

如果你很希望找到一份数据科学家的工作,与其因为不知道自己需要哪类技能而感到烦恼,不如了解一下究竟哪些人在这方面获得了成功,这样对你更有帮助。最常见的特征组合可能是那些拥有计算机科学、工程技术、数学或分析学硕士学位或博士学位的人;那些已经在行业中工作了大约 4 到 6 年的人;以及之前曾是研究人员、软件工程师、分析师或数据科学实习生的人。但不要错误地认为这种组合就构成了数据科学家的大多数,这只是代表了概率的倍增。
与其专注于数据科学家所需的技能,不如看看他们之前实际做过些什么。
原文作者:Hanif Samad, 发布于 2019 年 8 月 1 日。预计阅读时间:12 分钟。
在写这篇文章的时候,我的 Towards Data Science 定制主页上的每一篇热门文章都在讨论如何应用或学习数据科学技能。每一篇都是如此。排名靠前的文章讲的是全局技能,例如《 作为数据科学家,如何与利益相关者合作》和《如何成为数据工程师》,接下来是一些非常具体的技能,包括批次梯度下降与随机梯度下降比较、多类文本分类、更快的R-CNN,等等。作为一个数据科学领域“共享概念、想法和代码”的媒体平台,这样的学习资源受到 Towards Data Science 追随者的追捧并不足为奇,因为他们可能已经涉足这个领域。但是,对于一个新手来说,难免令人感到气馁。他们需要被训练成为 Kaggler 高手吗?把神经网络用于图像识别或自然语言处理?都不是?既然一切都是关于如何把模型部署到生产环境,那么学习一下Kubernetes及其部署模型怎么样?Hadoop到底怎么了?
我在 LinkedIn 上把自己描述成一个软件工程师和数据科学家。从我的职场生涯来看,前半部分可能更准确,因为我在数据科学领域只获得过一个短期合同。在我放弃早期的医疗统计学家职业后,我想在我所在的国家(新加坡)找一份全职的数据科学家工作,然而这让我陷入了烦恼之中。我的一些熟人只有学士学位,但很容易找到工作,而我有医学统计硕士学位和 Web 开发大会的证书,但它们并没有我所期望的作用。网上疯传诸如“我如何找到怎样怎样的职位”之类的炫耀帖,这让我的耐心很快消磨殆尽,而事实上,这样的例子并不多。
我逐渐意识到,我把数据科学实际做的事情和如何成为数据科学家混为一谈了。让我感到吃惊的是,这两者并不是指同一件事情。与大多数新手一样,我把网络上的博文、数据科学职位的要求以及从事该领域工作的人的传闻汇总在一起。这些来源都在强调技能,还有一些用苛刻和道德化的语气强调数据科学家能够并且应该学习一大堆东西,而颇具讽刺意味的是,这把新手带入了一个追逐最新技术的死循环中,而最有效的策略可能是先迅速找到一个跟数据科学紧密相关的工作,然后在工作中学习这些技能。
我想我需要在吃早餐前掌握 10 个不可能的技能,因为我读过的有关数据科学家的文章,他们看起来似乎就是这样,但我没有想到的是可能已经有数千位已经成功入职的数据科学家,他们中的大多数并不是超级明星。我并不想再写一篇有关数据科学家需要掌握哪些技能的文章,而是想分析一下那些已经成功过渡到数据科学领域的人的真实数据。他们之前是做什么工作的?
