
没有什么比“群星闪耀”更适合形容近期的 TTS(Text-To-Speech,文本转语音)模型领域了。
开年以来,从科技巨头到创业公司再到研究机构,都在发力 TTS 模型。2 月,字节跳动海外实验室推出一款轻量级 TTS 模型 MegaTTS3-Global;3 月,出门问问联合香港科技大学、上海交通大学、南洋理工大学、西北工业大学等顶尖学术机构,共同开源新一代语音生成模型 Spark-TTS;同月,OpenAI 推出基于 GPT-4o-mini 架构的 TTS 模型。
与 AI 领域其他热门技术相比,TTS 似乎格外低调,但它却是智能硬件、数字人等场景的“隐形基石”。凭借广泛的应用领域和开阔的商业前景,TTS 在最近一年取得了长足的进步,并悄然改变着行业规则。
最近,TTS 模型又有重磅“上新”,Speech-02 语音模型一出手,就将 OpenAI、ElevenLabs 甩在了后面,登顶 Arena 榜单,成为全球第一。

问鼎 Arena 榜首,Speech-02 模型有何独特之处?
问鼎 Arena 榜首的正是 MiniMax 最新推出的 Speech-02 模型。
在 Artificial Analysis Speech Arena Leaderboard 上,Speech-02 模型的 ELO 评分达 1161,力压 OpenAI、ElevenLabs 旗下的一众模型。Arena 榜单的 ELO 评分,是根据用户在听取并比较不同模型的语音样本时,做出的主观偏好判断得出的。这也意味着,与其他行业领先的语音模型相比,用户明显更偏好 Speech-02。
探究用户偏好的深层次缘由,或许可以从具体的技术指标中找到答案。在字错率(WER)这一关键维度上,Speech-02 和 ElevenLabs 不相上下,而在相似度(SIM,语音复刻场景)上,Speech-02 实现了全面碾压。

其中,字错率是衡量语音识别系统性能的一个重要指标,通过将语音识别系统输出的文本,与人工标注的参考文本进行对比,计算识别结果中错误的词数占参考文本总词数的比例。字错率越低,意味着语音识别系统的性能越好,识别准确率越高。
在字错率方面,Speech-02 在英语、阿拉伯语、西班牙语、土耳其语等多种语言处理中,与 ElevenLabs 打得有来有回,差距不大。但在中文、粤语、日语、韩语方面,明显优于 ElevenLabs。尤其是在中文语言环境中,凭借本土化优势,Speech-02 的中文和粤语字错率仅为 2.252%、34.111%,ElevenLabs 在这两项的字错率则分别为 16.026%、51.513%。
相似度则是语音复刻场景中的一个重要指标,用于衡量语音复刻结果与目标语音之间的相似程度。数值越接近 1,表明相似度越高,复刻效果越好,更能准确地还原目标语音的特征。
在相似度方面,Speech-02 全面优于 ElevenLabs。也就是说,Speech-02 模型在这 24 种评估语⾔中,⽣成的克隆语⾳更接近真实⼈声。
