
在人工智能与多媒体技术深度融合的当下,视频时序定位(Video Temporal Grounding)成为视频理解领域的核心任务之一,其目标是根据自然语言查询,在长段视频流中精准定位出与之匹配的时序片段。这一能力是智能视频剪辑、内容检索、人机交互、事件分析等众多场景落地的关键基础。例如,快速定位球赛进球瞬间、影视剧名场面、游戏高光镜头、响应“回放主角微笑片段” 、异常事件查看等需求,均依赖于高效精准的时序定位技术。如今,火山引擎多媒体实验室联合南开大学研发的 TempSamp-R1 框架,通过对强化学习技术的突破性创新,为视频大模型的“时空感知力”带来质的飞跃—— 该成果已被人工智能领域顶会 NeurIPS 2025 接收。

论文链接:https://arxiv.org/pdf/2509.18056
直击行业痛点:传统方法深陷 “效率与精度” 双重困境

图 1 视频时序定位任务示例
视频时序定位任务中,模型需在数分钟甚至数小时的视频流中,精准锁定与文本查询匹配的几秒到几十秒片段。现有主流方案长期面临两大核心难题:基于监督微调(SFT)的方法过度依赖确定性标注,缺乏动态时序推理能力,面对复杂视频场景易出现定位偏差;而基于强化学习的 GRPO 方法虽具备自适应学习能力,但受限于 on-policy 采样机制,在广泛的视频时序搜索空间中探索效率低下,且存在奖励信号稀疏、训练收敛不稳定等问题,导致训练时精度与速度难以兼顾。
三大核心创新:高效提升 MLLM 视频时序定位精度
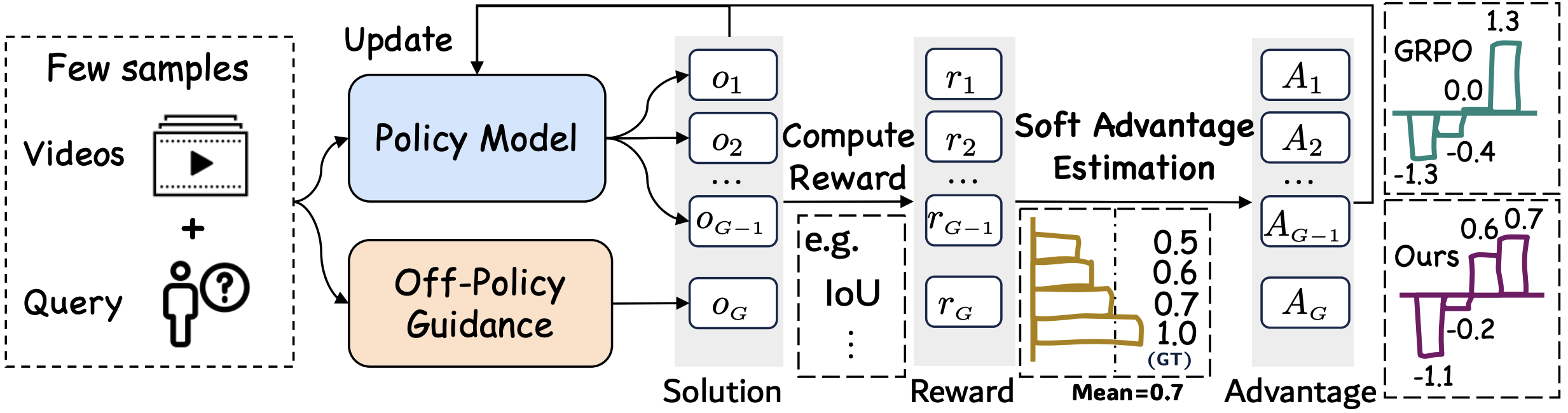
图 2 TempSamp-R1 框架概述,该框架用于微调多模态策略模型