我需要的是关于那些已经成功过渡到数据科学领域的人的实际数据。
有关数据科学家的数据
尽管已经有一些针对数据科学家进行大规模问卷调查的公开数据,但我发现这些数据存在一些问题:
自我选择偏差。由于这些问卷调查跟某类组织有关,并且是完全志愿的,因此受访者的某些个人资料可能导致样本出现过度偏差。我就发现了一个问题,那些对 TensorFlow 过分热情的参与者主导了 Kaggle 数据科学调查,这与数据科学在商业中的实际应用情况可能大不相同。
受访者偏差。受访者是百分百的志愿者,他们不太会有夸大头衔、教育情况或其他信息的动机。
市场代表性。我的主要动机是为了找到那些已经成功地在我的目标市场(新加坡)找到数据科学家工作的人的个人资料。从我已经知道的情况来看,市场问卷调查的主要参与者是有志于成为数据科学家的人(主要是学生),而新加坡数据科学家的具体信息相当有限。
在我看来,LinkedIn 无疑是一个我可以从中获取信息的地方。尽管仍然存在一些选择性偏差(LinkedIn 的算法也许没有把数据科学家的真正随机样本展示给我看),但我发现它被求职者和招聘行业广泛采用,将其作为内置检查,最小化受访者偏见,并确保个人资料的真实性。LinkedIn 的个人资料也受制于实际的就业市场。
此外,LinkedIn 允许我在搜索查询中指定个人资料的地理位置,如果需要,可以将其限制在新加坡。于是就剩下最后一个问题:如何获得数据。
爬取数据:不要说我没警告过你
关于爬取 LinkedIn 数据是否合法存在一些争议。尽管最近的一些先例说明这些数据是公开的,也就是说任何人可以获取,但其法律合法性并未得到证实。不管怎样,在试图爬取 LinkedIn 数据时,会遇到一些障碍:
LinkedIn 限制了个人资料免费查看次数的上限,爬虫程序很快就会达到这个上限(特别是我们又花了大量时间调试爬虫程序)。
LinkedIn 一直在悄悄地频繁改变他们的 HTML 标签,因而,基于当前标签属性集的爬虫程序只有相当短的寿命。
可以说,我开发的爬虫程序在 HTML 标签被替换前一直都很有用,足以爬取一个相当大的数据集(1027 份 LinkedIn 个人资料)。
通过使用搜索关键字“数据科学家和新加坡(Data Scientist AND Singapore)”,我从 LinkedIn 爬取了尽可能多的个人资料。我只考虑三个相关的数据元素:Current Position(现有职位,包括职位名称和雇主的名字)、Education(教育背景,包括最近毕业的院校和研究领域)以及 Experience(经验,包括职位、组织、之前工作的时间段)。只选择这三个元素不仅我为节省了开发和调试爬虫程序的时间,还把我试图不遵守 LinkedIn 服务条款而造成的潜在责任范围缩到最小。
在过滤了数据科学爱好者、学生和信息不足的个人资料后,我获得了 869 份数据科学家的个人资料。现在,我可以发问了:目前在职的数据科学家有哪些共同特征?
发现 1:大多数数据科学家拥有博士学位
数据中最令人注目的是,大多数(73%)从事数据科学家工作的人拥有本科以上的学历,这在别的地方也得到了证实。多数(55%)数据科学家拥有硕士学历,拥有博士学位的占了 29%,比拥有本科学位的人(21%)多。据报道,只有 6%的数据科学家持有 MOOC、训练营或非传统认证作从业资格。这表明未来的雇主会认可高学历,认为高学历更能满足数据科学家的角色需求。数据科学训练营或其他非传统认证项目可以替代学历的想法后所动摇。
