

春节前一周,经过社区内部讨论,阿里巴巴大数据引擎 Blink 作为 Flink 的分支正式开源。今天,Apache Flink 官方网站发文对 Blink 贡献回 Flink 项目的意义作进一步说明,并公布了 Blink 和 Flink 的合并计划。社区的合并计划最初会将重点放在有界/批处理功能上,社区将对 SQL/Table API 模块进行重组,将 Blink 查询规划器(优化器)和运行时(操作符)合并为当前 SQL 运行时的附加查询处理器。经过一段过渡期之后,将开发新的查询处理器,而当前的处理器很可能会被弃用。为了合并 Blink 的调度增强功能和有界数据的作业恢复功能,Flink 社区也在努力重构当前的调度功能。
前不久,经社区讨论,阿里巴巴决定将 Blink 贡献回 Flink 项目。为什么说这对 Flink 来说是一件大事?这对 Flink 的用户和社区来说意味着什么?这与 Flink 的整体愿景有着怎样的关系?让我们退后一步,一探究竟。
针对 Blink 的贡献形式,Flink 社区讨论邮件如下:
统一的批处理和流式处理方法
从早期开始,Flink 就有意采用统一的批处理和流式处理方法。其核心构建块是“持续处理无界的数据流”:如果可以做到这一点,还可以离线处理有界数据集(批处理),因为有界数据集就是在某个时刻结束的数据流。
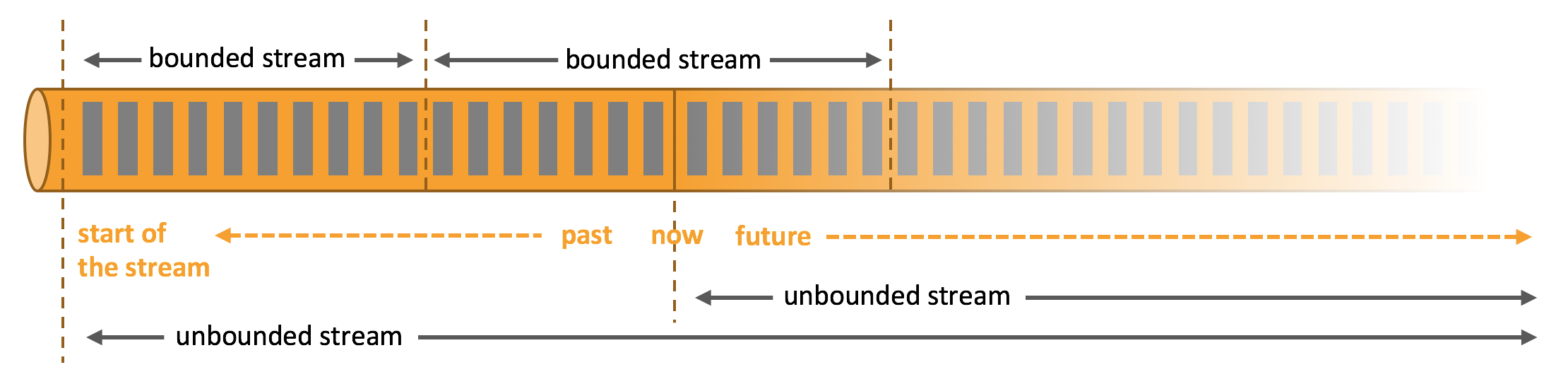
很多项目(例如 Flink、Beam 等)都支持“流式处理优先,将批处理视为流式处理的特殊情况”的理念,这个理念也经常被认为是构建跨实时和离线数据应用程序的强大方式,可以大大降低数据基础设施的复杂性。
为什么批处理器仍然存在?
“批处理只是流式处理的一个特例”并不意味着所有的流式处理器都能用于批处理——流式处理器的出现并没有让批处理器变得过时:
纯流式处理系统在批处理工作负载时其实是很慢的。没有人会认为使用流式处理器来分析海量数据是个好主意。
像 Apache Beam 这样的统一 API 通常会根据数据是持续的(无界)还是固定的(有界)将工作负载委托给不同的运行时。
Flink 提供了一个流式 API,可以处理有界和无界的场景,同时仍然提供了单独的 DataSet API 和运行时用于批处理,因为速度会更快。
那么“批处理只是流式处理的一个特例”这种想法出了什么问题?