TempSamp-R1 框架通过 “混合策略采样 + 优势塑造 + 灵活推理范式” 的三重创新,构建起高效稳定的视频时序定位学习体系,其技术突破点可概括为以下三方面:
混合策略采样:让真值标注成为 “精准导航仪”
TempSamp-R1 框架将 on-policy 动态探索与 off-policy 监督指导相结合,提出 “(G-1)+1” 混合采样策略,即每个查询对应 G 个训练样本,其中 G-1 个来自当前策略的 on-policy 生成样本,1 个为基于真值标注的 off-policy 样本。这种设计既保留了强化学习的探索能力,又通过标注数据样本为模型提供精准时序定位,有效解决了 GRPO 框架中 on-policy 采样的稀疏性问题。
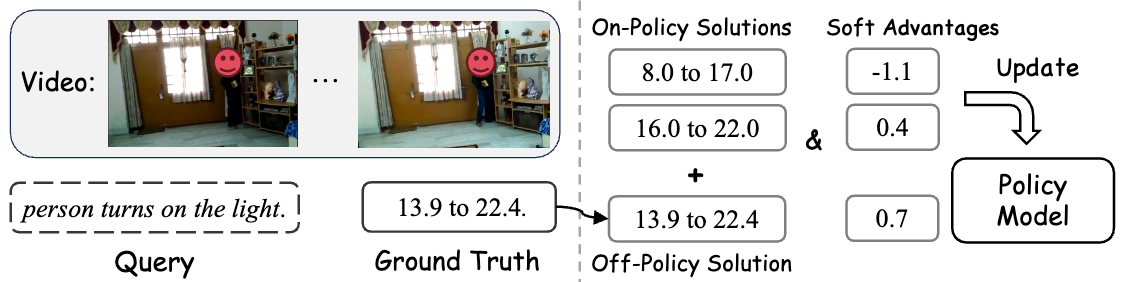
图 3 TempSamp-R1 将高质量的注释与基于策略的采样相结合示例
非线性优势塑造:给奖励信号 “装上稳压器”
混合采样虽结合两类样本优势,但 off-policy 标注数据样本的高奖励与 on-policy 探索样本的常规奖励存在分布偏移,直接融合易致训练主导失衡、梯度波动。针对此问题,TempSamp-R1 提出三个可选择的优势塑造策略:1.通过奖励缩放将 off-policy 奖励限制在最大值的 80%,避免其过度主导训练;2.采用优势锚定机制独立计算 off-policy 优势,增强监督信号的引导作用;3.创新引入非线性奖励函数,对高奖励区域进行压缩、低奖励区域进行扩展,有效缓解奖励稀疏带来的梯度不稳定问题。如图 4 所示,GRPO 基线奖励中位数低、箱线分散(方差大,训练波动剧烈),而 TempSamp-R1 奖励箱线更紧凑、中位数更高,直观印证优势塑造的 “稳压” 效果 —— 既稳定捕捉高价值时序解,又降低奖励波动,缓解梯度震荡。
