

伴随着数据化、智能化的浪潮,很多大企业为了沉淀通用技术和业务能力;加快企业智能化、规模化智能开发,开始了自建机器学习平台。从零搭建一个机器学习平台的复杂度是不容小觑的,关于平台的定位、需要解决的问题;及其架构、技术选型等需要提前考量和设计。本文根据几个从零到一的机器学习平台构建经历,再结合目前新兴热门的云上机器学习平台,试图对机器学习平台做一个概念和技术拆解。
平台的业务
从平台这个概念本身来说,它提供的是支撑作用,通过整合、管理不同的基础设施、技术框架,一些通用的流程规范来形成一个通用的、易用的 GUI 来给用户使用。通用性是它的考量之一、也是所有平台的愿景之一:希望平台能适用于各个不同的业务线来产生价值。所以从业务上来说,作为一个平台本身是不会、也不应该有太多 specific 的业务功能的。当然这只是理想情况,有时候为了平台使用方的需求,也不得不加上一些业务领域特定的功能或者补丁来适应业务方,特别是平台建设初期,在没有太多业务的使用的时候。整体来看,平台自身的业务可谓是非常简单,可以用一张图来表示:
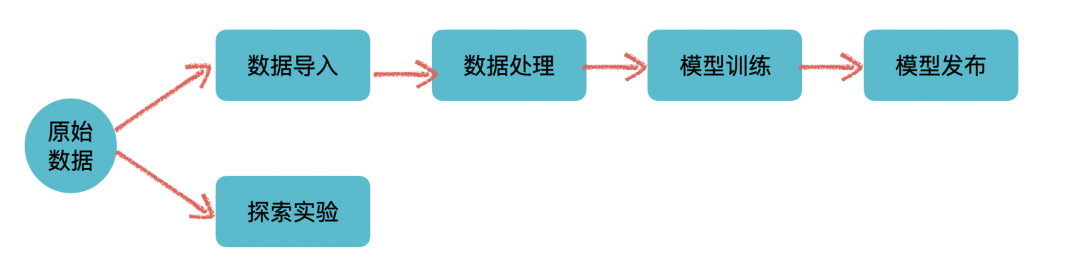
上面这个分支是标准的机器学习流程的抽象。从数据准备,数据处理,模型训练,再到模型上线实现价值完成整个流程。
下面这个分支,也是机器学习和数据科学领域中不可或缺的,主要指的是类似于 Jupyter Notebook 这类,提供高度灵活性和可视化的数据探索服务,用户可以在里面进行数据探索、尝试一些实验来验证想法。当然当平台拥有了 SDK/CLI 之后,也可以在里面无缝集成上面这条线里面的功能,将灵活性与功能性融合在一起。
基础设施
上面提到平台本身是整合了不同的基础设施、技术框架和流程规范。在正式开始之前,有必要介绍下本文后续所使用的的基础设施和框架。
在容器化、云化的潮流中,Kubernetes 基本上是必选的基础设施,它提供灵活易用的基础设施和应用管理能力,同时扩展性非常好。它可以用于
部署平台本身
调度一些批处理任务(这里主要指离线任务,如数据处理、模型训练。适用的技术为:Spark on kubernetes/Kubernetes Job),
部署常驻服务(一般指的是 RESTful/gRPC 等为基础的服务,如启动的 Notebook、模型发布后的模型推理服务。适用的技术为 Kubernetes Deployment/Kubernetes Statefulset/Service 等)。
机器学习的主要场景下,数据量都是非常大的,所以 Hadoop 这一套也是必不可少的,其中包含基础的 Hadoop(HDFS/HIVE/HBase/Yarn)以及上层计算框架 Spark 等。大数据技术体系主要用于数据存储和分布式数据处理、训练的业务。
最后就是一些机器学习框架,Spark 系的(Spark MLlib/Angel),Python 系的(Tensorflow/Pytorch)。主要用途就是模型训练和模型发布(Serving)的业务。
原始数据
原始数据,也叫做数据源,也就是机器学习的燃料。平台本身并不关心原始数据是如何被收集的,只关心数据存储的方式和位置。存储的方式决定了平台是否能支持此种数据的操作。存储的位置决定了平台是否有权限、有能力去读取到此数据。按主流的情况来看,原始数据的存储一般支持四类形式:
传统的数据库,例如 RDS/NoSQL。这类数据源见得比较少,因为一般在大数据场景下,通用的解决方案是将此类数据源通过一些工具导入到大数据体系中(如 Sqoop)。对于此类数据源的支持也是很简单的,使用通用的 Driver 或者 Connector 即可。
以 HDFS 为媒介的通用大数据存储。此类数据源使用较为广泛,最常见的是 HDFS 文件(parquet/csv/txt)和基于 HDFS 的 HIVE 数据源。另外,由于是大数据场景下的经典数据源,所以上层的框架支持较为完善。
NFS。NFS 由于其快速的读写能力,以及悠久的历史。很多企业内部都有此基础设施,因而已有的数据也极有可能存储在上面。
OSS(对象存储)。最过于流行的要属 S3 了。对象存储是作为数据湖的经典方案,使用简单,存储理论上无限,和 HDFS 一样具备数据高可用,不允许按片段更改数据,只能修改整个对象是其缺点。
值得注意的是,NFS 和 OSS 一般用于存储非结构化数据,例如图片和视屏。或者用于持久化输出目的,如容器存储,业务日志存储。而 HDFS 和数据库里面存放的都是结构化、半结构化的数据,一般都是已经经过 ETL 处理过的数据。存储的数据不一样决定了后续的处理流程的区别:
NFS/OSS 系数据源,基本上都是通过 TensorFlow/Pytorch 来处理,数据一般通过 Mount 或者 API 来操作使用。当然也有特例,如果是使用云服务,例如 AWS 的大数据体系的话,绝大多数场景下,是使用 S3 来代替 HDFS 使用的,这也得益于 AWS 本身对于 S3 的专属 EMRFS 的定制化。当然 Spark 本身等大数据处理框架也是支持此类云存储的。
HDFS 系和传统数据库系数据源,这个大数据框架、Python 系框架都是可以的。
平台一般会内嵌对以上数据源的支持能力。对于不支持的其他存储,比如本地文件,一般的解决方案是数据迁移到支持的环境。
数据导入
这应该是整个平台里较为简单的功能,有点类似于元数据管理的功能,不过功能要更简单。要做的是在平台创建一个对应的数据 Mapping。为保证数据源的可访问,以及用户的操作感知。平台要做的事情可以分为三步:
访问对应的数据源,以测试数据是否存在、是否有权限访问。
拉取小部分数据作为采样存放在平台中(如 MySQL),以便于快速展示,同时这也是数据本身的直观展现(Sample)。对于图片、视频类的,只需要存储元信息(如资源的 url、大小、名称),展示的时候通过 Nginx 之类的代理访问展示即可。
如果是有 Schema 的数据源,例如 Hive 表,数据源的 Schema 也需要获取到。为后续数据处理作为输入信息。
技术上来说,平台中会存在与各种存储设施交互的代码,大量的外部依赖。此时,外部依赖可能会影响到平台本身的性能和可用性,比如 Hive 的不可用、访问缓慢等,这个是需要注意的。
业务上来说,更多考量的是提高系统的易用性,举个例子,创建 Hive 表数据源,是不是可以支持自动识别分区,选择分区又或者是动态分区(支持变量)等。
数据处理
这里的数据处理是一个大的概念,从我的认知上来看。大体可以分成两个部分, 数据标注以及特征处理。
数据标注
数据标注针对是的监督学习任务,目前机器学习的应用场景大多都是应用监督学习任务习得的。巧妇难为无米之炊,没有足够的标注数据,算法的发挥也不会好到哪儿去。对于标注这块。业务功能上来说,基本上可以当成是另一套系统了,我们可以把它叫做标注平台。但从逻辑关系上来说,标注数据是为了机器学习服务的。本质上也是对数据的处理,所以划到机器学习平台里面也没有什么问题。
标注平台对应了之前提到平台的另一功能:提供通用的流程规范。这里,流程指的是整个标注流程,规范指的是标注数据存储的规范,比如在图像领域,目前没有通用而且规范的存储格式,比较需要平台来提供一种通用的存储格式。
数据标注有两种,一种是人工标注; 另一种是使用已训练好的机器学习模型来标注,然后再辅以人工确定和修订。无论是使用哪种方式,最后都需要人工介入。因为数据标注的正确性是非常重要的,大家应该都听过一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。如果给你的数据都是有问题的,那模型如何能学习到正确的能力呢。
在标注平台中,往往都是人工+模型混合使用的,整体流程如下:
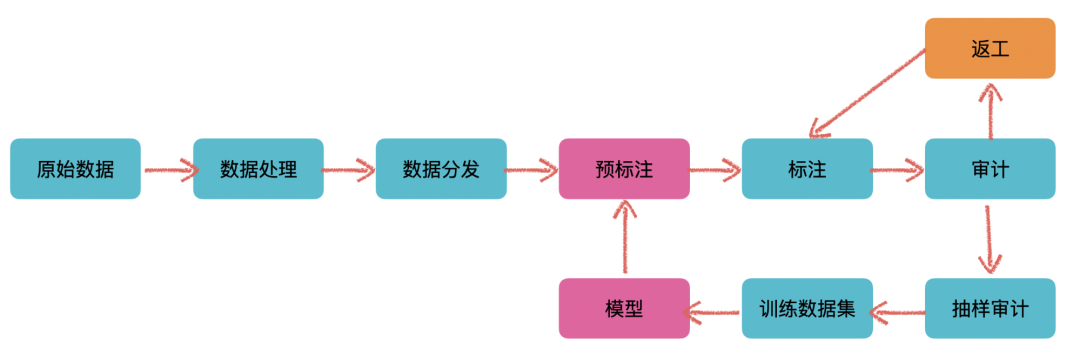
在最开始可能没有模型来辅助进行标注(这里的预标注),这个时候就需要人为手工介入,以此来训练出一个模型
当我们根据标注出的数据(训练数据集)训练出不错的模型之后,就可以使用此模型来对新输入的数据做一个预标注的工作,然后再辅以人工确认和修订
如此反复迭代,随着输入数据的增多,当我们训练出的模型准确率达到一个很高的水准之后,需要人工操作的数据就会越来越少。以此减少人工成本费
标注平台中需要考量的问题有几点:
一般来说,需要标注的数据量都是非常巨大的。不存在说两三个人随便标几下就完事。所以更为通用的做法是做一个众包平台,外包给其他公司或者自由职业者(标注员)来做。参考 AWS 的 Amazon Mechanical Turk。这就涉及到了权限控制、角色控制。
标注数据的准确性问题。不能避免有些标注员划水摸鱼,随意标注。此时是需要己方人员去做一个审计工作的,这里就是一个工作流,和上图所示差不多。是一个相对来说较为规范的流程,可以随着业务来增加额外的流程。
标注工具的开发。如果有合适开源工具,可以集成开源工具,如 VGG-VIA/Vatic, poplar。开源工具一般不会满足所有的需求,在开源上做二次开发往往成本更高。这里更倾向于自己开发,这样更能满足需要,自定义程度高,灵活性强
标注数据的存储。最好是一个相对通用的格式,以便于往各种其他格式做一个转换。在使用时做一个数据格式转换。这里更偏好 Json 格式类似的存储,可读性和代码可操作性都非常高
技术上的考量,这里并不是太多。唯一需要注意的可能是数据的处理,如图片、视频标注,资源的拆剪、缩放,各种标注数据的保存,坐标计算等。相对而言,后端主要是工作流处理,前端的各种标注工具是技术核心点。
特征处理
在正式开始模型构建与训练之前,对数据做特征处理基本上是必不可少的环节。特征处理的输入是之前创建的数据集、或者是标注完成后产生的数据集。它的输出是经过一系列数据操作后、可以直接输入到模型中的数据,这里称它为训练数据。
这里又可以分为两类,一类是不需要太多操作的特征处理,常见于非结构化数据,如图片、视屏。另一类是针对结构化/半结构化数据的特征处理流程,这类数据往往不是拿来即可用的,需要一定的特征处理。
首先来看第一类,第一类的典型应用场景就是 CNN 图像领域。对于输入的图片,一般不需要太多的操作。此类数据源往往也是存储在 NFS/OSS 上的。对于此类数据的处理,一般也不会使用到大数据框架,一般都是自己手撸 Python(C++)来处理;或者是放在模型训练一起处理,不单独拎开。Spark2.3 开始是支持图片格式的,不过目前没有看到太多的使用案例。整体流程如下:

本质上是一个批处理过程,Kubernetes 的 Job 天然适用于此类问题。当然其他调度框架来做这个任务调度也是可以的。
然后是第二类,这种基本上就是传统的特征工程了,以 Hive/HDFS 输入为经典例子。由于对数据的操作是非常多样的,所以一般倾向于构建一个数据处理的流水线,也就是 Pipeline:

把对数据的操作拆分成一个一个的操作运算(也就是一个 Pipeline Node 节点),可以把它叫做算子,然后利用 Pipeline 把操作进行自由组合,从而达到对数据进行各种变换处理的过程。使用过 Sklearn pipeline 或者 Spark MLlib pipeline 的小伙伴应该对此并不陌生,事实上,这就是基于此的可视化建模。使得用户可以在界面上进行拖拉拽,选择和输入一些参数来完成对于数据的操作,提供更灵活的功能。
那么这条 Pipeline 里面都有哪些操作呢,整个算子大致可以分为这几类别:
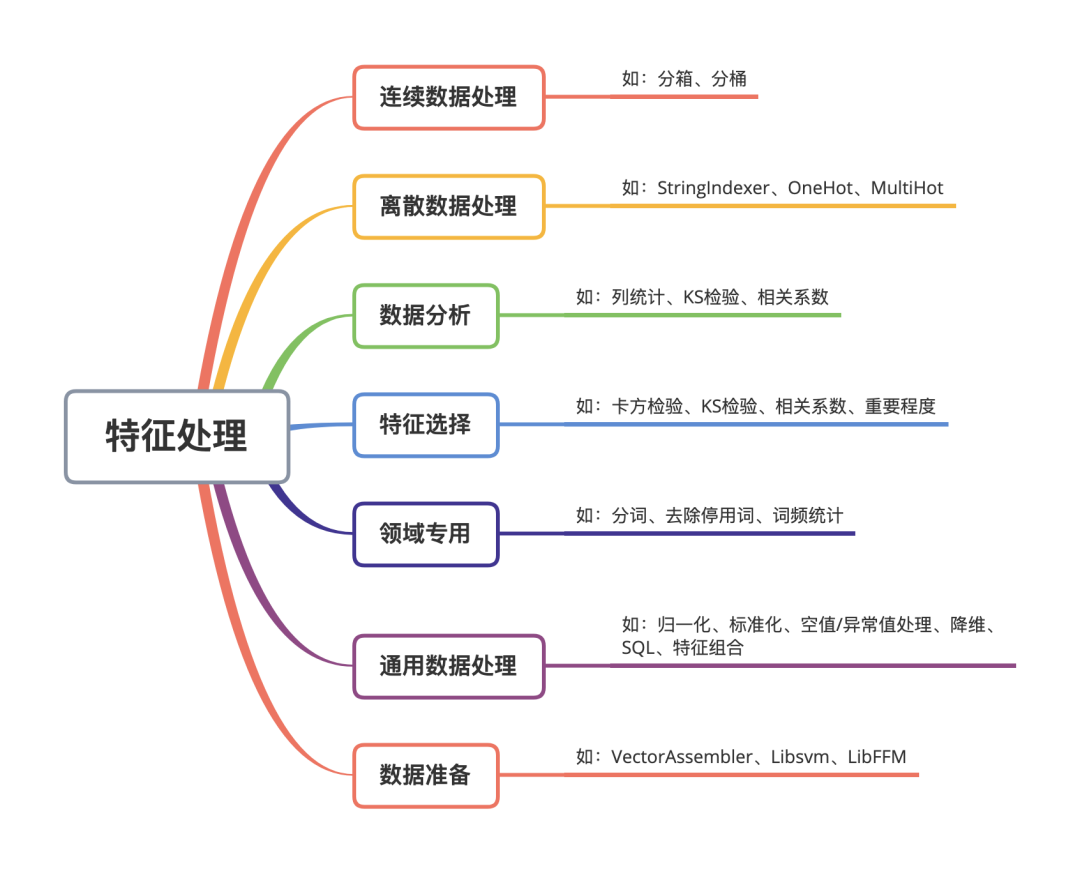
技术上,使用 Spark MLlib 是个不错的选择,可以适应不同数据量的规模。且天然支持这种 Pipeline 的形式,只需要对此做一定的封装。同时,考虑到业务功能,还需要手动定制、修改一些算子;对于扩展这点,它的支持也是非常不错的,自定义算子、算法都比较简单。当然也可以基于其他框架(如 Azkaban)或者自己造轮子。需要注意的是,在大数据场景下,Spark MLlib 里面部分自带的算子会有性能问题(有些直接 OOM),需要分析源码定位然后修复。包括我们自己实现的算子,也都要考量大数据场景下这个问题,这对于测试而言是个 Case。
整个 Pipeline 的核心是构造一个 DAG,解析后,提交给对应的框架来做处理。抛开技术来说,功能上来说,易用性和快速反馈是 Pipeline 需要注意的。比如:
所有的算子都应该能自动获取到可用的输入、对应类型,自动生成输出
支持参数校验,Pipeline 完整性校验
支持调试/快速模式,利用部分 Sample data 快速验证效果,相当于一个试验功能
日志查看,每个算子状态查看,以及操作完成后的 Sample data 查看
支持一些变量、SQL 书写,以扩展更灵活的功能,比如参数动态化
支持定时调度,任务状态邮件、短袖及时告警、同步等
模型训练
到了模型训练这块。从功能上来看需要的不是很多,更多是体验上的设计。比如参数在界面上的展示和使用,日志、训练出的 Metrics 的可视化、交互方式,模型的一些可视化等。核心功能包含这几块儿:
1.预置算法/模型
这里考量的点是:
支持界面手动调参
训练中日志、Metrics 的可视化。支持同时使用不同的参数多次训练,直观对比结果方便调参
需要支持常用的框架,如 Spark MLlib/Tensorflow/Pytorch,或者一些特定的框架(业务方需要的)
预置算法/模型很简单,在不同的框架上封装一层并且暴露对应的参数给到用户即可。有些算法可能框架不支持,这种根据情况决定如何解决(自己实现或者其他解决方案)。有一点就是,框架不宜太多,否则在后续模型发布的 Serving 上,也需要多套解决方案。对于训练本身来说,分为两种:单体/单机训练和分布式训练,分布式训练是训练这块的大头(也是技术难点所在)。
