

大家好,我是贝壳找房的孙拔群,今天给大家带来的是基于事理图谱的智能培训,我将从以下五个方面来跟大家进行分享。
贝壳找房实体图谱进展
贝壳找房事理图谱进展
知识图谱在智能培训的应用
知识运营闭环的建立
贝壳找房行业图谱未来思考
贝壳找房实体图谱进展
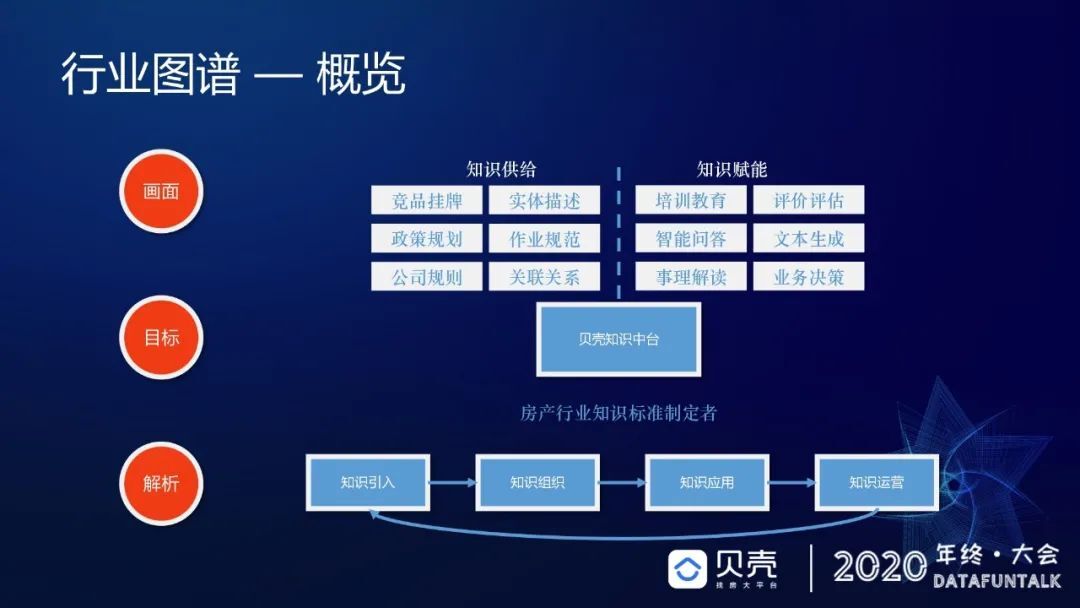
首先,我们团队希望通过知识引入、知识组织、知识应用和知识运营这四个步骤成为贝壳的知识中台,进而成为房产行业知识标准的制定者,通过知识的供给为业务赋能。2018 年我们面临这样一个问题:链家向贝壳找房这样一个平台化演进,我们有很多数据上的问题回答不了。所以我们希望通过大量的知识引入,能够让我们更加深入理解行业的全貌。所以我们设定了这样一个目标:通过引入的更新覆盖主流的房地产业务,包含一些重点实体信息,并对引入的数据进行知识分层,经过清洗融合挖掘之后,提供有价值的业务数据,形成我们的情报系统。
1. 知识引入
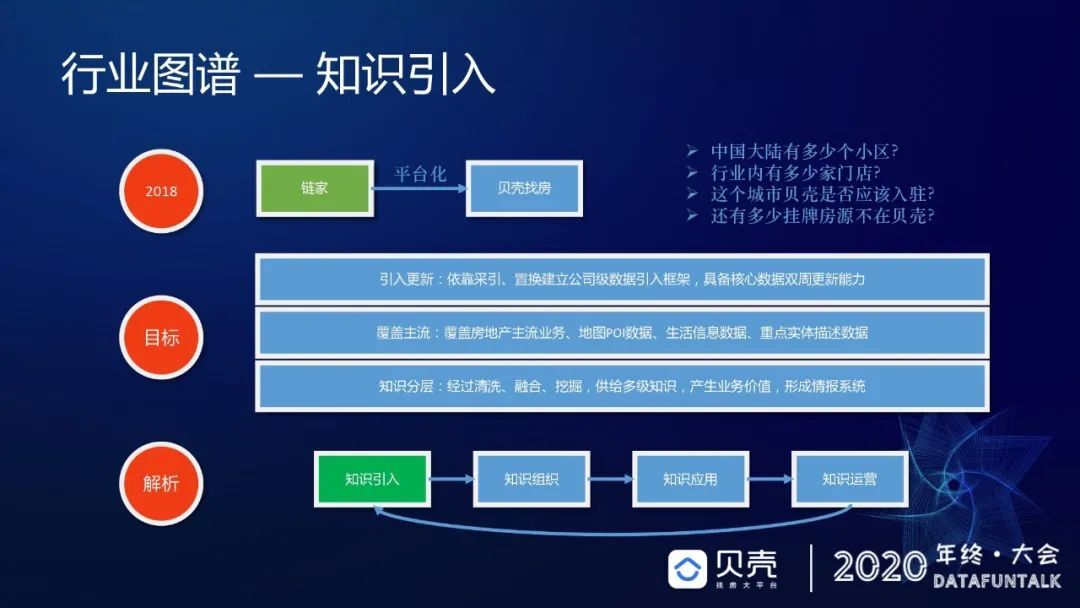
我们需要对所有的数据进行三个级别的知识融合:第一级别是获取跟外界交换过来的基础数据;第二级别是进行一些简单的清洗融合;第三级别是根据业务对数据进行非常深层次的挖掘。随着级别的加深,数据的量级会越来越小,但是每个单条的数据价值会更高,这样就可以通过这些数据形成一个情报系统。我们将这样的情报系统分为三个部分:提效、增量和决策,分别应对了我们三种主要的业务需求场景。两年以来,我们的数据仓库累计支持了大概 10 条线,24 个中心和 50 多个部门。
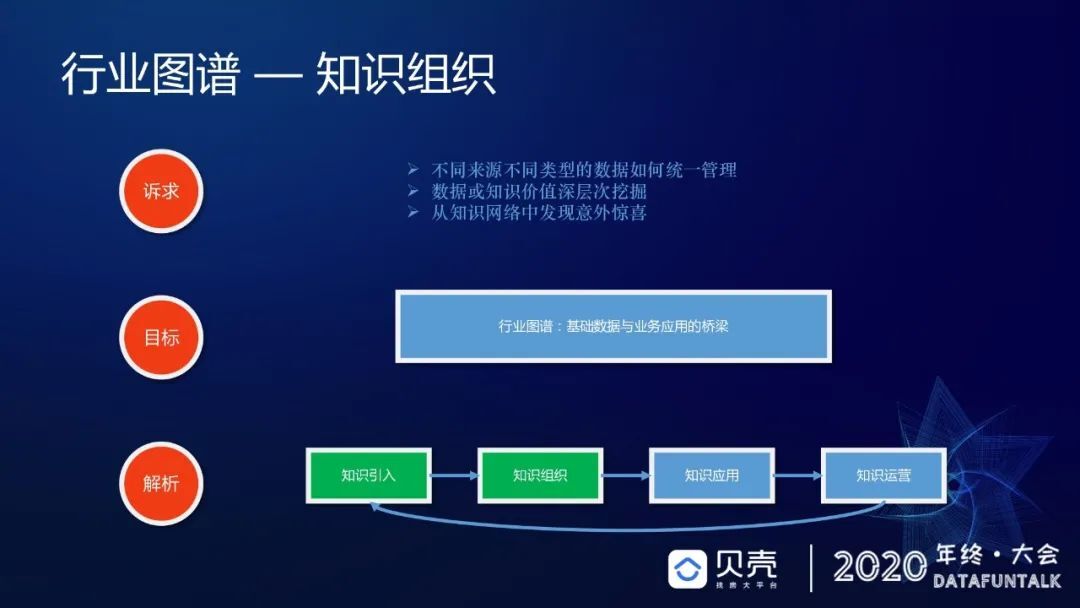
我们获取了大量知识,会面临各种各样的不同诉求:不同来源不同类型的数据怎么统一管理;数据和知识价值的深层次挖掘怎么实现;知识来自方方面面,怎样从中发现和获取种意外之喜。面对这些诉求,我们选择知识图谱作为基础数据业务应用的桥梁,希望通过知识图谱,能够将所有的知识进行一个合理的组织。