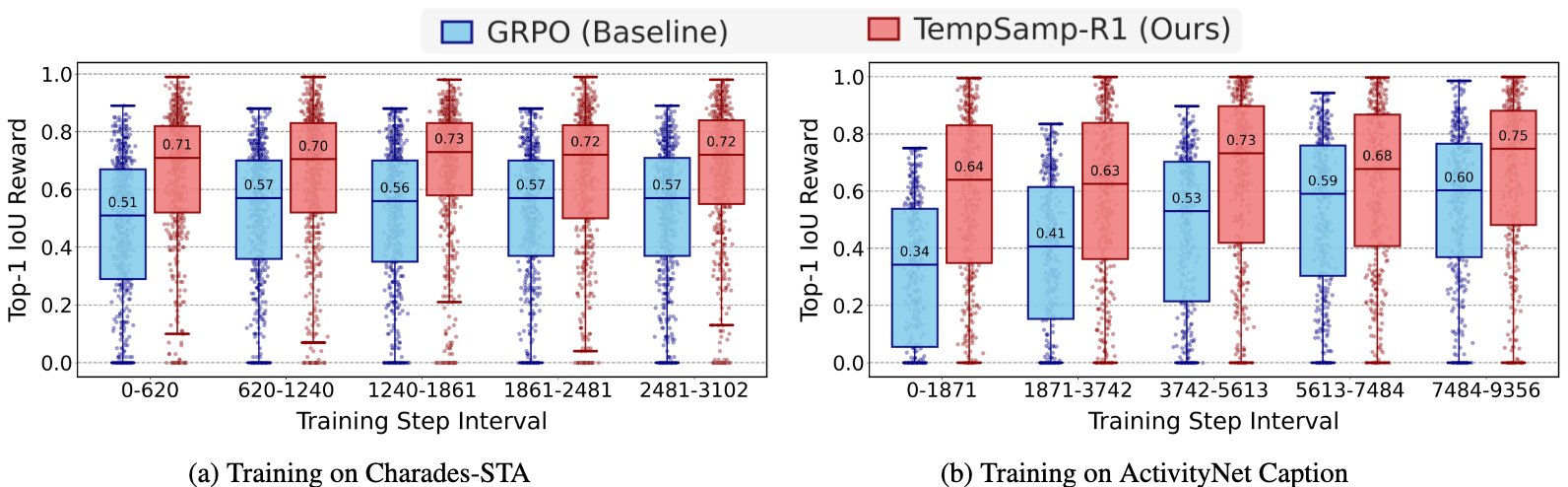
图 4 对比 GRPO 和 TempSamp-R1 算法在 Charades-STA 和 ActivityNet Captions 数据集上 top-1 IoU 得分的分布情况
混合 CoT 训练:兼容适配 “复杂 + 高效” 双重需求
考虑到不同视频任务的推理复杂度差异,框架设计了混合思维链(CoT)训练范式:第一阶段聚焦基础定位能力,仅要求模型输出

图 5 TempSamp-R1 进行时间定位的示例
刷新 SOTA 纪录:三大数据集性能全面突破
基于 Qwen2.5-VL-7B-Instruct 基座模型,TempSamp-R1 在三大权威基准数据集上展现出压倒性性能优势,核心指标均超越现有最优方案:
CharadesSTA(事件时序定位):R1@0.7 指标达到 52.9%,较最优 GRPO 基线提升 5.0 个百分点,较 SFT 基线提升 7.6 个百分点;
ActivityNet Captions(长视频事件定位):R1@0.5 指标达到 56.0%,较此前 SOTA 提升 5.3 个百分点,在长时序推理场景中优势尤为显著;
QVHighlights(视频高光检测):mAP 指标达到 30.0%,较最优基线提升 3.0 个百分点,且非 CoT 模式下推理速度提升 25%。
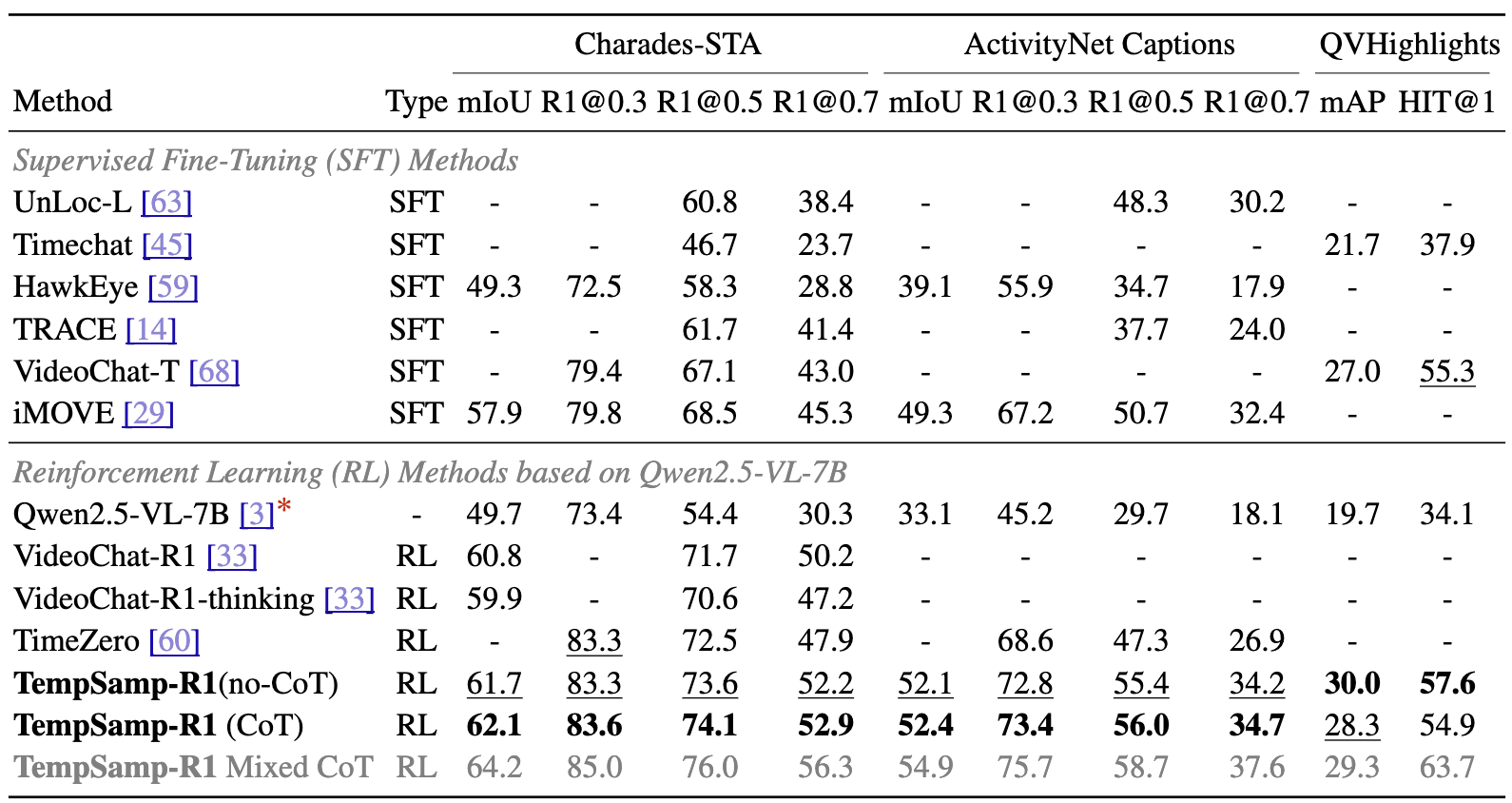
图 6 对比不同模型在 Charades-STA、ActivityNet Captions 和 QVHighlights 数据集上性能
