

在生产中部署深度学习模型可能很有挑战性,因为这远远不仅是训练出具有良好性能的模型就足够了。为了部署生产级深度学习系统,还需要正确设计和开发一众组件。本文介绍了 GitHub 上的一个工程指南,用于构建将部署在实际应用程序中的生产级深度学习系统。
在这篇文章中,我们将详细介绍生产级深度学习系统的各个模块,并推荐适合每个组件的工具集和框架,以及实践者提供的最佳实践。
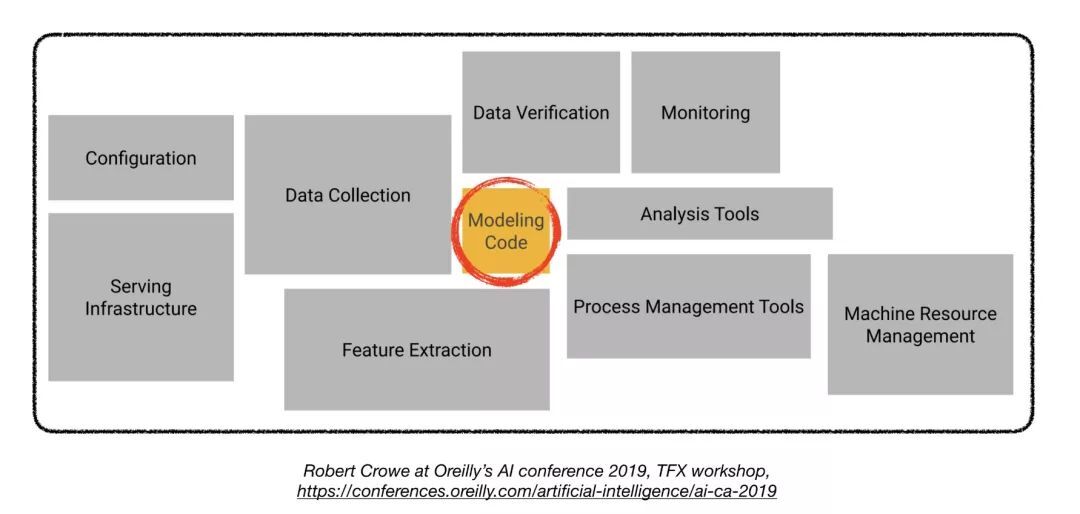
1. 数据管理
1.1. 数据源
开源数据 (好的开端,但并非优势)、数据增强以及合成数据
1.2. 标注
标注的劳动力来源:
众包
服务公司:FigureEight
雇佣标注员
标注平台:
Prodigy:一种由主动学习(active learning)(由 Spacy 开发人员开发)、文本和图像支持的注释工具。
HIVE:用于计算机视觉的人工智能即服务平台。
Supervisely:完整的计算机视觉平台。
Labelbox:计算机视觉。
Scale 人工智能数据平台(计算机视觉和自然语言处理)。
1.3. 存储
数据存储选项:
对象存储:存储二进制数据(图像、声音文件、压缩文本)
Aamzon S3
Ceph 对象存储
数据库:存储元数据(文件路径、标签、用户活动等)。
Postgres 对于大多数应用程序来说都是正确的选择,它提供了同类最佳的 SQL 和对非结构化 JSON 的强大支持。
数据湖:用于聚合无法从数据库获得的特征(例如日志)。
