

国家 2035 远景规划提出要加快全面数字化转型的步伐,而“大数据平台”是数字化转型的基础技术之一。经过六年多的探索和实践,微众银行打造了一套在金融领域“自主可控”的开源大数据平台。对于任何企业来说,建立和维护一个大数据平台都不是一件容易的事情,而建设一个有特色的、完整易用的大数据平台,显然更是一件技术难度极高的事情。InfoQ 采访了微众银行 WeDataSphere 主创团队,希望他们的实践经验能给大家带来一些启发和思考。
构建大数据平台要量体裁衣
对比互联网企业,由于监管要求和业务的特殊性,金融机构对数据平台的可用性、安全性要求极高。而当金融与互联网相结合之后,互联网银行 IT 架构面对着数字时代的大数据洪峰。用户对于各种类型的数据,在不同业务场景下的开发应用管理需求也在急剧膨胀。这让国内第一家互联网银行,走上了自研“自主可控”大数据平台的道路。
在开业之后的 7 年时间内,微众银行在引入优秀开源大数据组件的基础上,自主研发、反复迭代,形成了一个功能完备丰富并经过金融场景考验的大数据平台套件-- WeDataSphere。2016 年至今,这套数据平台套件从底层的基础引擎引入开始,逐步完成上层功能工具的构建,及中间层中间件的连通集成和治理管控。
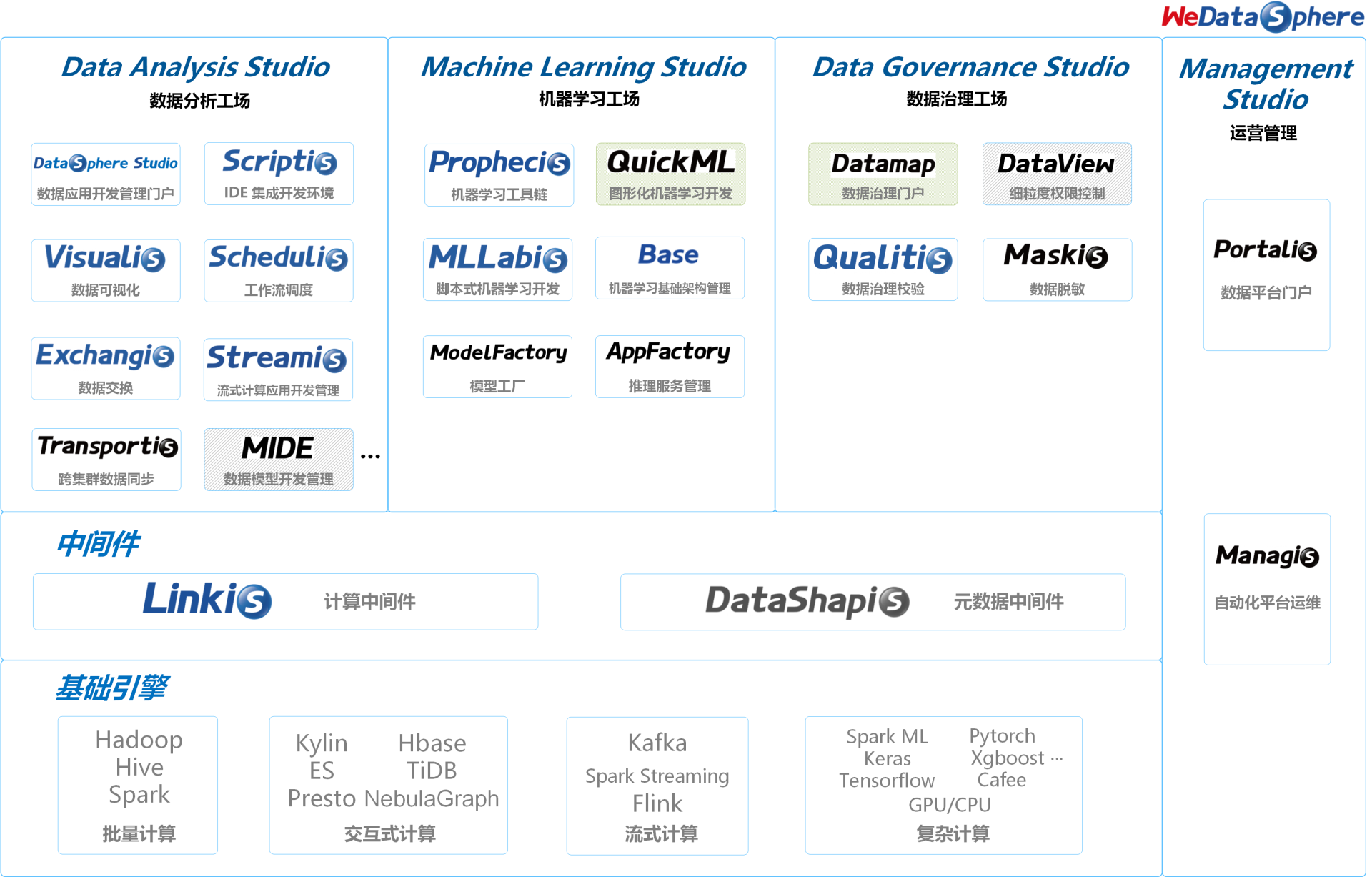
WeDataSphere 全景图,带蓝色 S 球的组件已开源
WeDataSphere 是一套一站式、金融级、全连通、开源开放的大数据平台套件,主要模块从前到后,形成一个“424”阵型:
前场,是数据分析、数据治理、机器学习和运营管理 4 大功能工具;面向用户,提供完整的数据开发应用管理工具集。
中场,是计算和元数据 2 大中间件;承上启下,提供连通、管控、扩展、复用等能力。
后场,是批量计算、交互式计算、流式计算和复杂计算 4 大基础计算存储模块。提供面向各场景的基础计算存储能力。
微众银行通过构建 WeDataSphere,逐步替换了原有的 SAS 平台,支持行内监管报送、核心批量、客户信息管理、实时营销、反洗钱等大量核心关键金融业务场景,达到数据量 40PB+、批量计算 Job 日均 80 万+的处理规模。
当今时代,很多企业都同样有着构建这样一套大数据平台的需求:通过大数据平台,将组织内部的数据进行打通、串联和整合,去服务组织复杂的业务目标和场景。但构建一套数据平台不是一件容易的事情,需要从功能性和非功能性等方方面面,考虑如何解决不同场景的数据开发应用管理问题。中间涉及到数据交换、计算存储、加工处理、可视化等数据分析相关,模型训练、检验、发布等机器学习相关,数据标准、质量、权限等数据治理相关,平台监控、配置、容量等运营管理相关等等各个环节。
WeDataSphere 团队发展到现在总共只有 30 多号人,但负责了 40 多个数据平台组件产品的开发,和微众银行超 200 套各类大数据集群环境的运维管理,同时还要做开源。在团队规模资源有限的条件下,要想做出特色和优势,WeDataSphere 大数据平台负责人邸帅总结了三个经验:
第一,要有产品化的思维。不要一下掉到技术实现层面里去,或者局限于系统当前的架构/实现情况。多跳出来,想想需求和问题到底是什么,目标用户群体是谁,别人是怎么做的,美好的未来可以是怎么样的。
第二,要能量体裁衣。从数据管理、数据平台、数据应用三个层面摸清自身现状,然后可基于如 WeDataSphere 这样的一站式开源解决方案,及其他优秀开源/商业化产品提供的“布料”来量身定做。
第三,须从产品架构设计,和开放共建模式上进一步优化。借用微众银行副行长兼首席信息官马智涛先生的一句话就是“小刀锯大树,必须靠方法。”
邸帅表示“每个组织的数据平台建设都应该要量体裁衣,且会是个长时间的持续 PDCA,螺旋上升的过程。好比你现阶段可能需要的就是一辆成本可控客货兼运的皮卡,那就不要把资源投入到如何去做一辆炫酷的敞篷跑车。先较全景地搞清现阶段所处的组织环境、所拥有的资源,和‘真正’的用户需求,然后真诚面对这些需求,因地制宜因时制宜地给出方案,合理划分阶段推动落地。其实就是要能真正做到所谓以‘用户’为中心。
我们团队选择的模式是主力投入到偏上层的功能工具系统和中间件的建设和开发,更多关注面向用户的数据平台服务化能力的提供,并在中间件层实现上下层之间南北东西向的连通融合。对底层引擎更多是打补丁、修 bug,及有限场景的针对性优化,而在中间件层去补充完善底层引擎所缺失的管控、编排等能力。避免对底层引擎代码修改过多,造成与社区版本差异过大、维护成本过高。在基础计算存储能力方面,开源生态蓬勃发展,各种底层引擎已经能够满足大部分公司的需要。
同时数据平台的功能/组件日益复杂是大势所趋,用户对数据平台一站式体验的要求是众望所归。我们通过在产品架构上设计数据平台中间件层,实现更为极致的解耦、可扩展和复用。同时通过开源开放的模式,团结一切可以团结的力量,互通有无各取所长,去协作打造这么一套庞杂的、一站式的 WeDataSphere 数据平台套件。”
解耦复用,大数据平台需要一个中间件层
随着大数据技术的普及和深入发展,越来越多样化的用户场景需求,催生出了非常多上层应用工具和底层计算存储引擎。在当前的大数据平台架构体系下,我们会发现从上层应用工具,到底层的各个引擎,还是各自为政,Server-Client 模式紧耦合满天飞。
在大量的上层应用工具和大量的底层引擎之间,缺乏一层通用的“中间件”框架设计,导致整个大数据平台变成下图的复杂网状架构:
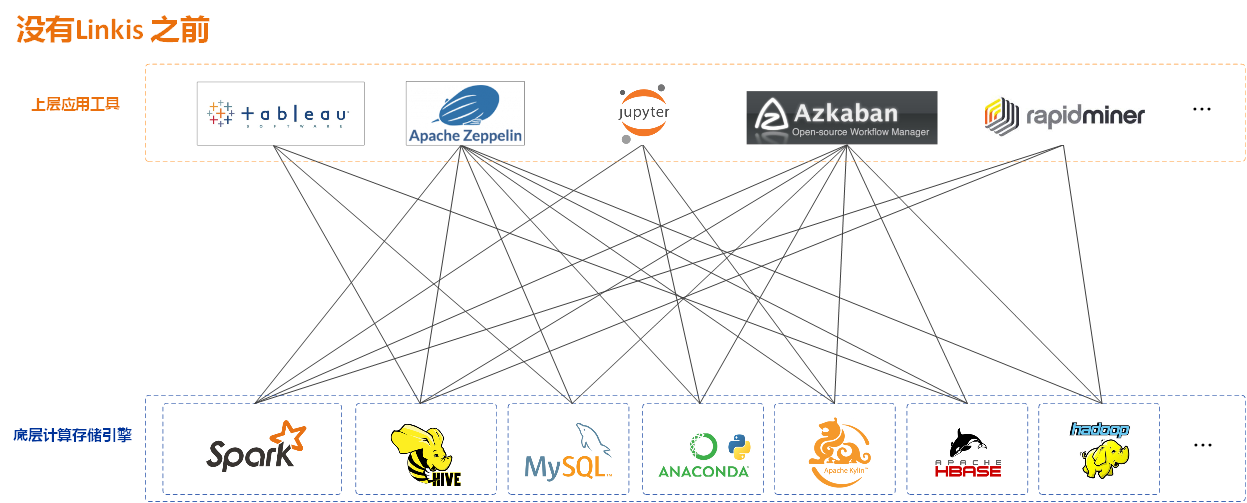
大量的上层应用和底层引擎之间,缺乏一层通用的“中间件”设计
由于缺乏一层通用的中间件层框架设计,使得连通、扩展、管控、编排、复用等“计算治理” 问题凸显。例如:从“连接”问题来看,大数据底层计算存储引擎繁多,各个上层应用工具需要各自维护底层引擎的 Lib 依赖、运行时环境等信息,导致部署运维工作极其繁重,底层引擎任何变动都会影响上层应用的可用性和可维护性;再从“扩展”问题来看,比如某个上层应用之前使用 Hive,后面觉得 Hive 计算太慢现在想用 Spark,用了 Spark 后还是觉得太慢想用 Presto,Presto 太慢又想用 ClickHouse,这时这个上层应用工具需要分别去扩展对接这些引擎,这无疑会带来非常巨大的开发成本。再来看“复用”问题,每个上层应用都要重复集成和管理各种底层引擎的 client 的连接及其状态,特别是在并发使用用户逐渐变多、并发计算任务量逐渐变大时,每个上层应用还要重复解决多个用户间在 client 端的资源争用、权限隔离,计算任务的超时管理、失败重试等等计算治理问题,造成的开发人力浪费不可小觑。
除了上述的架构层面问题,要想让复杂分布式架构环境下,各种类型的计算任务都能更简洁、灵活、有序、可控地提交执行并成功返回结果,计算治理还需关注高并发、高可用、多租户隔离、资源管控、安全增强、计算策略等细化特性问题。这里就不一一展开论述了。
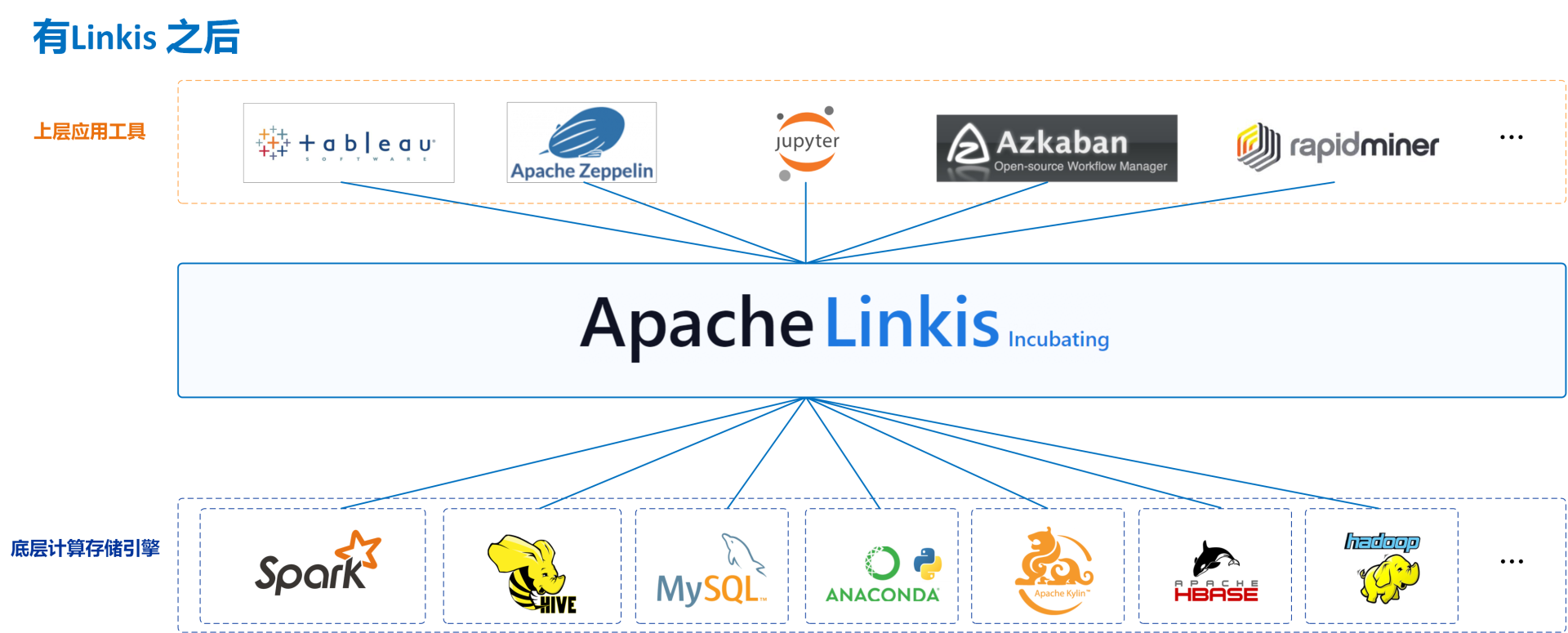
Apache Linkis 计算中间件解决数据平台连通、扩展、管控、复用等问题
在这样的背景下,计算中间件 Apache Linkis(incubating)应运而生,它是微众银行专门设计用来解决上述紧耦合、重复造轮子、扩展难、应用孤岛等计算治理问题的。当前主要解决的是复杂分布式架构的典型场景-数据平台环境下的计算治理问题。
Apache Linkis(incubating) 在上层应用和底层引擎之间构建了一层计算中间件。通过使用 Linkis 提供的 REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问 Spark、Presto、Flink 等底层引擎,同时实现跨引擎上下文共享、统一的计算任务和引擎治理与编排能力。
Apache Linkis(incubating) PPMC 尹强表示,计算中间件虽然是 2019 年在 Linkis 正式对外开源时,由 WeDataSphere 大数据平台负责人邸帅首次提出,但是社区其实自 2015 年开始,就有相关的开源项目聚焦于解决计算治理层的问题。比如 Apache Livy,它是一个简化用户与 Spark 集群交互的 REST 服务,通过 Job 或代码片段,简化了上层应用工具的 Spark 作业提交,是首个解决了“连接”问题的计算中间件;而 Apache Zeppelin,支持 SQL、Scala、Python、R 等多种脚本语言,基于 Web 的交互式数据分析 Notebook,设计了独有的 Interpretor 架构,可快速对接底层新的大数据引擎,是第一个解决了“扩展”问题的开源项目。由于这些开源项目大多都是聚焦于解决计算中间件的一个问题,而大数据平台架构的复杂性,呼唤既具备扩展又具备管控,还具有编排、连通、复用能力的中间件。因此,Linkis 借鉴了各家之长,“是一款站在巨人肩膀上的开源工具,可以极大简化大数据平台的架构,降低开发和运维的复杂度。”
2021 年 Linkis 顺利进入 Apache 软件基金会孵化器,并荣获 2021 OSCAR 开源产业大会“OSCAR 尖峰开源项目和开源社区”奖项。接下来,团队将继续优化 Apache Linkis(incubating) 部署使用体验,完善和规范项目协同开发流程,丰富产品功能,如统一数据源管理,对接 DataX、OpenLookeng 等全新引擎。并与更多的顶级开源社区,如 DolphinScheduler、OpenLookeng 等建立更紧密联系,推动社区进一步发展壮大。
用好开源,回报开源
如何用好开源?
随着大数据技术的广泛应用,如今数据应用的开发,已远远不再是加工和生产几个报表了。业务与数据如何快速实现互动,数据如何快速且高效地生成报告,协助商业决策,几乎是所有企业的核心诉求。
大数据开源组件越来越庞杂,使得数据平台架构愈发蓬勃,不断推陈出新,驾驭开源数据平台的难度也是与日俱增。比如:数据应用工具多,没有统一的用户入口,用户体验割裂感强;业务流程涉及多个系统相互协作,用户需频繁切换系统才可实现业务;很多数据应用系统边界不清晰,功能重叠不仅极大浪费人力,系统间也难以协同互通,用户更是需要花时间反复调研比较,才能最终敲定方案。
如何基于开源项目构建包含数据分析、数据治理、机器学习和大数据中间件的完整企业级大数据平台?
在数据分析领域,社区有很多开源的数据交换工具,例如 Exchangis、DataX、DataX Web 和 Dbus 等;在数据开发探索分析工具上,有 Scriptis 、Apache Zeppelin 和 Hue 等;数据可视化工具上,有 Visualis、Davinci 和 Superset 等;开源调度工具有 Schedulis、DolphinScheduler 和 Airflow 等。
在数据治理领域,开源的数据质量校验工具有 Qualitis、pydqc、Deequ 和 GriFFin 等;元数据管理工具有 DataHub、Apache Atlas 等。
在机器学习领域,有 Prophecis、Kubeflow、MLFlow 和天枢人工智能开源平台等。
进行开源产品选型,WeDataSphere 团队主要基于两个维度:一是技术特性。从技术的设计看是否满足场景需求,是否有完善的运维体系,系统是否足够成熟;是不是经过了企业内部的权威验证,测试是否完善,是不是第一个吃螃蟹、去踩坑的人。二是引入开源组件到内部的时间成本与人力成本,能给产品配置什么样的开发或维护人力成本;社区是否足够开放,是否能协同。需要做些取舍,从而选择合适的开源产品。
然而这也并不意味着用户只需要依照开源产品选型的方法从上面的这些开源工具中选择合适的几个组件就可以。对一个数据分析师来说,通过东拼西凑搭建起来的一套大数据平台,由于缺乏一套通用的协议去定义一套开发管理规范,使得上层各个应用工具的工程管理体系不统一、用户权限不统一、UI 不统一;另一个则是应用孤岛问题,资源物料不互通,运行时上下文不互通,使得用户必须频繁在多个上层工具中上传各种用户物料和资源文件;再就是各个上层应用工具互相隔离,使得用户需要频繁切换多个系统才能完成一个数据应用的开发调试,极大的降低了数据应用开发迭代的效率。
为解决这个痛点,WeDataSphere 团队开发了数据应用开发管理集成框架 DataSphere Studio。DataSphere Studio 将这些数据工具统一了起来,基于 AppConn 插拔式的集成框架设计,在统一的 UI 下,以工作流式的图形化拖拽开发体验,将满足从数据交换、脱敏清洗、分析挖掘、质量检测、可视化展现、定时调度到数据输出应用等,数据应用开发全流程场景需求。
AppConn,定义了一套统一的前后台接入协议,总共分为三级规范,可让外部数据应用系统快速简单地接入,成为 DSS 数据应用开发中的一环,是 DSS 可以简单快速集成各种上层 Web 系统的核心概念。
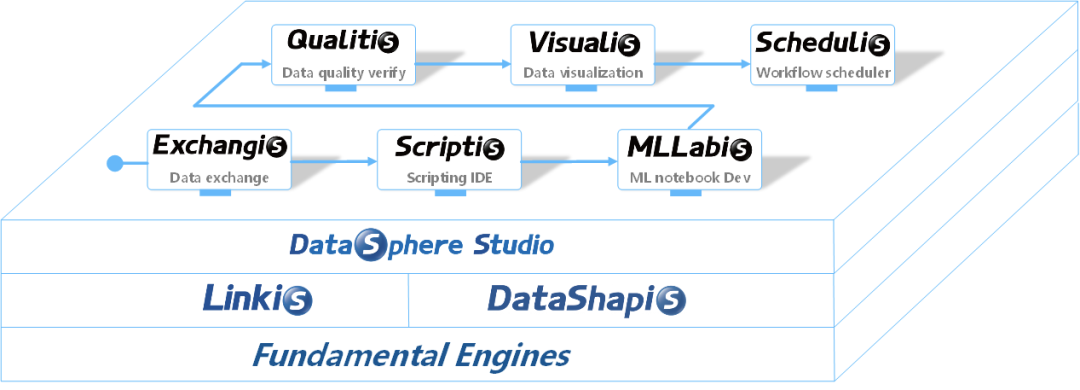
目前 DataSphere Studio 已集成了丰富多样的各种上层数据应用系统,如数据开发 IDE 工具——Scriptis、数据可视化工具——Visualis、数据质量管理工具——Qualitis、工作流调度工具——Schedulis、数据 Api 服务——DataApiService、流式应用开发管理工具——Streamis(即将开源),基本可满足用户的数据开发需求,是各企业构建一站式大数据平台套件的不二利器。
如何回报开源?
WeDataSphere 一站式大数据平台套件自研的各种组件正在逐步开源中。
WeDataSphere 团队致力于通过在整体设计上开放灵活,对扩展友好组件可插拔;形式上以开源开放的方式,吸引更多个人、组织,参与到 WDS 的开发建设和推广应用中来,在为大数据平台开源生态继续做出贡献的同时,联合社区各家实力强劲的大数据平台团队,协作共建先进的大数据平台套件。
所以,2019 年开始,微众银行开源了计算中间件 Linkis、数据应用开发管理集成框架 DataSphere Studio,以及 WeDataSphere 的其它 8 个组件,总代码量超过 80 万行。社区用户方面,涉及金融、电信、互联网、制造等多个行业,WeDataSphere 社区开发者超过了 110 位,社区代码贡献量超过 15 万行。
开源两年以来,微众银行还与社区一起开发共建了流式应用开发管理工具 Streamis、数据交换工具 Exchangis1.0 和 数据模型中心 DataModelCenter。
其中,Streamis 是微众银行 WeDataSphere 大数据团队联合天翼云、仙翁科技、萨摩耶云等企业开发共建的流式应用开发管理工具。整个项目由微众银行 WeDataSphere 大数据团队负责项目的整体协调和把控,天翼云大数据团队负责 StreamJobManager 前端的开发,仙翁科技负责 Stream JobManager 后端的开发,萨摩耶云则负责 StreamDataSource 模块的前后台开发。项目协同上,大家使用 GitHub 私有项目的形式进行代码管理,每周通过腾讯会议开一次周例会同步进度,共同解决开发测试过程中遇到的问题。比如,在开发 streamis-datasource-transfer 模块对接 Linkis DataSource 时,由于缺少 Linkis DataSource 模块,阻塞了 Streamis 的开发测试进展,后经微众银行 WeDataSphere 大数据团队与天翼云大数据团队多次线上沟通协商、共同推进,解决了 Streamis 依赖 Linkis DataSource 模块的问题。
对于未来发展,邸帅表示 WeDataSphere 团队将继续践行“Community Over Code”的“The Apache Way”开源文化主旨,打造一个更加协作、开放、多元的社区文化,持续降低社区用户的参与门槛,联合更多的组织和个人一起构建先进的大数据平台套件和世界级的大数据中间件开源项目。
写在最后
作为企业数字化转型的核心,大数据平台的构建是一个长期的战略性工作,涉及到技术选型、业务模型、团队建设、管理协作等多方面的事情,对于任何公司、任何团队来说,都是不小的挑战。
WeDataSphere 的建设已经持续了 5 年的时间,发展过程中也经历了很多挑战,他们的实践经验告诉我们,建设一个成功的大数据平台,必须不断地投入资源和精力,不断重复量体裁衣、完善和优化的过程,最终才能慢慢形成良性的循环,并从中取得比较好的收益和效果。
嘉宾简介:
邸帅,微众银行大数据平台负责人,WeDataSphere 社区主理人,Apache Linkis PPMC。
尹强,微众银行大数据技术专家,Apache Linkis PPMC,同时负责 WeDataSphere 中数据应用开发管理集成框架 DataSphereStudio、流式应用开发管理工具 Streamis 等系统的技术架构设计和开发。
项目仓库:
Apache Linkis(incubating) 计算中间件 https://github.com/apache/incubator-linkis
DataSphereStudio 一站式数据应用开发管理门户 https://github.com/WeBankFinTech/DataSphereStudio
Qualitis 数据质量管理平台 https://github.com/WeBankFinTech/Qualitis
Schedulis 工作流任务调度系统 https://github.com/WeBankFinTech/Schedulis
Exchangis 数据交换平台 https://github.com/WeBankFinTech/Exchangis
Prophecis 一站式机器学习平台 https://github.com/WeBankFinTech/Prophecis
Scriptis 交互式数据分析 Web 工具 https://github.com/WeBankFinTech/Scriptis
Visualis 数据可视化工具 https://github.com/WeBankFinTech/Visualis
本文选自《中国卓越技术团队访谈录》(2021 年第六季),点击下载全部内容,查看更多独家专访!本期精选了京东、微众、网易数帆、优酷、恒生等技术团队在技术落地、团队建设方面的实践经验和心得体会。
《中国卓越技术团队访谈录》是 InfoQ 打造的重磅内容产品,以各个国内优秀企业的 IT 技术团队为线索策划系列采访,希望向外界传递杰出技术团队的做事方法 / 技术实践,让开发者了解他们的知识积累、技术演进、产品锤炼与团队文化等,并从中获得有价值的见解。
如果你身处传统企业经历了完整的数字化转型过程或者正在互联网公司进行创新技术的研发,并希望 InfoQ 可以关注并采访你所在的技术团队,可以添加微信:caifangfang842852,请注明来意及公司名称。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论