

本文要点:
要做好性能测试很难,但花一些额外的时间做好性能测试是值得的,这样可以避免一些反复出现的问题;
要注意区分延迟测试和吞吐量测试,因为它们是系统的两个不同的方面;
在进行延迟测试时,要把吞吐量固定在一个水平;
在进行聚合时不要丢弃任何一个与性能有关的信息,要尽可能多地把它们记录下来;
只要多加小心,再加以自动化,就可以最大程度地避免出现性能回退。
对于像 Hazelcast 这样的内存计算平台来说,性能意味着一切。因此,我们在性能方面投入了大量精力,并在这个方面积累了多年的经验。
在这篇文章中,我将介绍一些常见的问题,并分享如何做好常规的性能测试。
性能测试中反复出现的问题
首先,测试环境差异是最常见的一个问题。如果一个系统最终要被部署到多台具有超强处理能力的机器上,那就不能够只根据在本地开发机上进行的性能测试做出合理的假设,因为在将系统部署到真实的环境中,结果会完全不一样。有趣的是,人们比他们自己认为的更容易犯这种错误。在我看来,其中的主要原因是懒惰(在本地测试很容易,但搭建额外的测试机器需要时间),意识不到这会成为一个问题,有时候是因为缺乏资源。
另一个反复出现的问题是测试场景不真实,例如,负载不够高、并发线程太少,或者完全不一样的操作比率。通常来说,在测试时要尽可能接近真实场景。也就是说,在开始测试之前,我们要尽可能多地收集与测试、用例、测试目标、环境和场景有关的信息,尽可能做到与真实环境相似。
下一个问题是不区分吞吐量测试和延迟测试,有时候甚至不确定是不是真的关心这两种测试。从我的经验来看,客户通常会更关心应用程序的吞吐量,于是他们就尽可能压榨系统的吞吐量,并基于这些结果做出决策。但如果你深挖下去,你会发现,在 99%的场景中,他们的负载都只是介于每秒多少个操作之间。在这个时候,可以把系统的吞吐量固定在这个水平,然后观察延迟,并进行延迟测试,而不是吞吐量测试。