Amazon Redshift
特征存储:机器学习特征的存储和访问。
FEAST(Google 云,开源)
Michelangelo(Uber)
在训练期间:将数据复制到本地或集群文件系统中。
1.4. 版本控制
DVC:用于机器学习项目的开源版本控制系统
Pachyderm:用于数据的版本控制
Dolt:用于 SQL 数据库的版本控制
1.5. 处理
生产模型的训练数据可能来自不同的源,包括数据库和对象存储中的存储数据、日志处理和其他分类器的输出。
任务之间存在依赖关系,每个人物都需要在其依赖关系完成后才能启动。例如,对新的日志数据进行训练,需要在训练之前进行预处理。因此,工作流在这方面变得相当重要。
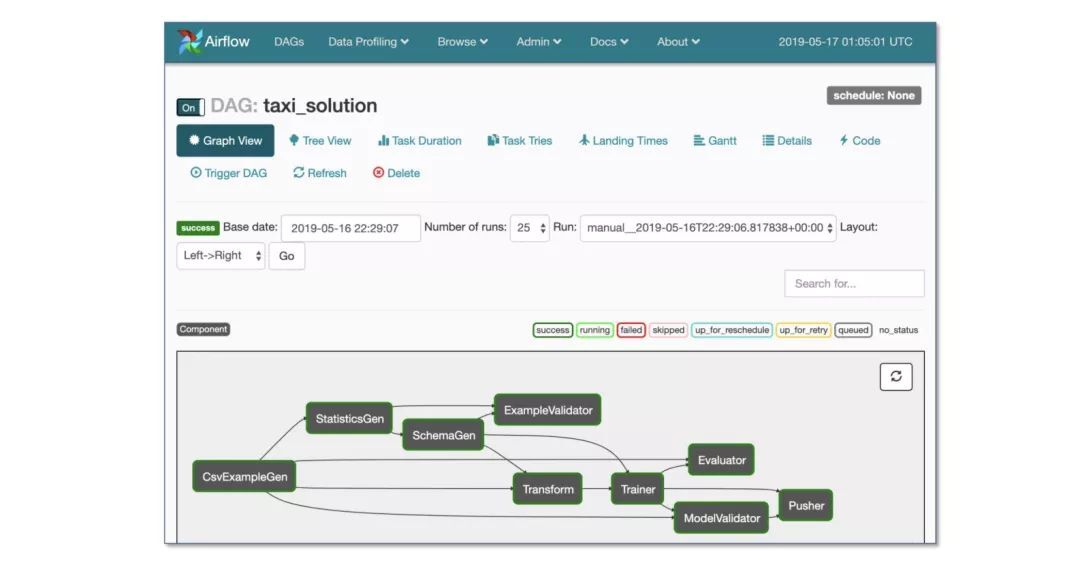
工作流:
Airflow (最常用的)
2. 开发、训练与评估
2.1. 软件工程
编辑器:
Vim
Emacs
VS Code(作者推荐):内置 Git 暂存和显示文件差异、Lint 代码扫描、通过 SSH 远程打开项目。
Jupyter Notebooks:作为项目的起点很好,但它难以实现规模化。
Streamlit:具有小程序的交互式数据科学工具。
建议:
对于个人或初创企业:
开发:一台 4 核图灵架构的计算机。
训练 / 评估:使用相同的 4 核 GPU 计算机。在运行许多实验时,可以购买共享服务器或使用云实例。
对于大型公司:
开发:为每位机器学习科学家购买一台 4 核图灵架构计算机,或者让他们使用 V100 实例。