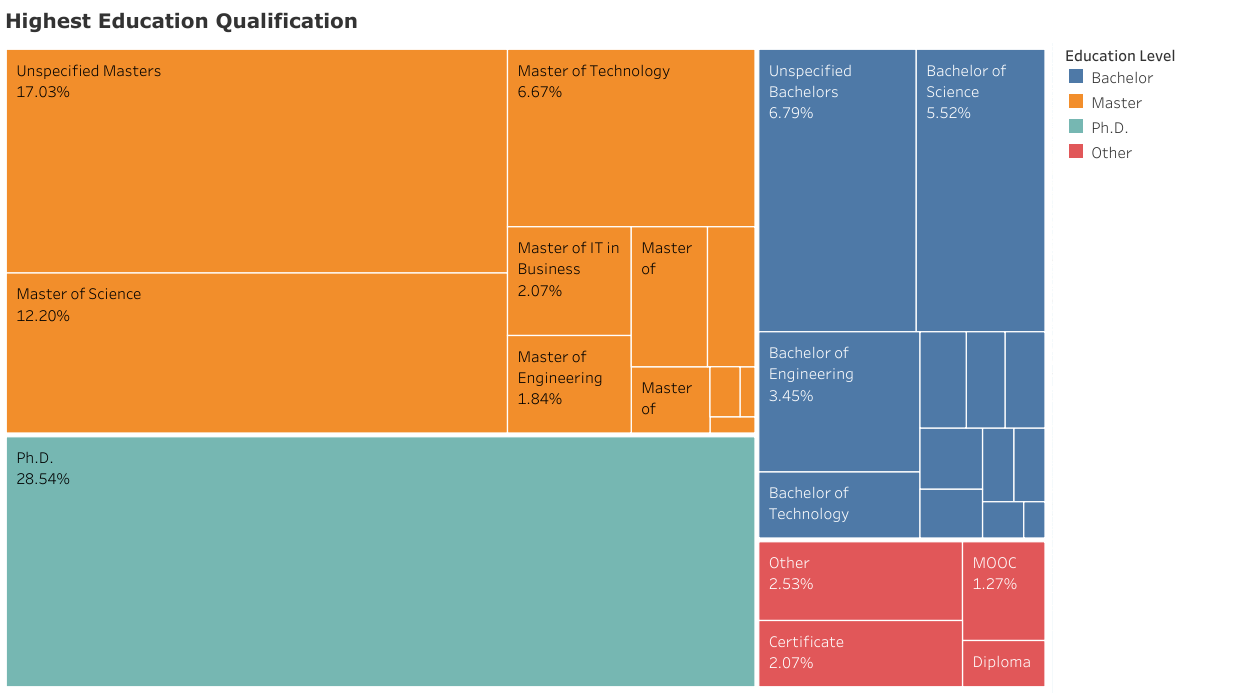
LinkedIn 数据科学家抽样报告中的学历划分
发现 2:计算机科学、工程和商业分析主导了研究领域
构成数据科学职业基石的计算机科学、数学和统计学及工程科学三位一体的概念在一定程度上得到了数据的证实。但还是有一些不一样的地方。到目前为止,计算机科学超过了其他所有的领域,占所有研究科学的 14%。工程学是个多样化的范畴,包括化学、电气和电子等领域,以及所谓的知识工程,加起来占研究学科的 22%。数学和统计学也以不同的形式出现,包括应用数学、数学物理、统计学和应用概率,但是,它们似乎只占研究科学更小的比例,累计约 12%。在数据科学教育领域,一个令人惊讶的赢家是商业分析和其他分析领域,加起来占所有学科的 15%。事实上,对数据科学家来说,这应该是排名最靠前的领域。据报导,这些数据科学家拥有的最高学位是硕士学位。
其他排名较高的领域包括:物理(3.5%)和信息技术(2.2%)。尽管与计算机和工程相关的领域显示出成为数据科学家的持续相关性,但数学和统计学的光芒在某种程度上被更新的面向商业的分析领域(及其相关变体)遮盖了。不过其他领域的长尾巴说明了当今数据科学家追求的领域的具有广泛的多样性。
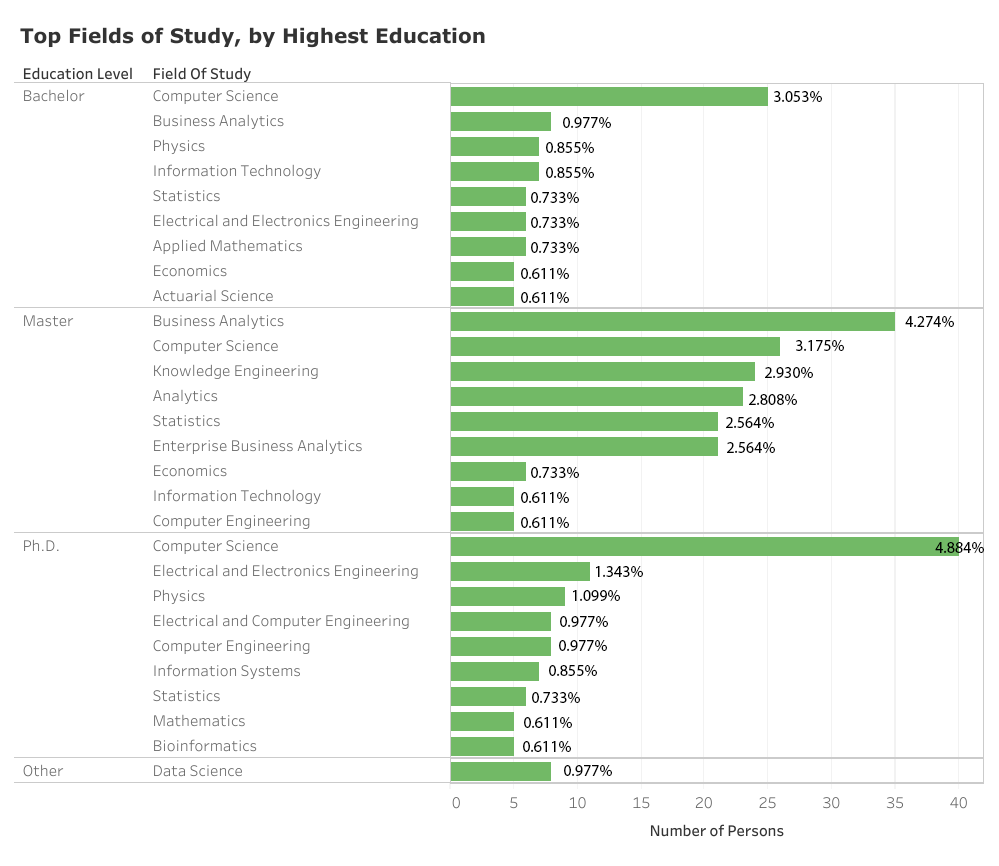
发现 3:当前在职的数据科学家大都处于职业生涯的中期
在抽样报告中,数据科学家的工作经验一般在 4 到 6 年之间,具体数字跟他们的最高学历有关。但值得注意的是,大多受聘数据科学家并不是那些从 MOOC 直接出来的大学毕业生。和大多数其他空缺职位一样,填补该职位空缺的人一般是有经验的人。