2. 知识组织
经过两年的建设,我们将公司所有的知识分为五个方向:第一是实体基础知识,比如说房源小区类的知识;第二是作业规范知识,比如说二手和新房的带看等线上作业规范;第三是公司规则知识,比如链家经典的 ACN 经纪人协作网络,基本上颠覆了经纪人合作模式;第四是政策解读知识,比如哪里要修地铁,哪里的小学变更入学政策,这些都算政策解读知识;第五是以上所有知识的关联性。形成了一个包含 60 多个实体类型,总计规模在 400 多亿,接近 500 亿量级的知识图谱。

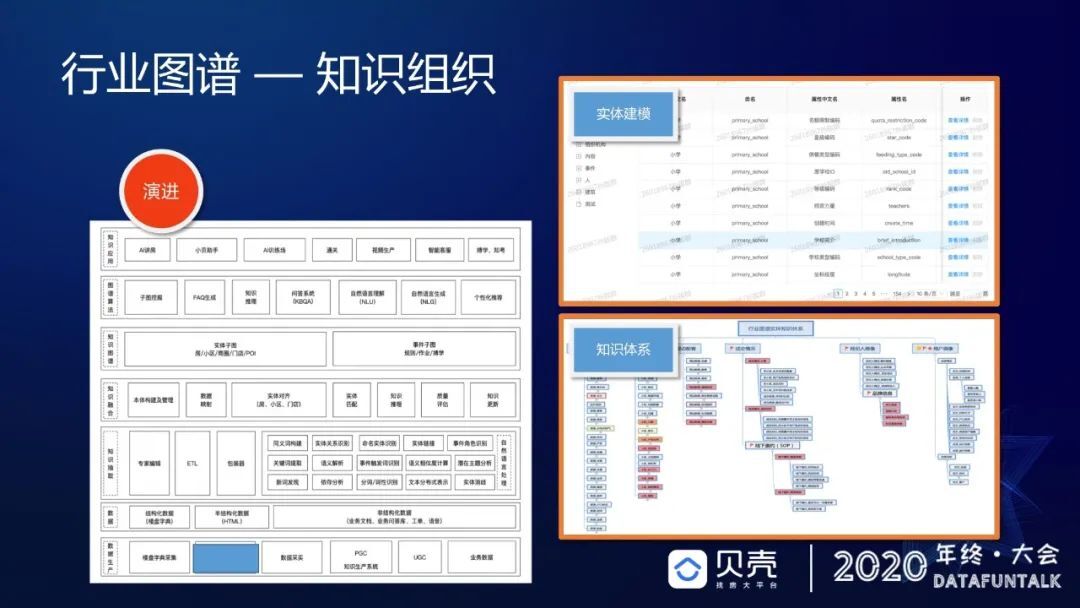
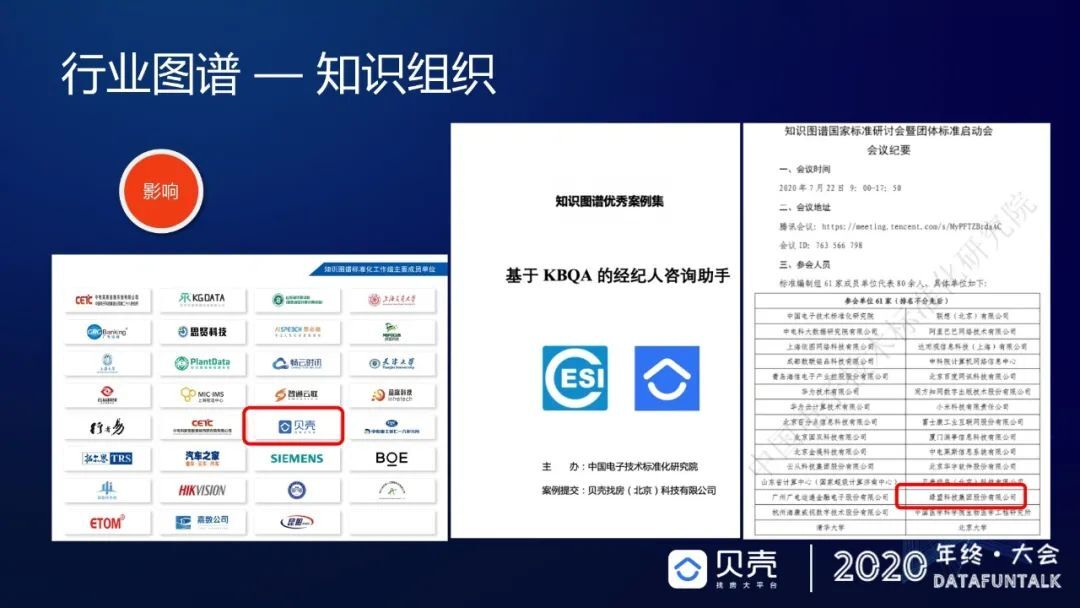
但是知识图谱的质量是不容易评估的,通过不断的去优化、去集中、去聚焦所有的知识含量,把这个规模变小了,但体验反而更好。我们建立了一个实体建模基础工具及一些其他的配套工具,能够极快的加速所有的知识库建设过程。2020 年 7 月份,中国电子技术标准化研究院邀请贝壳一起进行知识图谱国标的建设。
贝壳找房事理图谱进展
1. 需求

我们的事理图谱从 2019 年开始做,但是对于一些深交互的问题,通过规则是不能很好的处理。举个例子:某小区附近幼儿园的属性和入学条件,在第一层次上的回答是:小区附近向东走 500 米,有个开心幼儿园,走路五分钟即可到达,这是实体图谱直接可以解答的。但是用户对于每一套房的每一个居住属性,他的诉求都非常的深入,他想要的结果不仅仅是这些,比如说再加深一层:幼儿园是什么属性?是一级一类公立幼儿园。我们需要对公立幼儿园代表的含义进行解读,然后又引申出普惠幼儿园和非普惠幼儿园有什么样的优缺点,进而明确客户买这套房之后,凭借怎样的条件能够入学,这直接影响了客户能否进行购买。客户购买之后,读了幼儿园之后和直升小学的规则,这个问题越来越深,已经不能单纯依靠基于这套房或者基于个人的一些知识就能够完成,所以在这个层面上,一方面对实体图谱的质量要求越来越高,另一方面需要有事理解析的能力。针对于这种场景,我们通过重点业务去优化若干个实体子图,再去新建几个事理子图,最后通过运营机制去保障数据质量。
