

据 Facebook 2020 年第四季度财报披露,截至 2020 年 12 月,Facebook 日活跃用户平均达到 18.4 亿,全年月度活跃用户达到 28 亿,Facebook 应用家族(Facebook、Instagram 等)月度活跃用户平均达到 33 亿。Facebook 的体量如此庞大,由此不难想象,该平台要处理的视频量级有多大。那么问题来了,Facebook 是怎么处理如此海量的视频的?
人们每天在 Facebook 上传数以亿计的视频。为了保证每一段视频的传输质量(最高分辨率和尽可能少的缓冲),不仅要优化我们的视频编解码器以及压缩和解压视频以便观看,还要优化哪些编解码器用于哪些视频。但是,Facebook 上庞大的视频内容也意味着要找到一种有效的方式来实现这一目标,并且不会消耗大量的计算能力和资源。
为解决这一问题,我们采用了多种编解码器以及码率自适应技术(Adaptive Bitrate Streaming,ABR),根据观众的网络带宽选择最佳的收看质量,从而提高收看体验并减少缓冲。不过,尽管 VP9 等更先进的编解码器提供了比 H264 等老式编解码器更好的压缩性能,但它们也会消耗更多的计算能力。如果把最先进的编解码器应用于上传到 Facebook 的每个视频上,从纯粹的计算角度来看,效率会很低。这就是说,我们需要找到一种方法来确定哪些视频需要用更先进的编解码器来编码。
现在,Facebook 通过结合效益 - 成本模型和机器学习模型,解决了对高质量视频内容编码的巨大需求,这使得我们能够优先考虑对观看率高的视频进行高级编码。如果能预测哪些视频将会受到高度关注,并进行编码,我们就能减少缓冲,提高总体视觉质量,让 Facebook 上可能受到流量套餐限制的用户观看更多的视频。
但是,这项任务并不像让最受欢迎的上传者或者拥有最多好友或粉丝的内容跳到最前面那样简单。还有一些因素需要考虑进去,这样我们就可以在 Facebook 上为人们提供最好的视频体验,同时也保证了内容创作者的内容在这个平台上仍然被公平地编码。
过去 Facebook 是如何编码视频的?
传统上,一旦视频上传到 Facebook,就会启动 ABR 过程,原始视频很快就会重新编码成多种分辨率(比如 360p、480p、720p、1080p)。当编码完成时,Facebook 的视频编码系统将尝试使用更先进的编解码器(如 VP9)或更昂贵的“菜谱”(recipe,视频行业术语,用于微调转码参数),例如 H264 veryslow 的配置文件,尽可能压缩视频文件,从而进一步改善观看视频的体验。各种转码技术(使用不同的编解码类型或编解码参数)在压缩效率、视觉质量和所需的计算能力方面存在着不同的权衡。
怎样把工作安排得更好,让每个人的总体体验最大化,已经成为人们最关心的问题。Facebook 有专门的编码计算池和调度器。该方法接受一个附加优先级值的编码作业请求,将其放到优先级队列中,高优先级的编码任务得到优先处理。因此,视频编码系统的工作就是给每项任务分配适当的优先级。这可以通过一系列简单的、硬编码规则来实现。编码任务可以根据几个因素来分配优先级,包括视频是否为授权音乐视频、视频是否为产品视频、视频所有者有多少朋友或粉丝。
但是,这个方法有其缺点,随着新的视频编解码器的出现,需要维护和调整的规则越来越多。因为不同的编解码器和菜谱有不同的计算要求、视觉质量和压缩性能的权衡,所以不可能通过一组粗粒度的规则对最终用户的体验进行全面优化。
或许最重要的是,Facebook 的视频消费模式极不均衡,这意味着 Facebook 视频的上传者和主页在好友或粉丝数量方面存在巨大差异。与迪士尼等大公司的 Facebook 主页相比,播客的主页可能只有 200 个粉丝。摄像师可以同时上传他们的视频,但是迪士尼的视频可能会有更多的观看时间。但是,任何视频都可以得到病毒式的传播,即使上传者只有很少的粉丝。问题在于,不仅要支持受众最广的内容创作者,还要支持各种规模的内容创作者,同时还要承认这一现实,即拥有大量的受众也可能意味着更多的浏览量和更长的观看时间。
输入效益 - 成本模型
这个新模型仍然采用了一套 quick 的初始 H264 ABR 编码,以确保所有上传的视频能够尽快得到高质量的编码。但是,我们改变的是如何计算视频发布后的编码工作优先级。
效益 - 成本模型是根据以下基本观察得出的:
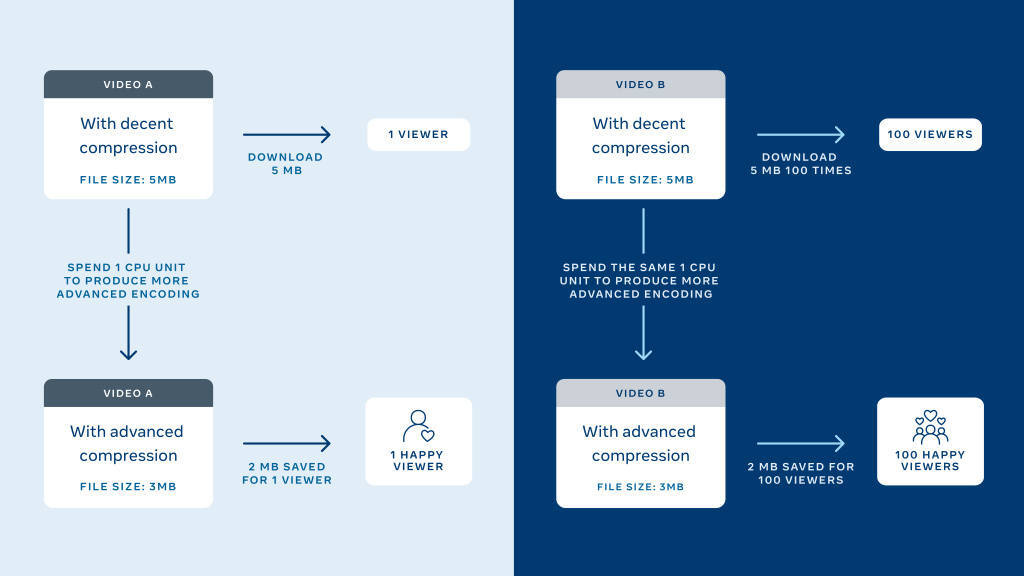
只在第一次编码时,视频才会消耗计算资源。编码完成后,存储的编码可以根据需要多次发送,而不需要额外的计算资源。
Facebook 上的所有视频中,有一小部分(约三分之一)产生了大部分的整体观看时间。
Facebook 数据中心只有有限的支持计算资源的能源。
在现有能源有限的情况下,通过将计算密集型的“菜谱”和先进编解码器应用于最常观看的视频,我们可以使每个人的视频体验最大化。
以此为基础,我们对效益、成本和优先权作出如下定义:
效益 =(固定质量下编码族的相对压缩效率)*(有效预测观看时间)
成本 = 族中丢失编码的归一化计算成本
优先级 = 效益 / 成本
固定质量编码族的相对压缩效率:通过编码族的压缩效率来衡量效益。“编码族”(Encoding family)指的是一组可一起交付的编码文件。举例来说,H264 360p、480p、720p 和 1080p 编码通道构成一个族;而 VP9 360p、480p、720p 和 1080p 则构成了另一个族。在相同视觉质量的情况下,比较不同族间的压缩效率是一个挑战。
为了理解这一点,我们先来看看我们开发的一个指标,即每 GB 数据包的高质量视频分钟数(Minutes of Video at High Quality,MVHQ)。MVHQ 把压缩效率和互联网流量补贴的问题直接联系在一起:对于 1GB 的数据,我们可以流式传输多少分钟的高质量视频?
MVHQ 在数学上可理解为:
比如说,我们有一个视频,用 H264 fast 预置编码的 MVHQ 为 153 分钟,用 H264 slow 预置编码的 MVHQ 为 170 分钟,用 VP9 的 MVHQ 为 200 分钟。这就是说,使用 VP9 编码的视频,在视觉质量门槛较高时,与 H264 fast 预置相比,使用 1GB 数据可以延长 47 分钟的观看时间(200-153)。我们使用 H264 fast 作为基线来计算这个视频的效益值。我们将 1.0 分配给 H264 fast,1.1(170/153)分配给 H264 slow,1.3(200/153)分配给 VP9。
实际的 MVHQ 只能在编码产生后才能计算出来,但是我们需要在编码产生之前就得到它,所以我们使用历史数据估算出给定视频的每个编码族的 MVHQ。
有效预测的观看时间:正如下面所描述的,我们有一个复杂的机器学习模型,它可以预测观众在不远的将来看一段视频的时间。当我们在视频级别上获得预测的观看时间后,我们就可以估计编码族在视频应用的效率。它揭示了一个事实,那就是并非所有 Facebook 用户都拥有能够播放更新的编解码器的最新设备。
举例来说,大约 20% 的视频消费发生在无法播放 VP9 编码视频的设备上。所以,如果一个视频的预测观看时间是 100 小时,那么使用广泛应用的 H264 编解码器的有效预测观看时间是 100 小时,而 VP9 编码的有效预测观看时间是 80 小时。
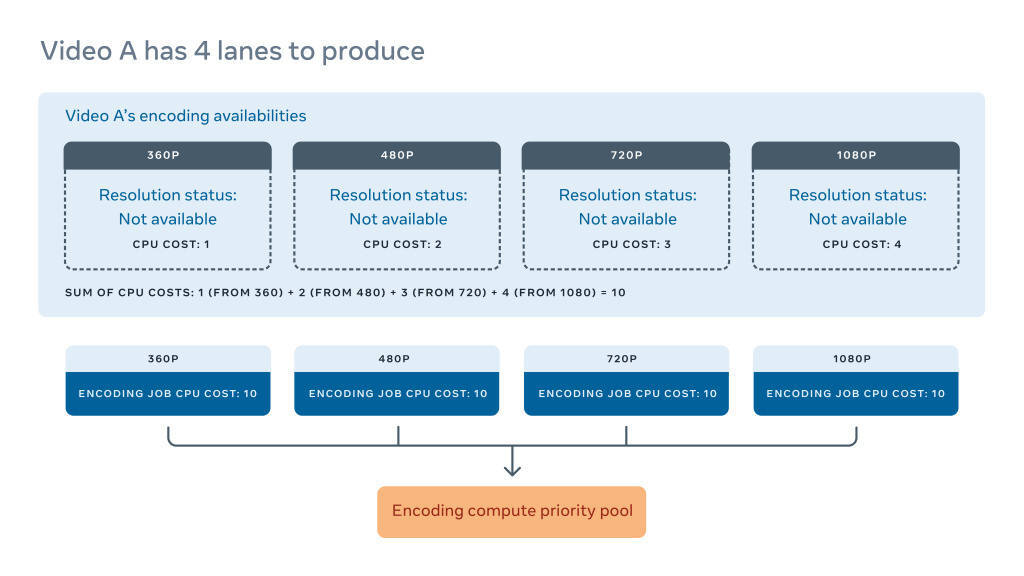
编码族中缺失编码的归一化计算成本:这是我们为使编码族可交付所需的逻辑计算周期量。在交付视频之前,编码族需要提供一组最低的分辨率。举例来说,VP9 族至少需要 4 种分辨率才能编码特定的视频。但一些编码需要比另一些编码更长的时间,这意味着不是所有的视频分辨率都可以同时提供。
举个例子,假设视频 A 缺少 VP9 族中的所有 4 个通道。通过总结所有 4 个通道的估计 CPU 使用量,我们可以为四个任务分配相同的归一化成本。
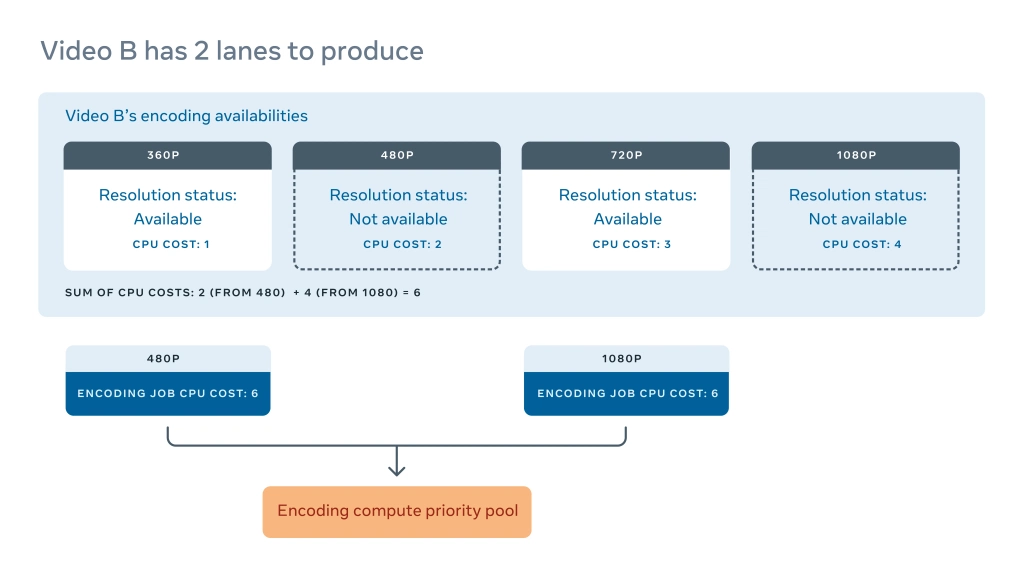
如视频 B 所示,如果我们在 4 个通道中只有 2 条缺失,那么计算成本就是产生其余两个编码的总和。同样的成本适用于两个任务。因为优先级是效益除以成本,所以当更多通道可用时,任务的优先级就变得更加急迫。编码通道直到可交付时才有价值,所以尽快得到完整的通道非常重要。比如说,拥有包含所有 VP9 通道的视频要比拥有 10 个不完整(因此无法交付)VP9 通道的视频更有价值。
通过机器学习预测观看时间
一种新的效益 - 成本模型告诉我们应该如何对某些视频进行编码,下一个难题是如何确定哪些视频应该优先编码。因此,我们现在使用机器学习来预测哪些视频将被观看的次数最多,从而应该优先考虑使用高级编码。