最后一个问题是只关心聚合指标,比如均值和中值。这些指标把很多信息隐藏掉了,而这些被隐藏的信息很可能有助于做出更好的决策。本文的“评测性能”一节将更详细地介绍应该要收集哪些信息。
延迟测试和吞吐量测试之间的区别
吞吐量基本上是指某段时间内完成的操作次数(通常是每秒多少次操作)。延迟,也就是响应时间,是指从执行一个操作开始到接收到结果之间的时间。
这两个最基本的指标之间通常是相互关联的。在非并行系统中,延迟与吞吐量是成反向关系的,反过来也是一样。简单地说,如果每秒可以完成 10 个操作,那么每个操作(平均)需要十分之一秒。如果每秒种完成的操作越多,那么每个操作需要的时间就越少。
但是,在并行系统中,这种关系很容易被打破。以在 Web 服务器中增加线程为例,这样做不会缩短每个操作的响应时间,也就是说延迟不变,但吞吐量却提升了。
因此,吞吐量和延迟实际上是系统的两个不同的指标,我们要单独测试它们。更确切地说,在进行延迟测试时,我们要把吞吐量固定在一个水平,例如,“在每秒钟 10 万个操作的前提下测试延迟”。如果不这么做,在不同的吞吐量下系统延迟会发生变化,也就失去了可比性。
我们得到的经验教训是:在进行延迟测试时要使用固定的吞吐量。
收集和比较性能测试结果
另一个问题是如何收集、记录和分析性能测试结果。我觉得可以分为两个部分:一个是不要丢弃信息,一个是把分散的点连接起来。
我经常看到性能基准测试报告里会显示每秒平均操作数、中值或者延迟的某种百分位。的确,这样的报告看起来很简洁,也很容易发布出去。但是,如果你真的关心性能问题,就不要这么简单粗暴,你需要看到“所有”的数据。
