
摘要
1800+ 家客户,40+ 个国家,每年 80+ 亿笔交易记录,这是美国某大型 SAAS 公司云上数据分析架构探索与实践!
在 Kyligence Cloud 2020 大会上,Kyligence 首席架构师史少锋分享了某美国大型 SAAS 公司在服务遍布全球 40+ 个国家的 1800+ 家客户的背后,所面临的海量数据分析挑战与日俱增。建设新的数据平台迫在眉睫,该公司新的平台如何做到高性能、高并发的同时降低总体拥有成本?详情请见下文。
客户简介

该 SAAS 公司位于硅谷,以 AI 技术见长,为企业提供自动化的报销审核服务。以前企业里报销票据需要管理者以及财务人员人工审核,效率低且容易出错,给企业带来财务风险和漏洞,造成资金的浪费;近年来,随着企业的信息化的普及,以及 AI 技术快速发展,很多的财务审计可以先由 AI 程序自动来完成,从而大幅度减少人工核对的工作量,并提高效率和准确度。
截至目前,这家公司已经为超过 1800 家的大型企业提供自动的财务审批,每年处理的审批的报销记录超过 80 亿笔,其超过 1/3 的客户是世界 500 强企业。
项目背景
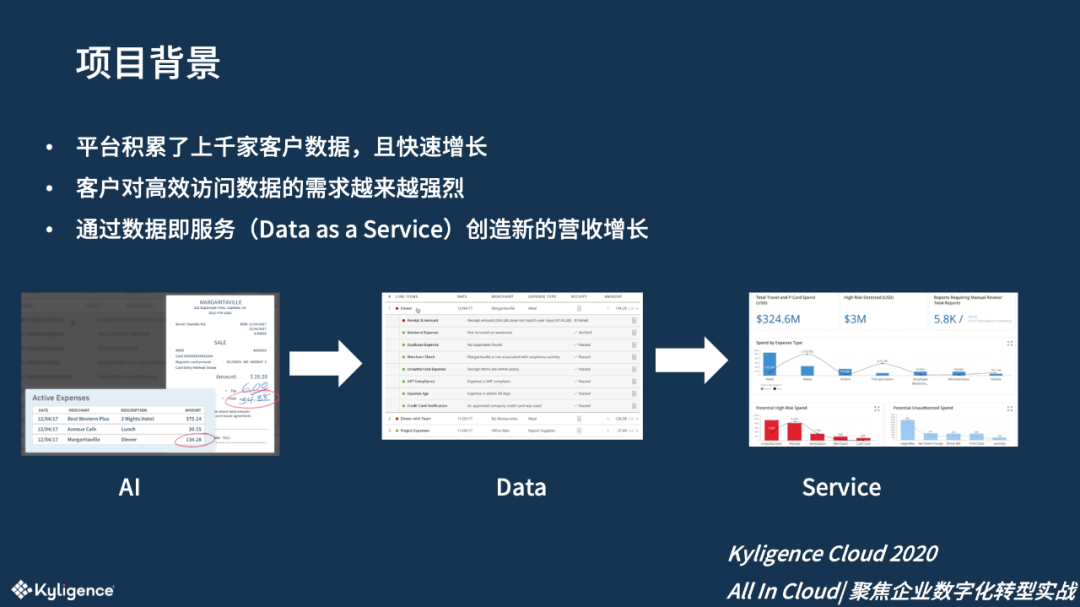
该 SAAS 公司的客户数据以全托管的模式存放在亚马逊云(AWS)上,随着业务的快速发展,海量的客户数据迅速累积,客户对这些数据也提出了越来越强的访问需求,建立一个 DaaS 平台迫在眉睫。
该公司需要将这些数据按照客户需求提供高性能的访问 API 以及各类分析报告,从而提高客户满意度,增加用户黏性;另一方面,该公司也希望通过为客户提供附加服务找到新的业务增长点,创造更多营收。
原有方案