训练 / 评估:在正确配置和处理故障的情况下使用云实例。
2.2. 资源管理
为程序分配免费资源:
资源管理选项:
旧式集群作业调度程序(如,Slurm 工作负载管理器)
Docker + Kubernetes
Kubeflow
Polyaxon(付费功能)
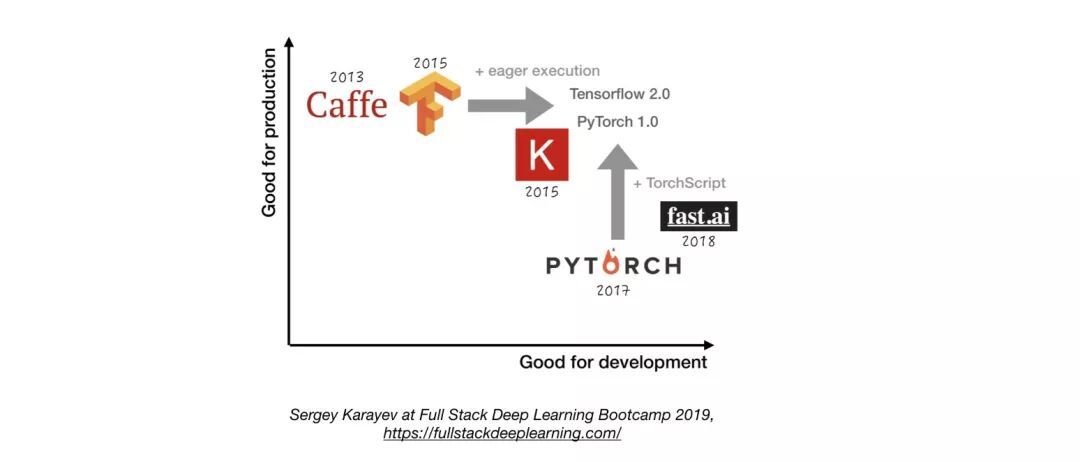
2.3. 深度学习框架
除非有充分的理由不这样做,否则请使用 TensorFlow/Keras 或 PyTorch。下图显示了不同框架在开发和 生产方面的比较。
2.4. 实验管理
开发、训练和评估策略:永远从简单开始。在小批量上训练一个小型模型,只有在它能起作用的情况下,才扩展到更大的数据和模型,并进行超参数调优。
实验管理工具:
Tensorboard:提供了机器学习实验所需的可视化和工具。
Losswise(用于机器学习的监控)
Comet:让你可以跟踪机器学习项目上的代码、实验和结果。
Weights & Biases:通过简单的协作,记录并可视化研究的每个细节。
MLFlow Tracking:用于记录参数、代码版本、指标和输出文件,以及结果的可视化。
2.5. 超参数调优
Hyperas:用于 Keras 的 hyperopt 的简单包装器,使用简单的模板符号定义要调优的超参数范围。SIGOPT:可扩展的企业级优化平台。Ray-Tune:可扩展的分布式模型选择研究平台(专注于深度学习和深度强化学习)。Sweeps from Weights & Biases:参数并非由开发人员显式指定,而是由机器学习模型来近似和学习的。