其实这种范式并没有错。统一批处理和流式处理 API 只是一个方面,我们还需要利用“有界数据”这个特殊情况的某些特征来应对批处理用例。毕竟,批处理器就是专门为这种特殊情况而准备的。
建立在流式运行时之上的批处理
我们始终认为,同时拥有一个可用于流式处理和批处理的运行时是可能的。一个流式处理优先的运行时也可以利用有界数据流的特殊属性进行快速的批处理,就像批处理器那样。而这就是 Flink 所采用的方法。
Flink 包含了一个网络栈,支持低延迟/高吞吐的流式数据交换和高吞吐的批次 shuffle。它还提供了很多流式运行时操作符,也为有界输入提供了专门的操作符,如果你选择了 DataSet API 或 Table API,就可以使用这些操作符。
因此,Flink 实际上在早期就已经展示出了一些令人印象深刻的批处理性能。下面的基准测试有点旧了,但在早期很好地验证了我们的架构方法。
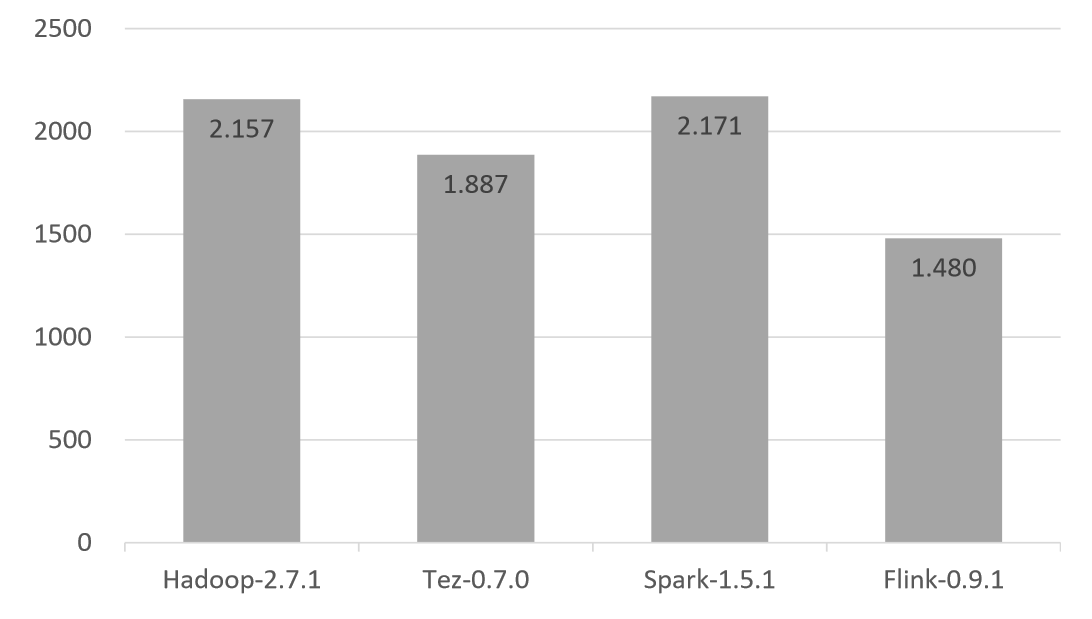
排序 3.2TB(80GB/节点)数据所使用的时间(以秒为单位)
还差些什么?