还有一个有趣的事实:这些数据科学家没有一个是刚完成非传统认证项目就找到工作的,他们通常至少有 1 年以上的工作经验。
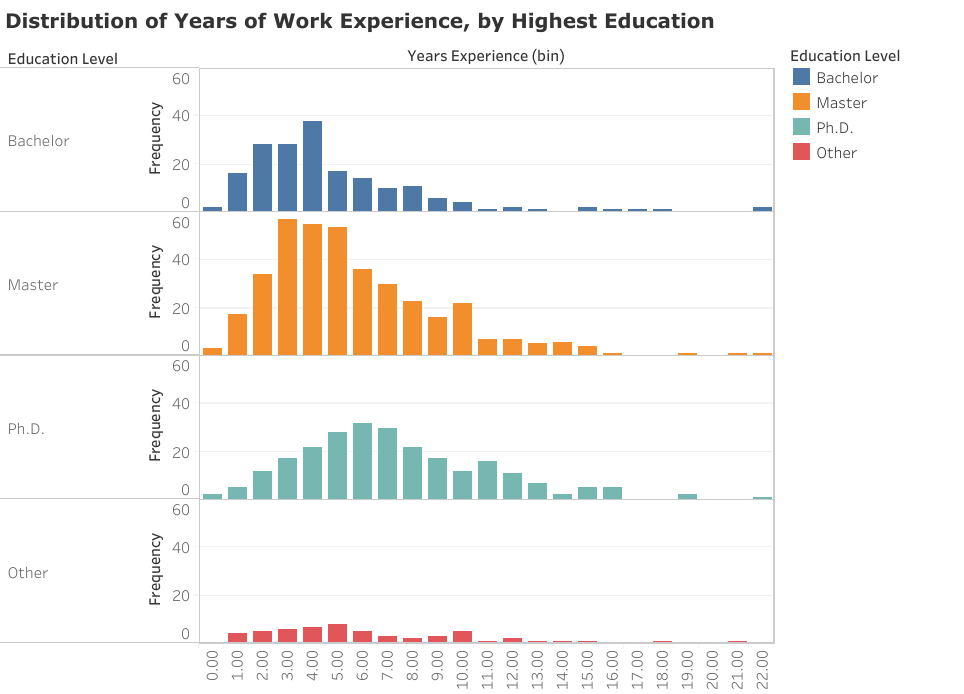
LinkedIn 数据科学家抽样报告表明他们有多年的工作经验
发现 4:大多数数据科学家职位都是新的
大多数数据科学家(76%)在目前职位上的工作时间不到 2 年,多数(42%)的工作时间不到 1 年。这表明尽管大多数数据科学职位空缺是最近出现的,但填补职位空缺的人已经在求职市场上等待了一段时间。
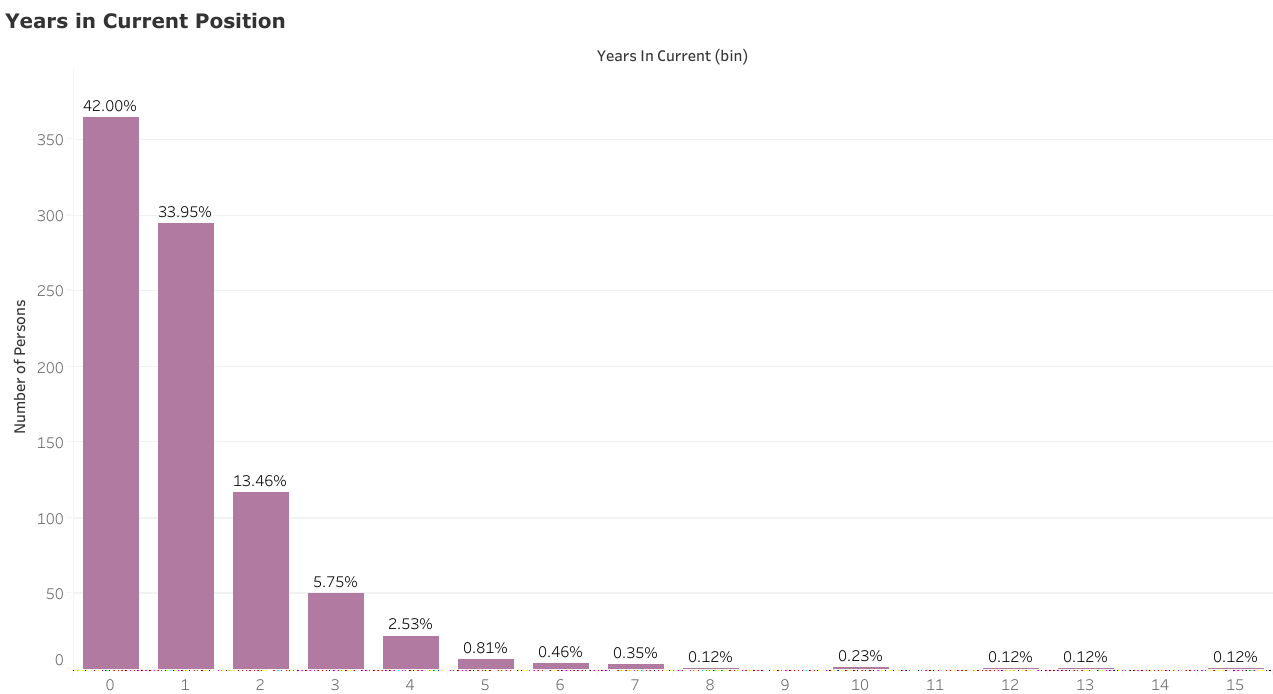
LinkedIn 数据科学家抽样报告显示他们目前的就职年限。“0”表示 0 到 1 年(不包括 1 年)
发现 5:你是研究员、软件工程师、分析师或数据科学实习生?很好。还是数据科学家?那更好。
我要找出数据科学家在从事目前的工作之前所做的事,这是我想要得到的核心发现。也许这并不令人感到意外(考虑到样本中研究生学位持有者占大多数),他们中的很大一部分(11%)之前曾经是科学家或研究人员(包括研究助理和研究员)。而相当一部分(11%)曾从事过某些形式的软件工程工作,包括开发人员和解决方案架构师。另一部分数据科学家之前曾从事分析师工作(11%),包括数据分析师和系统分析师。有趣的是,实习生和受训人员(11%)也属于成熟数据科学家角色的先行者类别,他们通常采用数据科学或分析实习的形式。其他排名靠前的前职位包括咨询(5%)、各种管理职位(5%)和数据科学指导职位(3%)。
抽样数据显示,28%的数据科学家之前就已经在从事这个工作。此外,这种在职优势似乎还在增加,比如:29%入职 1 年以内的人之前就是数据科学家,而在入职 3 到 4 年的人中,数据科学家只占 12%。
对我自己来说,从统计学家和精算师成为现职数据科学家的排名最为靠后。
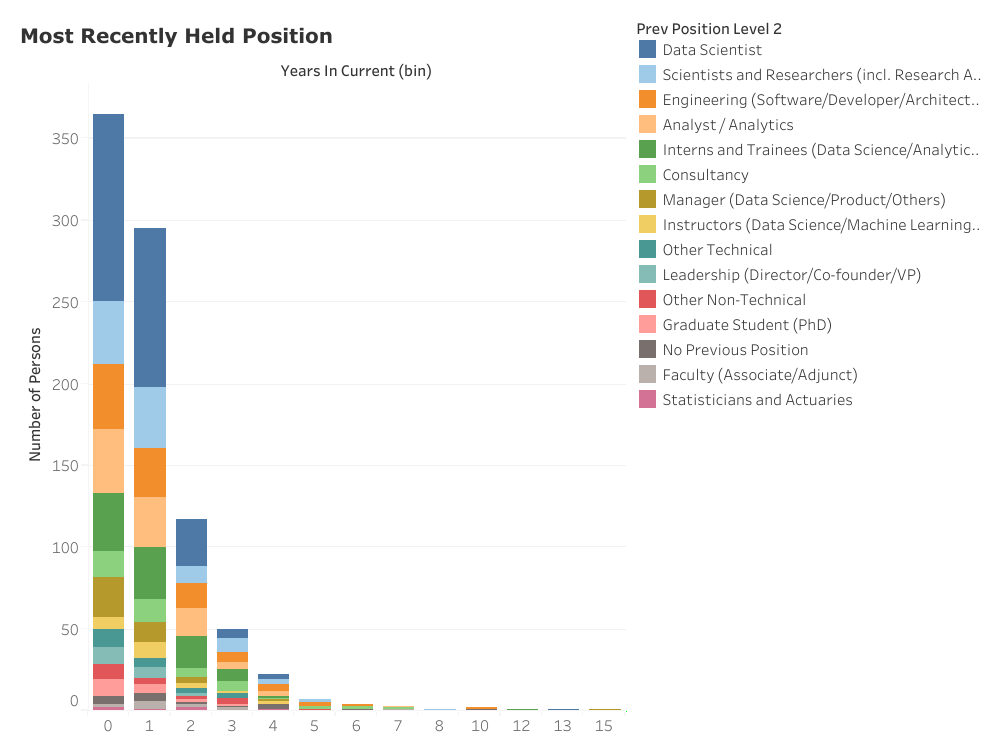
LinkedIn 数据科学家抽样报告显示最近的职位,按当前职位在职年限分组。“0”表示 0 到 1 年(不包括 1 年)")
发现 6:一半的数据科学家职位来自非技术公司
由于资金充足,成熟的技术公司(如谷歌或亚马逊)往往成为数据科学家就职的理想场所。但值得注意的是,样本中几乎一半(49%)的数据科学家来自于非直接创造技术产品的组织。这些公司和机构来自于:金融和保险(11%)、咨询(9%)、政府(5%)、制造业(5%)和学术界(2.4%)。在技术领域中,具有良好代表性的行业包括:交通(8%,主要归功于总部位于新加坡的叫车应用程序 Grab)、企业(8%,包括 IBM、SAP 和微软)、电子商务(5%)和金融(5%)。我们可以看到像星展银行之类的金融机构招聘数据科学家与像Refinitiv这样利用数据科学为机构创造科技产品的金融科技公司之间的区别。
我把一大类技术公司标记为 AI 和 ML(6.5%),包括像DataRobot这样的公司,它已经有交付过实际的自动化机器学习产品,还有像Amaris.AI这样的新公司。
如果把数据科学领域的非技术公司和技术公司出身的区分与其他地方提出的A类型和B类型数据科学家的特征对应起来,那么就可以很明显地看出,就业市场(至少在新加坡)一直在为这两种类型的数据科学家提供平等的机会,这将是一个有待验证的有趣且有价值的假设。
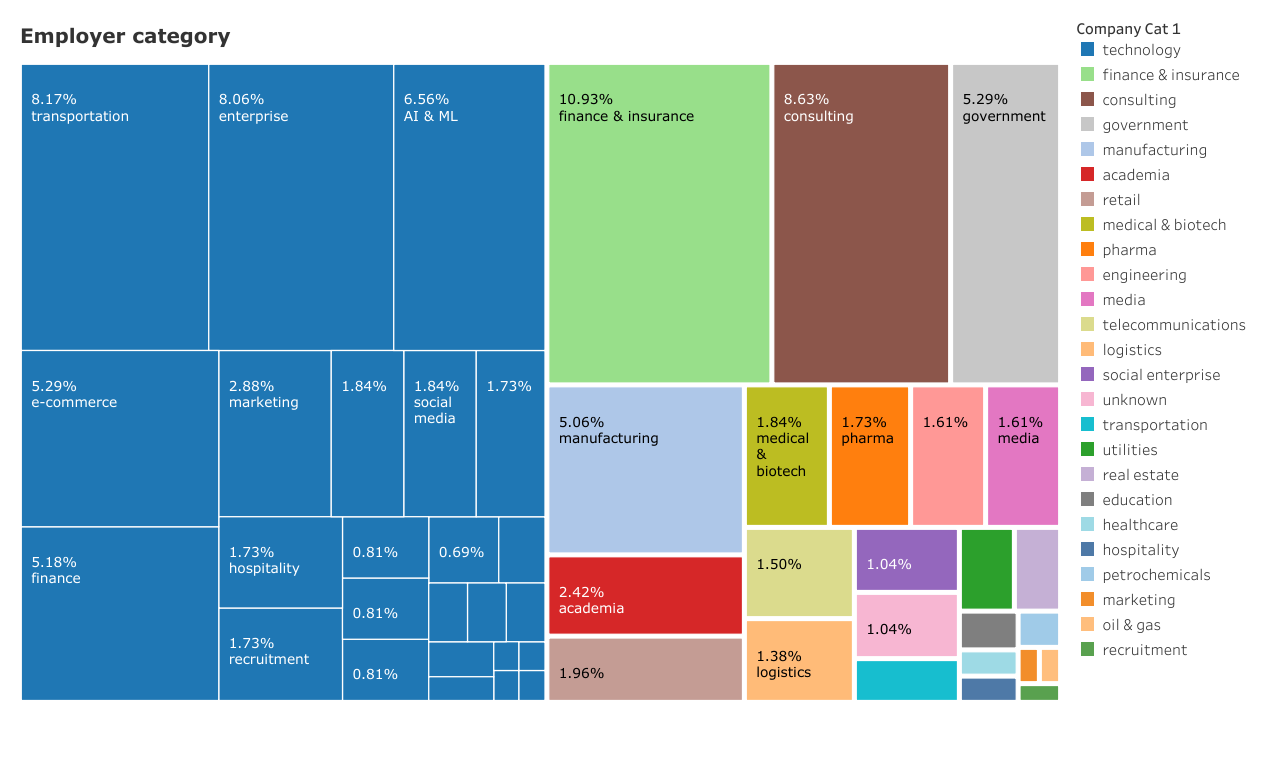
LinkedIn 数据科学家抽样报告显示的雇主类别
结论: 对我来说,所有这一切意味着什么?
如果你很希望找到一份数据科学家的工作,与其因为不知道自己需要哪类技能而感到烦恼,不如了解一下究竟哪些人在这方面获得了成功,这样对你更有帮助。最常见的特征组合可能是那些拥有计算机科学、工程技术、数学或分析学硕士学位或博士学位的人;那些已经在行业中工作了大约 4 到 6 年的人;以及之前曾是研究人员、软件工程师、分析师或数据科学实习生的人。但不要错误地认为这种组合就构成了数据科学家的大多数,这只是代表了概率的倍增。正如本文和其他研究所指出的,数据科学家的背景非常多样化,比起其他职位(如软件工程师)的多样性更丰富。
最后我要指出的是,尽管数据没有说明那些从 MOOC 和数据训练营等非传统证书机构获得技能的必要性,但确实表明了这些并非充分条件。研究生学位会更有竞争力。但这并不是说获取技能不重要,数据科学的发展速度很快,很多重要的算法和技术不会出现在传统的教学大纲里。这只是表明,特定技能的获取也许是为了满足某种需求,但不是马上就能让你入职数据科学家岗位。
关于数据科学的专业课程层出不穷,这些课程似乎是专门为那些感到不安的有志者而设计的。他们不断地被告知,只要掌握了那些技能就能够实现突破。在了解了那些真正入职数据科学家的人之后,他们应该清醒清醒了。
原文链接:I wasn’t getting hired as a Data Scientist. So I sought data on who is.

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论