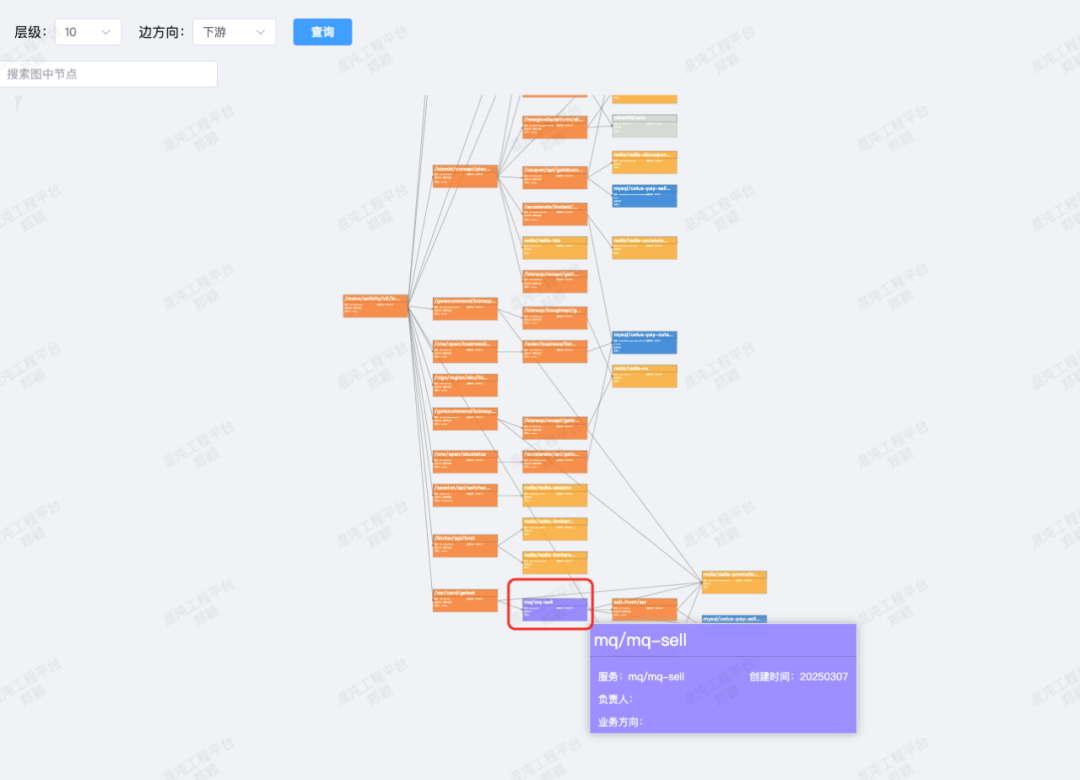
得益于基建能力的建设,作业帮建成了如下所示的分布式追踪系统,并作为一项关键的基础观测能力提供出来,从架构层面支持了对服务间通信和基础服务访问进行追踪,能够实现实时监控与深度分析系统的运行状态及性能指标,为作业帮的技术运维提供了强有力的支持,同时也为优化用户体验、提升服务质量创造了条件。
业务无感接入
作业帮的追踪系统依托于其他云原生基建能力:统一的服务网格和服务框架,采用边车 + 日志 + 服务的采集模式构建,业务无需关心具体实现即可自动接入使用。
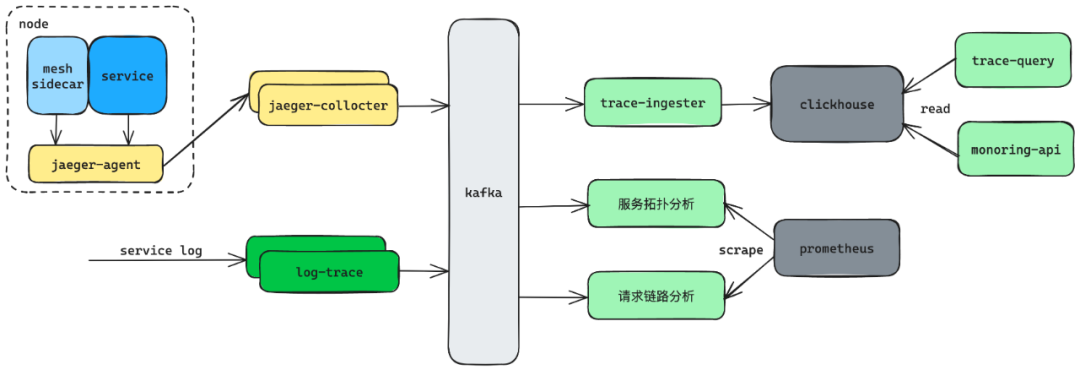
基于 MESH 的追踪(MESHTracing)
mesh 边车会对服务的所有出入流量做追踪打点, 这部分对服务是完全无感的。追踪数据上报到本机上的 jaeger-agent 服务上, 之后再批量传输到 jaeger-collctor 服务上,jaeger-collctor 服务负责统一将追踪数据写到 Kafka 中。另外我们最新版本的 mesh 在追踪埋点上的开销几乎可以忽略不计,对服务的性能影响极小。
基于日志的追踪(Log-Based Tracing)