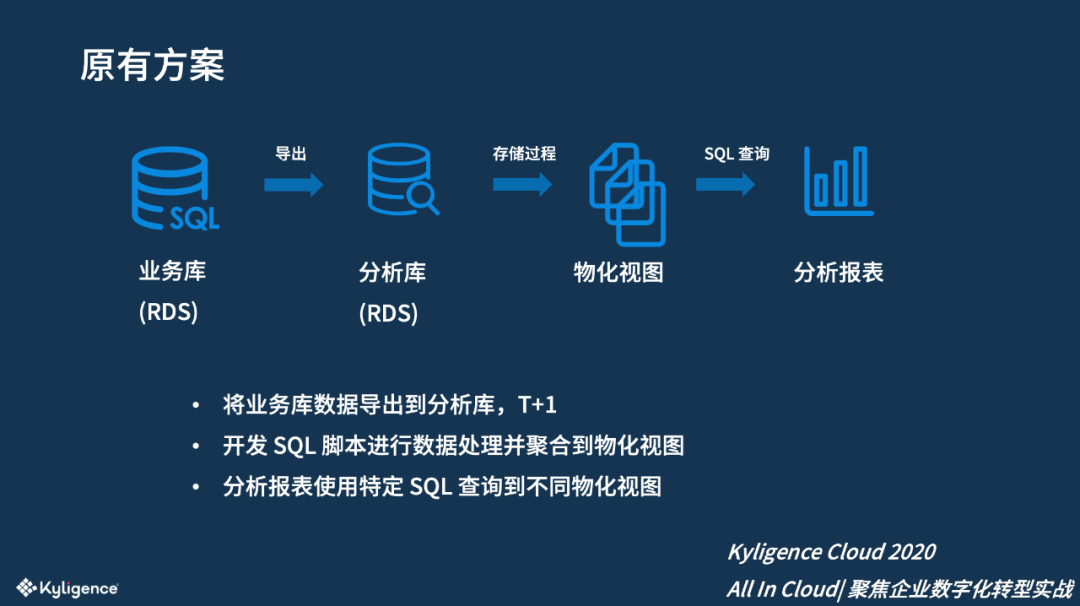
在使用 Kyligence 之前,该 SAAS 公司已建立了一个初步的从 OLTP 到 OLAP 的方案:原始数据主要存储在业务数据库 RDS(AWS RDS)中,为了避免对业务库的影响,该公司定期对该 RDS 创建快照,然后在另外一个 RDS 中恢复出来;为提升数据访问性能,会使用存储过程来计算各种物化视图,对数据进行预先的加工和计算。随后对接分析报表,通过 SQL 来查询物化视图达到提升性能的目的。
该公司明细数据量大,按照报表访问的方式去创建不同的物化视图,此此方法虽然可行,但存在诸多挑战。
例如: 从业务库到分析库是以全量导出的方式,整个过程会花费若干个小时,而且容易出错。 从分析库的明细数据加工到物化视图需要人工编写 SQL 脚本来执行;随着分析报表越来越多,物化视图也会越来越多,因此开发运维的成本也会越来越高。
可能大家会问:为什么不能够直接在业务库进行查询?
这是因为 OLTP 和 OLAP 两种负载会造成资源冲突:当做数据分析的时候,需要扫描大量的历史数据,会对交易型的业务造成影响,所以必然要将业务库和分析库分离。即便是分开,分析库也有很多的选择,例如 AWS 自带的 Redshift 分析型数据仓库等,但是客户做过测试,发现它的性能和并发达不到要求。
面临的挑战
该公司的分析平台目前主要面临以下挑战:
架构难扩展,处理能力弱
使用传统 RDBMS,不能水平伸缩。
聚合查询通常超过 5 秒,并且难以同时运行多个查询。
开发效率低
新需求需要前后端一起开发,周期长,投入大。
无法提供灵活分析。
数据延迟久
T+1 重刷物化视图,刷新平均需 10 小时以上。
