

我是 Kurio(来自印度尼西亚的一款新闻聚合器)的软件工程师。Kurio 是一款聚合器应用程序,我们的主要工作是:收集发布合作伙伴网站上的新闻或文章,并通过我们的应用程序将其提供给用户。
与其他新闻聚合器一样,我们为用户提供了多种新闻内容,例如按我们的 top_stories 逻辑进行排序的新闻、按照趋势进行分类的新闻以及来自特定发布商的新闻。
移动端的 Kurio 新闻布局
Feed 的构建过程由我们的 Feed 服务负责处理。
这个服务是 Kurio 的三大主要项目之一,之前的版本已经运行了很长一段时间。因此,它变得非常复杂,有时也会难以理解。这也使得添加新功能变得非常困难。因此,我们决定重建我们的 Feed 服务。希望通过这个新版本的 Feed 服务,我们可以轻松添加新功能或者使其更易于维护。
在这个新项目中,我们创建了新的架构,并混合了旧架构,具备了动态和灵活性。我们知道,新闻源可以是任意类型的对象,比如文章、视频、音频等等。使用 Go 语言实现这些真的很有挑战性,因为 Go 语言是一种静态类型的编程语言,它没有 Java 或其他编程语言的泛型类型。
了解流程
首先我们需要了解以前的系统是如何工作的。从编译、测试和部署开始,直到收到用户请求,我们需要知道整个过程的工作原理。
因为这是一个核心的服务,而我刚刚来这里一年,我真的不知道它是如何运作的,尤其是多年来整个系统添加了很多额外的功能和补丁,很难通过阅读代码来了解它。所以,我们需要了解流程和规则,然后基于这些流程和规则构建新的流程和规则。
例如,当用户打开应用程序时,会得到由这项服务提供的 top_stories 新闻源。或者是一些规则,例如:在 top_stories 新闻源中向用户显示的内容是有限制的。或者类似于:不要向用户展示他们不关注的主题,或者根据用户的属性(性别、年龄等)显示新闻。
列出这些规则和流程是一件简单的事情,难就难在如何将其转换为代码。一般来说,我们的流程非常简单,如下所示。
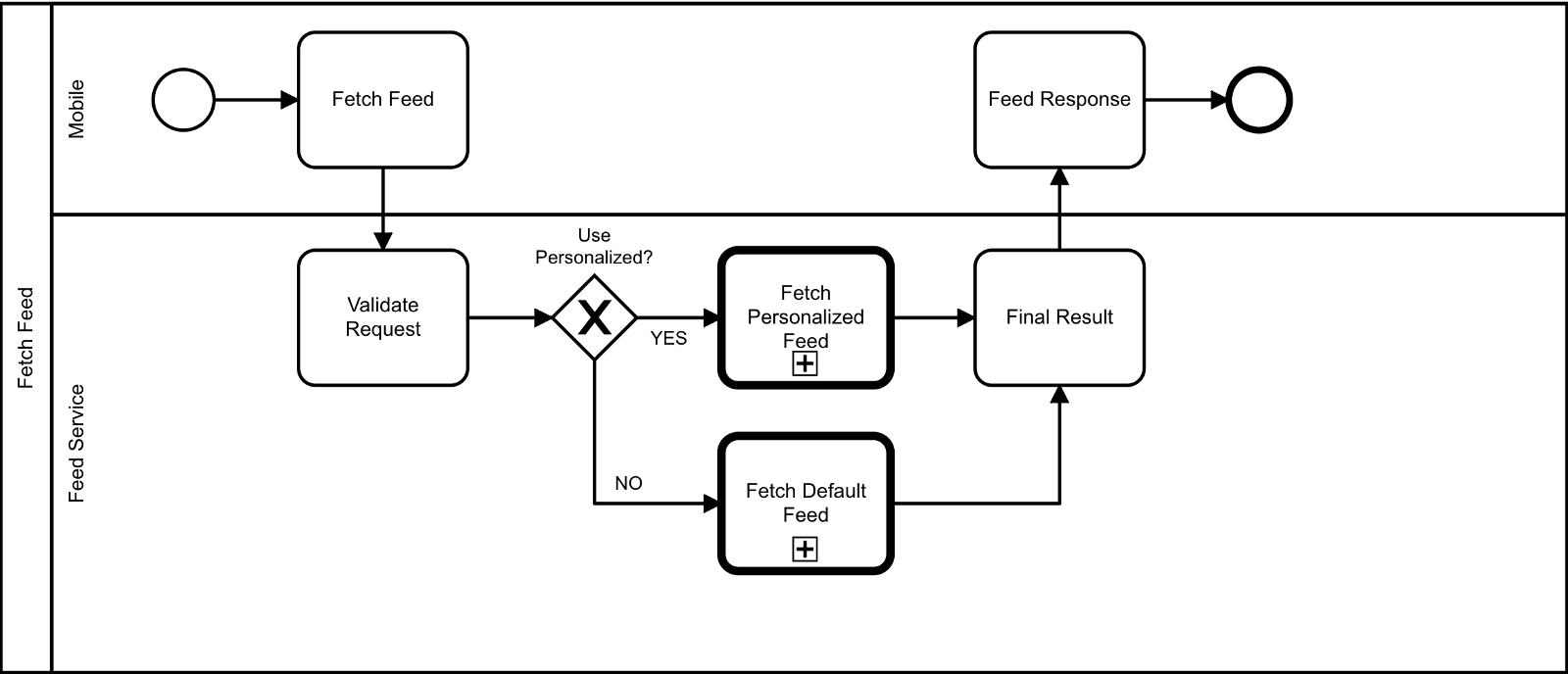
用户获取新闻的流程
基本上主要是两个大功能,获取个性化新闻和获取默认新闻。最难的是获取个性化新闻,因为我们必须将它与个性化引擎相结合。此外,我们必须遵循一些与上面提到的个性化内容相关的规则(提取用户兴趣和属性,然后根据用户的兴趣构建新闻源)。
设计和讨论
我们之所以要重构这个服务,是因为当我们要添加新功能时,之前系统的代码架构无法很好地扩展。如果要在未来开发新功能会非常痛苦,因为我们不得不重构很多东西。
所以我们真正需要的是修复架构。设计一个新的架构真的很难。我们需要问自己很多问题,比如:“这样做会怎样?”、“为什么要这样?”、“为什么不是这样?”我们希望新架构能够解决“未来”的问题,并提供向后兼容性。为此,我们进行了大约一个月的讨论,针对每个大功能进行了技术栈和流程方面的讨论。
最终,我们决定尝试一些函数式的开发方式。我们放弃了之前使用的代码架构,发明了一种新的代码架构,带有函数式编程(使用高阶函数模式)的味道,但又不像 Lisp 或 Clojure 那么动态。