对于单体/单机训练的解决方案,和上诉特征处理中的解决方案一致。优先使用 Kubernetes 的 Job,或者使用 Spark,控制下 Executor 即可。
对于分布式训练,目前接触到的,基本上都是数据并行:
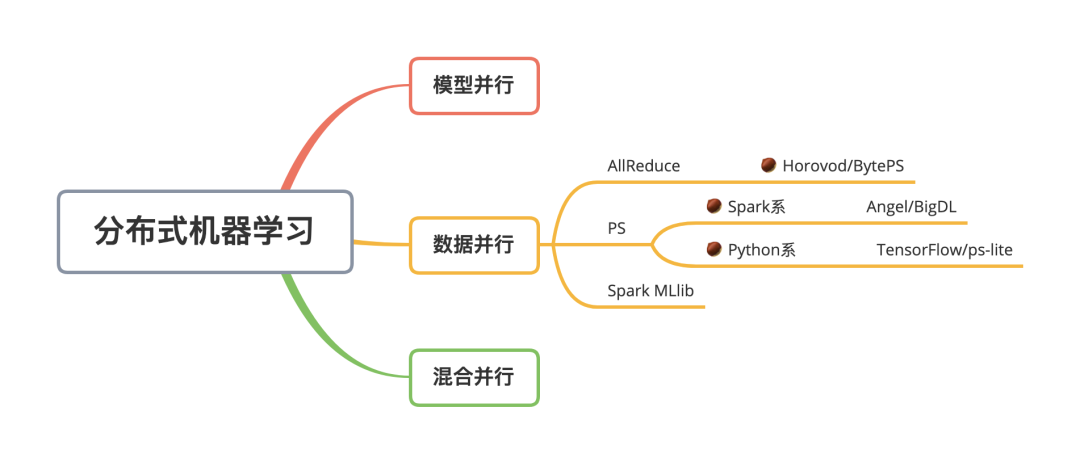
以 Spark 为基础的基本都使用的是 PS 模式。PS 模式一般使用的都是异步更新参数,每个 Worker 只需要和 PS 通信,所以容错管理上会更加简单。AllReduce 模式则是同步的参数模式,而且每个 Worker 都需要上下游通信,相对而言,容错处理会更苛刻一些。
Spark 系的分布式训练,经典的算法可以由 Spark MLlib 提供。但是其对于 DNN 的支持并不好,而且 Spark 的训练是一个同步的过程,如果数据倾斜的话,整个训练的速度取决于最慢的 RDD。如果要在 Spark 上跑深度学习的模型,一般会选用其他框架或者基于 Spark 的框架,如腾讯的 Angel、 Intel 的 BigDL。两者的思想都是一致的,同属于 PS 模式下的分布式训练,整个流程可以概括为这几步:
利用 Spark 来作为任务调度、资源分配、数据读取和容错处理的容器
从 PS 拉取参数,然后将数据和参数通过 JNI 喂到底层的框架代码中去(如 Pytorch C++ Frontend)完成训练,返回梯度
使用优化算法和梯度,更新参数,再将新的参数更新到 PS。如此反复
借用一张 Angel 的图:
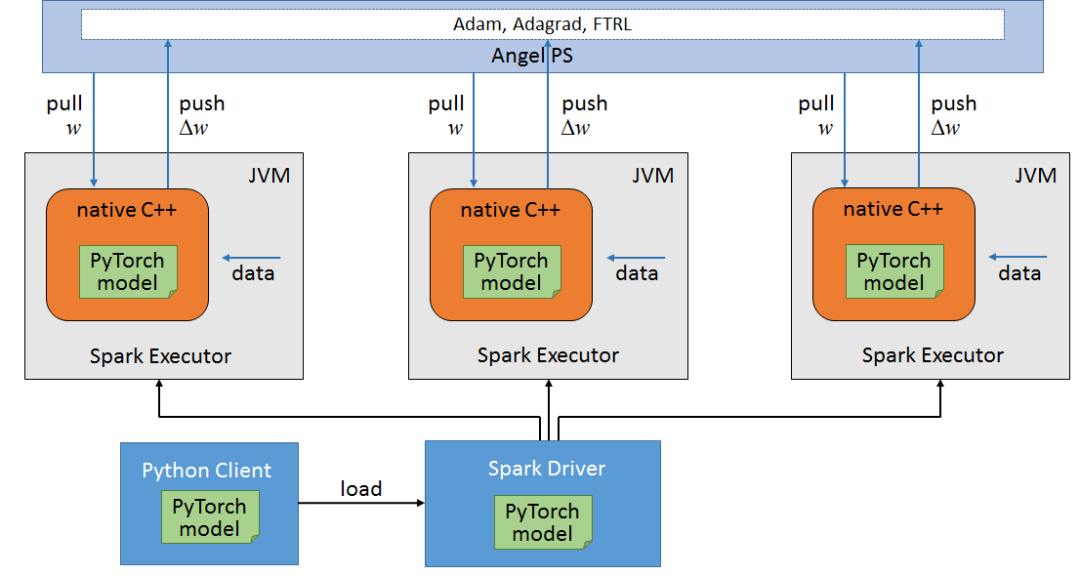
顺着这个思路,可以以 Spark 为基础,兼容任何深度学习框架。只要底层框架:
支持模型/代码序列化,以支持分发模型到所有 Worker 中进行本地训练
通过 JNI 能调用模型提供的接口,如 Forward/Backward
这要比自己造轮子更加便利和友好,毕竟 Spark 已经是一个成熟的分布式计算框架了。
如果使用的是 Python 系的深度学习框架有两点需要注意:
如何读取分布式存储上的数据以支持数据并行。也就是 Spark 里面 Partition 的概念。当然最简单的方法,就是将数据拆分成块,不同的节点读取不同的数据来训练。
另外一点在于容错性,基于 Spark 的分布式训练的优势就在于数据的分配、容错处理。现在就得自己去保障这两点了。
训练部署上面。Spark 系的,使用 Spark 支持的即可(Yarn/Kubernetes/Standalone)。Python 系的更倾向于云原生、或者基于 Kubernetes 的解决方案(自定义 Operator 是个比较好的选择),这里有个为云原生和容器化而生的框架:Polyaxon,值得一试。
2. 自定义算法
关于自定义算法,个人更倾向于将这个功能放在 Notebook 中而不是界面化的操作上,因为这个功能的自由度很高,允许用户自己写代码。平台其实只需要提供:
数据读取能力,这里包括源数据、平台内生成的数据
NFS/OSS 使用 Mount 形式或者 API 提供(如 Databricks 的 DBFS)
HDFS 系列的 API 提供支持(如提供 pyspark)
调度能力,能根据需求调度起任务。
以上两者功能,都或多或少依赖于 SDK/API/CLI。可以参考大厂的实现 Amazon SageMaker、Databricks Notebooks。
