

近日,科大讯飞再次登上 SQuAD 2.0 挑战赛榜首,不过这次顺带刷新了一下纪录:在 EM(精准匹配率)和 F1(模糊匹配率)两项指标上全面超越人类平均水平,分别达到 87.147 和 89.474。其中 EM 指标高出人类平均水平 0.3 个百分点,F1 则是略微超过人类平均水平。同时,科大讯飞所提出的单模型效果也是目前榜单中最好的一个。
能取得这样的成绩,得益于科大讯飞团队此次的参赛模型“BERT + DAE + AoA”。为什么这个模型能取得这样高的精度?为寻找答案,AI 前线邀请到科大讯飞 AI 研究院资深级研究员、研究主管崔一鸣,来详细了解科大讯飞在比赛中刷新纪录的秘密。
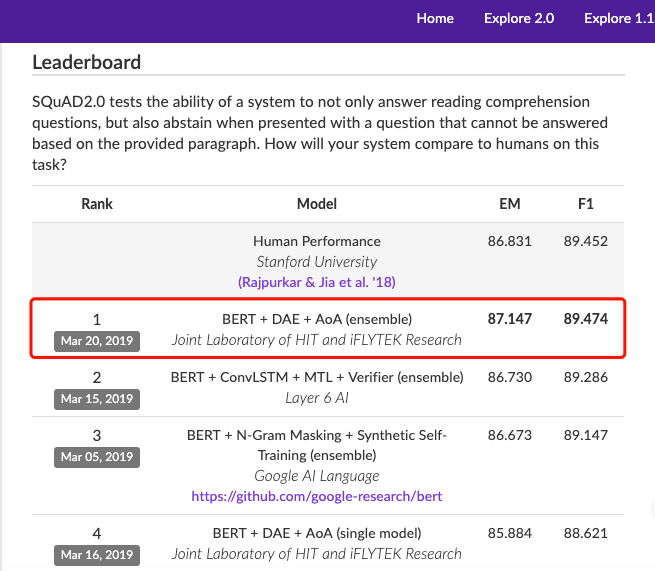
EM、F1 两项指标首次全面超越人类平均水平
SQuAD 2.0 是认知智能行业内公认的机器阅读理解领域顶级水平测试,通过吸收来自维基百科的大量数据,构建了一个包含十多万问题的大规模机器阅读理解数据集。
SQuAD 2.0 阅读理解模型的评估标准包括两个,即精确匹配(Exact Match)和模糊匹配(F1-score),这是对参赛者提交的系统模型在阅读完数据集中的一个篇章内容之后,回答若干个基于文章内容的问题,然后与人工标注的答案进行比对之后得出的结果。
此前,这两个指标中的单一指标均不断被打破,评价指标超过人类平均水平甚至是两个指标都超过人类平均水平尚属首次,所以有人评价道,此次突破还是值得更多人关注的。
与其他机器阅读理解任务不同,SQuAD 2.0 阅读理解任务的模型不仅要能够在问题可回答时给出答案,还要判断哪些问题是阅读文本中没有材料支持的,并拒绝回答这些问题。
听起来不简单。那么,科大讯飞是怎么做到的呢?