因此,在我们的代码中可以找到很多 HOF(高阶函数)模式,如下所示:
但因为我们使用的是 Go 语言,一种静态类型的编程语言,所以当创建了很多函数时就会有很多痛点,必须进行大量的类型检查和转换,而这耗费了大量时间。
因此,我们意识到 Go 语言不适合用来解决我们的问题,但在我们这 10 个后端工程师当中,只有一个人了解 Clojure(函数式编程),而学习新的编程语言就意味着我们需要额外的时间。经过长时间的讨论,我们决定继续使用 Go 语言,不仅是因为我们所有的后端工程师都很了解 Go 语言,也是因为 Go 语言已经在很多微服务中得到验证。
了解基础
在将流程和设计转换为代码时,我意识到我们必须对基础有一个真正的了解。一开始,我并没有真正理解高阶函数的工作原理。在阅读代码时感到很困惑,怎么总是一个函数接收一个函数作为参数然后再返回一个函数呢?不过要感谢谷歌,我现在终于明白了。
我们还需要了解 Go 语言本身的基础知识,比如使用指针作为函数接收器、DateTime 的基础知识,以及很多其他基础的东西。如果我们对这些东西不了解,只会增加完成这个项目的时间。
先运行,后优化
优化的第一条规则——不要优化
优化的第二条规则——还不到优化的时候
优化前先分析
因此,在开发这个服务时,我们的第一个目标是确保至少可以运行它。我们没有去考虑性能问题,并试图忽略任何有关优化的事情,例如使用 Go 例程。
在开发完代码后,我们就可以编译并运行它,所有请求都能被正常处理,响应也很正常。当然,初始版本速度非常慢。与之前的系统相比,它慢了十倍。以前的系统在使用 staging 服务器时单个 API 请求大约需要 500 毫秒,而新版本需要 50000 毫秒(约 50 秒)或更久。
优化代码也是我们最重要的任务之一。为了优化我们的代码,我们遵循了以下步骤:
找出需要长时间处理的循环代码,将其转换为使用 Go 例程,提高并行性或使用管道。
分析系统并检测所有速度慢的功能,对其进行优化。所幸的是,在 Go 语言中进行分析很容易。借助 pprof(https://blog.golang.org/profiling-go-programs)工具,我们可以对系统进行分析并检测所有速度慢的功能。我们甚至可以检测出我们所使用的哪个库最慢,这样我们就可以使用具有类似功能的另一个库替换它们。
如果有必要,增加缓存。
构建服务时,我们的规则是只在确实需要使用缓存的情况下使用缓存。缓存就像一种药物,它会让我们上瘾,因为当我们的系统看起来很慢时,会把缓存看成是解决问题的灵丹妙药。通常,在开发大型并发项目时沉迷于使用“缓存”的人,首先想到的是“缓存”,而不是先考虑优化(基准测试、分析)功能(逻辑/算法)。
对于我们的情况,我们通过两种方式来使用缓存:
去重管理:因为新闻源可能是来自很多存储库(数据库和服务)的内容(文章、新闻)列表,所以内容可能会重复。因此,我们将缓存作为临时存储来处理重复数据。
存储库缓存:因为新闻源可能是来自很多存储库(数据库和服务)的内容(文章、新闻)列表,多个用户有可能请求相同的内容。因此,为了避免从存储库中获取相同的内容,我们缓存了存储库结果。
通过这种优化,我们至少可以像在以前的系统中那样改进新系统的性能(staging 服务器的响应时间约为 400 毫秒,生产服务器的响应时间约为 180 毫秒)。
小心地做出变更
基于语义版本控制,在不添加新特性和不破坏 API 的情况下进行重新构建就不算是一个新的版本。基本上,在这个新重建的系统中,我们的目标是改变架构,而不是 API 规范。因此,无论我们在系统中进行做出哪些变更,都不能更改 API。因为即使是非常微小的变化也会影响到所有相关的服务。
为了让它成为一个新版本,我们对错误响应消息正文进行了一些修改。
原始错误响应消息正文:
新版本的错误响应消息正文:
因为进行了这些变更,我们还需要处理其他使用了我们 API 服务的相关服务。所幸的是,只有两种服务使用了我们的 API 服务,所以我们只需要更新两个应用程序:仪表盘应用程序和移动网关 API。此外,因为只有响应错误发生了重大变更,所以只需要修改应用程序的一小部分即可。
永远不要忽略了测试
在重新构建这个服务时,我们至少进行了三次测试,然后才发布到生产环境中:单元测试、集成测试和负载测试。
在所有这些类型的测试中,单元测试是最小的测试。有些人似乎低估了单元测试的重要性,因为它只是一个单元,一个小功能。但是,在重建这个新服务时,我体会到了单元测试的重要性。
在 Sprint 开始时,我们忽略了单元测试,因为我们希望专注在代码架构的设计上。所以我们开发了一些没有任何测试的功能。我们这样做是因为我们仍然在构建一些实验性的代码架构,为了避免进行不必要的单元测试重构,我们在这个时候没有创建任何单元测试。
但是,在完成代码架构设计之后,我们忘了为在 Sprint 开始时创建的功能添加单元测试。直到我们将它部署到 staging 服务器并与另一个真实服务进行了集成测试。我们在应用程序中发现了很多错误。然后我们查看了源代码,发现我们的功能有很多条件都没有覆盖到。
知道了这个问题后,我们意识到我们还没有测试过这个功能。它还没有通过单元测试。如果我们从一开始就进行单元测试,那么修复这个问题并重新部署它就不需要做额外的工作。在进行单元测试时,我们可以考虑很多不同情况,并在部署应用程序之前修复它们。
结论
虽然我们做的是幕后工作,并且对我们的用户没有可见的影响,但我们确实学到了很多东西。我学到了很多关于如何从头开始构建高并发系统的知识。完成这项任务后,我知道了为什么当我们在面试后端开发职位时,总会被问及逻辑和算法问题。这是因为在构建高并发系统时,性能是非常重要的方面,任何算法都会影响到系统的响应时间。
英文原文:https://dzone.com/articles/we-rebuilt-our-backend-feed-service-here-what-i-le

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论