
我们正站在人工智能新时代的门槛上,就像所有新时代刚开始的时候一样,每隔几天就会有一个新的技术方向/观点出现,上一个技术方向还没有落地就被拍死在半空中,就连大厂也无法保证一直领先。行业的参与者在面对日新月异的技术发展时,有时候是迷茫的、混乱的、纠结的,甚至是焦虑的。特别是对于很多中小型企业他们的机会在哪里?该怎么去选择?因为太多案例证明,今天花大量成本做的项目,明天就有可能被大模型轻松碾压,这就是大模型赛道的现状,对于本身“燃料”就不充足的中小企业,投入高昂的成本做模型相关的事情是有非常大风险的。
有没有一种低成本的方式让更多的企业有机会在 AI 赛道中找到自己的位置,本文分析了豆蔻大模型(一个经过微调的妇科大模型)案例,研究了大模型微调在构建垂直行业模型时的基模选择、数据准备与训练、效果评估和成本,为中小企业提供了一种可能。
该案例使用了一张英伟达 4090 GPU 卡(24G),基于 QwQ-32B 基模进行的微调,使用了近 2000 条标注数据,涉及妇科的 6 大症状,耗时 4 小时左右完成一次微调,通过系统自动化评估和多位妇科专家的严格评测,效果超过满血版。
通过对通用大模型进行微调构建行业垂直模型是必要的
通用大模型飞速发展,是不是就可以搞定一切?
RAG 和微调到底该怎么选?
微调的模型怎么选择,如何跟上基模的迭代速度?
垂直行业模型的微调成本多高?复杂度多高?
微调使用的数据如何构建?需要什么质量的数据?需要多少数据?
微调一次要花费多少时间?
量化微调对精度影响有多大?
理论上,通用大模型只要能够把社会上所有的数据都能拿到,进行训练,那么就会训练出搞定一切的通用大模型,但现实的情况是私有的数据、闭源的系统一定是存在的,有些数据是通用大模型无法拿到的,通用大模型可以快速成长为一个“医学博士生”,但很难成长为“妇科专家”。
通用大模型加 RAG 的组合,是当前很多 AI 专家推荐的大模型在企业内部的落地方式,这种组合就像特定领域的开卷考试,需要大模型能够理解特定领域的知识才能更好的读懂知识库,否则即便是开卷考试也很难达到理想的效果,另外,RAG 还有泛化的问题。在伯克利大学发表的论文《RAFT: Adapting Language Model to Domain Specific RAG》中,提出 RAFT-检索增强微调,通过微调使模型学习特定领域的知识,能够更好的理解知识库内容,还确保模型对检索到的干扰信息具有鲁棒性,可见微调是必不可少的。