BERT + DAE + AoA 详解
工作原理
科大讯飞能够完成完成可回答问题,识别并拒绝无法回答的问题,最终刷新机器阅读理解能力纪录,与背后的参赛模型 BERT + DAE + AoA 息息相关。下面是关于这个模型的详细工作原理和性能表现数据:
BERT + DAE + AoA 模型融合了业界领先的自然语言语义表示模型 BERT 以及团队持续积累和改进的层叠式注意力机制(Attention-over-Attention,AoA)。除此之外,本次提交的系统包含了全新技术 DAE(DA Enhanced),这里的 DA 有两层含义,一个是数据增强(Data Augmentation),另一个是领域自适应(Domain Adaptation)。早在 2017 年,科大讯飞团队就开始研究利用伪训练数据提升神经网络模型效果,并将之应用于中文零指代任务中。通过生成大量的伪数据可以进一步扩充已有的训练数据,提供了更多的<篇章,问题,答案>三元组,有利于模型进一步学习三者之间的关系,从而提升系统效果。
本次提交的模型中,多模型的 EM(精准匹配率)达到 87.147,F1(模糊匹配率)达到 89.474,其中 EM 指标高出人类平均水平 0.3 个百分点,F1 则是略微超过人类平均水平。同时也可以看到,所提出的单模型效果也是目前榜单中最好的一个。
仍有改进空间
但是,BERT + DAE + AoA 并非此类任务的完美解决方案,它还有很大的改进空间。
崔一鸣表示,由于 SQuAD 2.0 评测的一大侧重点是加入了“不可回答的问题”,这就要求模型不仅能够做好预测答案的工作(即 SQuAD 1.1 任务),还要同时判断问题是否能够使用篇章内容进行回答。我们可以看到,SQuAD 1.1 上最新的一些模型在模糊准确率上已经可以达到 93%以上了,这就意味着对于这些“可答”的问题来说提升空间已不是那么大了。同时,对于“不可答”的这类问题,答对的话 EM 和 F1 均得 1 分,答错的话两个指标均不得分,而不像“可答”的这类问题一样存在“灰度”,即只要答对一部分就能得一些分。
目前在 SQuAD 2.0 上,虽然科大讯飞取得了不错的效果,但在拒答方面的准确率仍然要低于可答的部分。所以从这样的一个客观情况分析,后续仍然要设计更加精巧的模型来判断一个问题是否能够通过篇章进行回答。
目前主流的模型采用的是“多任务”的思想,机器需要同时完成两件事:
1)预测一个问题是否可答
2)预测该问题在篇章中的答案
模型需要从训练样例中学习到哪些问题是可以回答,哪些问题是不能回答的(在训练样本中有对应的标记),对于可回答的问题同时要学习如何判断篇章的起止位置从而抽取出对应的答案。在预测时,需要注意的是“可答”和“不可答”问题之间是需要有一个界线来划分。所以,如何权衡这两类回答的比例也是一个很难的问题。绝大多数模型目前采用手工阈值的方法来决定这个界限,但这样的方法普适性较差,应进一步寻求一个自动阈值的方法来平衡这两类问题的答案输出。
怎样看待暴力求解派?
“大数据+大算力”=大力出奇迹
前段时间,谷歌的 BERT 模型、OpenAI 推出的 NLP 模型 GPT 2.0 在业界引起了热议,它对 Transformer 模型参数进行扩容,参数规模达到了 15 亿,并使用更海量的数据进行训练,最终刷新了 7 大数据集基准,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。业界还有一种说法,即模型越大、数据越多,可能效果就会越好。如果未来我们有了 50 亿、100 亿的参数,会不会在机器阅读理解某些方面实现更多突破?如果能实现,会是在哪些方面?作为 NLP 领域专家,崔一鸣怎么看待像 GPT 2.0 这样的暴力求解派呢?
崔一鸣表示,谷歌 BERT 模型的成功给我们很大启示,也从真正意义上让自然语言处理迈向大数据时代,为整个自然语言处理领域做出了很大贡献。不可否认的是“大数据+大算力”能得到“大力出奇迹”的效果。如果我们能够应用更多的数据,有更强算力的设备,也许自然语言处理还会迈向一个更高的台阶。
机器学习距离真正的“理解”还有很远的距离
但作为每个子领域的研究人员,对于任务本身的深度理解是可以在巨人的肩膀上看得更远,跳得更高。虽然我们目前欣喜地看到在机器阅读理解的一些子任务中机器的效果已经超过人类的平均水平,但我们距离真正的“理解”还有很长一段路要走。目前机器只能完成一些“知其然”的工作,但在很多领域,例如司法、医疗,机器不仅仅需要“知其然”,更要“知其所以然”,这样才能更好的辅助人们的工作。
相比图像,语音领域、自然语言处理领域的发展相对来说是比较缓慢的。其主要原因在于自然语言并不是自然界中的物理信号,例如像素、波形等。自然语言是人类在进化过程中高度抽象化的产物,其语义信息是非常丰富的,但这也意味着对于自然语言的精准物理表示是很困难的。一个自然语言处理任务的性能效果往往很大程度的依赖于如何更好的表示自然语言,或者说如何用与当前自然语言处理任务更加契合的方法来表示自然语言。
纵观近期在自然语言领域引起轰动的一些成果,例如艾伦人工智能研究院(AI2)提出的 ELMo、谷歌提出的 BERT、OpenAI 提出的 GPT 等等,无一例外都是围绕自然语言的表示所做出的贡献。我们可以看到应用了这些模型的系统在自然语言处理的各个任务上均取得了非常好的效果。由此可见,自然语言的表示是一个需要持续推进的基础研究,这对于整个自然语言处理领域都是非常重要的研究议题。
在崔一鸣看来,机器阅读理解未来的发展方向包括:
1) 阅读理解过程的可解释性
2) 引入深层推理,外部知识的阅读理解
3) 阅读理解与其他自然语言处理任务的结合
阅读理解与问题拒答技术的结合已有落地
不过话说回来,再好的技术最终还是要落地于产品才会发挥最终的价值,BERT + DAE + AoA 在机器阅读理解方面可以达到这么好的效果,那什么时候它才能被应用到科大讯飞的产品中呢?