2.6. 分布式训练
数据并行性:当迭代时间过长就使用它(TensorFlow 和 PyTorch 均支持)。
模型并行性:当模型不适合单 GPU 的情况下就是用它。
其他解决方案:
Ray
Horovod
3. 故障排除『有待完善』
4. 测试与部署
4.1. 测试
与 CI/CD 与传统软件相比,机器学习生产软件需要更多样化的测试套件:
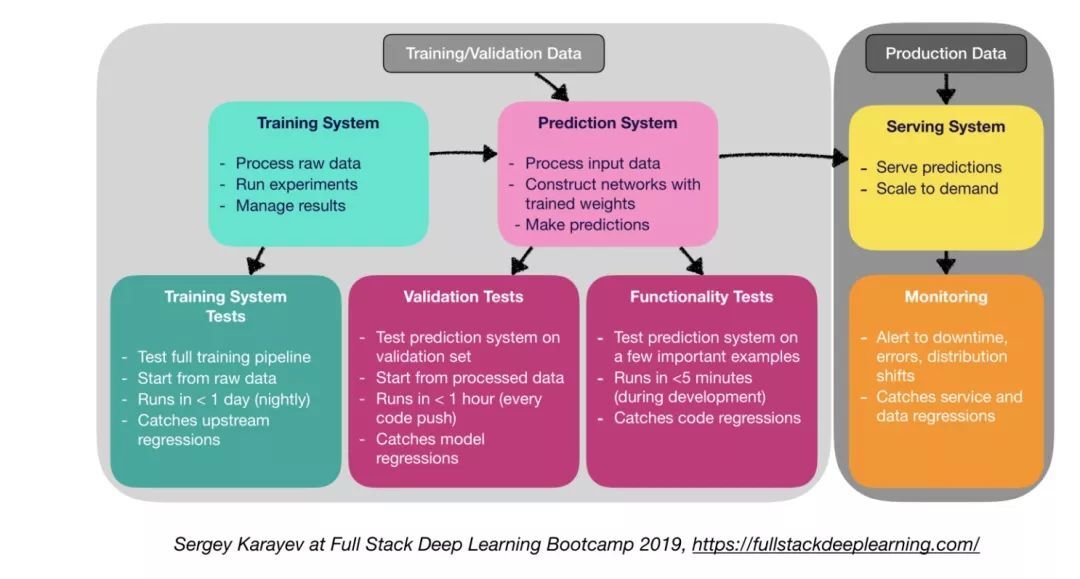
单元测试和集成测试
测试类型:
训练系统测试:测试训练管道。
验证测试:在验证集上测试预测系统。
功能测试。
持续集成:在将每个新代码更改推送到仓库后运行测试。
用于持续集成的 SaaS:
CircleCI、Travis
Jenkins、Buildkite
4.2. 网络部署
由预测系统和服务系统组成:
在考虑规模的情况下为预测服务。
使用 REST API 为预测 HTTP 请求提供服务。
调用预测系统进行响应
预测系统:处理输入数据,进行预测。
服务系统(Web 服务器):
服务选项:
Docker
Kubernetes (现在最流行)
MESOS
Marathon
通过 模型服务 解决方案部署。
将代码部署为“无服务器函数”。
模型服务:
Tensorflow 服务
MXNet Model 服务器
Clipper (Berkeley)
SaaS 解决方案 (Seldon,算法)
专门针对机器学习模型的网络部署。