单个库容量有限
仅能存放近半年历史数据,不能存放全量。
因为既有方案存在很多的问题,该公司最后找到了 Kyligence,并提出了对新平台的具体要求。
对新平台的要求
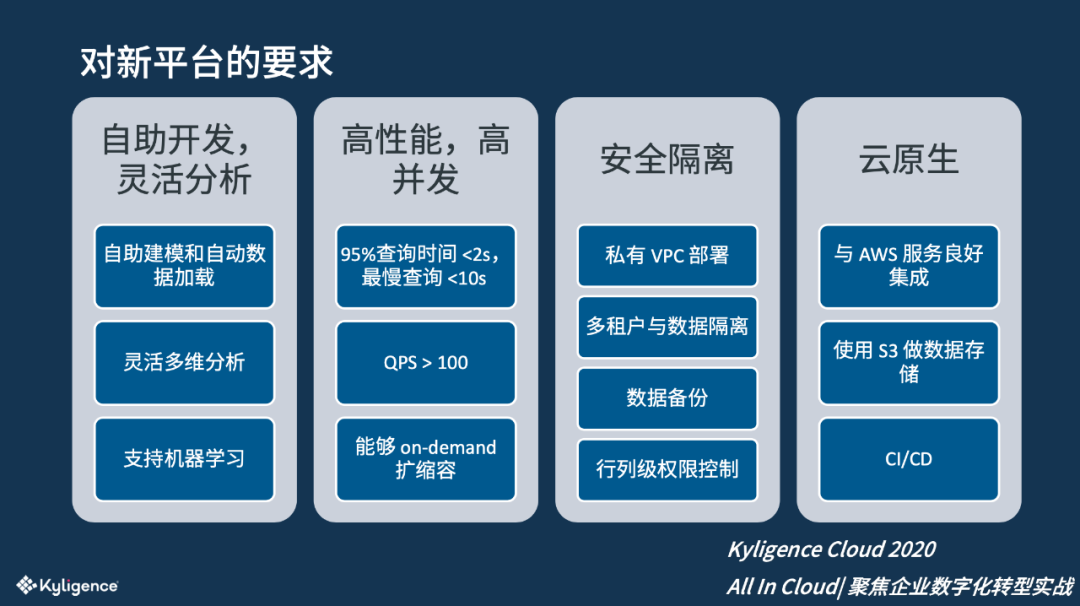
对于新的平台,该 SAAS 公司提出了四个方面的要求。
自助开发: 首先新的架构要能够支持业务人员做自助的数据模型开发,可以支持灵活的分析。同时,新的架构需要能够支持机器学习的接入,因为该公司的核心就是 AI,希望能够从新的技术平台上获得额外的数据输入。
高性能,高并发: 考虑到平台的分析报告服务面向客户的高层管理人员,用户体验非常重要,该公司对性能有非常高的要求:明确要求 95%的查询小于 2 秒,最慢的查询不能超过 10 秒;能够支持到高并发,例如可以每秒完成超过 100 个查询;为了应对用户和数据的快速增加,体系架构需要能按需伸缩。
安全隔离: 平台存储和管理着多个客户的财务数据,具有较高的敏感性,所以该公司对安全隔离的要求很高:平台需在私有 VPC 内部署,数据加工不能出 VPC;要能够支持多租户部署;具备自动的数据备份,数据管控要可以做到行列级的权限控制。
云原生: 该公司的平台整体运行在 AWS 上,因此新的平台需要能与 AWS 集成;优先使用 S3 存储数据,以在可承受的成本内达到更高的可靠性;平台需有丰富的 API 可以跟现有的 CICD 做集成。
解决方案:Kyligence Cloud
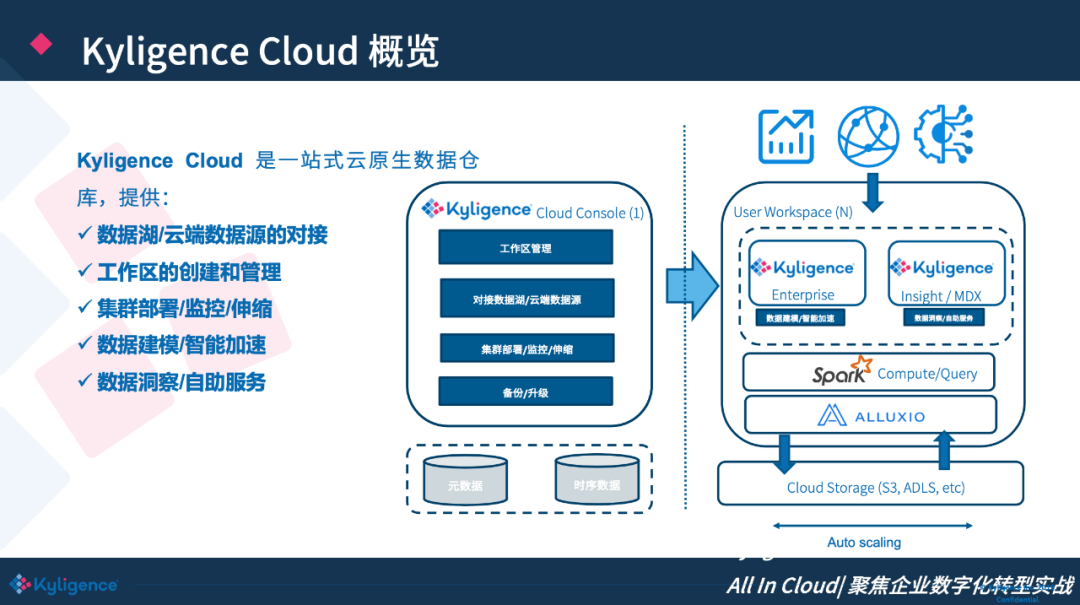
基于上述调研,Kyligence 为该公司提出了 Kyligence Cloud 方案。Kyligence Cloud 是一站式云原生数据仓库,提供:
数据湖/云端数据源的对接。 支持直接对接云上的数据源,比如说 S3、 RDS。
工作区的创建和管理。 可以满足多租户的需求。
集群部署/监控/伸缩。 部署时间不超过 5 分钟。
数据建模/智能加速。 Kyligence Cloud 具有 AI 增强的分析模式,用户不仅可以便捷地创建业务分析模型,而且能对不同的查询做智能加速。
数据洞察/自助服务 。包括 Kyligence Insight、MDX、SQL 接口,可以连接到客户的不同分析系统。
Kyligence Cloud DaaS 方案介绍
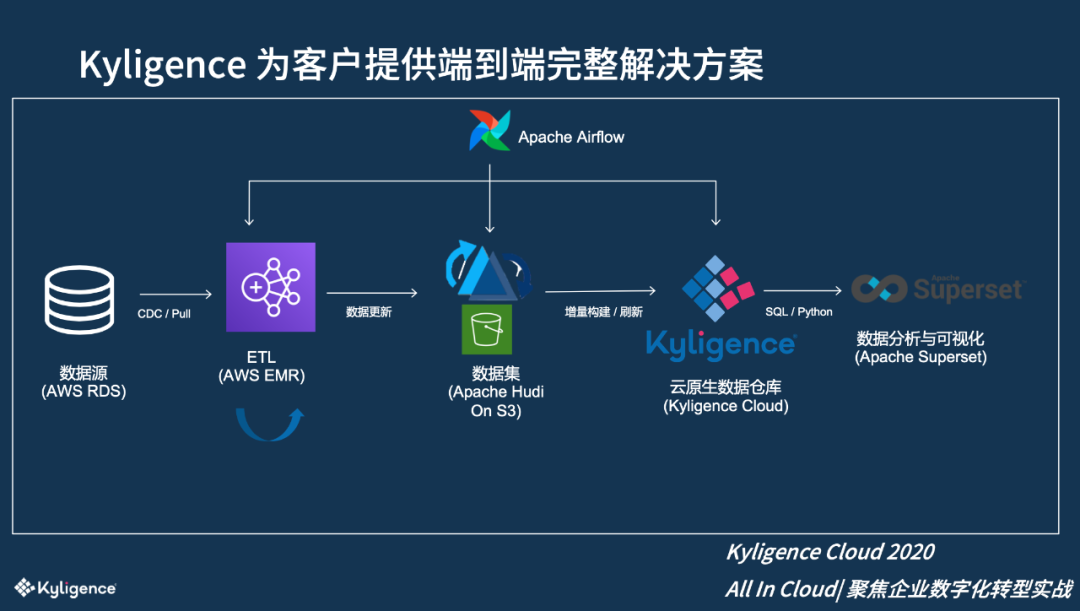
最终,Kyligence 为该公司建立了一个从 SAAS 到最终分析的端到端的 DaaS 解决方案。
第一步:对数据源进行 ETL。因为数据源的表比较多,会按需启动 AWS EMR,把数据通过 EMR 里的 Sqoop 任务抽取出来,随后使用 Spark SQL 进行现场 Join 和二次加工;
第二步:把初步加工好的明细数据导入 S3 中,通过 Apache Hudi 来管理数据的增量修改,实现多版本管理并保证每次修改的原子性。Hudi 有很多丰富的功能,能用比较小的代价实现在大量数据上的插入和修改,比传统的存储如 Kudu 成本更低,可以直接使用 S3。
第三步:数据增量进入 Hudi 数据集后,通过特定的 API 识别数据的新增或者修改,从而触发 Kyligence Cloud 对数据进一步的聚合预算(构建或刷新)。Kyligence Cloud 会申请 AWS 的计算资源,从 Hudi S3 获取新增或修改的数据,然后按照模型进一步计算。