为了总结这个方法,并让 Flink 在有界数据(批处理)方面达到最新的水平,我们需要做出更多的增强。我们认为下面这些特性是实现我们愿景的关键:
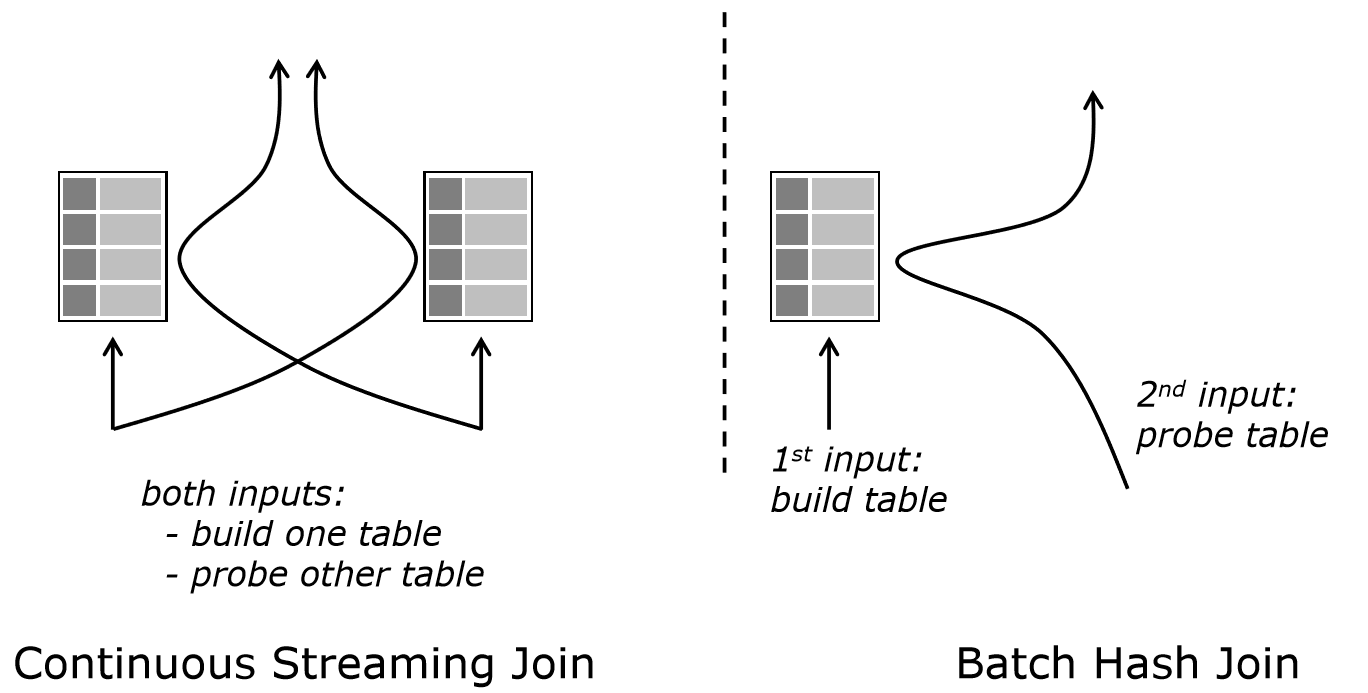
真正统一的运行时操作符栈:目前,有界和无界操作符具有不同的网络和线程模型,不会混在一起,也不匹配。最初是因为批处理操作符遵循的是“拉取模型”(为了方便批处理算法),而流式操作符遵循的是“推模型”(可以获得更好的延迟/吞吐量)。在统一的操作符栈中,持续流式操作符是基础。在操作有界数据时,如果没有延迟方面的约束,API 或查询优化器可以从更大的操作符集中选择合适的操作符。例如,优化器可以选择一个特殊的连接操作符,先完全读取第一个输入流,然后再读取第二个输入流。
利用有界数据流来减小容错范围:如果输入数据是有界的,可以在 shuffle(内存或磁盘)期间缓冲数据,并在发生故障后重放数据。这样可以实现更细粒度的故障恢复,也更有效。
利用有界数据流操作符的属性进行调度:持续无界的流式应用程序需要同时运行所有操作符。基于有界数据的应用程序可以根据其中一个操作符如何消费数据(例如,先构建哈希表,再探测哈希表)来调度另一个操作符。这样做可以提高资源效率。
为 DataStream API 启用这些特殊优化:目前只有 Table API 在处理有界数据时激活了这些优化。
SQL 的性能和覆盖范围:SQL 是事实上的标准数据语言,虽然它被用在持续流式处理种,但并不适用于有界/批处理的情况。为了与最佳批处理引擎展开竞争,Flink 需要提升 SQL 查询执行覆盖率和性能。虽然 Flink 的核心数据平面具有很高的性能,但 SQL 执行的速度在很大程度上取决于优化器规则、丰富的操作符和代码生成,等等。
现在来说说 Blink
Blink 是 Flink 的一个分支,最初在阿里巴巴内部创建的,针对内部用例对 Flink 进行改进。Blink 添加了一系列改进和集成(https://github.com/apache/flink/blob/blink/README.md ),其中有很多与有界数据/批处理和 SQL 有关。实际上,在上面的功能列表中,除了第 4 项外,Blink 在其他方面都迈出了重要的一步:
统一的流式操作符:Blink 扩展了 Flink 的流式运行时操作符模型,支持选择性读取不同的输入源,同时保持推送模型的低延迟特性。这种对输入源的选择性读取可以更好地支持一些算法(例如相同操作符的混合散列连接)和线程模型(通过 RocksDB 的连续对称连接)。这些操作符为“侧边输入”(https://cwiki.apache.org/confluence/display/FLINK/FLIP-17+Side+Inputs+for+DataStream+API )等新功能打下了基础。
Table API 和 SQL 查询处理器:与最新的 Flink 主分支相比,SQL 查询处理器是演变得最多的一个组件:
Flink 目前将查询转换为 DataSet 或 DataStream 程序(取决于输入的特性),而 Blink 会将查询转换为上述流式操作符的数据流。
Blink 为常见的 SQL 操作添加了更多的运行时操作符,如半连接(semi-join)、反连接(anti-join)等。
查询规划器(优化器)仍然是基于 Apache Calcite,但提供了更多的优化规则(包括连接重排序),并且使用了适当的成本模型。
更加积极的流式操作符链接。
扩展通用数据结构(分类器、哈希表)和序列化器,在操作二进制数据上更进一步,并减小了序列化开销。代码生成被用于行序列化器。