对一些业务小众或者特殊的网络调用, 我们通过约定日志规范的方式做追踪数据采集,如部分服务出流量(服务访问 ck、表存储的流量)、网关的入流量等。log-trace 服务负责做日志的追踪数据采集, 它会从日志 kafka 订阅所有业务日志, 解析后封装成标准的追踪数据直接写入到 kafka 中,这里没有先上报到 jaeger-agent 再由 jaeger-collctor 统一采集,避免了中转开销。
日志采集模式基于底层语言框架同样对服务无感,是作为 MESH 采集模式的补充,当前公司主流的语言框架均已完成支持。
基于服务的追踪(Service-Based Tracing)
以上的两类采集方式专注于对服务边界的观测, 如果服务有对内部的观测需求则通过服务自定义打点的方式上报追踪数据,按需增加追踪深度。服务通过接入追踪 SDK 方式上报追踪数据到本机上的 jaeger-agent 服务上, 再通过 jaeger-collceror=>kafka 的链路完成上报。
存储效率与成本的权衡
作业帮的追踪系统对数据不做采样, 使用全采样的策略。在当研发遇到线上问题时,就可以通过请求 ID 来快速排查整个链路, 快速定位问题。但这会导致追踪数据量极其庞大,作业帮早期使用 ES 作为存储,实践发现 ES 的写入性能不够理想,尤其是在晚高峰的时候总是会出现写入延迟,影响追踪服务的使用。