这些技术优势带来更直观的效果,体现在模型在实际应用中的表现上。总体来看,Speech-02 具有三大特点:
超拟人:错误率低且稳定,情绪、音色、口音、停顿、韵律等方面表现与真人无异;
个性化:支持声音参考与文生音,是业内首个实现“任意音色,灵活控制”的模型;
多样性:支持 32 种语言,能够在同一段语音里,实现多个语种间的自如切换。
笔者也对 Speech-02 进行了一番实测,选择多个音色讲述同一段文本:
阳光懒洋洋地洒在阳台上,茶杯里升起袅袅的热气。我靠在藤椅里,随手翻开一本旧书,纸页间飘出淡淡的墨香。窗外,几只麻雀在枝头跳来跳去,偶尔发出叽叽喳喳的声响,像是在争论什么重要的事情。风轻轻吹动窗帘,带来一丝桂花香,让人想起小时候外婆做的桂花糕。就这样静静地坐着,看云卷云舒,听风声低语,便是最好的时光。
同样的一段文字,三种音色完全是不同的感觉:第一个音频女声字正腔圆,仿佛在朗诵一般,温婉大气;第二个音频(粤语)更有生活气息,像是邻家妹妹在轻轻细语;第三个音频则像是奶奶在耳畔讲故事,娓娓道来。
而在多语种的测评中,Speech-02 更是展现了不俗的实力,在多个语种之间切换自如:
这次去 Tokyo 出差真的太疯狂了!刚出成田机场就遇到一个サラリーマン对着手机大喊『やばい! deadlineに間に合わない!』然后我帮他找了台 printer,他居然用中文说『感恩!』还硬塞给我一盒クッキー... 这剧情也太マンガ了吧?不过那盒 cookies 真的美味しい,包装上还写着『一期一会』。
早在 Speech-02 系列内测期间,就有不少创作者抢先体验。
中国传媒大学戏剧影视学院导演系张净雨教授,用 Speech-02 制作了一段广播剧剧本的三人对话。对话中,三个人的人物形象差异比较鲜明,人物的情绪也较为到位,对话节奏衔接在一起,整体也比较自然。“目前 Speech-02 的生成效果还是很不错的,特别是在客观信息类作品,如新闻播报、纪录片旁白。较高难度的剧情作品,也能做到有情绪、有抑扬顿挫的声音表达,配合剪辑,已具备制作广播剧、有声小说、甚至剧情类影视配音作品的潜力。”
星贤文化创始人、海螺 AI 超级创作者陈坤表示:“相对于 Runway 的期货,我认为 MiniMax 的语音更让人惊喜,AI 配音有那么点人味了。”
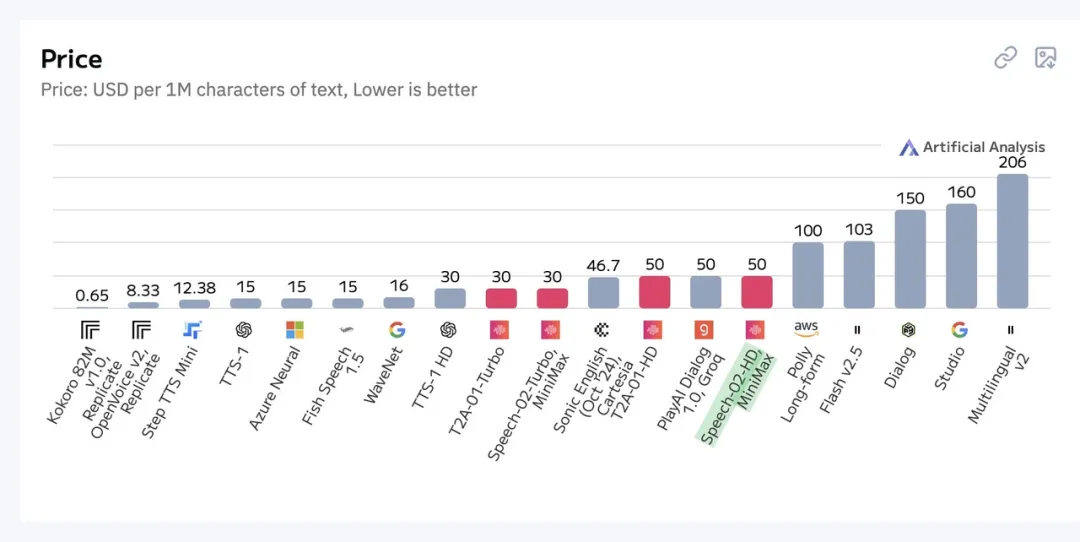
在模型表现之外,Speech-02 以 50 美元 / 百万字符文本的价格,在性价比方面极具优势。 与之相比,ElevenLabs 最便宜的 Flash v2.5 也需要 103 美元 / 百万字符文本,足足是 Speech-02 的两倍。
可学习的 speaker 编码器,实现 zero-shot 零成本复刻
在 TTS 模型中,兼顾模型性能与性价比并非易事。Speech-02 的创新之处在于,它通过数据的多样性、架构的泛化能力,让模型同时学会所有声音,更好地平衡模型性能和成本。