2. 方法
对于如何实现,我们的方法设定是:通过一套构建工具去复现 schema 和 data 的集合,然后放在业务中去应用,呈现出一些知识算法,利用数据质量的评测体系,可以不断的去形成数据的质量提升闭环。
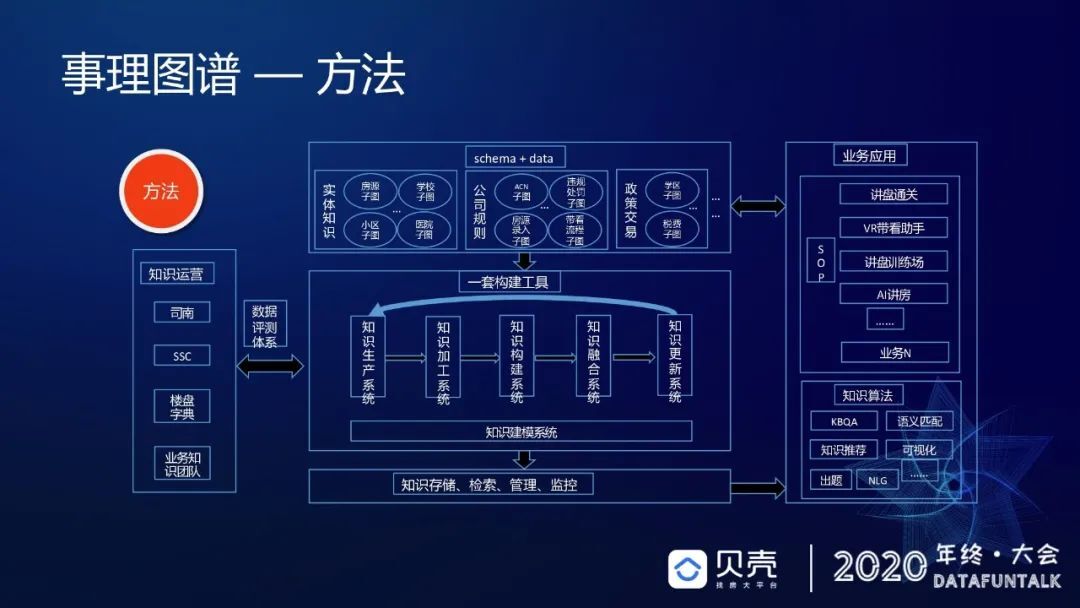
举个例子(如下图所示),在事理图谱中,对于诉求,很多时候是人工拆解,所以我们设立了这样一个工具,它能够实现通过左边纯文本的方式转换成右边有点像决策树或者事理子图的方式。

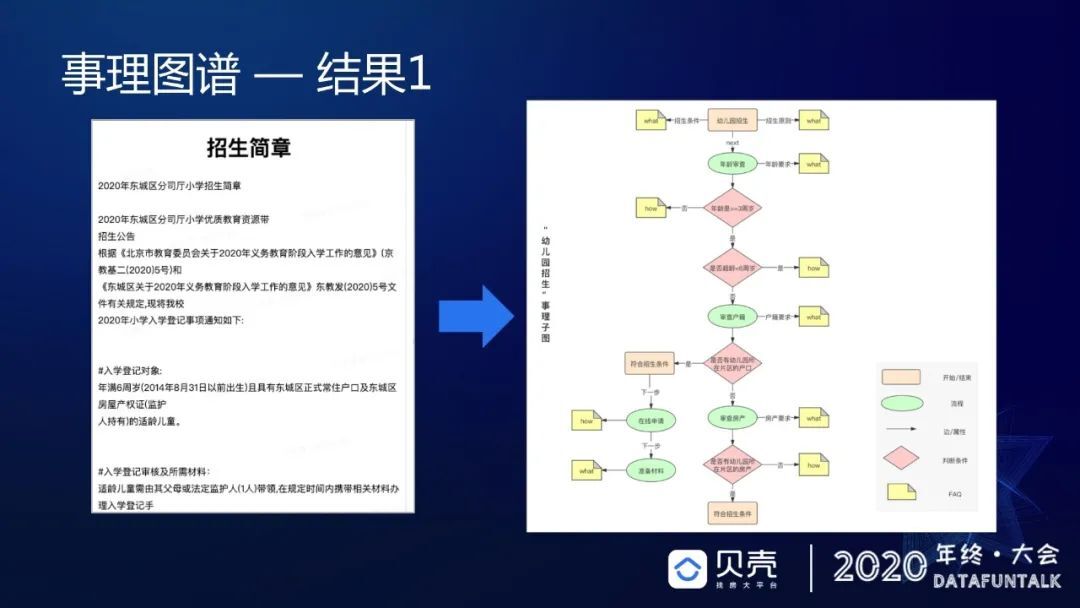
刚才介绍了学区的例子,现在来介绍在税费计算上的应用。在购房的时候一般接触的是契税是多少、有没有增值税等,实际上国家对于房产交易的税费,有很多细节,只是一般人接触不到。但经纪人在为客户服务时,对估算税费的准确率是有严格要求的,如果估算错,差额震荡超过百分之几,就要全额赔付客户。所以对于我们来说挑战比较大,针对这一诉求,我们进行了专项的事理图谱的推进。我们在建设事理图谱时,不只建设事理图谱,还将事理图谱和实体图谱相结合,并且不断地下钻。举一个例子(如下图),这里面涉及到 4 个税种,个人所得税、契税、增值税和增值税附加,每个税种在开始计算的时候,通过第一层级的子图推演,对于每一个绿色标签,可以继续向下推演它的规则是什么样,这个人符合什么样的一个前进路径。比如对于个人所得税契税,可以继续向下推演,可以生成一个事理子图,生成事理子图之后,我们可以将所有规则去挂靠到每一套房源,然后去映射成几种用户类型或者几种业主类型,这样就可以将事理图谱的结果直接映射成最容易使用的 3 元组释放到 KBQA 或者是其他的场景里面去使用,可以极大的方便作业过程,也能够提升准确率。
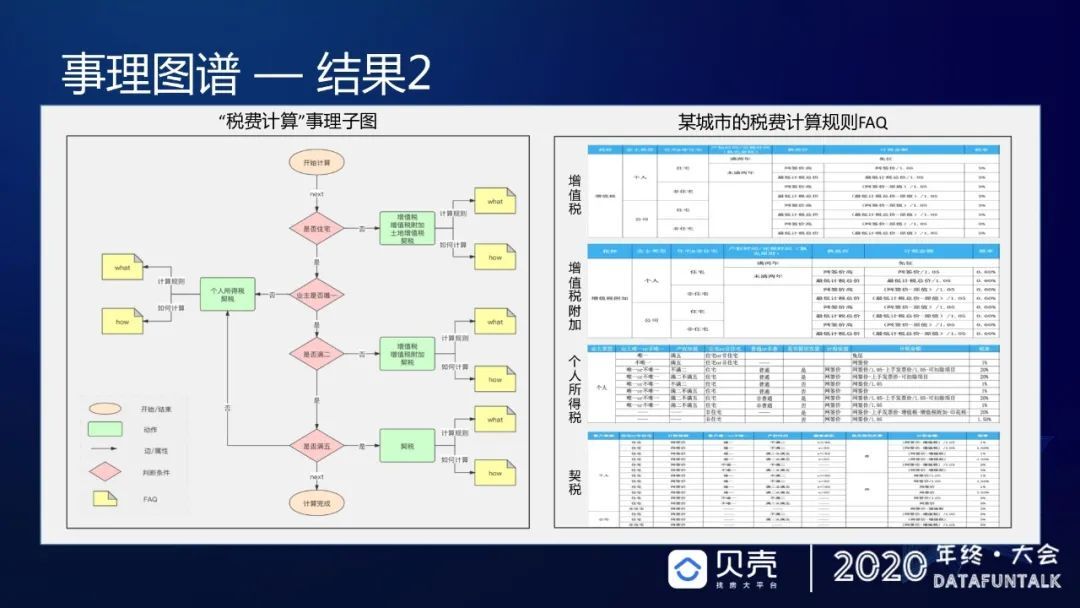
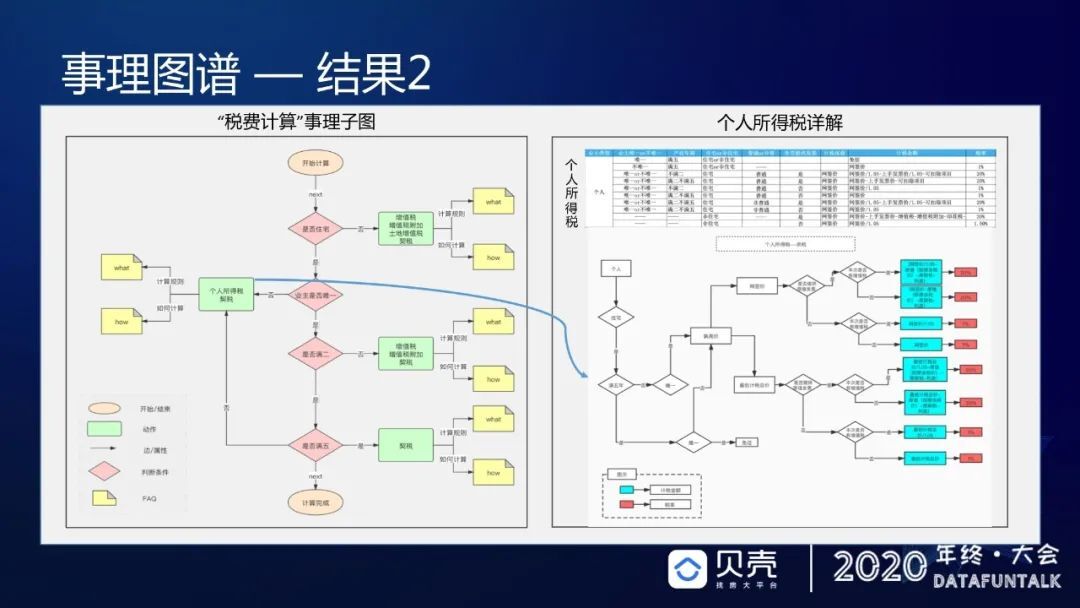
这个工作我们持续了 4 个月左右,学区事理子图现在已经可以覆盖北京市 140 多个学区的规则、90%的社区和 80%的房源;税费事理子图现在已经覆盖全国 17 个城市的税费规则、100%的房源,经专家测算准确率基本上达到 100%。

知识图谱在智能培训的应用
前面都是图谱的构建过程,在做好这样一个知识图谱之后,我们希望它能够在一些应用上落地,只有这样才可以去评估图谱的质量,知道里面的数据价值,同时也能知道该如何去优化,使其变得更好。知识图谱属于基础建设,一般都是螺旋迭代式发展,有时候需要独立的去做这种平台式的,有时候又需要强业务去牵引去提升自己的整体质量。
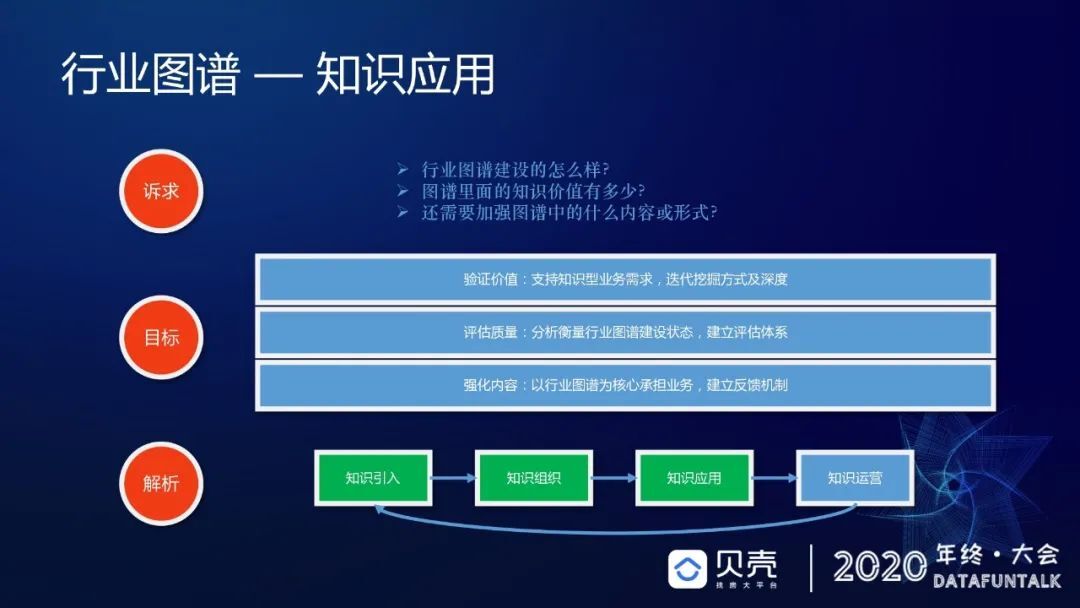
在 2020 年下半年阶段,就属于需要业务去牵引强化内容的阶段,所以我们做了很多业务上的应用,然后去发现数据质量效果。举几个例子(如下图),这些都是线上去作业的经纪人常用的一些知识层面的诉求,在这里面会思考一个问题,在做知识图谱的时候,它每一个业务都需要知识,但是知识图谱真正适用于什么样的需求,或者说哪一个业务真正的需要用知识图谱去提升自己的能力,所以我们在不断地寻求类似的应用诉求。

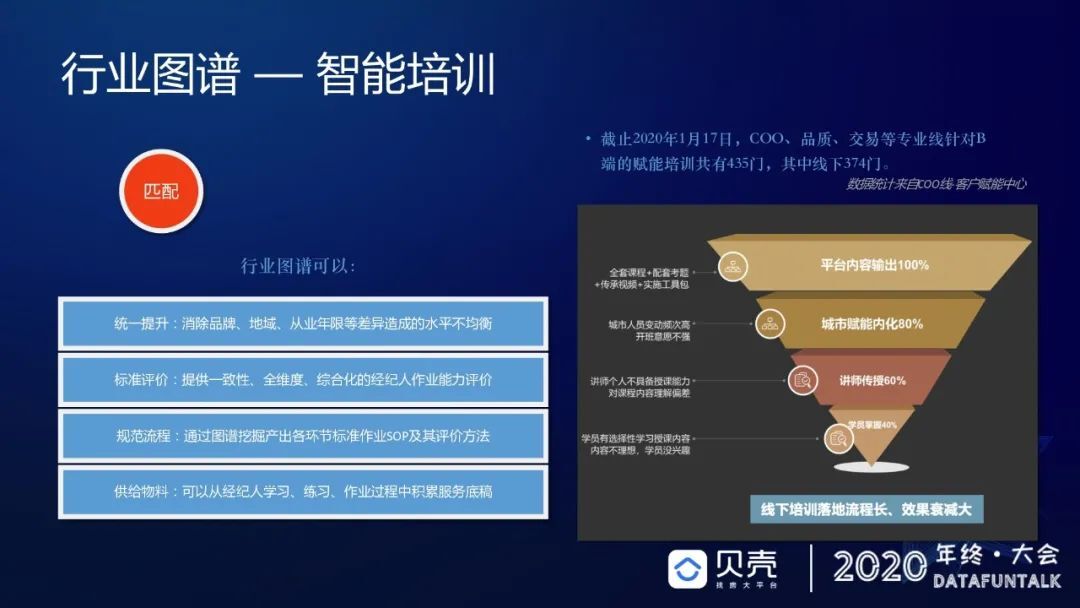
2020 年初,我们接到智能培训的业务需求。ToB、ToC 服务类公司,对培训的诉求非常高,过去都是纯线下的培训,我们统计过贝壳现有 435 门赋能培训,其中线下培训有 374 门,线上都集中在上面的那种规则类的培训。线下的人对人培训效率非常低,对专家的能力要求也非常高,所以说差异性非常高,导致线下培训不太好做。在这个过程中,我们思考行业图谱可以提供什么,第一可以统一的提升消除各种因素造成的水平不均衡;第二可以提供标准的评价方式,提供一致性全维度的作业评价能力;第三可以规范化作业流程;第四可以积累很多的作业优秀物料,可以在未来的作业过程中直接使用。