大模型的发展路径告诉我们,要构建一个越来越聪明的大模型,而不是构建一个越来越复杂的知识库,在细分领域,通过基于私有数据对优秀的基模进行微调,实现垂直领域精度更高的大模型是必要的。
此次我们与壹生健康(闺蜜医生)一起合作,共同构建了一个成本低、迭代速度快、微调复杂度低、精度更高的妇科行业垂直模型,探索了一条中小企业发挥大模型红利的可行路径。
壹生健康豆蔻大模型
首先要确定基模和模型的大小,这直接影响到成本和效果。
作为创业团队,作为商业化为目标的项目,如何用最低的成本获得最佳的效果,是要重点考虑的。因此项目组对比了 7B、14B、32B、72B 四种参数量的模型的推理成本和回复效果,即评估多大参数量的模型在妇科诊断领域掌握了足够的医学知识。经技术人员多次测试和比较,32B 参数量的模型在计算资源和回复效果之间取得了最佳平衡,在 32B 的模型中,又对比了 Deepseek-Distill-Qwen2.5-32B 和 QwQ-32B,最终选择了 QwQ-32B,基于以下几点原因:
32B 有良好的医学知识预训练基础,足够应对复杂症状分析。
推理速度满足实时诊断咨询需求,具备现实可行性。
临床诊断对可解释性要求高,QwQ-32B 诊断推理思路条理清晰,与专业医学诊断基本保持一致,无大幅度的偏差。
QwQ-32B 的诊断结果和处理建议相对完整,表达通俗易懂,既不过于简略或啰嗦,也没有过多的专业术语。
参数规模可以在英伟达 4090 GPU 卡上即可进行微调和推理,解决成本问题。
然后进行微调数据的准备和微调,项目证明,高质量的标注数据是微调效果的关键。
模型微调的过程分为以下几个步骤:
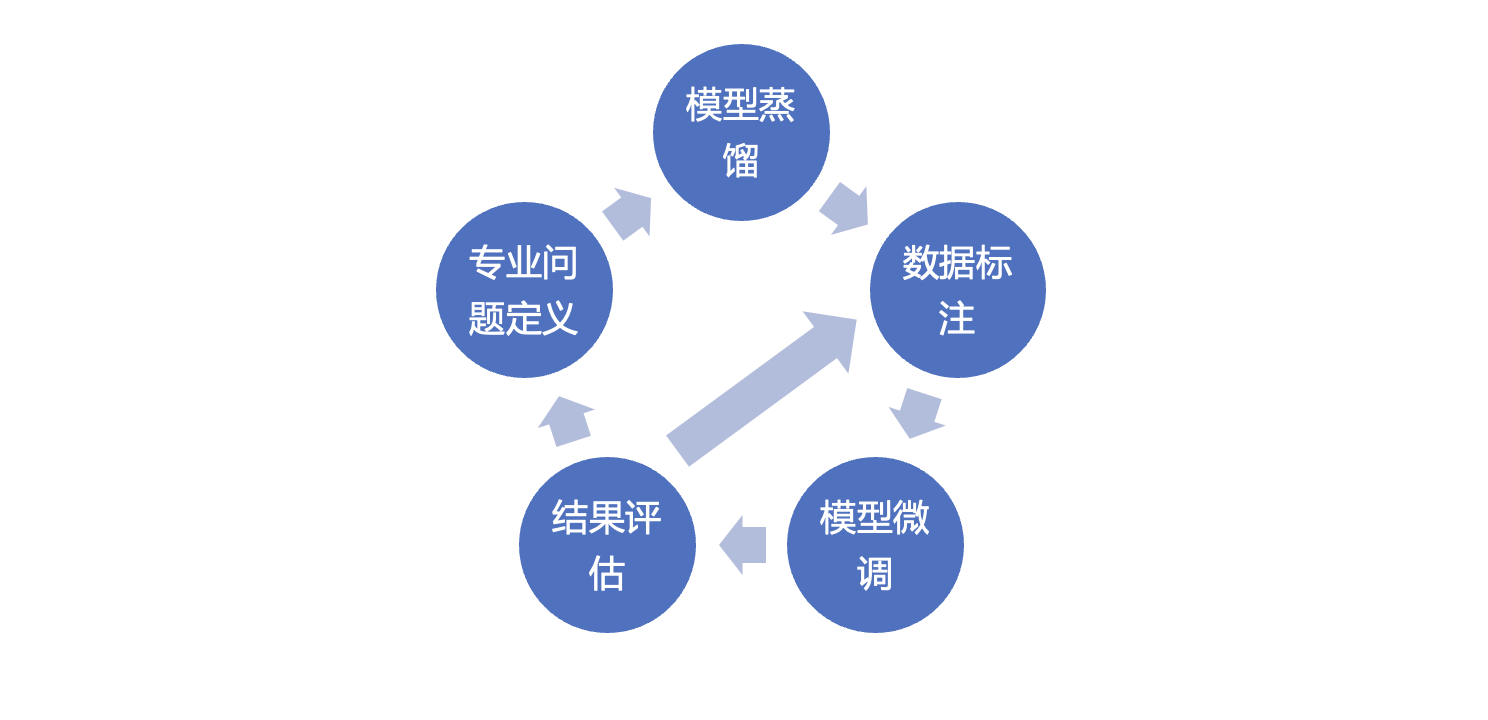
预先准备妇科专业问题。本项目的问题来自临床实际问诊问题,由妇科专业医生筛选了 1400 多个覆盖妇科各个板块的问题(经过脱敏)。
使用第一步准备的问题,用 DeepSeek-R1 满血版大模型进行蒸馏,得到微调需要的部分数据。在垂直模型微调的过程中,用大尺寸满血版模型进行蒸馏是准备训练数据的一个常用手段。
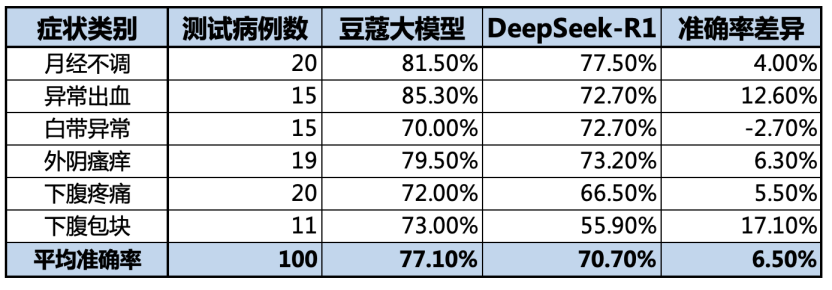
采用第二步蒸馏出的数据直接对 32B 的模型进行微调,测试结果见表二,其效果高于未进行微调的 32B 模型,但对模型的能力提升影响较小。
组织妇科医生对蒸馏出的数据进行标注,确保每一个诊断流程、每一条推理逻辑都符合临床实践标准,采用标注好的高质量数据对 32B 模型进行微调,量化为 8bit 做推理评估,在高质量的数据达到几百条后,其效果超越了满血版,但是在准确率上仍然与目标差距较大。下表为部分模型微调时的对比数据。

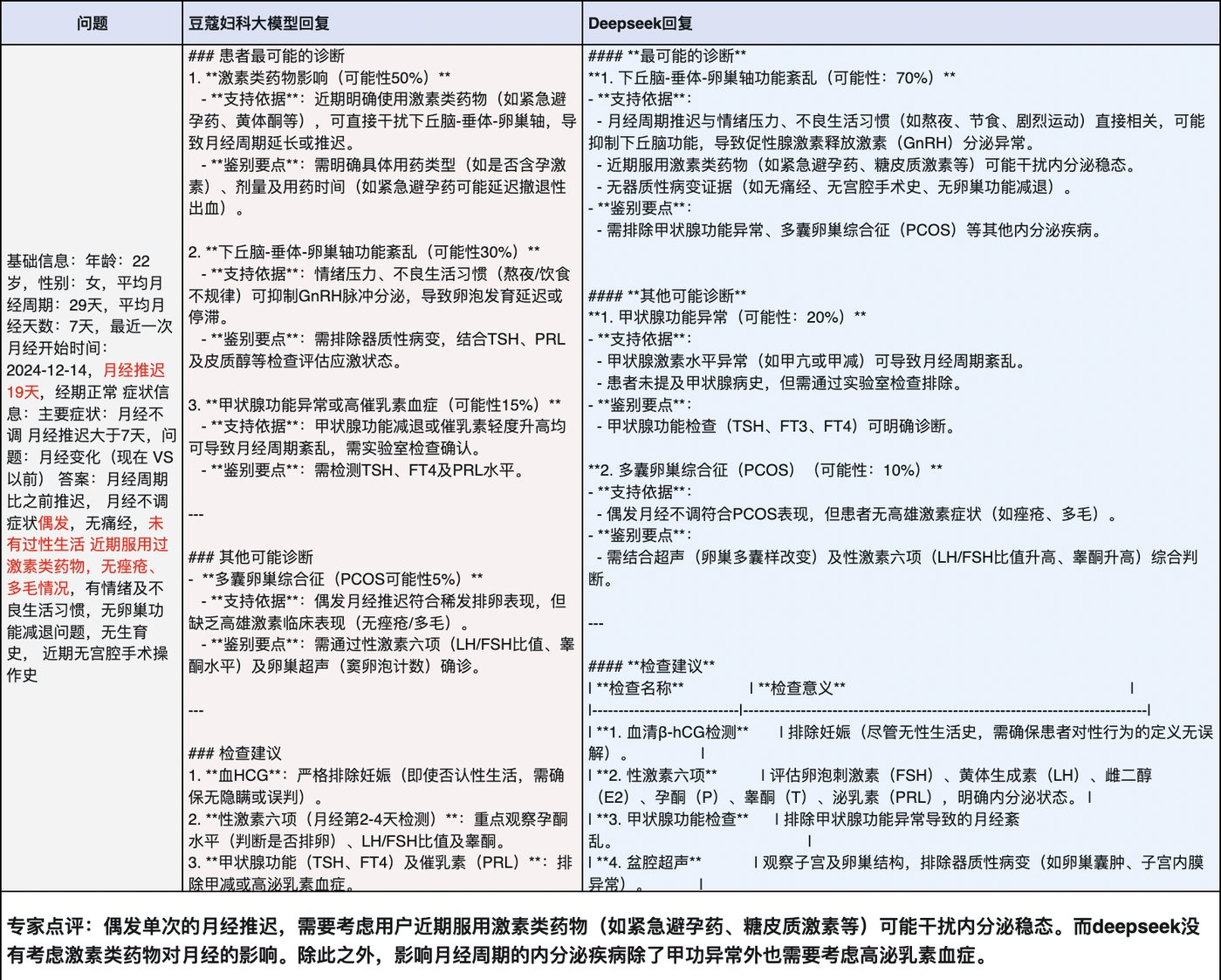
经分析,数据失衡成为关键瓶颈:其一,下腹包块病例数据量仅为其他症状的 1/10,导致该类诊断得分显著偏低;其二,下腹疼痛数据中左下腹病例占比超 70%,致使其他部位疼痛诊断效果不佳。为此,团队通过规则合成再补充了 600 例数据,并经医生团队多轮审核标注,最终构建起覆盖全症状、均衡化的数据集,最终准确率提升至 77.1%,达到了表一的结果,符合这一阶段的预期目标。
单张英伟达 4090 GPU 卡,4 小时完成一次微调过程,成本低、迭代快,解决了模型迭代的成本和效率问题
本次训练在贝联云算力平台( https://cloud.lccomputing.com )上完成,贝联云平台提供了数据标注、微调环境、推理服务、算力调度等完整的一站式模型微调、推理解决方案,让客户在平台上聚焦关注高质量数据的构建和模型微调效果的验证,降低 AI 使用门槛,让每个企业都能够最低成本的构建自己的垂直模型。
本项目最终是在 24G 显存的单卡 4090 上微调 QwQ-32B。随着微调数据量的大小变化,微调的时间也从几个小时到 28 小时(微调几万条数据)不等,基于我们对本项目的结果观测,针对妇科的场景,在 RTX 4090 上,基于 32B 模型,4 小时内可以完成一次微调,成本 20 元人民币左右,效果超过 DeepSeek-R1 满血版。微调中分布合理的高质量标注数据是关键,技术工具标准化,迭代速度快。
为什么要用 RTX 4090 来做模型微调?主要成本的原因。不论是 A800、H100、H20 等卡,成本都是比较高的,RTX 4090,成本和前面提到的卡低一个数量级,用最小的成本去创新,大大缓解了中小企业的压力。推理方面,4090 仍然是目前小尺寸模型性价比最高的选择,在同一个卡上完成微调到推理的闭环,不需要来回折腾数据和模型文件,能大大加快试错迭代的步骤,这是一个完美的组合。
为了能在 4090 上微调 32B 的模型,我们采取了如下组合:
用了 unsloth 训练引擎。unsloth 很好的结合了动态量化、Triton 优化内核与 LoRA 集成,并提供了方便的 SDK 封装。
训练时用 4bit 加载基础模型。通过非对称 4bit 量化将原始 FP32/FP16 权重压缩至 4bit 存储,结合 分块量化(Blockwise Quantization) 和 动态反量化(Dynamic Dequantization) 机制,在训练时将权重动态恢复至 FP16 精度进行梯度计算。可以节约 75% 显存且能保持很小的误差。
开启 lora 微调, lora rank 为 32; 通过 lora 技术冻结原始模型参数,仅训练秩分解矩阵,大大节约了算力和显存占用量。
训练完成后,考虑部署推理的成本,我们希望把模型量化成更小的精度,以便于在更少资源的英伟达 4090 上实现可承受一定量的业务并发请求。基于此我们对训练后的模型分别做了 INT8、INT4 精度的量化,并测试精度下降后对结果准确率的影响。经测试,量化到 INT4 后的模型诊断准确率降低了 5%,有较为明显的下滑,而 INT8 的量化的影响很小,可以忽略不计,所以最终选择了 8 位的量化版本。
Agent 最近火出天际,微调版的垂直行业模型,不正是 Agent 里面的一个子专家 Agent 吗?关于这一部分,我们下一次详细聊,如何构建一个专有的 Agent,为企业服务。