另外一点是 GPU 的支持,这点,如果是选择 Kubernetes 作为基础设施,是有基本的功能支持的,利用 Extended Resource(ER)配合 Device plugin 体系:
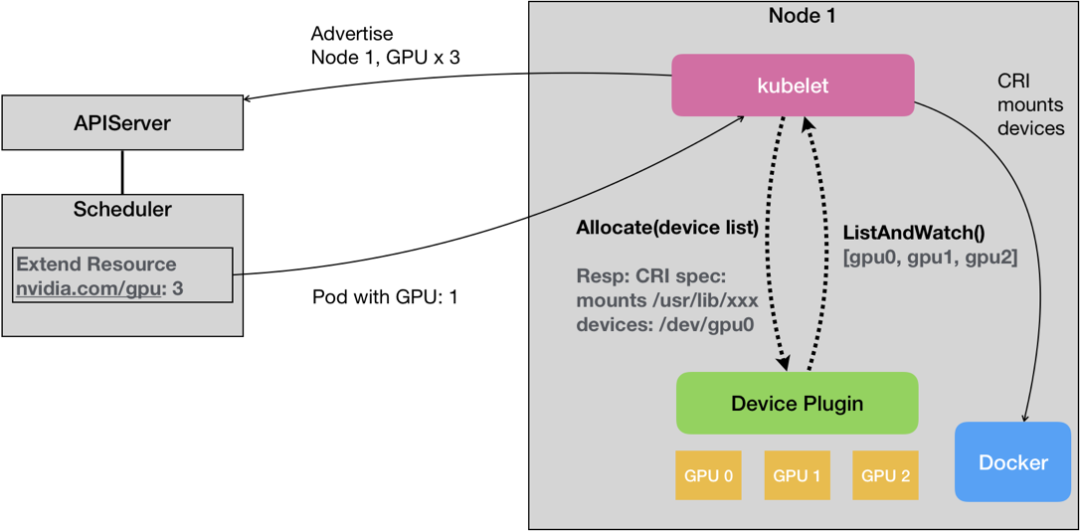
对于 Hadoop 体系的话,3.1.X 之后也是支持的。
这两者对于 GPU 的支持都非常有限,都是处于一个能用,但是不好用的状态。使用的时候,淌坑可能在所难免。
3. AutoML
关于 AutoML 这块。目前还没有太多的接触。从我看来,做个简单的随机搜索还是问题不大的,集成算法来自动调参、自动构建模型也是不难的。就跟上诉集成算法进来是一样的。唯一考量的是,集成那些算法进来以及计算资源的考量,尤其是深度学习大行其道的今天,类似于随机搜索这样耗费的资源是巨大的。如何设计这个功能,以及具体实现还是需要非常专业的领域知识。
总的来说,模型训练这块。是一个很偏技术的功能。完成一个 Demo 的端到端,实现基本的功能很简单。但是要做到好用、稳定性这两点就并不那么容易。尤其是分布式机器学习这一块儿,还是需要不断淌坑的。
模型发布
终于来到最后一步,是整个平台产生价值的最后一环。模型发布,通常包含两种发布:
发布成 API(RESTful/gRPC),以供业务侧实时调用。这类服务通常对于性能要求苛刻
发布成批处理形式,用于批处理数据,上述标注平台中的预标注属于此类任务
对于批处理形式的发布,较为简单。一般框架本身都支持模型的序列化和加载做预测:
Spark 系的就依旧走原始路线,提交 Spark Job,做批处理预测
TensorFlow 类似的,配合不同的镜像环境,Mount 模型,读取数据,配合 Kubernetes Job 的方式来启动批处理达到一个统一的处理流程
对于实时推理服务,于平台而言,能使用通用的框架/技术来做那当然是极好的。然鹅,现实很残酷。通用的解决方案,要么性能不够(如 MLeap),要么支持的算子/操作/输入有限(如 ONNX。想要在真正的业务场景下发挥价值都是需要淌坑的。用的更多的,往往都是性能领域强悍的 C/C++/RUST 来实现,比如自研、或者框架本身自带的(如 TensorFlow 的 Serving),会更能满足性能需求。平台选用的框架最好是不要太多,这样做 Serving 会比较麻烦,不同的框架都要去找解决方案实现一遍。
虽然做不到通用的模型 Serving 方案,但是通用的模型发布、提供服务的平台却是可以做到的。这是这部分的重点,即如何设计一个通用的推理平台。一个推理平台需要考量的点如下所示:
支持各种框架,多语言、多环境
模型版本管理
API 安全性
可用性、可扩展性,服务状态监控、动态扩容
监控、告警,日志可视化
灰度上线/AB Testing
把 Serving 看做是普通的 Web 服务。对于上诉的点,Kubernetes 体系是绝佳的选择:
镜像,配合 NFS 的模型,启动时 Mount 再复制到容器内部。可以支持多语言、多环境
版本管理,每个版本在 NFS 上创建新的版本目录,比如 0.0.1,放入对应的模型和启动脚本配合一个 Service。这样就允许不同版本的 Service 同时在线,或者部分在线
API 安全性,与 Kubernetes 本身无关。简单的做法是为每个 API 生成对应的调用 Token 来做鉴权,或者使用 API 网关来做
可用性、可扩展性。利用 Kubernetes 原生的 Liveness/Readness probe,可以检测单个 Pod 中服务的状态。使用 Kubernetes 的 HPA、或者自己实现监控再配合 Autoscale 可以满足需求,而且这些都可以成为一些配置暴露给用户
监控、告警。可以 Prometheus+Grafana+Alertmanager 三件套,或者配合企业内部的运维体系
交给 Istio 即可。灰度发布肯定妥妥的,利用一些 Cookie/Header 来做分流到不同版本的服务也可以做到部分 AB Testing 的事情
由于 Serving 服务与服务之间是没有关系的,是一个无状态的单体服务。对于单体服务的各种处理就会比较简单。比如不使用 Kubernetes,使用 AWS 云的 EC2 来部署,配合 Auto Scaling、CloudWatch 等也是非常简单的。
Addons
除开上诉的核心功能。一般来说,机器学习平台还有一些扩展。最经典的当属 CLI 和 SDK 了。
CLI 就不用多说了,主要提供快捷入口。可以参考 AWS 的 CLI。需要包含的点主要是:
提供基本的操作功能,满足用户的使用
以及导入导出功能。方便用户共享配置、快速创建和使用平台的功能
支持多环境、认证
完善的操作使用文档、帮助命令、模板文件等
对于 SDK 这块,需要和平台本身的功能做深度集成;同时,还需要一定的灵活性。比如上诉的自定义算法,用户可以在 Notebook 里面读取平台生成的数据集,写完代码后,还得支持提交分布式训练。既要集成平台功能,又得支持一定程度的自定义,如何设计会是一个难点。
探索实验(Notebook)
Notebook 本身功能并不复杂。实质上就是对 Jupyter Notebook/JupyterLab 等的包装。通常的做法是使用 Kubernetes 的 Service,启动一个 Notebook。以下几点是需要考量的:
存储要能持久化,需要引入类似于 NFS 这样的持久目录以供用户使用
内置 Demo,如读取平台数据、访问资源、提交任务
预置不同的镜像,支持不同的框架,以及 CPU/GPU 诉求用于启动不同的 Notebook
安全问题,一个是 Notebook 本身的安全。另一个是容器本身的安全
有可用的安全源,以供用户安装和下载一些包和数据
能够访问到基础设施里面的数据,Mount/API
最好能有 Checkpoint 机制,不用的时候回收资源。需要的时候再启动,但环境不变
大致的解决思路如下:
持久化需要 Mount 存储。Storage class 可以帮助
Notebook 自身的安全,可以在里面增加 Handler 或者外面配置一层 Proxy 来鉴权。容器的安全大概有这几点需要考量(要做到更严格还有很多可以深挖):
限制容器内部用户的权限
开启 SELinux
Docker 的—cap-add/—cap-drop
heckpoint 机制的实现,数据已经持久化在外部存储了。只需要 Save 新的镜像,作为下次启动的镜像即可,可使用 Daemonset+Docker in dokcer 的形式做一个微服务来提交镜像。
平台的基石
这一节主要讨论的是做平台一定绕不开的问题。首先逃脱不了的是多租户问题:
可能要和已有的系统进行集成。而不是新开发
租户间权限、数据隔离
租户资源配额、任务优先级划分
技术上来说,系统自身的租户功能难度不高。主要是数据、资源隔离这块。要看对应的基础设施:
Hadoop 可以使用 Keberos
Kubernetes 可以使用 Namespace
再配合不同的调度队列。即可完成需求。
另外一点是偏技术层面的调度功能。这可以算是整个平台运行的基础,无论是数据处理还是模型训练、模型部署都依赖于此, 调度系统分为两块:
调度本身,即如何调度不同的任务到不同的基础设施上
状态管理,有些任务可能存在依赖关系,会触发不同的 Action。这也是一个状态机的问题
状态管理这块,业务场景不复杂的情况下自己实现即可。一般平台上也没有太复杂的依赖关系,经典的模型训练也不过单向链路而已。如果过于复杂,可以考虑其他开源任务编排工具:

调度本身是一个任务队列+任务调度组合而成。队列用啥都可以,数据库也可以。只要能保证多个 Consumer 的数据一致性即可。任务调度,如果不考虑用户的感受,可以直接丢给对应的基础设施,如 Yarn/Kubernetes 都可以。由这些基础设施来负责调度和管理,这样最简单。
如果想做的尽善尽美,那还是需要维护一个资源池。同步基础设施的使用情况,然后根据剩余资源和任务优先级来做调度。
状态更新方面。对于 Yarn 体系,只能通过 API 去轮询状态、获取日志。
对于 Kubernetes 体系,推荐一个 Informer 机制,通过 List&Watch 机制可以方便、快速获取整个集群的情况:
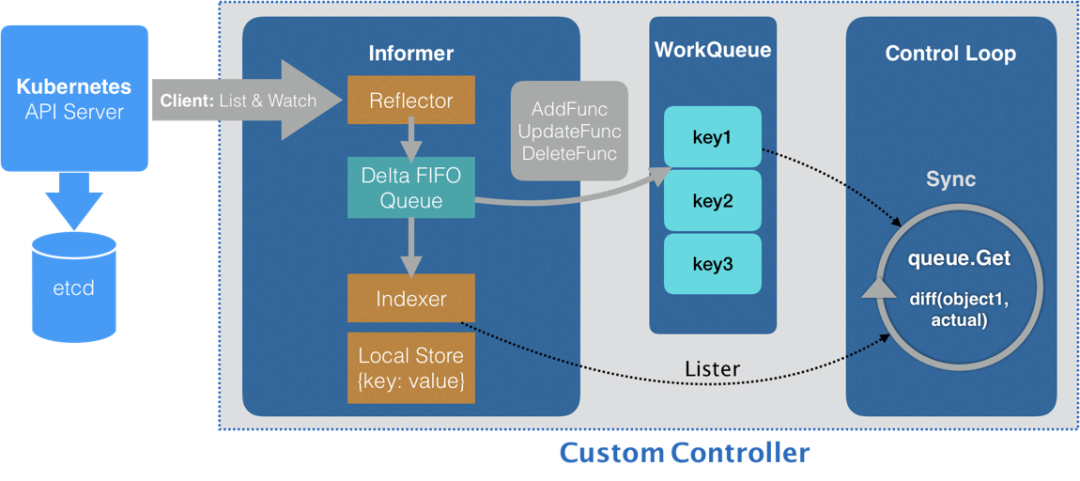
关于如何提交任务到基础设施:
Spark/Yarn - 直接 API、包装下命令行者 Livy 都可
Kubernetes - SDK
最终 Boss
做平台,最怕的是什么?当然不是某某技术太过于复杂,攻克不下。而是没有用户使用平台,或者不能通过平台产生真实业务价值,这才是最重要的。有某一业务场景在平台实现端到端产生价值,才能证明这个平台的价值,才能吸引其他用户来使用。
对于用户来说,一般都已经有自己成熟的技术线。想要他们往平台上迁移,实属不易,除非已有系统满足不了他们的需求、或者已有系统不好用。毕竟,自己用的好好的系统,迁移是需要耗时耗力的,用别人的东西也没有自己做来的灵活;学习一个新的系统使用也是如此,有可能一开始用着并不习惯。此外,新的系统,没有人期望第一个来当小白鼠的。有这么多缺点,当然平台本身也有其优点。比如将基础设施这块甩给了第三方,不用去关注底层的东西,只要关注自己的业务了。
事实上的流程往往都是,随着平台 MVP 的发布。部分用户开始上来试用,然后提各种想法和需求;紧接着,会逐渐迁移部分功能上来试用,比如搞些数据上来跑跑 Demo,看看训练的情况等。同时,在这个阶段,就会需要各种适配用户原始的系统了,比如原始数据导入与现有系统不兼容,需要格式的转换;再比如只想用平台的部分功能,想集成到自己现有的系统中等。最后才是,真正的在平台上使用。想要用户能端到端的使用平台,来完成他们的业务需求,还是需要漫长的过程的。
相对而言,至上而下的推动往往更为有效。总有一批人要先来体验、先来淌坑,给出建议和反馈。这样这个平台才会越来越好,朝好的地方发展。而不是一开始上来就堆功能,什么炫酷搞什么、大而全。但是在用户使用上,易用性和稳定性并不好,或者是并不能解决用户的需求和难点。那这种平台是活不下去的。
本文转载自:ThoughtWorks 洞见(ID:TW-Insights)
原文链接:机器学习平台建设指南

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论