在进行吞吐量测试时,一个常见的做法是讲总的操作数除以时间,这样做很容易就把重要信息丢掉了。如果你想要看到整体的情况,就需要显示吞吐量的变化过程。
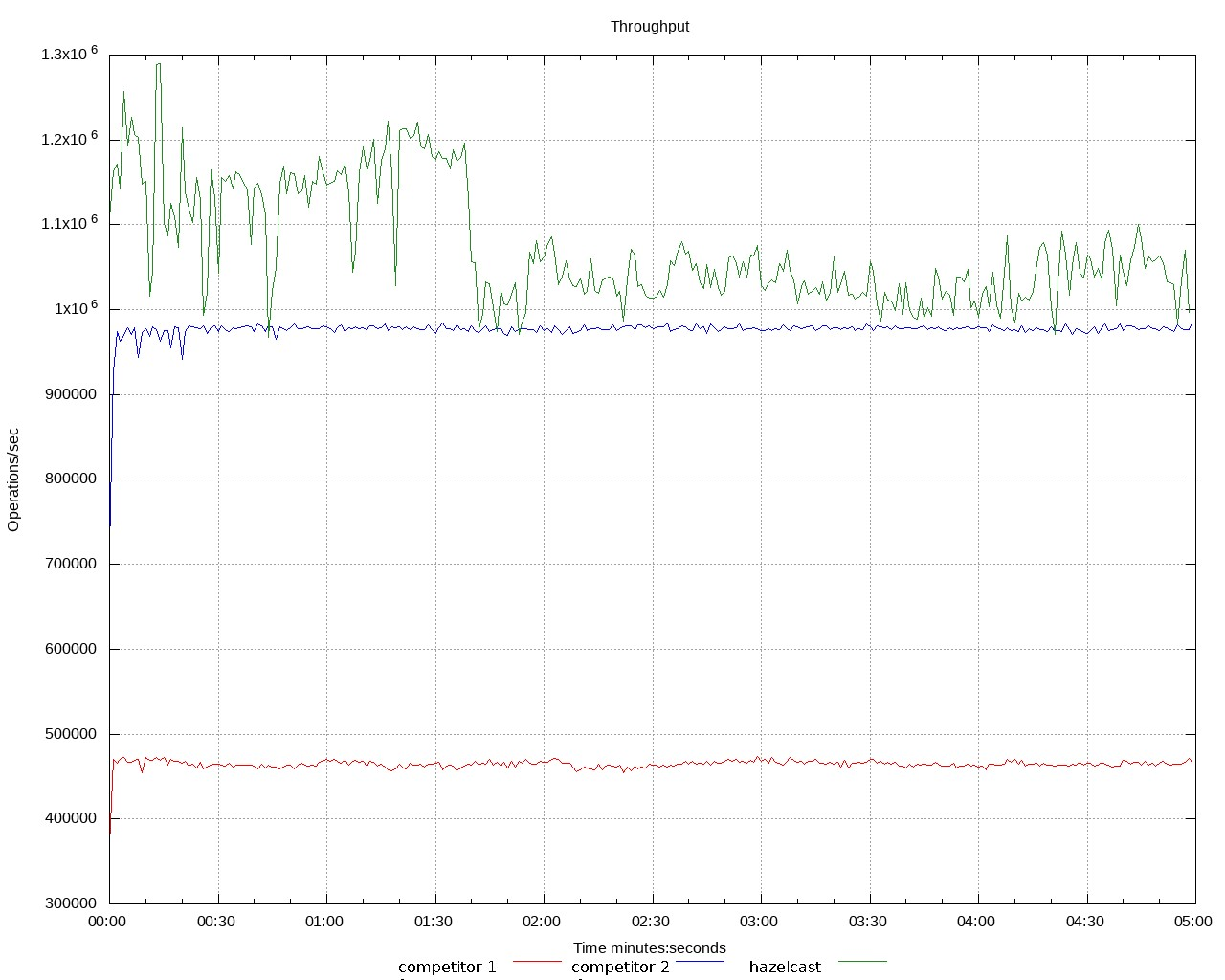
从这张图可以很容易地找到问题所在。根据简单的“每秒平均 X 次操作”,你可以快速地得出结论:绿线是最好的。但是,这张图看起来又有点奇怪。虽然绿线的吞吐量是最大的,但是也是最不稳定的。换句话说,绿线抖动得很厉害,一点也不平滑。我们基于这条线发现了线程调度问题。
总的来说,这张图显示了吞吐量的变化过程,但如果只是从聚合结果来看,是不可能发现问题的。我们可能会因为绿线的值最高而欢呼雀跃,但却忽略了一个重要的性能问题。
在进行延迟测试时,另一个常见的问题是只显示平均延迟,或者好一点的话会显示某种百分位。在理想情况下,你可以创建一个百分位直方图,让你可以看到整体的情况。你还可以做得更好,就是查看百分位随时间的变化情况。
作为例子,下图显示了 50 百分位随着时间发生变化的情况。
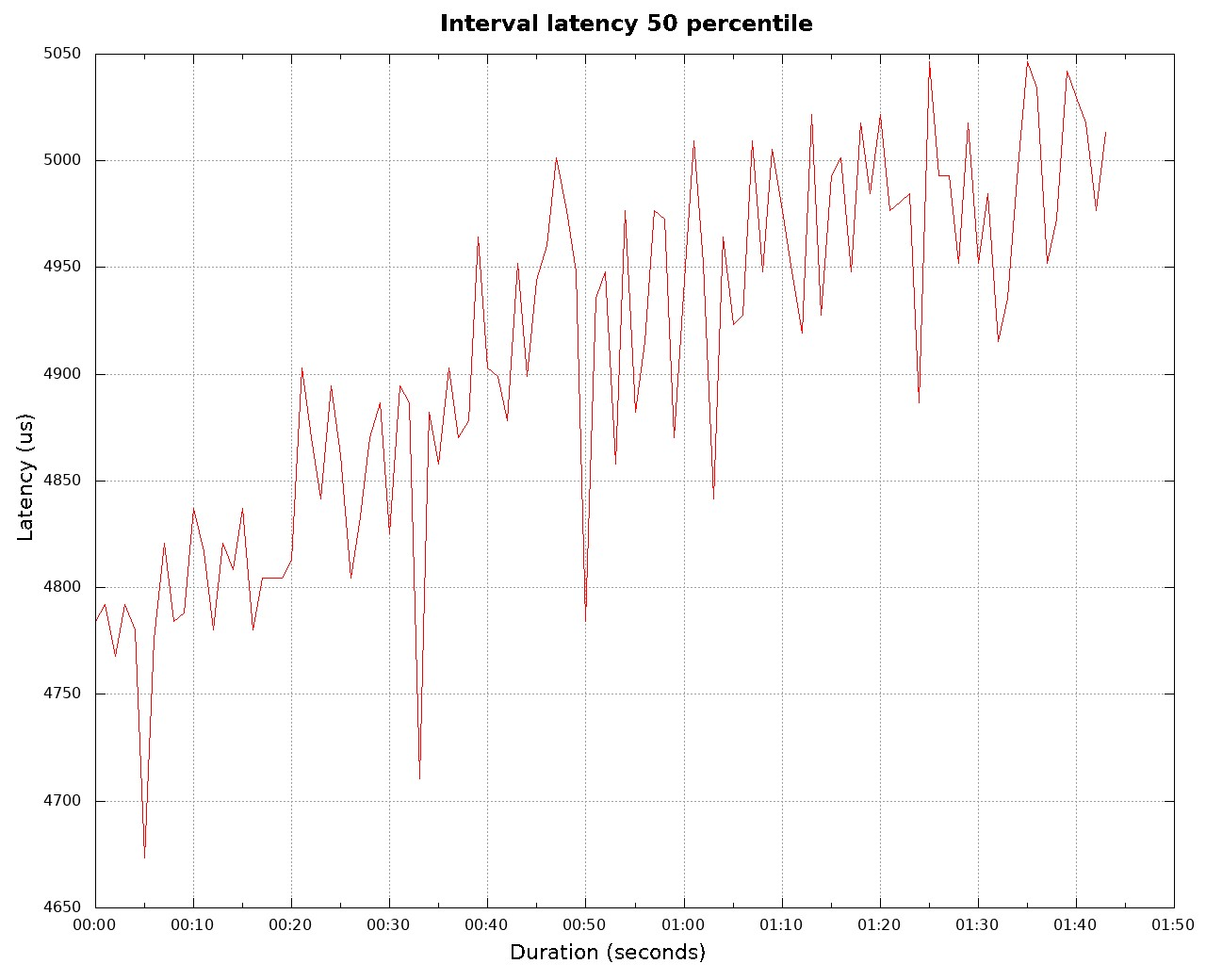
从图中我们可以清楚地看到延迟随着时间的变化而增长。如果我们只发布平均值或者是一个完整的直方图,就很难发现这些信息。我们知道,系统发生了内存泄露。
Gil Tene 的HdrHistogram是一个非常好的用来生成百分位和延迟图表的工具。
然后是同时查看所有的图表。如果你在其中的一张图中发现了问题,要在另一张图中进行确认。如果有性能问题,通常会在多个地方体现出来。