第四步:完成数据准备后,客户可以通过我们提供的 Restful API 或 JDBC/Python 等连接器无缝对接 Kyligence Cloud。整个端到端的 Workflow 通过 Airflow 进行调度,以连接到这里面的每一个组件。
Kyligence Cloud DaaS 方案亮点
引入新技术 Apache Hudi。 这个项目开始的时候, Hudi 还在 Apache 孵化器,它帮助在海量数据上进行代价比较小的 Upsert,同时可以保证每一批数据修改的原子性。在此之前,在大数据集上做增量更新有时候会失败,导致数据不一致,需要管理员的手动介入,成本非常高。在今年初的时候,AWS EMR 官方宣布集成了 Hudi 并提供技术支持,进一步证明这个方案是可行的,为我们带来了信心。
集成 Alluxio 分布式缓存,解决性能和并发的问题。 Alluxio 可以透明地把热数据 Cache 在内存或者本地磁盘中,把冷数据存储在 S3 中。一方面提高了查询访问的性能,另一方面减少对 S3 API 的调用,减少网络带宽使用,从而进一步帮助节省成本。
读写分离。 Kyligence Cloud 采用两个 Spark 集群,一个集群用于数据加工计算,另外一个集群用于线上查询,以此确保数据负载的分离,保证查询的高稳定。计算数据的集群可以自动按需启动,而且根据数据量大小,自动向 AWS 请求合适的计算资源。这可以大幅度节省资源,因为在云上 CPU 是非常昂贵的。
Airflow 全自动的调度。 我们为客户基于 Airflow 开发了端到端的数据加工链路,实现了全流程的自动化调度、自动告警、自动重试等;最终做到端到端的增量数据更新延迟小于 1 小时。
数据不出 VPC, 所有计算都在客户的 VPC 内,只能通过 VPN 接入,从而保证了高安全性。
自助分析
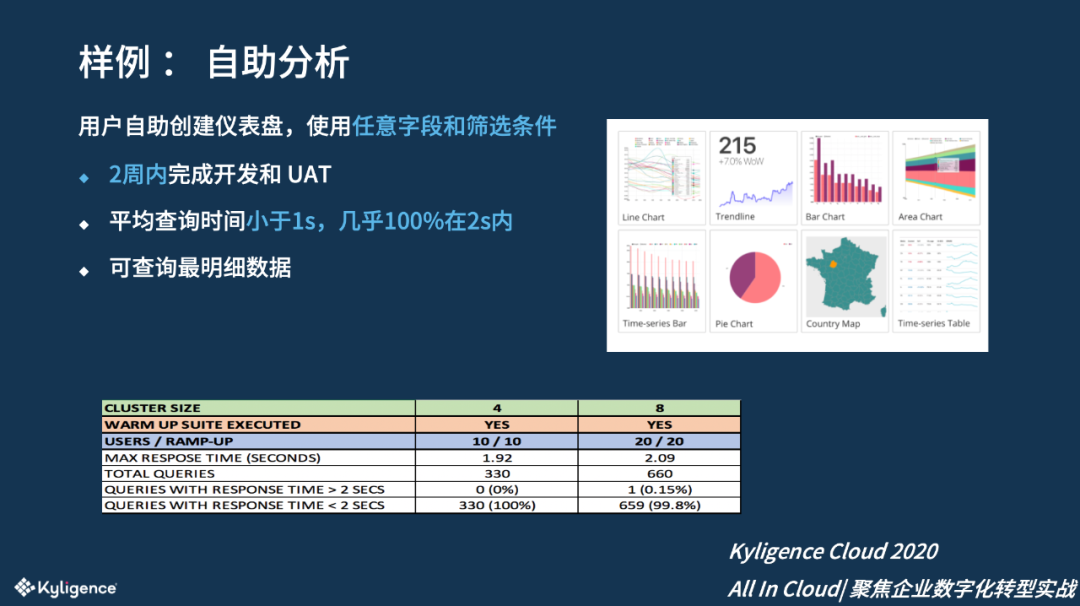
通过模型把多达 50 个的常用维度提供给该客户的内部业务分析师,用户可以自由组装维度。该需求非常紧急, Kyligence 项目组完成了开发和 UAT 仅用时两周。 最终,性能压测的效果非常好,几乎 100%的查询在 2 秒以内完成,而且平均查询的时间小于 1 秒,这也得益于前述进行的大量优化。
管理者视图
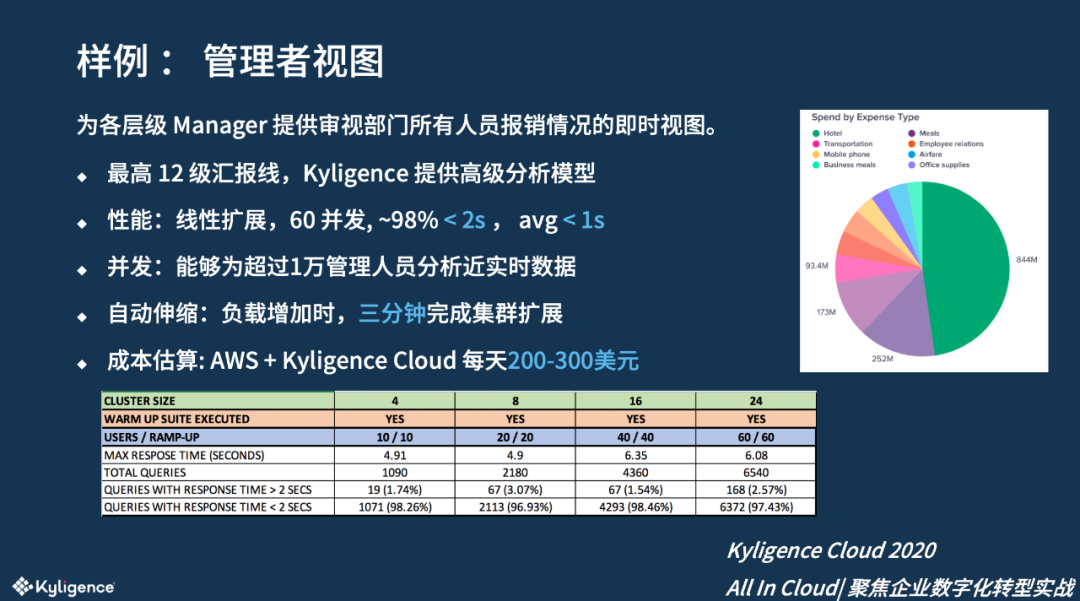
报销审批通常由 Manager 负责,每一层级的 Manager 会定期审查他所管理部门所有人的报销数据,在大型企业中汇报链最高可达 12 级,例如 CEO 会审视公司所有人员的汇总数据。使用传统技术,很难确保对各个等级的管理者提供一致的、高性能的分析报告,而 使用 Kyligence 的高级分析模型仅需一次计算就完成所有层级的统计。
性能表现上 ,该平台可以支撑 60 个用户的同时访问,98%的查询在两秒内,平均的查询时长小于 1 秒, 其它分析方案很难达到这样的效果。统计下来每天成本只需要 200 到 300 美金。
疫情过后,该公司也在官网上适时推出对该 DaaS 产品的介绍。通过这个产品用户可以对财务数据获得全视图的理解,而且业务人员可以在自助地创建出他们想要的分析报告。目前此业务正在推广中,将助力该客户转型并开拓新的增值业务!
本文转载自公众号 Kyligence(ID:Kyligence)。
原文链接:




