

本文是一个系列文章的第一部分,阐述了如何基于事件溯源的理念在不影响既有业务的情况下,对单体式的 CRUD 应用进行改造。
本文最初发表于Wix Engineering网站,经原作者Jonathan David授权由 InfoQ 中文站翻译分享。
我们都听过这样的故事:大型的单体应用曾经给我们带来过巨大的业务价值并且很好地为我们的客户提供了服务,但是现在这种方式已经开始拖累我们了。产品的愿景逐渐朝反应式特性演化,这意味着要在正确的背景下对多个领域事件作出实时反应。但是,问题在于我们的单体应用被设计成了一个典型的 CRUD 系统,也就是在状态发生变化时同步运行业务逻辑。
本文是系列文章的第一篇,会讲述如何将事件溯源和事件驱动架构引入到我们的客户支持平台(customer support platform)中,在这个过程中,我们允许逐步迁移,并且在没有将现有功能置于风险之中的前提下,已经开始为我们提供新的商业价值。按照传统的 CRUD 方式进行系统设计时,我们主要关注的是状态以及如何在一个分布式环境中由多个用户进行状态的创建、更新和删除操作,而事件溯源方式关注的是领域事件,它们何时发生以及它们如何表达业务意图。在事件溯源方式中,状态是事件的具体化(materialization),这只是领域事件多种可能的使用方式之一。
客户支持平台是实践反应式能力的一个很好的用例。因为客户代理会处理来自不同渠道的案例,在这个过程中,很容易错失对高优先级案例的跟踪。而事件驱动系统能够单独跟踪每个支持案例,能够帮助客户代理保持对正确案例的关注,并在其他案例需要关注的时候发出告警。这只是众多示例中的一个。另外一个示例是当某个种类的案例在给定的时间段内大量出现的时候,我们就需要采取一定的措施。
Wix Answers 是一个客户支持解决方案,它将工单、帮助中心和呼叫中心等支持工具集成到了一个直观的平台中,具有先进的内置自动化和分析能力。
如果我们能重新开始的话,系统会是什么样子呢?
如果能够重新开始的话,我们会选择事件溯源架构。我不会深入介绍事件溯源架构是什么,如果你想了解更多知识的话,我强烈推荐 Martin Fowler 的这篇较旧的文章和 Neha Narkhede 的这篇较新的文章。
我喜欢事件溯源的原因在于,它将领域事件放在优先的位置,并且以此为中心。如果你仔细倾听客户阐述他们的需求的话,你会经常听到他们这样说:“当发生这种情况时,我希望系统那样做。”实际上,他们是在用领域事件的方式在说话。作为开发者,如果能够理解我们的主要目标就是产生领域事件时,事件就开始步入正轨了,我们就会理解事件溯源的威力。
在讨论我们采取了哪些行动将单体应用变得具有反应式特征之前,我想要描述一下如果没有任何的遗留代码,能够重新开始的情况下,理想的解决方案是什么。我认为这样的话,你就能更好地理解我们所采取的路线以及我们必须要做出的妥协。
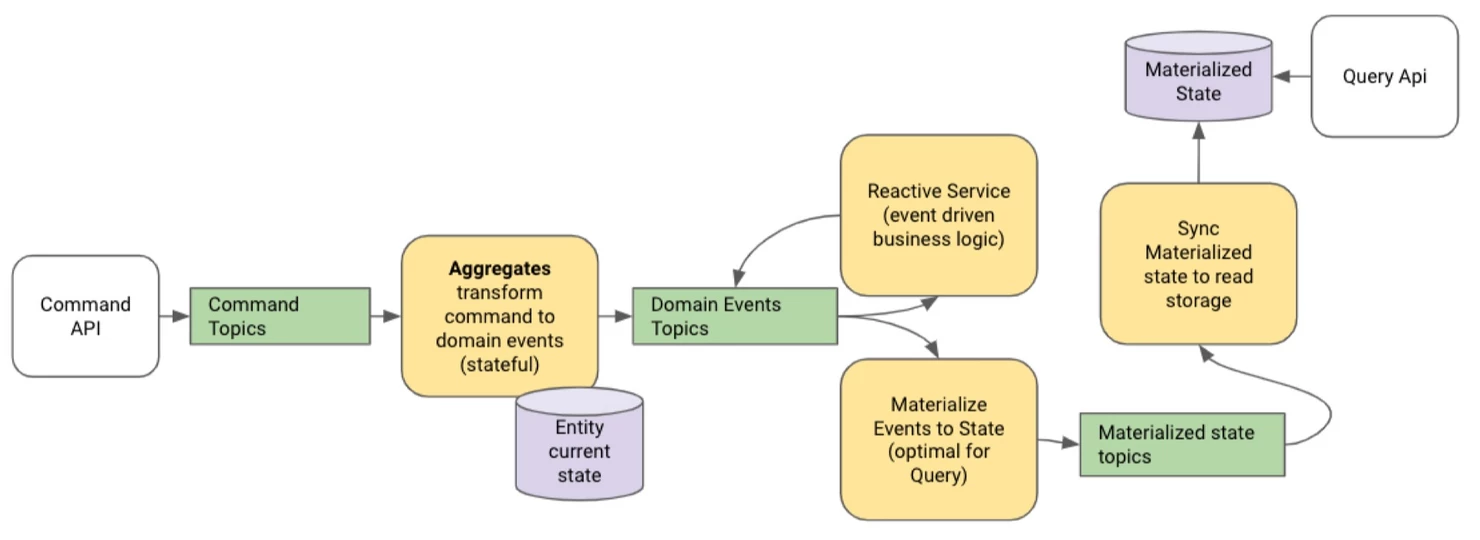
这是事件溯源架构中事件的一般流程:命令(command)是由客户发起的,旨在改变某个实体(通过 entity-id 进行唯一标识)的状态。命令则是由聚合(aggregate)处理的,聚合要根据当前的实体状态决定接受或拒绝命令。如果一条命令被接受的话,聚合要发布一个或多个领域事件同时要更新当前实体的状态。我们必须要假定聚合能够访问到最新的实体状态,并且没有其他的进程正在并行地对特定的实体 id 进行决策,否则的话,我们就会面临状态一致性的问题,这是分布式系统所固有的问题。由此可见,实体当前状态(entity-current-state)的存储是实体真实情况的来源(source of truth)。实体其他形式的表述最终都将是一致的,这是基于事件的具体化实现的。
使用 Kafka Streams 作为事件溯源框架
有很多相关的文章讨论如何在 Kafka 之上使用 Kafka Streams 实现事件溯源。我认为关于这个话题还有很多需要讨论的,但是我会在一篇单独的文章中进行讲解。现在我只想说,Kafka Streams 使得编写从命令主题到事件主题的状态转换变得很简单,它会使用内部状态存储作为当前实体的状态。内部状态存储是一个由 Kafka 主题作为备份的 rocks-db 数据库。Kafka Streams 保证能够提供所有数据库的特性:你的数据会以事务化的方式被持久化、创建副本并保存,换句话说,只有当状态被成功保存在内部状态存储并备份到内部 Kafka 主题时,你的转换才会将事件发布到下游主题中。如果采用 exactly-once 语义的话,这一点是能够得到保证的。通过依靠 Kafka 的分区,我们能够保证某个特定的实体 id 总是由一个进程来处理,并且它在状态存储中总是拥有最新的实体状态。
在我们的单体 CRUD 系统中,是如何引入领域事件的?
我们首先要问的是,真实情况的来源是什么。我们的单体系统通过 REST API 接收变更命令,更新 MySQL 实体,然后返回更新后的实体给调用者。
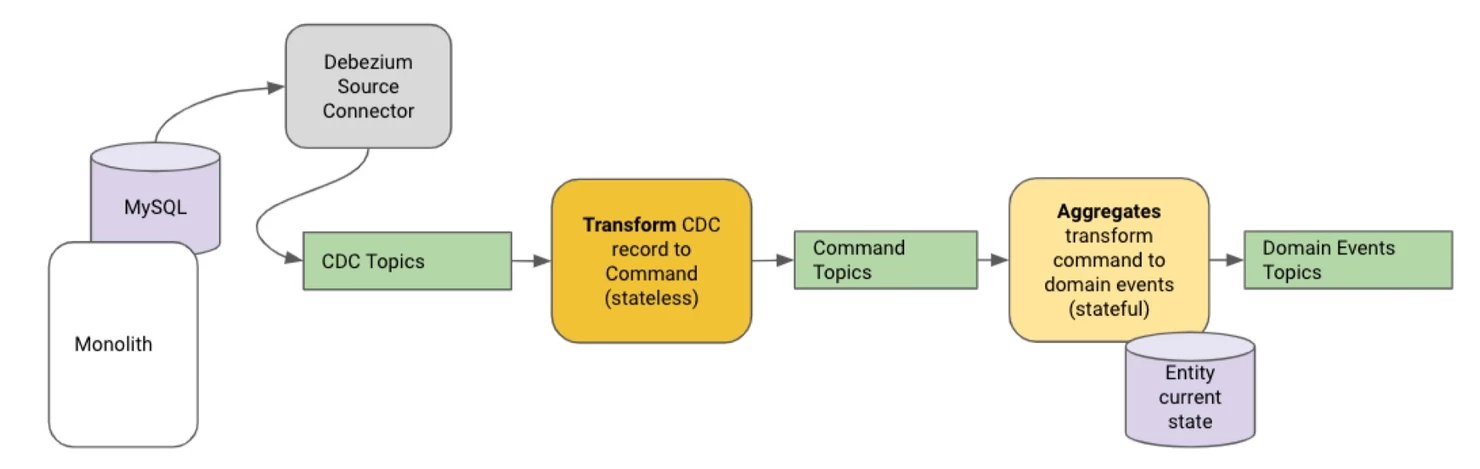
这使得 MySQL 成为了我们的事实来源。如果不对我们的单体和它与客户端的通信方式作出重大变更的话,我们就无法改变这一点,通信必须要变成异步的。这势必导致客户端的重大变化。
变更数据捕获(Change Data Capture,CDC)
将数据库的 binlog 以流的方式传向 Kafka 是一个众所周知的实践,这样做的目的是复制数据库。表中数据行的每一个变化都会被保存在 binlog 中,这样的记录包含之前和当前的行状态,这种方式能够有效地将每个表转换为一个流,从而能够以一致的方式具体化为实体状态。我们使用Debezium源连接器将 binlog 流向 Kafka。
借助 Kafka Streams 进行无状态转换,我们能够将 CDC 记录转换为命令,发布到聚合命令主题。我们这样做有几个原因:
在很多情况下,我们有多个表使用实体 id 作为二级索引。我们希望聚合能够处理与同一 id 相关的所有命令。例如,我们可能有一个主键为 orderId 的 “Order”表,以及一个带有 orderId 列的“OrderLine”表。通过将 Order CDC 记录转换为 UpdateOrderCdc 命令,将 OrderLine CDC 记录转换为 UpdateOrderLineCdc 命令,我们能够确保同一个聚合将会处理这些命令,并能访问最新的实体状态。
我们想为所有的聚合命令定义一个模式。这个模式可以从 CDC 的更新命令开始,但也可以演变成更细粒度的命令,这些命令也可以由同一个聚合来处理,这样就可以逐步演变成一个真正的事件溯源架构。
随着聚合不断处理命令,它会逐渐更新 Kafka 中的实体状态。我们可以重新创建源连接器,并实现相同表的再次流化处理,然而,我们的聚合会根据 CDC 数据和从 Kafka 检索的当前实体状态之间的差异来生成事件。在某种程度上来讲,Kafka 成为了我们的流平台的事实情况来源,该平台是与单体应用并存的。
CDC 记录代表了已提交的变化,为什么它们不是事件呢?
CDC feed 的目的是以最终一致的方式复制数据库,而不是生成领域事件。CDC 记录包含了变更前后的元素,通过变更前后的差异将其转换成领域事件是一种很有诱惑力的方案。但是,仅仅依靠 CDC 记录有一些严重的缺陷。
当执行无状态转换时,我们无法对来自不同表的 CDC 记录做出正确的反应,因为不同的表之间无法保证顺序。最终,我们可能会在获得 Order 记录之前就处理了 OrderLine 记录。一个好的领域事件将提供一些关于 Order 的上下文,将其作为 OrderLine 事件的一部分。采用有状态的转换允许我们使用聚合状态作为 OrderLine 的存储,并且只有在 Order 数据到达之后才发布 OrderLine 事件。这是聚合作为实体事件源的责任的一部分。记住,我们现在无法实现纯粹的架构,而是一种并行的模式。
引入 Snapshot 阶段
binlog 永远不会包含所有表的全部变更历史,为此,当为一个新的表配置新的 CDC 连接器时都会从 Snapshot 阶段开始。连接器将标记 binlog 中当前所在的位置,然后执行一次全表扫描,并将当前所有数据行的当前状态以一个特殊的 CDC 记录进行流式处理,也就是会带有一个 snapshot 标记。这本质上意味着在每次快照中,我们都会丢失领域事件信息。如果订单状态随着时间的推移发生了多次变化,快照将只给我们提供最新的状态。这是因为 binlog 的目标是复制状态,而不是成为事件溯源的支撑。这就是聚合状态存储和聚合命令主题之所以重要的关键所在。我们想把我们的解决方案设计成每个表只进行一次快照的方式。
事件溯源的强大功能之一就是能够通过回放历史事件或命令来重建状态或重建领域事件。但在这里再次执行快照并不是正确的解决方案,因为快照将导致事件信息的丢失。
如果想重新创建我们的领域事件,那么我们需要重置命令主题的消费者所采取的行为。命令主题将 CDC 记录打包成命令,并且已经将来自不同表的命令以正确的顺序(或聚合知道如何处理的顺序)存储起来了。
在本文中,我们只涉及了使单体应用具备反应性特征的基本步骤。我们讨论了如何使用 CDC 来建立一个命令主题,以及为什么不能使用 CDC 记录作为命令。我们有了命令主题之后,就可以使用有状态的转换来创建事件,进而能够开始享受事件溯源的好处:重放命令以重新创建事件,重新处理事件以具体化状态。
在接下来的文章中,我们将讨论更高级的话题,将会涉及到:
如何使用 Kafka Streams 来表达聚合的事件溯源概念。
如何支持一对多的关系。
如何通过重新划分事件来驱动反应式应用。
如何重新处理命令的历史,确保在响应事件的反应式服务不停机的情况下重建事件。
最后,如何在多中心的 Kafka 中运行有状态的转换(提示:镜像主题真的不足以实现这一点)。
参考资料:
1. Martin Fowler,2005,https://martinfowler.com/eaaDev/EventSourcing.html
2. Neha Narkhede, 2016,https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论