我们再以内存泄露为例。如果一个 Java 程序发生内存泄露,我们会看到内存使用量上升,这个时候吞吐量应该会下降,因为垃圾回收会占用更多的时间。与此相关联的是,延迟也可能会增加。我们也可以看一下线程的 CPU 时间,它们的 CPU 时间也会减少,因为垃圾回收占用了更多的 CPU 时间。信息越多,你就会得到更好的结论,就越容易找到解决问题的方案。
找出性能瓶颈
找出性能问题的根源通常是一个漫长而痛苦的过程,取决于具体的代码、测试人员的经验,有时候甚至是运气。但我们仍然是有迹可循的。
首先是逐步诊断,每次只诊断一个步骤。在进行性能调优时,我们通常会说“这个选项很好用,这样设置垃圾回收对性能有帮助,打开这个开关可以获得更好的结果,我们都试试吧”。最终,这种叠加效果导致我们搞不清楚哪个才是有效的。因此,每一次我们只走一步,只使用一个开关,只修改一个地方。
具体来说,我们可以利用所有可利用的工具,特别是在手机数据的时候。你掌握的信息越多,就越是能够更好地了解系统行为,更快地找到痛点。因此,我们需要尽可能收集所有信息:系统息息(CPU、内存、磁盘 IO、上下文切换)、网络信息(对于分布式系统来说尤为重要)、垃圾回收日志、Java Flight Recorder(JFR)的分析数据,等等。我们还开发了专有的诊断工具,更细粒度地直接收集内部信息——操作时间取样、内部线程池的大小和时间、内部管道和缓冲区的统计信息,等等。
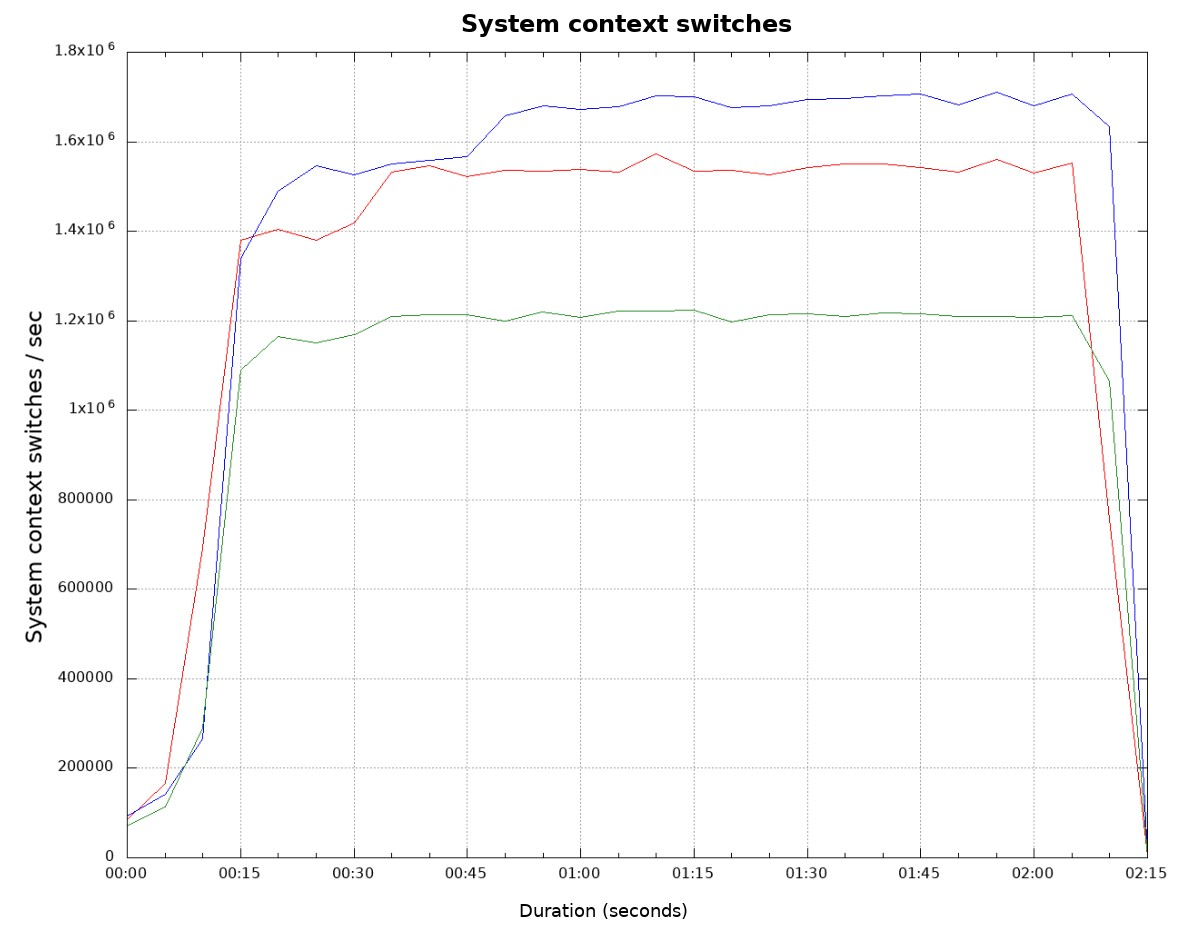
上图比较了三种调优选项的不同点,显示了每秒钟系统上下文切换次数。从结果看,绿线的切换次数最少,说明系统做的有用的事情更多,这个可以从吞吐量那张图中得到验证。
防止性能回退
进行常规(每天)自动化性能测试是很有必要的。在引入变更时需要尽可能快地获取必要的数据。在发现性能回退后,我们可以很容易将其隔离出来,极大减少用于修复回退所需的时间。
