
演讲嘉宾 | 韩剑,字节跳动商业化技术 AIGC 算法工程师
以 ChatGPT、DeepSeek 为代表的大语言模型取得了巨大的成功,掀起了全球新一轮 AI 浪潮。但是在视觉生成领域,目前主流的方法却是一直以扩散模型为主导。与大语言模型采取相同技术路线的视觉自回归方法因为具有更好的 scaling 特性,能够统一理解 & 生成任务,隐藏着巨大的潜力,正受到人们越来越多的重视。
本文整理自字节跳动商业化技术 AIGC 算法工程师韩剑 6 月份在 AICon 2025 北京站的分享《Infinity:视觉自回归生成新路线》。本次演讲以被选为 CVPR 2025 Oral 的工作 Infinity 为例,详细介绍自回归视觉生成的底层技术原理。并以图像生成和视频生成两个具体场景,分享最新的研究成果和相关思考。
12 月 19~20 日的 AICon 北京站 将以 “探索 AI 应用边界” 为主题,聚焦企业级 Agent 落地、上下文工程、AI 产品创新等多个热门方向,围绕企业如何通过大模型提升研发与业务运营效率的实际应用案例,邀请来自头部企业、大厂以及明星创业公司的专家,带来一线的大模型实践经验和前沿洞察。一起探索 AI 应用的更多可能,发掘 AI 驱动业务增长的新路径!
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
自回归模型和 Scaling Law
自回归之所以得名,是因为模型将自己预测的 token 作为输入,预测下一个 token。然后再把预测结果作为下一步的输入,继续迭代。这个循环天然契合语言的离散序列特性。然而视觉信号没有天然的离散单位,于是必须把图像先“翻译”成 token:先用编码器压缩,再用解码器重建,把连续像素变成一串可索引的离散符号,才能套进自回归的框架。过去的工作大多沿用这条思路:要么直接以像素为 token,要么借助编码器 - 解码器把图像离散化后再做下一个标记预测,由此衍生出自回归文本到图像或类别到图像任务上的早期范式。

谈到自回归模型,就无法回避 Scaling Law——它正是我们对自回归模型持续抱有热情的核心原因。在语言模型中,我们发现,只要模型、数据与算力三者中的任意一项扩大,而其他两项保持不变,性能便会按幂律提升;在小规模实验里测得的曲线,可以准确预测大规模训练的最终损失与精度。凭借这条规律,我们得以用可控的小规模试验推演“堆大模型、堆大数据、堆大算力”后的收益,从而笃定地继续扩张。

在视觉生成领域,这条规律却一度显得模糊。早期的 iGPT 直接以像素为 token,沿光栅顺序逐点自回归,结果受限于分辨率——token 数量爆炸,只能生成极小图像。随后出现的 VQVAE 引入矢量量化码本,将连续特征映射为离散索引,把空间分辨率压缩 8 倍乃至 16 倍,显著减少了 token 数;VQGAN 更进一步,用判别器强化量化后的重建质量。到了 2022 年,Google 的 Parti 把这一范式推向 20 B 参数规模,成为当时的里程碑。然而,这些努力仍留下四个悬而未决的问题:其一,生成质量在高分辨率下仍落后于扩散模型 DiT;其二,视觉离散 token 的 Scaling Law 尚未被系统验证;其三,光栅扫描顺序导致推理步数过长,效率低下;其四,从直觉上讲,人类看图是整体感知,而非逐行逐列地扫读,光栅顺序似乎天然与视觉模态相悖。

视觉自回归 v.s. 扩散模型
画过素描的人都知道,起稿往往先用几根轻淡的线勾出骨架,再逐层补上细节;视觉自回归模型 VAR 采用的正是这种“由粗到细”的思路。我们把一张图像拆成多级分辨率——从模糊的小图开始,逐级放大到清晰大图——让网络像人眼一样先抓住整体结构,再慢慢补全纹理。相比 Parti 那种全程在单分辨率上按光栅顺序逐点描摹的做法,VAR 的多尺度透视过程显然更贴近图像本身的物理属性。
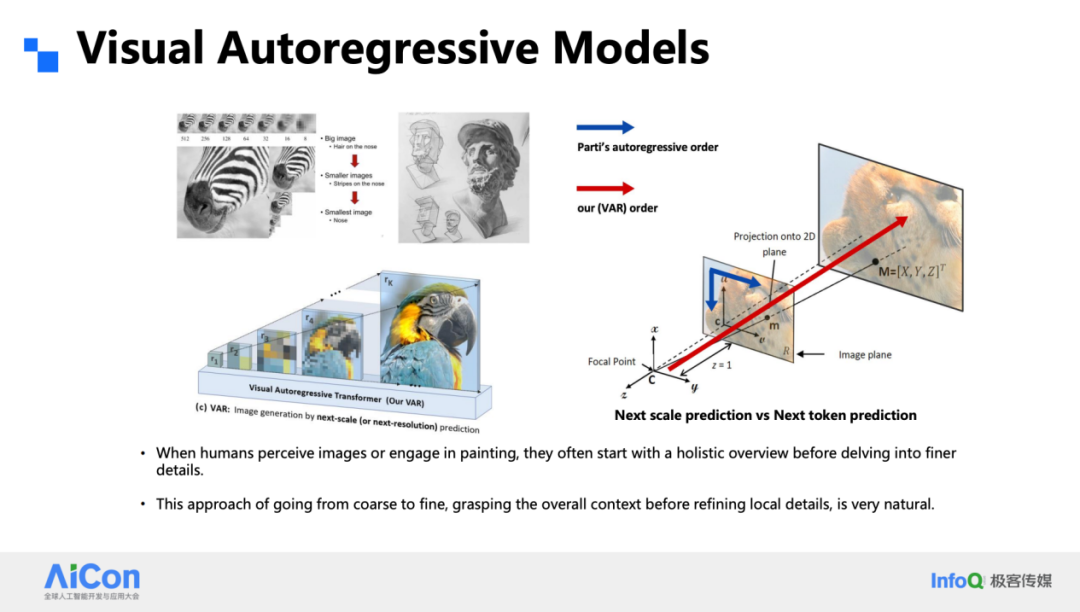
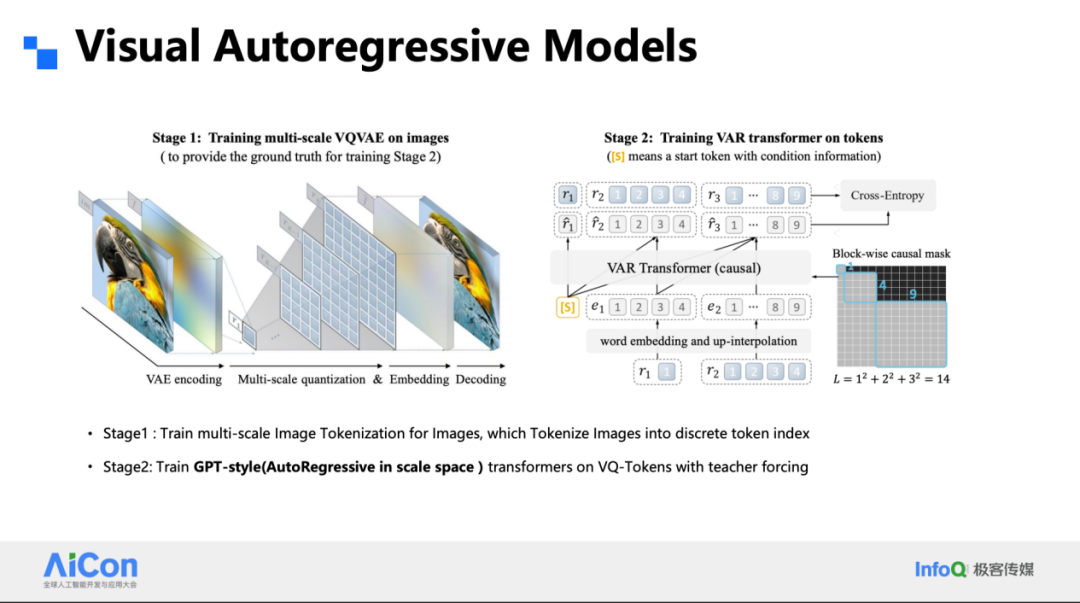
具体实现上,我们把任务拆成两块。第一块是改进后的 VQ-VAE:它不再是扁平的单一尺度,而是金字塔式的层级结构,把输入图像编码成 R₁、R₂……Rₖ 一系列逐级放大的特征残差。残差设计保证了每一级只需补全上一级尚未刻画的信息,既省 token,又易收敛。第二块是专为 VAR 定制的 Transformer:它不再一次只猜下一个 token,而是一次并行地预测一整片 token——例如 1×1、2×2、3×3 的小方块——从而把迭代次数压到传统逐点方式的十分之一。
在 ImageNet 的基准上,VAR 首次在生成质量上超过了 DiT,这一点已经给了我们足够的惊喜。更关键的是,它展现出清晰而稳健的 Scaling 曲线:把模型继续做大,性能仍按幂律抬升。这条曲线像一盏绿灯,让我们继续加码算力与参数。

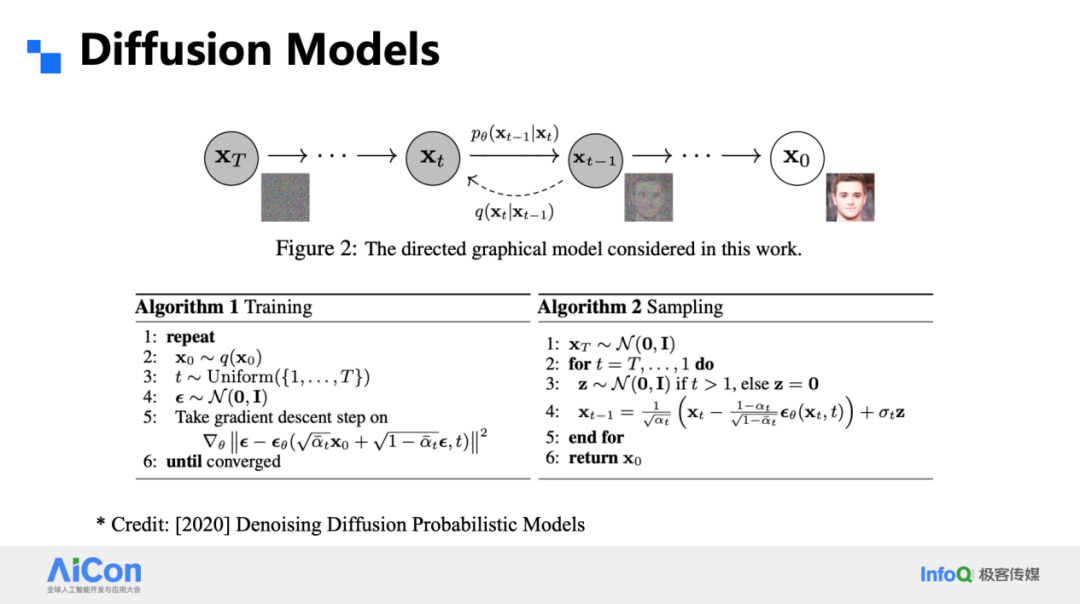
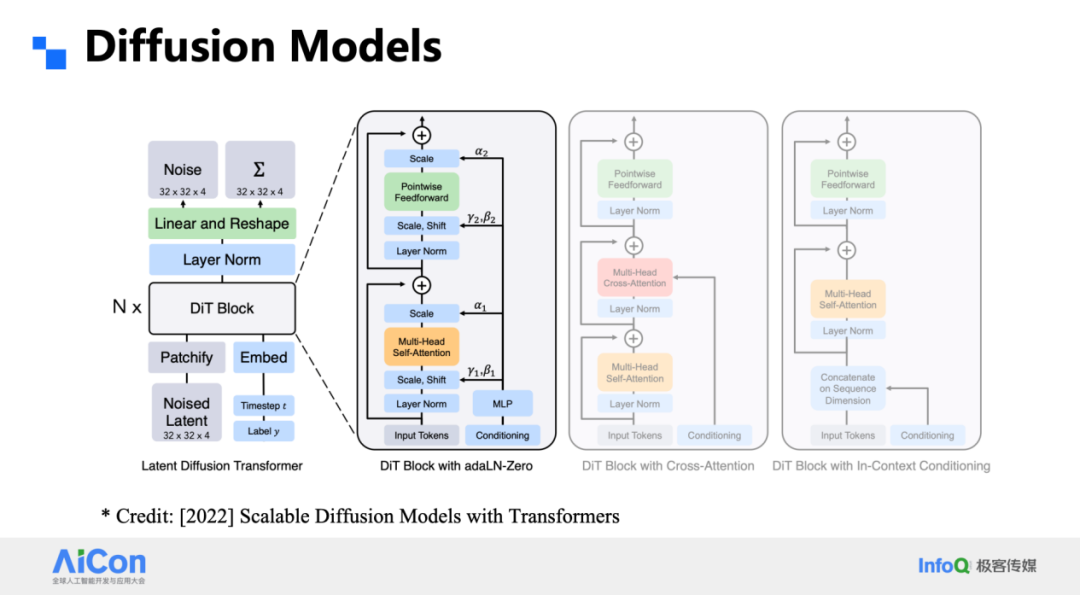
扩散模型的核心思想是在原始分辨率上给图像逐步添加高斯噪声,把清晰样本 X₀ 一路加噪成高斯分布;随后训练一个网络反向去噪,从 Xₜ₋₁ 一步步还原出 X₀。整个过程在同一尺度完成,空间分辨率保持不变。
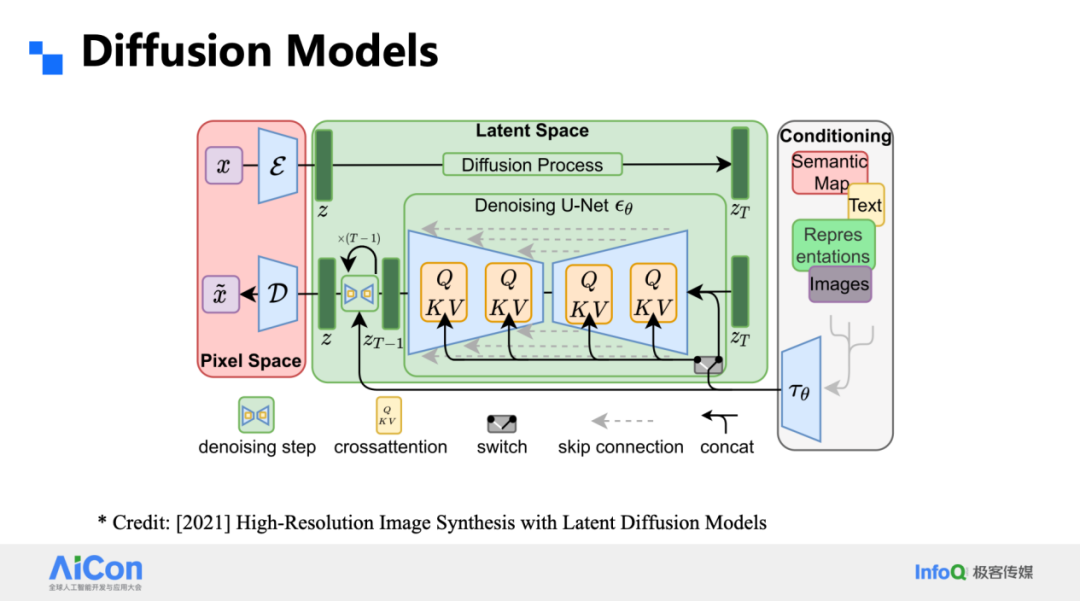
LDM 把这一思路引入条件生成:编码器先把图像压进潜空间,再在潜空间里做扩散,条件是文本、深度图或其他语义信号。注意,这里所有表征都是连续的,而 VAR 或我们稍后谈到的 Infinity 则坚持离散 token;LDM 也是单尺度,而我们的工作有层级金字塔。