在体系结构上,Speech-02 主要由三个组件构成:标记器、自回归 Transformer 以及潜在流匹配模型。与其他使用预训练说话人编码器的语音合成模型不同,Speech-02 中的说话人编码器与自回归 Transformer 进行联合训练。这种联合优化使得说话人编码器能够专门针对语音合成任务进行定制,通过提供更丰富、更相关的说话人特定信息,提升了模型的合成质量。
此外,由于说话人编码器是可学习的,它可以在训练数据集中的所有语言上进行训练。与可能未接触到同样多样语言的预训练说话人编码器相比,这种可学习的说话人编码器确保了更广泛的语言覆盖范围,并有可能增强模型的泛化能力。
这也意味着,Speech-02 具备强大的零样本学习能力,能够仅从一个未转录的音频片段中,合成出模仿目标说话人独特音色和风格的语音。而此番登顶 Arena 榜单,也说明 Speech-02 模型的底层架构代表了⼀种更先进的下⼀代⽅法。或许,这才是 TTS 模型们追求卓越性能与性价比的新解。
创新 Flow-VAE 架构,给 TTS 模型提供新解法
在 Speech-02 之前,很多 TTS 方法都存在一定的局限性,尤其是在零样本语音克隆与高保真合成等核心场景中,音频质量和人声相似度难以实现最佳效果。比如,传统 TTS 方法过度依赖转录参考音频,既限制了模型跨语言能力的发挥,也影响了语音合成的表现力。此外,由于生成组件的局限性,很多模型难以平衡音频质量与说话人相似性。这也是为什么很多 TTS 模型“AI 味”十足,而 Speech-02 的人声相似度能够高达 99%。
在架构层面,Speech-02 在 VAE(变分自编码器)的基础上,创新性地提出了 Flow-VAE 架构。该架构显著优于 VAE。其独特之处在于,引入了一个流匹配模型,能够通过一系列可逆映射,灵活地转换潜在空间。这种融合解决方案可谓是“强强联合”——不仅充分利用了 VAE 对数据的初始建模能力,还借助了流模型对复杂分布的准确拟合能力,使得模型能够更好地捕捉数据中的复杂结构和分布特征。

据介绍,该流匹配模型采用 Transformer 架构,通过 KL 散度作为约束,对编码器 - 解码器模块进行优化,让潜在分布变得更加紧凑且易于预测。与之相比,传统的流匹配模型大都是在“走弯路”:先预测梅尔频谱图,再由声码器将其转换为音频波形。在这个过程中,梅尔频谱图很可能会成为信息瓶颈,限制最终语音质量。而 Speech-02 的流匹配模型能直接模拟从音频训练的编码器 - 解码器模块中,提取的连续语音特征(潜在特征)分布,类似于 “抄近道”,避免了信息瓶颈的问题。
在一些测试集的评估中,Flow-VAE 与 VAE 相比,实现了全面领先。
以声码器重合成维度的测试为例,通过比较 Flow-VAE 和 VAE 的波形重建能力,并在多个维度上将合成的音频与原始音频进行比较,来计算评估指标。最终结果表明,在所有评估指标上,Flow-VAE 模型相较于 VAE 模型均展现出显著优势。
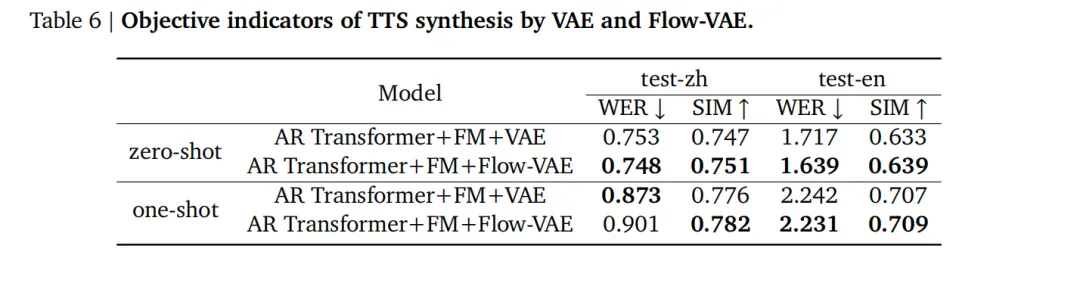
而在 TTS 合成方面,按照 Seed-TTS 的字错率(WER)和相似度(SIM)评估方法,技术团队在两种推理设置下生成了测试数据:零样本和单样本。最终测试数据表明,与 VAE 模型相比,Flow-VAE 在字错率、相似度指标上都具有显著优势。
这也解释了为什么 Speech-02 模型能够问鼎 Arena 榜首,并且在多个技术指标中把海外顶尖模型甩在身后。从更长远的视角来看,Speech-02 模型的意义远不止屠榜,而是通过创新架构解决现有 TTS 方法存在的痛点,重新定义技术边界。
“更有人味”的 AI 配音,征途是星辰大海
从 MegaTTS3-Global 到 Spark-TTS,再到 Speech-02,TTS 模型“神仙打架”,各显神通。这种良性竞争既促进了 TTS 技术的快速迭代,也进一步繁荣了 AI 应用交互生态。目前,TTS 模型正在越来越多的领域中得到广泛应用,从多个维度提升用户体验。
以教育领域为例,TTS 模型不仅能够让晦涩难读的书面教材转化为活生生的有声读物,还能通过音色复刻,为用户提供可以 24 小时陪练的名人 AI 助手。比如,最近在市场上掀起英语学习热潮的“吴彦祖带你学口语” 课程,就是通过音色复刻,实现了 24 小时可定制化 AI 语言陪练系统——“AI 阿祖”。借助 MiniMax 语音大模型和多模态交互系统,“AI 阿祖”完美复刻了吴彦祖的声音,不仅能纠正用户发音、修正语法,还能在情景对话中给予真实且富有情感的反馈。

在智能硬件领域,TTS 模型也用“更有人味”的 AI 配音,为各类产品赋予生命力。以玩具为例,很多玩偶是不具备语音功能的,通过 TTS 模型,AI 挂件能够让玩偶“开口说话”。被小红书用户评为 AI 玩具 Top1 的 Bubble Pal,正是这类对话交互式挂件玩具的代表产品。通过接入 MiniMax 语音模型能力,Bubble Pal 能够根据儿童喜欢的卡通人物复刻音色,并且高度还原角色音色,让玩具“活起来”。

而在智能汽车领域,TTS 模型也能通过联合深度推理模型,为用户提供千人千面的个性化体验。以极狐汽车为例,其用 DeepSeek 精准理解用户意图,用 MiniMax 语音模型即时响应用户问答,让冰冷的座舱更有温度,能够和用户直接用语言进行交流,从而实现更加个性化的体验。
值得一提的是,早在 3 年前,MiniMax 就开始发力 TTS 赛道,为用户提供个性化、自然动听的语音服务。2023 年 11 月,MiniMax 便推出初代语音大模型 abab-speech 系列,支持多角色音频生成、文本角色分类等功能。通过将语音技术对外开放,MiniMax 成为国内最早采用大模型架构提供语音服务的公司之一。目前,MiniMax 已成功服务全球超 5 万家企业用户与个人开发者,包括阅文起点有声书、高途教育等知名企业。
随着 TTS 技术不断进步,我们有理由相信,它将在更多场景中得到应用,为用户带来更多便利。甚至,它改写未来的 AI 应用交互范式,也未可知。