一个是执行测试,一个是保存和分析结果。在 Hazecast,我们使用PerfRepo,一个开源的 Web 应用程序,用于保存和分析性能测试结果。它会更新每一个最新的性能测试结果,所以很容易发现性能回退——你会在图中看到线往下走。我在 Red Hat 工作期间积极维护这个项目,因为时间原因,现在的开发进度慢了一些,但仍然是个完全可用的项目。
但不管怎么样,限制还是有的。我们无法面面俱到,因为各自情况的组合几乎是无限的。我们倾向于选择“最重要”的那些,但具体怎么做仍然值得我们讨论。
结论
要做好性能测试很难,很多方面都会出问题。关键在于要多注意细节,了解系统的行为,避免出现一些可笑的结果。当然,这需要时间。在 Hazelcast,我们也很注意这些,我们愿意为此付出时间和精力。你们呢?
作者介绍
Jiři Holuša是一个专注于开源的软件工程师,他热爱他的工作。之前在 Red Hat 工作,目前是 Hazelcast 质量工程团队的负责人。Hazelcast 是一家开发内存计算平台的公司。Holuša 喜欢深挖一个问题,从来都不放弃,直到问题得到解决。除此之外,他喜欢运动,作为一个真正的捷克人,他喜欢在喝啤酒时与别人进行愉快的交谈。如果你想看到更多由 Holuša 提供的有关性能测试的演讲,可以看他在 2019 年欧洲 TestCon 大会上做的Performance Testing Done Right演讲。你可以在 Twitter 通过 @jholusa 联系他。
原文链接:
Lessons Learned in Performance Testing
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论