2020 年 2 月份我们开始启动基于行业图谱智能培训业务,智能培训一共经历了 4 个阶段,第一个阶段是产品化,通过行业知识图谱的讲盘知识和标准评价能力去产品化落地到讲盘训练场,讲盘训练场通过数据的反馈和提供的优质内容,为行业知识图谱做加强。
举个例子,如何去加强行业知识图谱,知识图谱落地到讲盘训练场应该都能理解如何去做,那么如何反馈呢?在做重的 ToB 业务的时候,会发现定点的知识很难去系统性的收集,比如各种楼盘的知识,总会有缺少,有的地方特别稠密,有的地方特别稀疏。在培训过程中要求经纪人要想参与培训,就要贡献这样的资料,经过两个星期的迭代,基本上收集了北京市 7000 多个小区的所有数据,而且数据质量非常高。

第二个阶段是平台化,我们发现不仅在二手讲盘有培训的诉求,在新房讲盘、招聘讲盘甚至业主面访都有非常相似的诉求,这些诉求对于技术上的挑战并不大,基本上都是一样的,就是提供一个简单的问答,加一个评价就足够了,经纪人也非常喜欢这种培训过程快,反馈效果也快的过程。

第三个阶段是场景化,在培训过程中,发现做得不够深入,跟不上经纪人的进步速度,所以就挑选了其中一个场景做深入的场景化,选的是公司特色场景-VR 场景,并做了两步认证:基础认证和专家认证,可以这么认为,前面的属于基础教育,VR 属于精英教育。
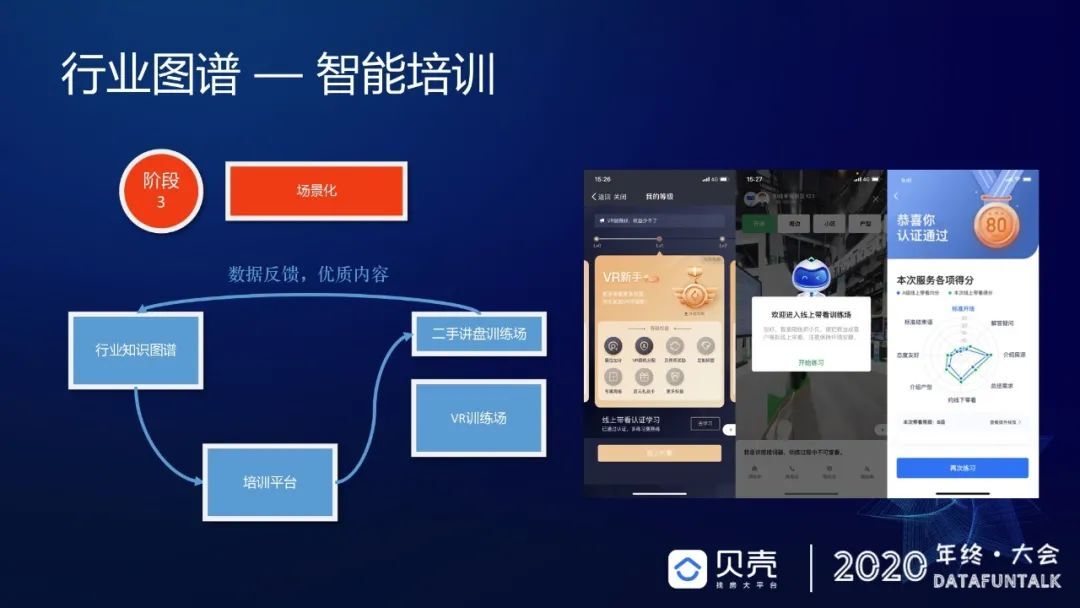
第四个是模块化,做完场景化之后,发现很多能力都可以去复用给其他的业务,比如很经典的评价能力,除了在培训里面能用,在作业过程中可不可以用,在作业之后可不可以用?这是一个复用。再有就是在做培训的时候,有一个天然诉求:要梳理整个业务的所有作业流程,而且这个过程是非常标准的,是完全符合公司专家对于业务的系统性理解。所以我们可以把整个内容加上能力全都发放给其他的业务产品。
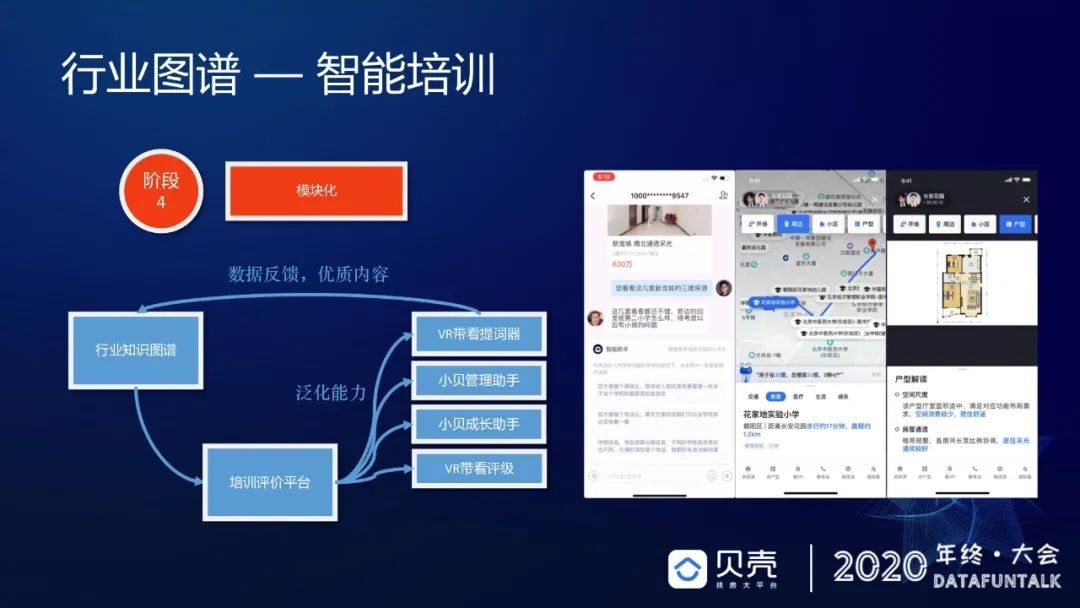