在综合考虑成本与存储效率后,我们选择使用 ClickHouse 替代 ES 来存储和索引追踪数据,并将数据保留 3 天。由于 Jaeger 官方目前尚未正式支持 ClickHouse 作为存储后端,我们自研的插件实现了这一功能,通过调用原生 ClickHouse 客户端的方式进行写入,新的写入模块单核可以支持 4W/S 的 span 写入速度。
ClickHouse 作为一个列式存储, 相比 ElasticSearch 有以下优势:
更有效的存储利用率: 列式存储相比于行数存储能够实现更高效的压缩,节省存储空间
更好的写入性能: ClickHouse 优化了批量插入操作,这对于大规模数据的高速写入非常有效。另外 ClickHouse 对索引的建立更加灵活, 支持只对部分 tag 做索引, 这也减少了索引的成本
更快的查询速度: ClickHouse 专为高性能查询设计,特别是在处理大规模数据集时,能够在毫秒级内返回复杂的查询结果
更友好的查询方式:ClickHouse 支持标准 SQL 查询,使用起来相比于 DSL 查询会更熟悉,上手成本更低
更低的资源消耗:相比 Elasticsearch,ClickHouse 在相同硬件条件下消耗更少的资源(CPU、内存、磁盘 I/O)
在使用 ClickHouse 后, 带来的收益如下:
CPU 使用下降了 80%, 单核可以支持 1W/S 的 span 写入
磁盘占用下降了 50%, 单个 span 平均只占用 100B 的空间
整体写入性能提升 40%,支持 1000W/S 的 span 写入
平均读取耗时降低, 晚高峰不再有明显的查询延迟现象
追踪赋能业务
作业帮在建设多维观测能力体系过程中,始终围绕着“降低使用门槛、赋能业务决策”两大核心目标,让每一次请求可观测、可诊断、可优化。
更便捷的追踪数据访问方式
我们构建的分布式追踪系统,提供两种方式访问存储的追踪数据:
可视化检索界面:支持用户直接通过界面的方式实时检索链路数据, 支持查看每个请求的耗时, 结果和错误信息, 方便定位链路问题
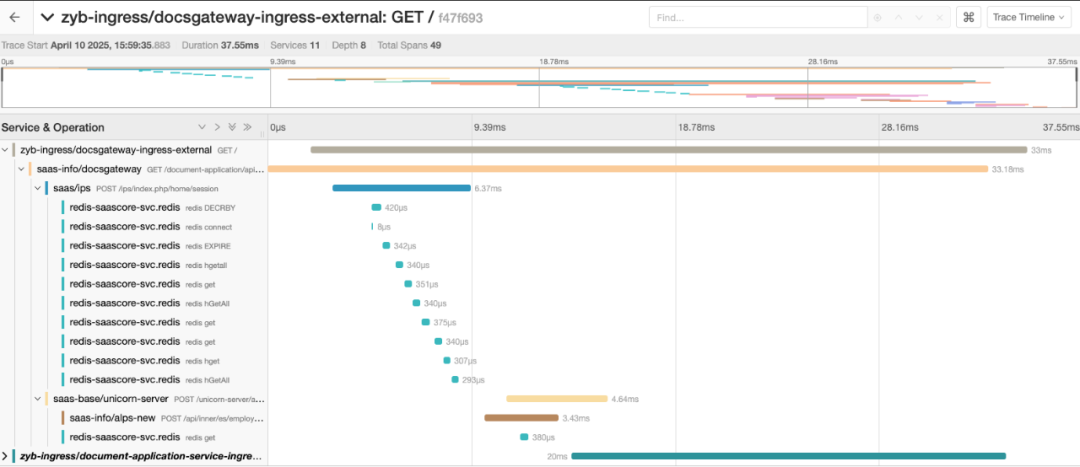
开放数据 API:支持服务通过 API 的方式访问追踪数据, 以满足业务侧自定义的监控和 Debug 需求
更深入的追踪数据价值提炼
单个请求数据或者单条链路数据都是离散的,仅凭追踪数据难以全面了解服务的请求状态。然而,在拥有全量追踪数据后,我们就可以实时消费这些数据,并对其进行聚合统计,从而支持从服务和链路的视角来分析请求链路的整体状态。这些统计和监控数据将被存储到 Prometheus,并通过图表的形式展示给用户,帮助他们直观地理解系统的运行状况。
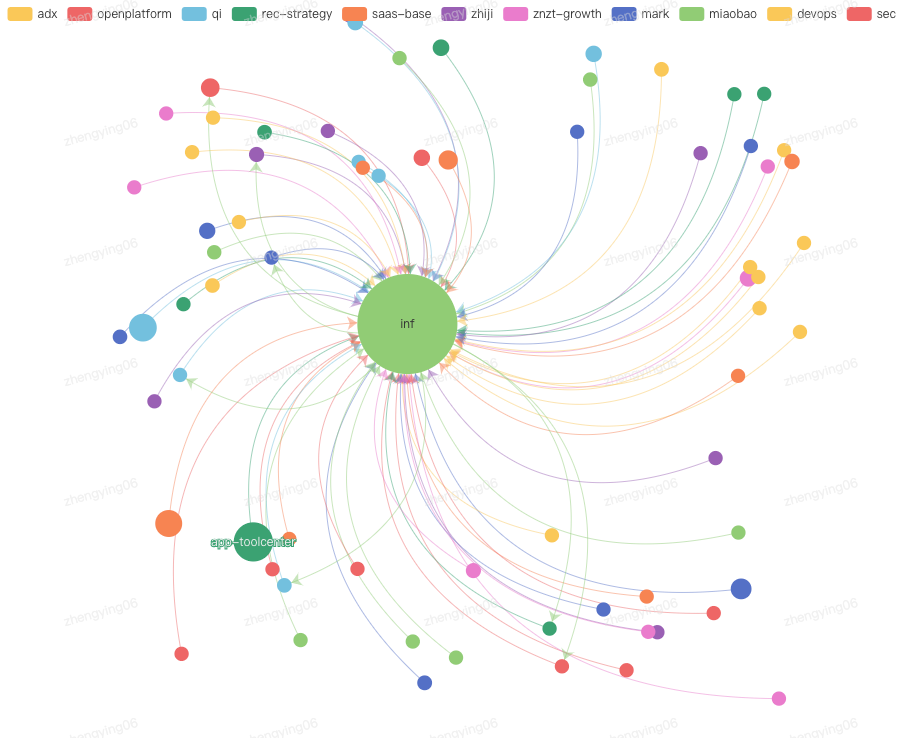
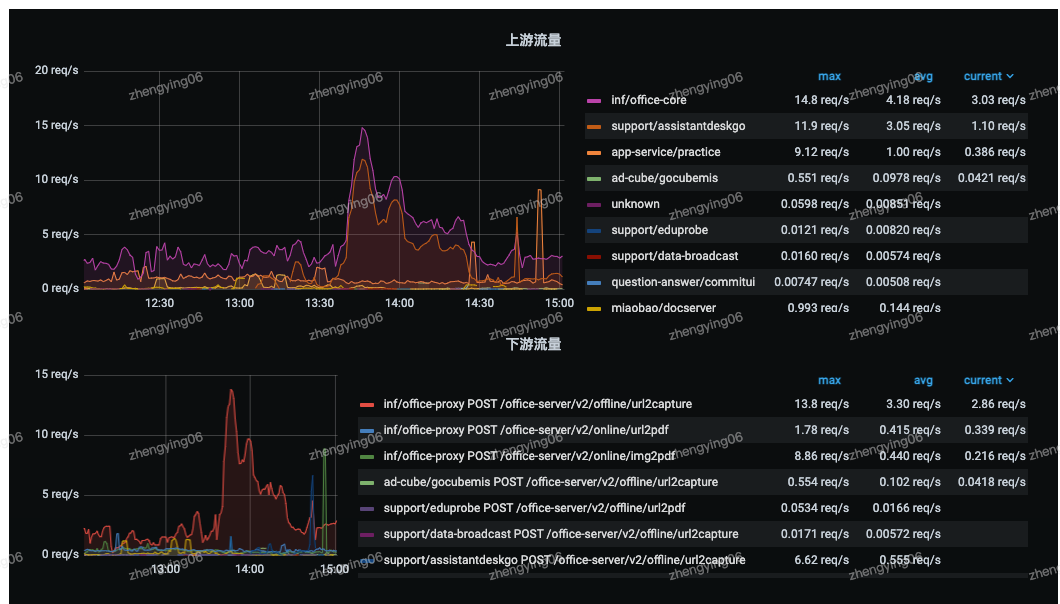
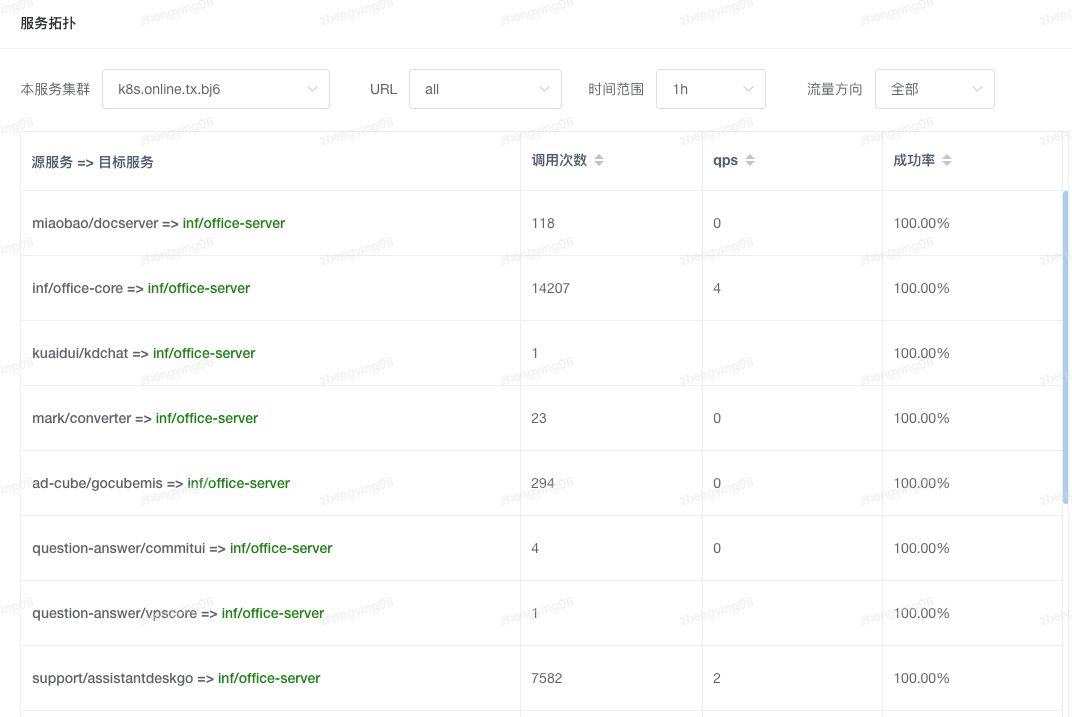
全景服务拓扑
服务拓扑分析支持按服务维度分析其上下游依赖关系。根据请求 URL 展示每个请求的上游来源服务和下游依赖服务,形成服务拓扑图,并按请求次数、成功率和平均耗时等性能指标评估依赖质量。通过拓扑分析可以帮助研发团队全面了解系统各个服务的依赖关系,做好依赖管理,及时发现潜在问题并进行针对性优化,提升系统的稳定性和可靠性。
请求链路分析
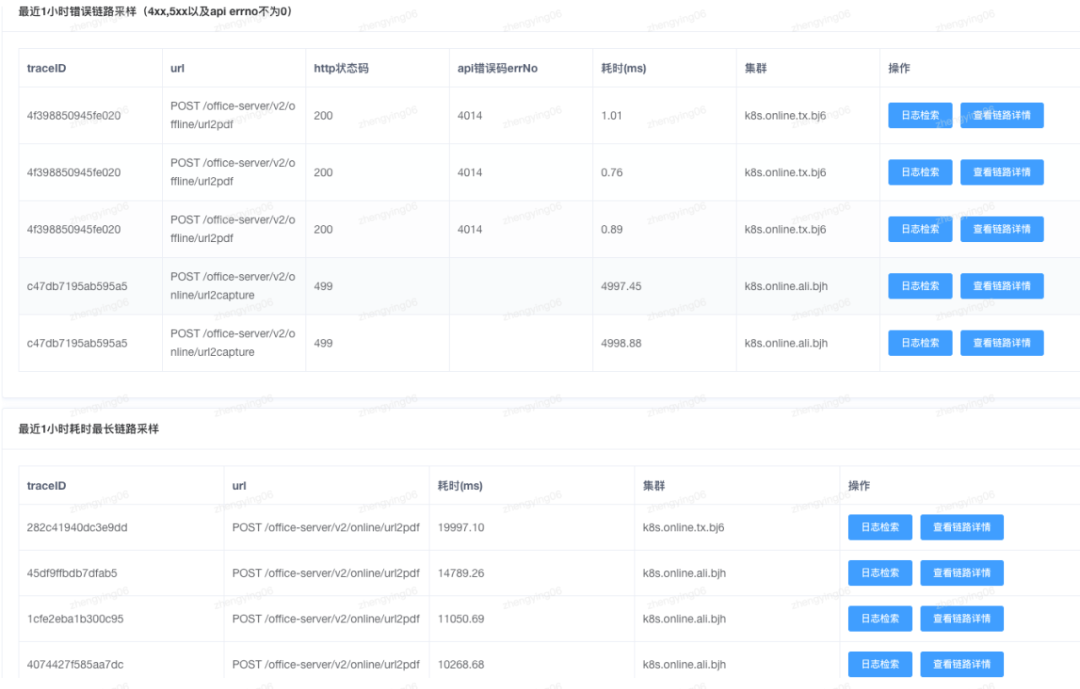
提供服务的错误链路采样和慢链路采样,对服务最近 1h 的错慢链路数据进行统计,并使用根因分析智能生成分析结果,辅助业务快速定位问题。


异步链路串联,当服务间使用 MQ 进行异步通信时,利用 messageID 自动关联异步调用,补足异步调用链路的缺失,实现更全面的追踪。