这个模型将考虑一些因素来预测视频在接下来的一小时里的观看时间。它通过查看视频上传者的好友或粉丝的数量和他们之前上传的视频的平均观看时间,以及视频本身的元数据,包括视频的长度、宽度、高度、隐私状态、帖子类型(直播、故事、观看等等)、视频的发布日期、视频过去在平台上的受欢迎程度,来实现这一目的。
但当将所有这些数据都用于决策时,会遇到一些内在的挑战:
观看时间具有高度的差异性,而且长尾效应非常显著。即便我们集中精力预测下一个小时的观看时间,一段视频的观看时间也可能从零到 5 万小时以上,这取决于视频的内容、上传者和视频的隐私设置。这个模型不仅需要能够判断视频是否会受欢迎,而且需要能够判断其受欢迎程度。
下一个小时的观看时间最好的指标是它之前的观看时间轨迹。一般而言,视频的受欢迎程度很不稳定。同一内容创作者上传的不同视频,有时会因为社区对该内容的反应而导致不同的观看时间。通过对不同特征的实验,我们发现,过去的观看时间轨迹是未来观看时间的最佳预测指标。在设计模型结构和平衡训练数据方面,这将带来两项技术挑战:
新上传的视频没有观看时间轨迹。一段视频在 Facebook 上停留得越久,我们就能从它过去的观看时间中获得更多信息。也就是说,最能预测的特征将不适用于新视频。在数据缺失的情况下,我们希望我们的模型也能很好地发挥作用,因为系统越早确定将在平台上流行的视频,就越有可能提供更高质量的内容。
热播视频有控制训练数据的趋势。最受欢迎的视频模式未必适合所有的视频。
观看时间的性质因视频类型的不同而不同。故事视频较短,平均观看时间比其他视频短。在流媒体播放过程中或之后的几个小时里,直播流可以获得大部分观看时间。同时,点播视频(VOD)的寿命也是多种多样的,如果人们后来开始分享这些视频,那么在最初上传之后很长一段时间就可以积累观看时间。
机器学习指标的提高未必与产品改进直接相关。RMSE、MAPE 和 Huber Loss 等传统的回归损失函数对离线模型的优化效果良好。但是,建模误差的降低并不一定会直接导致产品的改进,例如改善用户体验、增加观测时间的覆盖率或者提高计算效率。
构建视频编码的机器学习模型
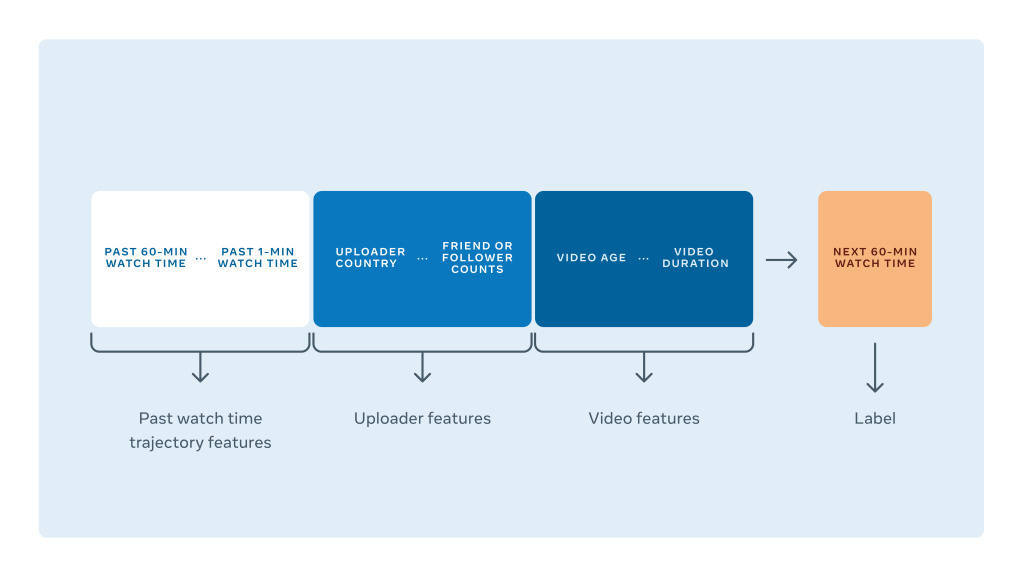
为应对这些挑战,我们决定通过使用观看时间事件数据堆模型进行训练。在训练 / 评估中的每一行都表示一个决策点,表示系统必须对它进行预测。
因为我们的观看时间事件数据会在许多方面出现偏离或不平衡的情况,所以我们对我们所关注的维度进行了数据清洗、转换、桶化和加权采样。
此外,由于新上传的视频没有可供参考的观看时间轨迹,我们决定建立两种模型,一种用于处理上传时间请求,另一种用于处理观看时间请求。视图 - 时间模型使用了上面提到的三组功能。上传时间模型可以看到内容创作者上传的其他视频的表现,并用过去的观看时间轨迹代替。当一段视频在 Facebook 上停留了足够长的时间,并且有了一些过去的轨迹,我们就把它转换成使用视图 - 时间模型。
在模型开发过程中,我们通过研究均方根误差(Root Mean Square Error,RMSE)和平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)来选择最佳发布候选者。由于 RMSE 对异常值敏感,而 MAPE 对小值敏感,所以我们使用了这两种指标。观看时间标签具有较高的方差,所以我们使用 MAPE 评估流行和中度流行的视频的表现,而使用 RMSE 评估较少观看的视频。同时,我们也关注与不同视频类型、年龄和受欢迎程度上的泛化能力。因此,我们的评估也总是包含了每一类别的指标。
MAPE 和 RMSE 是很好的模型选择总结指标,但不一定能直接反映产品的改进。有时候,当两个模型的 RMSE 和 MAPE 相似时,我们也会将评估转化为分类问题,以了解其权衡。例如,如果一个视频获得了 1000 分钟的观看时间,但模型 A 预测的是 10 分钟,那么模型 A 的 MAPE 是 99%。如果模型 B 预测的是 1990 分钟的观看时间,那么模型 B 的 MAPE 将与模型 A 的相同(即 99%),但是模型 B 的预测将会使视频更有可能具有高质量的编码。
同时,我们也对视频分类进行了评估,因为我们希望在过度频繁地使用高级编码和失去使用这些编码的好处之间找到一个平衡点。举例来说,在 10 秒的阈值下,为了计算模型的假阳性和假阴性率,我们计算出实际视频观看时间少于 10 秒且预测时间也少于 10 秒的视频数量,反之亦然。我们对多个阈值进行了同样的计算。这一评估方法使我们能够深入研究该模型在不同受欢迎程度的视频中的表现,以及它是倾向于推荐过多的编码工作还是错失了一些机会。
新视频编码模型的影响
这一新模型不仅提高了用户对新上传视频的体验,而且能够识别 Facebook 上应该使用更高级编码的老视频,并为它们分配更多计算资源。这会把大部分看问题的时间转移到高级编码上,从而减少缓冲时间,而无需额外的计算资源。经过改良的压缩技术还可以让 Facebook 上那些流量有限的用户,如新兴市场用户,观看更多质量更高的视频。
更重要的是,当我们引入新的编码菜谱时,我们不再需要花费很多时间去评估在优先级范围中将它们分配在哪个位置。相反,该模型根据菜谱的效益和成本值自动分配优先级,从而最大化整体效益吞吐量。举例来说,我们可以引入一种计算密集型的方法,这种方法只适用于一些极受欢迎的视频,并且模型能够识别这种视频。总而言之,这使得我们能够继续投资更新、更高级的编解码器,为 Facebook 上的用户提供最好的视频体验。
作者介绍:
Taein Kim,Facebook 软件工程师;Ploy Temiyasathit,Facebook 数据科学家;Haixiong Wang,Facebook 软件工程师。
原文链接:
https://engineering.fb.com/2021/04/05/video-engineering/how-facebook-encodes-your-videos/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论