更值得关注的是,TempSamp-R1 展现出极强的泛化能力:
在跨数据集迁移测试中,从 CharadesSTA 训练的模型直接应用于 ActivityNet Captions,mIoU 指标达 34.7%,较 GRPO 提升 4.0 个百分点;
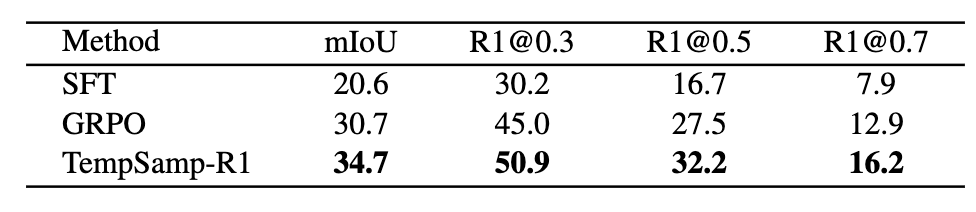
图 7 从 Charades-STA 到 ActivityNet 的跨域泛化性能
在小样本的训练中,仅用 50 个训练样本时,mIoU 达 44.7%,超 SFT 2.8%;500 样本时 mIoU 达 55.1%,超 SFT 8.9%、GRPO 5.3%,且训练时间(218 分钟)短于 GRPO(338 分钟)。
智能剪辑迎来突破:效率实现跨越式提升,重构内容生产流程
TempSamp-R1 在强化学习领域的核心突破,不仅是技术层面的创新升级,更关键的是,依托该技术已构建起 “基于时序理解的高光检测→基于故事线理解的智能剪辑” 这一行业领先的完整技术闭环解决方案,目前已在点播与直播场景深度应用,跨越式提升智能剪辑效率:
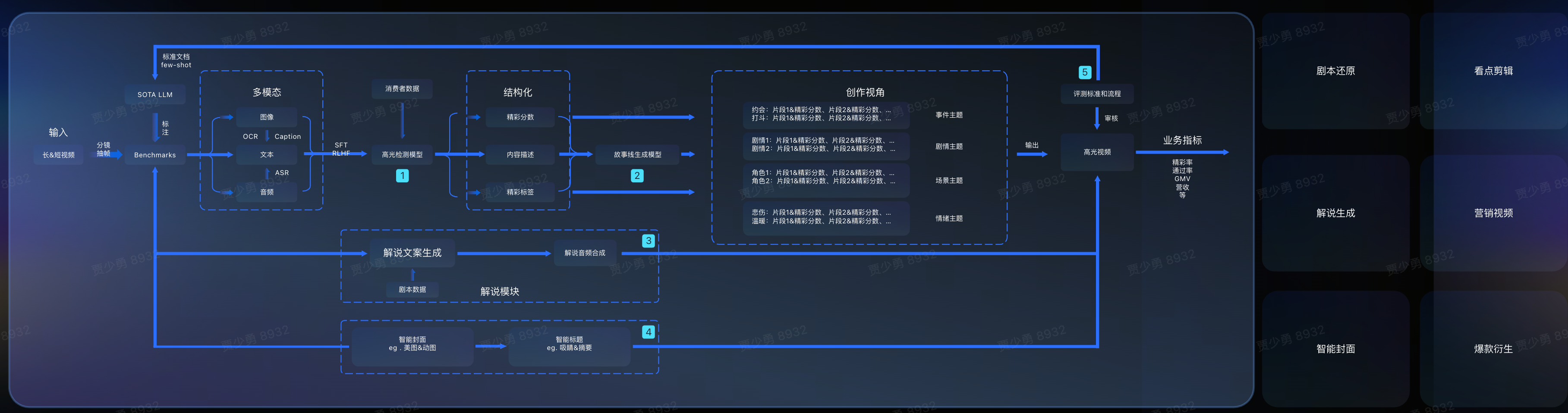
图 9 视频高光智剪解决方案框架图
点播场景:基于 TempSamp-R1 对视频内容的深度理解技术,打造 “精彩标题 - 智能封面 - 看点解说 - 爆款衍生” 一站式高光混剪解决方案,可实现高光剧情集锦、精彩内容解说等内容的大规模自动化生产,大幅提升二创视频生产力,有效促进用户消费,为业务增长注入技术动力;
视频 1 点播剧情视频高光智剪流程说明