经过 4 个模块之后,大概有 3 个版本迭代上线,之后去采访一些经纪人,他们对于讲盘能力的提升,还是比较认可的。对于业务上的表现,我们长期监控了一些分公司的业绩表现(如下图),确实能够看得出来,参与讲坛智能培训的人中成绩好和成绩不好的人,表现如灰色的柱状图,他们的累积业绩差会越来越高,越来越大。其实这只是做一个证明,因为我们都知道只要你学习,你就会进步,但是进步是一种定性的描述,但是定量描述没有办法做到,所以我们在尝试建立一种定量的归因方式。

知识运营闭环的建立
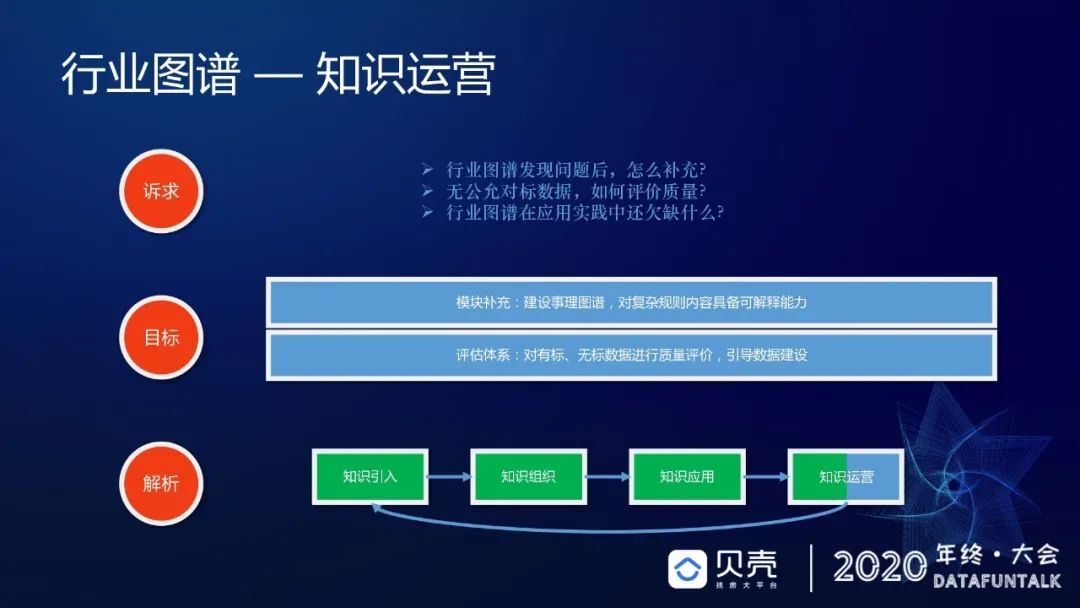
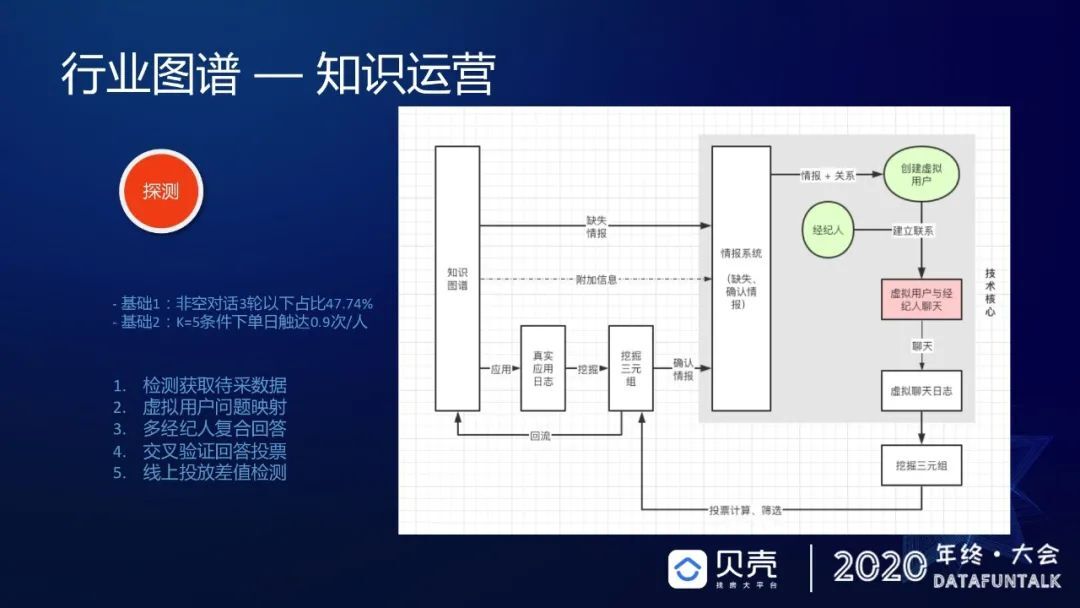
前面讲过,在做知识图谱或者知识建设的时候,会存在一个问题,即很难去评价知识质量,通常会利用人工标注的方式去评估,但是对于没有公允对标数据,该怎样评价数据质量呢?因为没有找到权威性的人去告诉你什么样的数据是对的,还有就是在应用实践中欠缺哪些点,这些可能也是需要通过在应用中得到我们欠缺的一面,对于如何获取这些点,我们设立运营目标:第一是加强事理图谱;第二是建立完备的评估体系,对于有标和无标数据进行质量评估,进而引导数据质量建设。我们有这样一个机制,通过行业图谱在业务上的应用,会发现质量评价的方式分为这样几个部分:第一是空值检测,第二差值检测,第三是用户引导,第四是主动探测,第五是抽样标注,下面分别来解释一下这几个部分。
空值检测和差值检测都是应对于高频的 B2C 客服过程,因为我们这个行业 B2C 的交互频率非常高,类似于微信、企业微信或者钉钉这类 IM 通讯工具。针对用户和经纪人之间的交互非常频繁,我们做了一个插件,当用户问一个问题之后,我们会给一个提示,说这个答案大概是什么,然后你可以采纳,也可以不采纳。如果经纪人不采纳,我们就要分析这个原因:有可能是因为答案错了,或者是答案不好,我们再去分析这样的归因,会找到这样一个分布:明确有多少的问题是在 B2C 过程就验证了问题是不对的。至于为什么不去直接采用人工标注,因为这些标注的人不如经纪人专业,另外它的量级也赶不上经纪人量级,我们直营的经纪人大概有 40 万左右,这个量级已经非常大了,任何标注公司都是跟不上的。在这个过程中我们知道哪些数据是重点被提及的,如果再去做采集标注的话,应该是一些抽样的方式,所以没有办法去直接在一线上得到价值最大化。
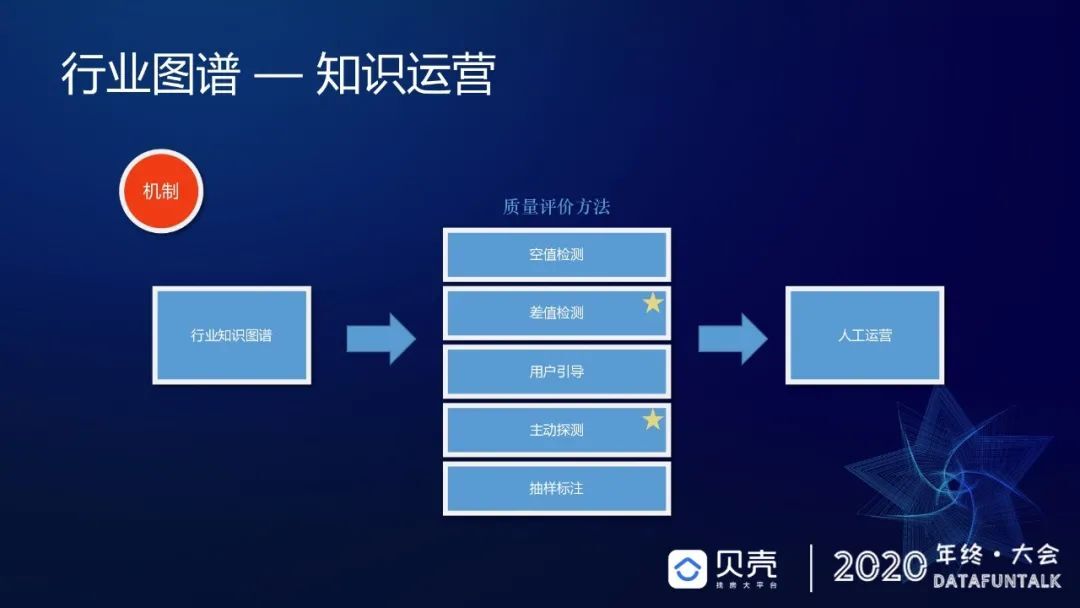
主动探测,我们每天大概去发布这样一些信息,直接触达经纪人,问他们楼盘的信息到底是什么,获取一些结果,再根据加权的 PV 找到人工运营,帮我们补充这样的数据。
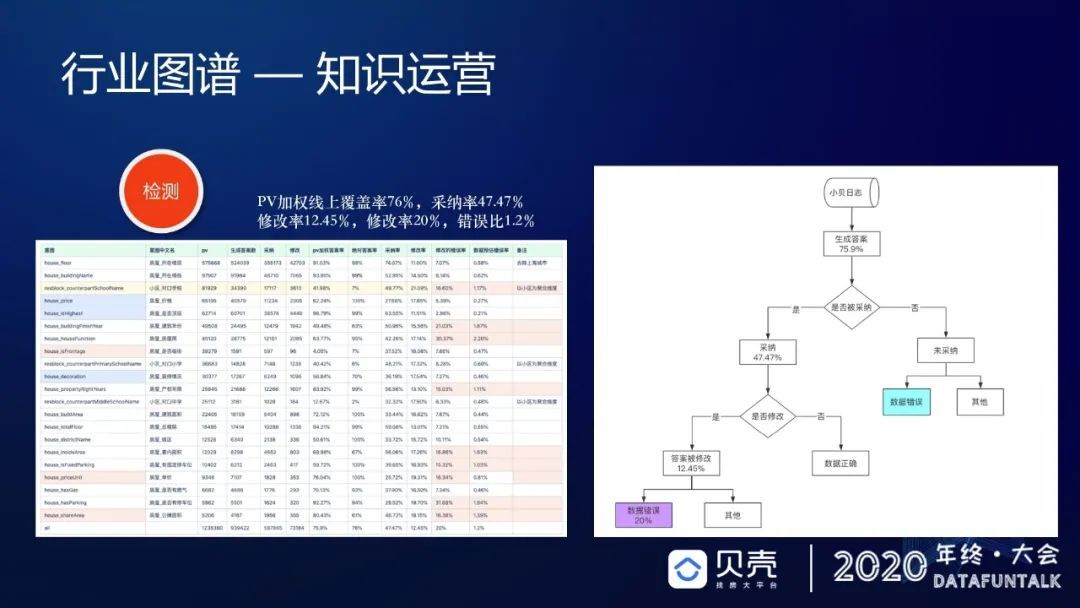
这里详细介绍一下检测过程,PV 线上加权已经可以覆盖整体数据的 76%,采纳率不到 50%。这样我们就可以不断地下钻,找到最后的错误比大概在 1.2%,对于这 1.2%的错误比,我们可以预估在核心数据里面,数据准确率的天花板大概在 98%左右。我们探测的时候发现,47.74%的量级大概是不到 20 万,通过五折交叉验证,触达经纪人大概只需要每天 0.9 次,所以这个价值还是比较足够的,通过这样的链路去直接触达经纪人去进行知识运营的探测。
贝壳找房行业图谱未来思考
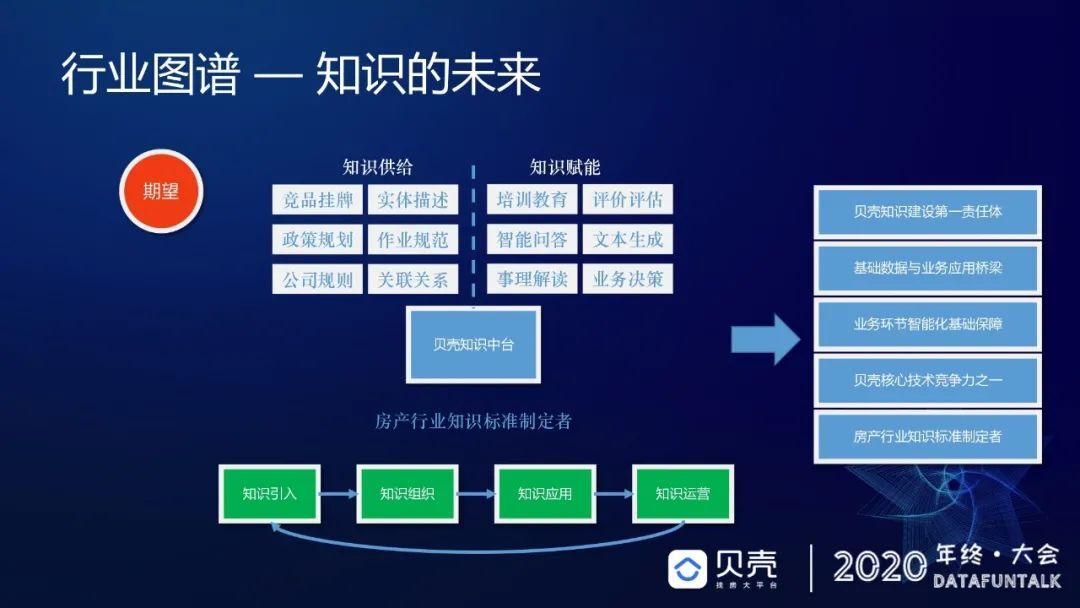
下面跟大家分享一下我们对于贝壳找房行业图谱的未来思考。前面讲到我们希望能够成为贝壳的知识中台,进而成为房产行业知识的标准制定者。在竞品、实体、培训教育评估问答的知识赋能过程中,可以成为贝壳知识建设的第一责任体,进而成为贝壳的核心竞争力。这个是我们对内的宣扬,但是对外的话,我们希望对房产行业这种深度非常深的服务行业去做一个知识标准的贡献。

对于我们重点业务的思考,大概从 6 个角度去分析培训平台:
第一是对于目标受众的一个思考,我们尝试了两种类型,一个是基础教育,一个是精英教育,对于我们这种流动性高的行业,基础教育的 ROI 会更高。
第二是关于内核体验的,问答式的优点就是快,只做 QA。交互式就是 AQA、QAQA 这种类似于对话机器人的一个过程,体验肯定是交互式的好,但是交互式的做起来比较麻烦,不过我们在未来还是会重点向交互式方向发展,因为我们的场景更复杂,如果是纯功能、纯政策类的,可能用问答式更适合。
第三是在做业务发展的时候,选择一个什么样的方向,我们在做前面讲盘以及新房二手都是向平台化发展,在做 VR 的时候,我们做的是场景化的发展,这个跟基础教育和精英教育是比较类似的,它独特的点是场景化对于 SOP 的确认路径要求更高,对于推广速度要求更高,所以在这个业务里,我们可能会优先平台化,其次场景化,大概 7:3 的配比,不同行业可能有不同的发展方式。
第四是过去我们培训衍生出很多能力,但大都是向外去输出,之后可能会多与其他的作业方面去进行多项联动,这也是大势所趋,毕竟我们不是做纯教育的。
第五是如何去推广培训,一个是打口碑,就是不断积累口碑,一个是有快速的应急反馈,但是这些都建立在一个条件之上,就是我们去做这件事情的时候,需要一些运营节奏的手段去配合。
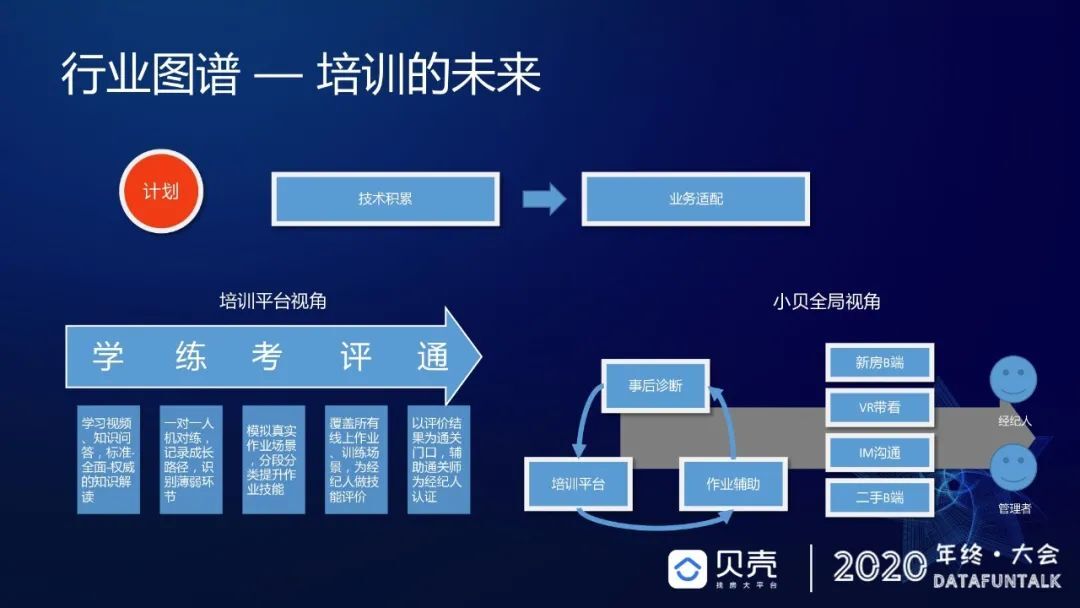
第六是之前我们只关注单点诉求,而对于一个人来说,他做一些技能的方方面面都要去考虑,这将是下一阶段的一个转变,在未来我们会深化培训平台,让这样一个链路成为经纪人的成长通路。对于多向联动,和小贝在培训、作业辅助、事后诊断等方面应用到我们的业务中,最后触达经纪人和管理者。
嘉宾介绍:
孙拔群
贝壳找房 | 高级技术经理
孙拔群,毕业于哈尔滨工业大学,曾就职于腾讯、搜狗、微博等大型互联网公司以及创业公司,2018 年加入贝壳主持建设贝壳房产知识体系,通过数据引入、知识加工,建立了有贝壳特色的行业知识图谱。同时,通过知识对业务赋能,支撑贝壳知识型业务,作为公司主打智能化产品—小贝助手智能培训方向负责人,专注于提升经纪人专业技能,打造培训评价平台。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:贝壳基于事理图谱的应用与实践

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论