改进的调度和故障恢复:最后,Blink 实现了对任务调度和容错的若干改进。调度策略通过利用操作符处理输入数据的方式来更好地使用资源。故障转移策略沿着持久 shuffle 的边界进行更细粒度的恢复。不需重新启动正在运行的应用程序就可以替换发生故障的 JobManager。
Blink 的变化带来了大幅度的性能提升。以下数据由 Blink 开发者提供,给出了性能提升的粗略情况。
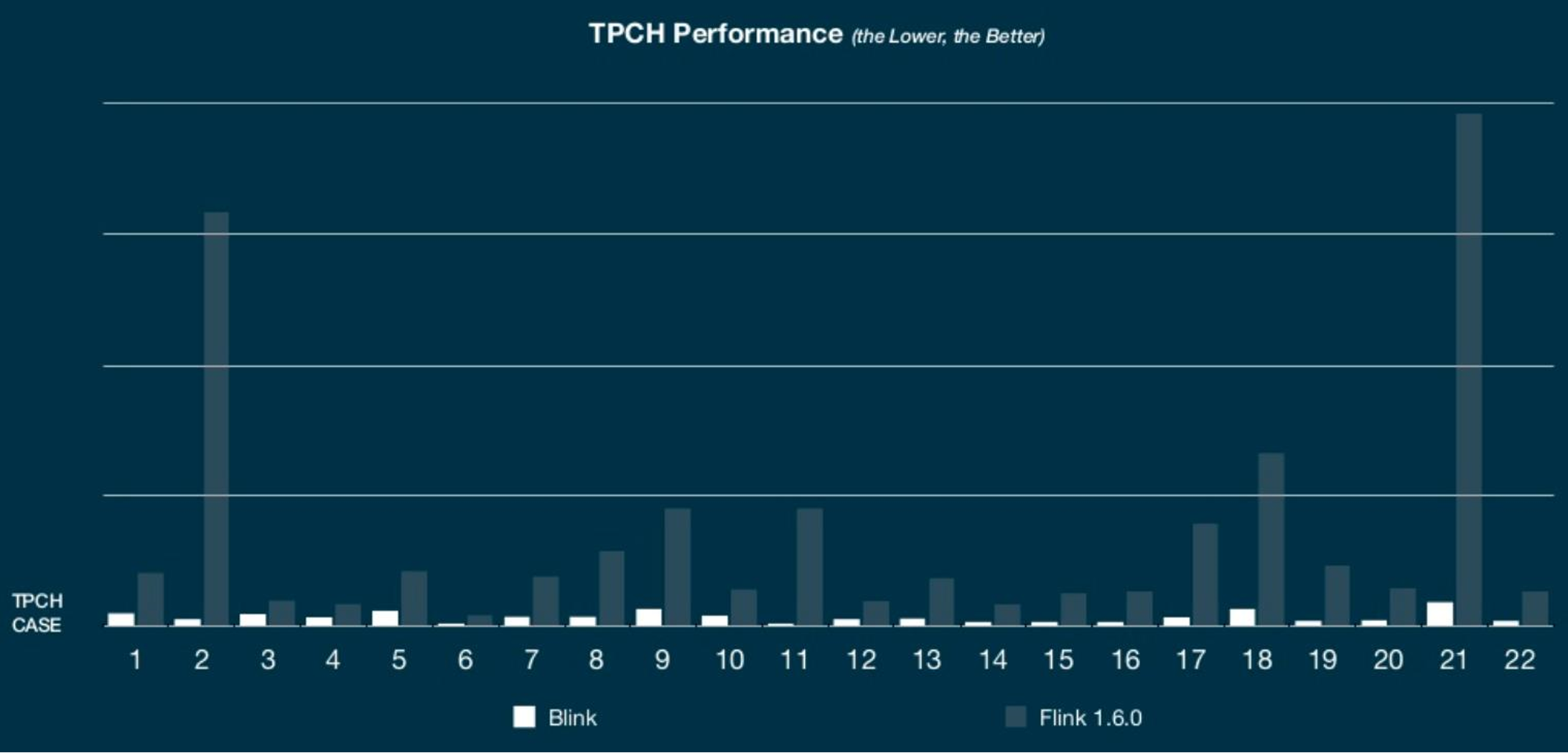
在 TPC-H 基准测试中,Blink 与 Flink 1.6.0 的相对性能。Blink 性能平均提升 10 倍
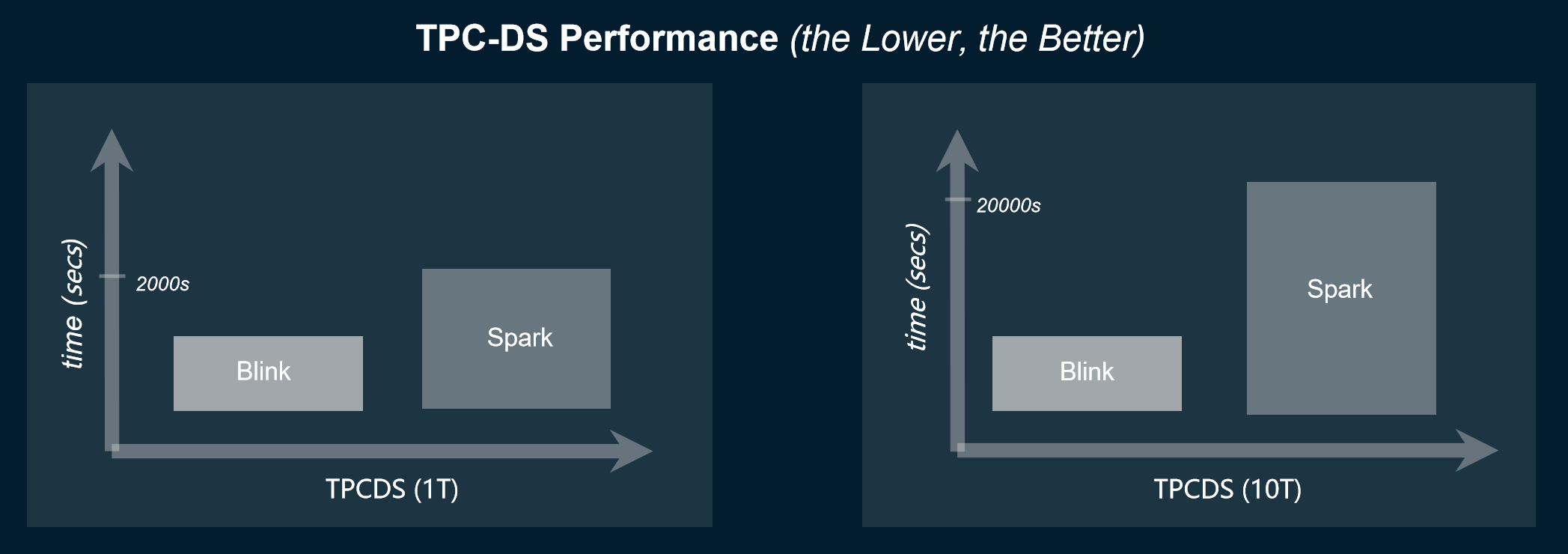
在 TPC-DS 基准测试中,Blink 与 Spark 的性能,将所有查询的总时间汇总在一起。
Blink 和 Flink 的合并计划
Blink 的代码目前已经作为 Flink 代码库的一个分支(https://github.com/apache/flink/tree/blink )对外开放。合并这么多变更是一项艰巨的挑战,同时还要尽可能保持合并过程不要造成任何中断,并使公共 API 尽可能保持稳定。
社区的合并计划最初将重点放在上述的有界/批处理功能上,并遵循以下方法以确保能够顺利集成:
为了合并 Blink 的 SQL/Table API 查询处理器增强功能,我们利用了 Flink 和 Blink 都具有相同 API 的事实:SQL 和 Table API。在对 Table/SQL 模块( https://cwiki.apache.org/confluence/display/FLINK/FLIP-32%3A+Restructure+flink-table+for+future+contributions )进行一些重组之后,我们计划将 Blink 查询规划器(优化器)和运行时(操作符)合并为当前 SQL 运行时的附加查询处理器。可以将其视为同一 API 的两个不同的运行器。最开始,可以让用户选择要使用哪个查询处理器。经过一个过渡期之后,将开发新的查询处理器,而当前的处理器很可能会被弃用,并最终被丢弃。因为 SQL 是一个定义良好的接口,我们预计这种转换对用户来说几乎没有影响。
为了合并 Blink 的调度增强功能和有界数据的作业恢复功能,Flink 社区已经在努力重构当前的调度功能,并添加对可插拔调度和故障转移策略的支持。在完成这项工作后,我们就可以将 Blink 的调度和恢复策略作为新查询处理器的调度策略。最后,我们计划将新的调度策略应用于有界 DataStream 程序。
扩展的目录支持、DDL 支持以及对 Hive 目录和集成的支持目前正在进行单独的设计讨论。
总 结
我们相信未来的数据处理技术栈会以流式处理为基础:流式处理的优雅,能够以相同的方式对离线处理(批处理)、实时数据处理和事件驱动的应用程序进行建模,同时还能提供高性能和一致性,这些实在是太吸引人了。
要让流式处理器实现与专用批处理器相同的性能,利用有界数据的某些属性是关键。Flink 支持批处理,但它的下一步是要构建统一的运行时,并成为一个可以与批处理系统相竞争的流式处理器。阿里巴巴贡献的 Blink 有助于 Flink 社区加快实现这一目标。
英文原文:
https://flink.apache.org/news/2019/02/13/unified-batch-streaming-blink.html
更多内容,请关注 AI 前线。


暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论