直播场景:依托 TempSamp-R1 打造的“直播高光智剪”解决方案,以强大的内容理解能力为内容生产注入全新动能;
在体育赛事直播中,该方案支持多语种解说智能剪辑,即时捕捉精彩瞬间,自动生成集锦和吸睛标题,显著提升内容生产效率;
在电商直播场景中,该方案可精准识别商品讲解高光与核心卖点,一键生成引流视频,显著提升直播间成交转化,助力商家实现降本提效与业务增长。
视频 2 赛事直播 &电商直播高光智剪流程说明
「V-Orbit」音视频 AI 应用广场:是火山引擎视频云智能媒体产品线聚焦音视频处理工具 + AI 应用的平台。平台全面覆盖视频直播、视频点播、企业直播及 ImageX 产品线的所有 AI 能力,您可以一站式使用所需的音视频图片处理工具,体验上文介绍的短剧高光智剪和直播高光智剪、视频处理智能体 Aideo Agent、智能播放器 Aideo player、AI 视频翻译、无痕字幕擦除、电商万创等热门应用,详情可访问:https://www.volcengine.com/experience/vcloudlite/ai。
图 10「V-Orbit」音视频 AI 应用广场页面
火山引擎多媒体实验室的前沿探索
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
关于火山引擎
火山引擎是字节跳动旗下云和 AI 服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和应用工具开放给外部企业,通过云和智能技术帮助企业构建体验创新、数据驱动和敏捷迭代等能力,推进企业 AI 转型,激发增长潜能。
简历投递或者项目合作可联系:jiaoshaohui@bytedance.com