崔一鸣表示,其实早在 2017 年,科大讯飞就已经开始探索阅读理解与问题拒答技术的结合,并成功应用在智能车载交互系统中。机器阅读理解技术目前成功应用在车载电子说明书产品中且已在实际车型上得到应用。通过让机器阅读汽车领域的材料,使机器深度理解并掌握对该车型的相关知识。在用户提出问题时,不仅能够快速反馈给用户相关章节,并且还能够利用阅读理解技术进一步挖掘并反馈更精准的答案,同时针对不可回答的问题进行拒答,从而减少用户的阅读量,提高信息获取的效率。
除了 SQuAD 这类的任务之外,科大讯飞还在探索对话型阅读理解的研究。通过多轮人机对话完成阅读理解并获取所需要的信息更加符合真实的应用场景,也是未来机器阅读理解技术落地的一大方向。
背后的团队
最后,我们了解了一下此次参赛模型背后的团队——哈工大讯飞联合实验室和河北省讯飞人工智能研究院联合团队。
其中,哈工大讯飞联合实验室于 2014 年由科大讯飞与哈尔滨工业大学联合创建,全称是“哈尔滨工业大学•讯飞语言认知计算联合实验室”(HIT•iFLYTEK Language Cognitive Computing Lab,简称 HFL)。根据联合实验室建设规划,双方将在语言认知计算领域进行长期、深入合作,具体开展阅读理解、自动阅卷、类人答题、人机对话、语音识别后处理、社会舆情计算等前瞻课题的研究。重点突破深层语义理解、逻辑推理决策、自主学习进化等认知智能关键技术,支撑科大讯飞实现从“能听会说”到“能理解会思考”的技术跨越,并围绕教育、司法、人机交互等领域实现科研成果的规模化应用。
科大讯飞河北省讯飞人工智能研究院,成立于 2019 年 1 月,是科大讯飞推动人工智能战略落地和京津冀区域人工智能规模化应用和产业发展重要核心研发团队之一。研究院重点聚焦人工智能中认知智能技术,实现认知基础前沿技术、教育认知技术、司法认知技术等技术在政务、各公共服务等领域的应用。
作者简介
崔一鸣,科大讯飞 AI 研究院资深级研究员、研究主管。哈尔滨工业大学社会计算与信息检索研究中心(SCIR)在读博士研究生,2014 年和 2012 年毕业于哈尔滨工业大学计算机科学与技术专业分别获得工学硕士以及工学学士学位。长期从事并探索阅读理解、问答系统、机器翻译、自然语言处理等相关领域的研究工作。曾作为主要研究人员参加了 2012 年国际口语机器翻译评测(IWSLT2012)、2014 年国际口语机器翻译评测(IWSLT2014)、2015 年 NIST 机器翻译评测(NIST OpenMT 15)并获得了多项第一名,2017 年至今带领阅读理解团队多次获得国际权威机器阅读理解评测冠军,同时,在自然语言处理顶级及重要国际会议 ACL、AAAI、COLING、NAACL 上发表多篇学术论文,并担任 ACL/EMNLP/COLING/NAACL/AAAI 等国际顶级会议程序委员会委员,JCSL、TKDD 等国际 ESI 期刊审稿人等学术职务。


暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论