
Google DeepMind 宣布推出 EmbeddingGemma,这是一款拥有 3.08 亿参数的开源嵌入模型,专为在本地设备上高效运行而设计。借助这一模型,RAG(Retrieval-Augmented Generation,检索增强生成)、语义搜索、文本分类等应用无需依赖服务器或网络连接,也能顺畅运行。
EmbeddingGemma 采用 Matryoshka 表征学习方法,使嵌入向量可以灵活缩减,同时结合量化感知训练(Quantization-Aware Training),大幅提升了运行效率。Google 表示,在 EdgeTPU 硬件上处理短文本输入时,推理时间可控制在 15 毫秒以内。
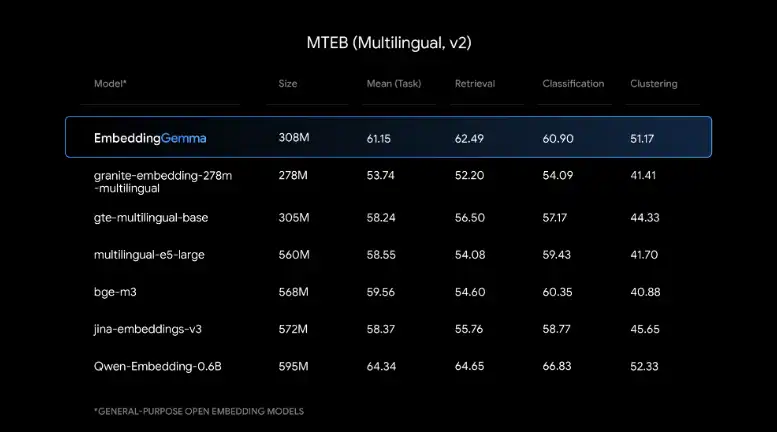
在 Massive Text Embedding Benchmark (MTEB) 测试中,EmbeddingGemma 以不足 5 亿参数的体量,拿下了同类开源多语言嵌入模型的最佳成绩。它支持 100 多种语言,量化后内存占用不足 200MB。开发者可以根据需要,将输出维度在 768 到 128 之间灵活调整,在性能和存储之间找到平衡,同时保证模型质量不打折。
Google 将 EmbeddingGemma 定位于离线和隐私敏感的使用场景,例如本地搜索个人文件、在移动端运行基于 Gemma 3n 的 RAG 流程,或开发特定行业的聊天机器人。模型也支持微调,便于开发者针对特定任务进一步优化。目前,它已经与 transformers.js、llama.cpp、MLX、Ollama、LiteRT 和 LMStudio 等工具完成集成。
在 Reddit 上,用户也分享了对嵌入模型的实际用途的看法:
有人能跟我说说嵌入模型到底能干啥吗?我懂它能用在一些场景里,但它们具体是怎么发挥作用的呢?
用户 igorwarzocha 回复称:
除了那种大家都知道的搜索引擎,其实你也能把它塞在大模型和数据库中间,当个打杂的助手。有些写代码的工具已经这么玩了。只是不确定它是真能帮上忙,还是只是让大模型更迷糊。
我玩过一阵子,把它当成“匹配器”,用来把描述和关键词配起来(可能是反过来?我忘了),这样就能在素材库里自动找到对应的图片,不用我一张张手动翻。效果还行吧,但最后我还是选择自己生成定制图片。
Google 方面则强调,EmbeddingGemma 不仅适用于搜索,还可应用于离线助手、本地文件检索,以及隐私敏感行业的专用聊天机器人。由于数据处理全部在本地完成,像邮件或商务文档这样的敏感信息无需离开设备。同时,开发者也能进一步微调模型,以满足特定领域或特定语言的需求。
随着 EmbeddingGemma 的推出,Google 试图为开发者提供更多选择:既可以在本地使用这一高效轻量的嵌入模型,也可以通过 Gemini API 调用更大规模的 Gemini Embedding 模型,用于大规模部署。两者相互补充,形成了覆盖本地与云端的完整产品线。
原文链接:




