
Meta 近日为 Instagram 推出了全新的机器学习排序框架,通过引入“多样性算法”(diversity algorithms)来减少重复内容的推送,从而缓解用户的通知疲劳,同时保持整体参与度。这个注重多样性的排序系统,通过在现有互动模型中引入“乘性惩罚”(multiplicative penalties),解决了平台上用户被相似创作者或产品类型内容过度曝光的问题。
这一框架主要针对两个痛点:一是用户频繁收到来自同一创作者的消息;二是算法过度倾向单一内容形态(如 Stories),而忽略 Feed 或 Reels 等其他内容。此前,Instagram 的机器学习模型主要以点击率和互动数据为优化目标,这在提升短期参与度的同时,也让通知变得过于重复,甚至被部分用户认为是“刷屏式骚扰”,导致他们关闭通知。
Instagram 工程师表示:
真正的挑战在于如何找到平衡点:如何在不牺牲个性化和相关性的前提下,让用户的通知体验更具多样性。
新系统作为一层“多样性过滤层”运行在现有的互动模型之上。它会从多个维度评估候选通知,包括内容类型、作者身份、通知类别以及所属产品区域(如 Feed、Reels 或 Stories)。对于那些与近期通知过于相似的候选项,系统会施加经过校准的“乘性惩罚”,降低其相关性评分。这种“惩罚系数”介于 0 到 1 之间,通过调整基础分数来降低重复通知的排名。工程师可以为不同维度配置权重,以微调“相关性”与“多样性”的平衡,让不同团队可根据自身产品需求灵活应用。
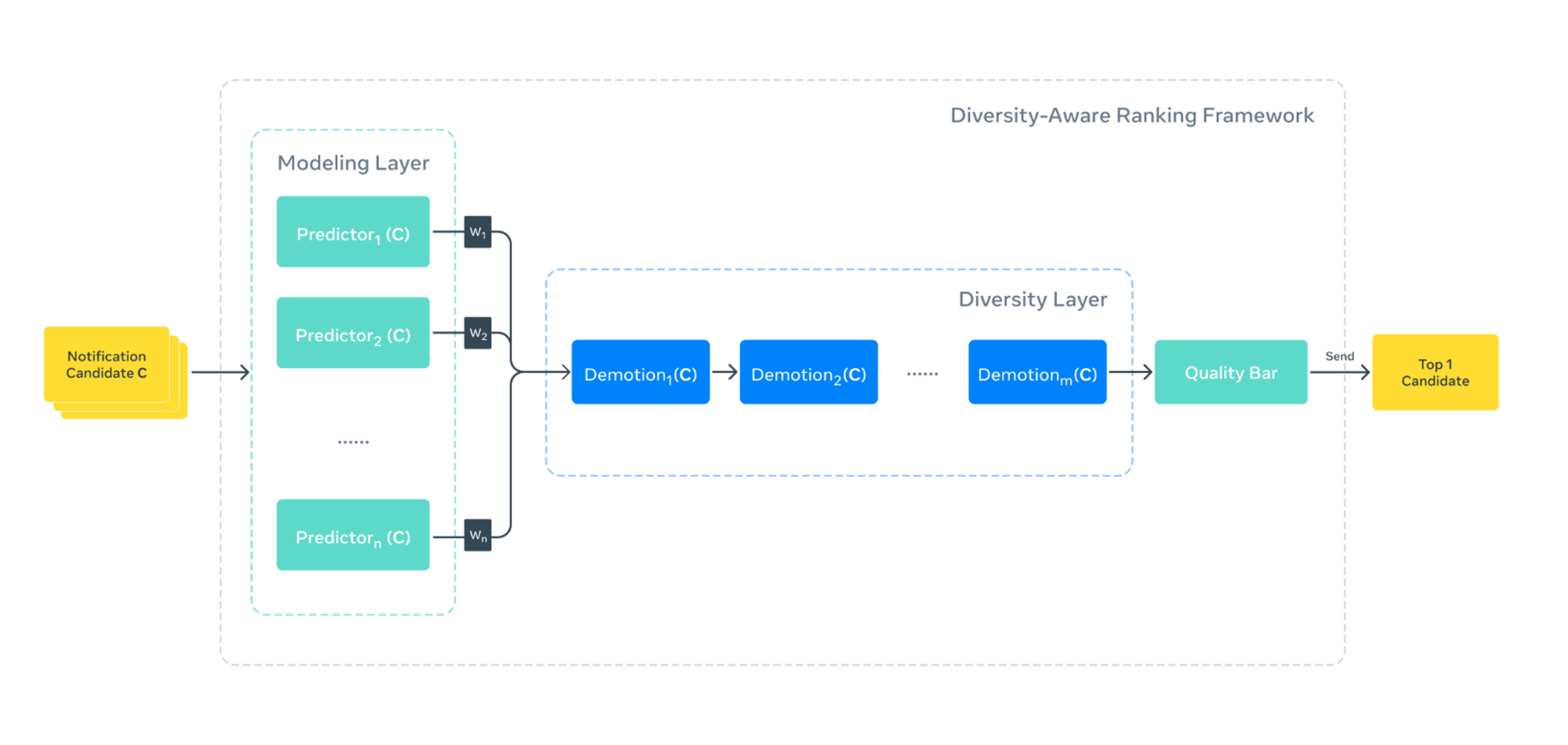
Instagram 的多样性排序框架(来源:Engineering at Meta 博客)
在数学实现上,该系统通过“基础相关性评分 × 多样性惩罚因子”的方式计算最终得分。每个语义维度上,系统会使用“最大边际相关性”(maximal marginal relevance)方法计算通知候选项与历史通知之间的相似度信号。若候选项在某个维度上超过设定阈值,就会被标记为相似,从而触发降权。
据 Instagram 工程师介绍,这一框架显著减少了用户每日收到的通知数量,同时提升了点击率。系统还支持在不同维度上自定义惩罚逻辑,并通过可配置权重调整降权力度,使算法既具备可扩展性,又能灵活应对不同的产品策略。其核心目标是在个性化与多样性之间取得平衡,让通知既保持相关,又避免审美疲劳。
Instagram 团队表示,下一步将探索“动态降权策略”(dynamic demotion strategies),即让惩罚力度根据上下文(如通知的时间点或频率)自动调整。同时,团队还计划研究如何利用大语言模型来衡量语义相似度,以进一步优化通知多样性。
Instagram 和 Meta 工程师所指出,这种方法体现了机器学习应用中的一个更广泛趋势:排序系统正从单纯追求个性化,转向在相关性与多样性之间寻找平衡。类似的算法理念也可用于推荐系统、搜索引擎及其他排序平台中,以减少内容冗余、提升用户体验并保持信息的新鲜感。
原文链接:
https://www.infoq.com/news/2025/09/instagram-notification-ranking/