用于 GPU 推理的批处理请求。
框架:Tensorflow 服务、MXNet Model 服务器、Clipper、SaaS 解决方案 (Seldon,算法)
决策:
TensorFlow 服务或 Clipper
自适应批处理很有用。
如果 CPU 推理满足要求,则更可取。
通过添加更多的服务器或无服务器进行扩展。
CPU 推理:
GPU 推理:
4.3 Service Mesh 和 Traffic Routing
从单片应用程序过渡到分布式微服务体系结构可能具有挑战性。
服务网格(由微服务网络组成)降低了此类部署的复杂性,并减轻了开发团队的压力。
Istio:一种服务网格技术,简化已部署服务网络的创建,而服务中的代码更改很少或没有。
4.4. 监控
目的:
针对停机时间、错误和分发变化的警报。
抓取服务和数据回归。
此外,云提供商的解决方案也是相当不错。

4.5. 在嵌入式和移动设备上部署
主要挑战:内存占用和计算限制
解决方案:
DistillBERT (用于自然语言处理)
MobileNets
量化
缩小模型尺寸
知识蒸馏
嵌入式和移动框架:
Tensorflow Lite
PyTorch Mobile
Core ML
ML Kit
FRITZ
OpenVINO
模型转换:
开放神经网络交换(Open Neural Network Exchange,ONNX):用于深度学习模型的开源格式。
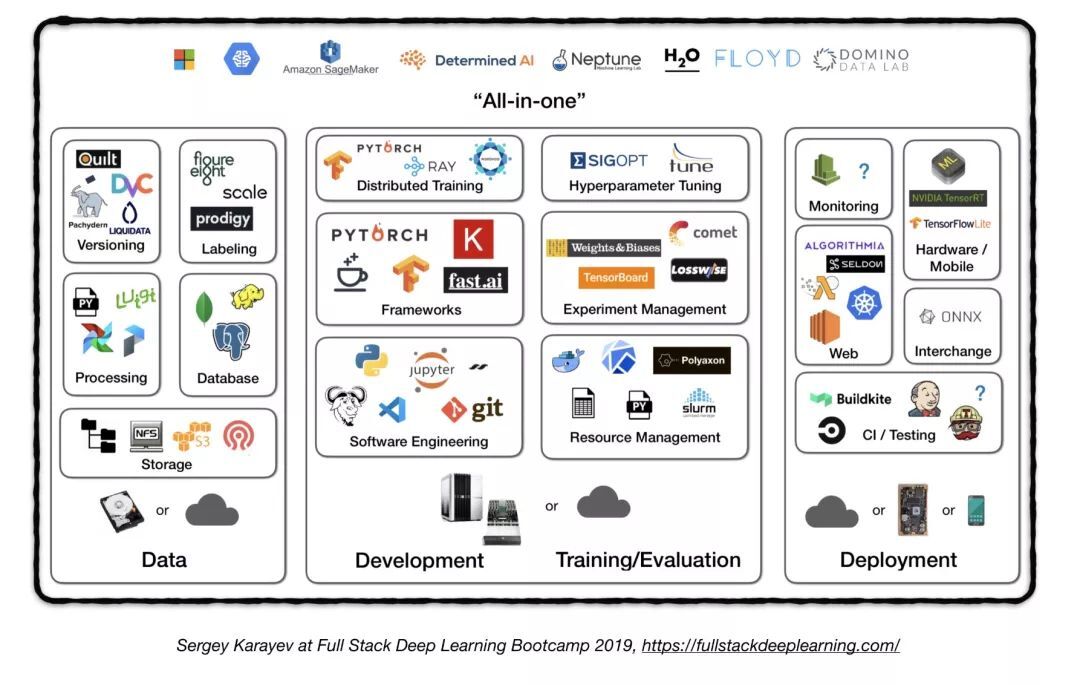
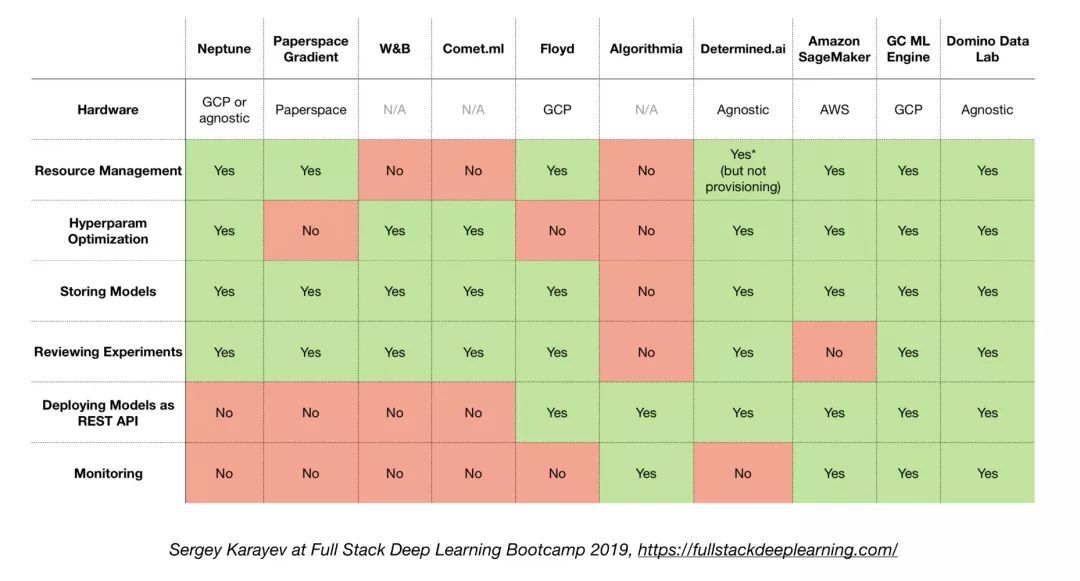
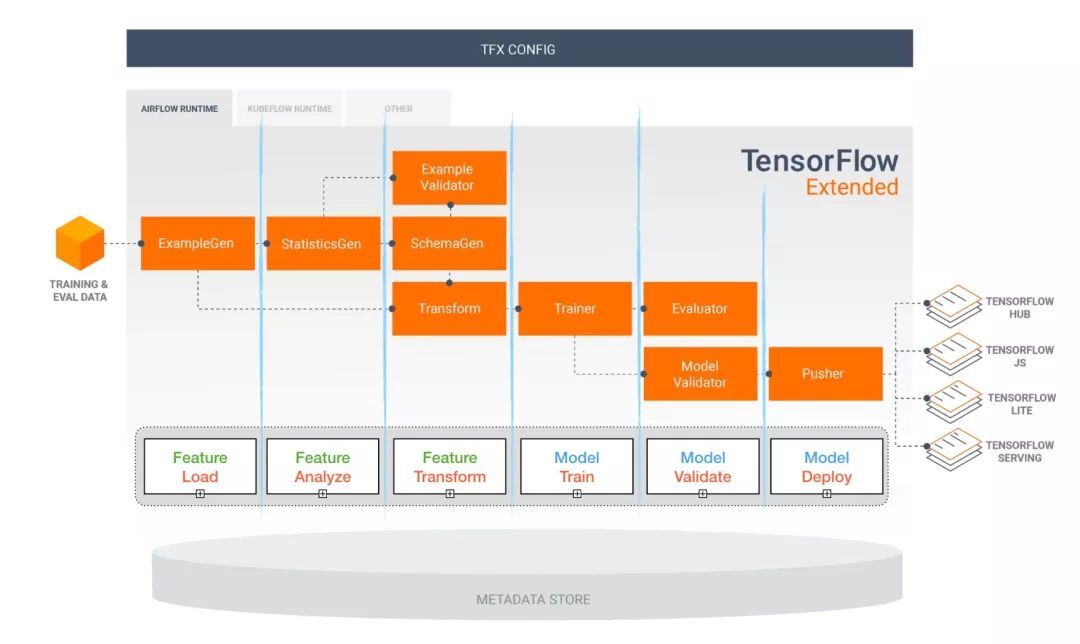
4.6. 一体化解决方案
Tensorflow Extended (TFX)
Michelangelo (Uber)
Google Cloud AI Platform
Amazon SageMaker
Neptune
FLOYD
Paperspace
Determined AI
Domino data lab
Tensorflow Extended (TFX)
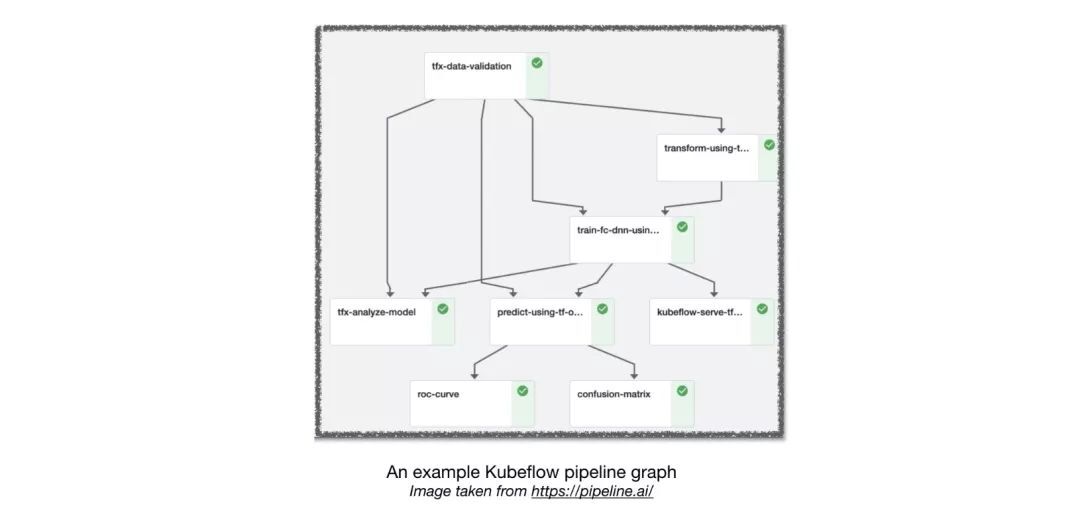
Airflow and KubeFlow ML Pipelines
本文提供的材料大部分来自于 Full Stack Deep Learning Bootcamp(全栈深度学习训练营)(作者:Pieter Abbeel、Josh Tobin、Sergey Karayev)、TFX 工作室(作者:Robert Crowe)、Pipeline.ai 举办的 Advanced KubeFlow Meetup(作者:Chris Fregly)。
该项目的 GitHub 地址(该项目还在完善中):
https://github.com/alirezadir/Production-Level-Deep-Learning

InfoQ 主编

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论