DiT 进一步把 LDM 里的 U-Net 换成 Transformer,关键改动在于用层归一化替代批归一化,并调整整体结构,使模型在扩大规模时仍能优雅地服从 Scaling Law。沿着这条路线,人们把模型、数据、算力一路推向极限,最终孕育了 Sora,也让扩散方案彻底点燃了视觉生成领域。
把 VAR 和扩散放在同一张流程图里,二者都在“把噪声变成图”,但是 VAR 从低分辨率逐级放大,每次只在残差里补细节;扩散则始终维持原始分辨率,从纯噪声开始一步步去噪。
VAR 的优势在于训练并行度高:所有尺度一次喂给网络,不像 DiT 必须按时间步拆成多次前向。同时,由粗到细的过程与人类直觉一致,解释性强。代价是误差会沿着尺度累积;扩散在同一分辨率反复迭代,误差可被后续步骤修正,但训练和推理的步数开销更大。
Infinity:视觉白回归生成新路线
把 VAR 从类别到图像扩展到文本到图像,我们遇到了三个最棘手的障碍:离散 VAE 的重建质量、自回归的累积误差,以及高分辨率和任意长宽比的支持。VAR 的原始 VQ-VAE 在 256×256 或 512×512 方图上还能勉强应付,一旦拉到 1024×1024 或自由长宽比,高频细节立刻崩坏;更严重的是,teacher-forcing 训练没有显式纠错机制,早期 token 的错误会一路放大,最终输出面目全非。
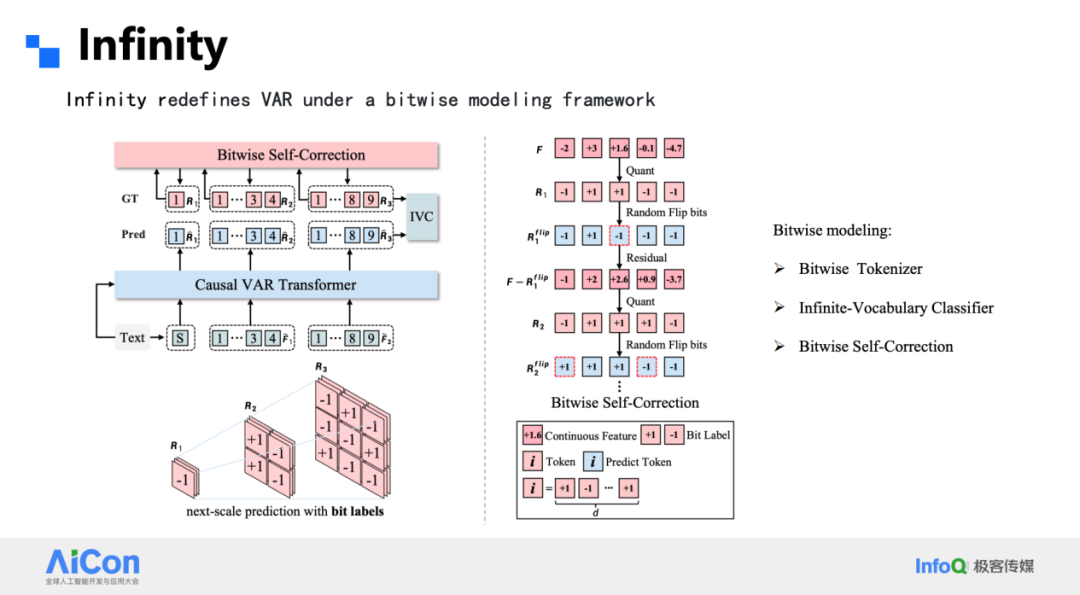
为此,我们把整个框架进行了升级,核心是“bitwise tokenizer + bitwise classifier”。
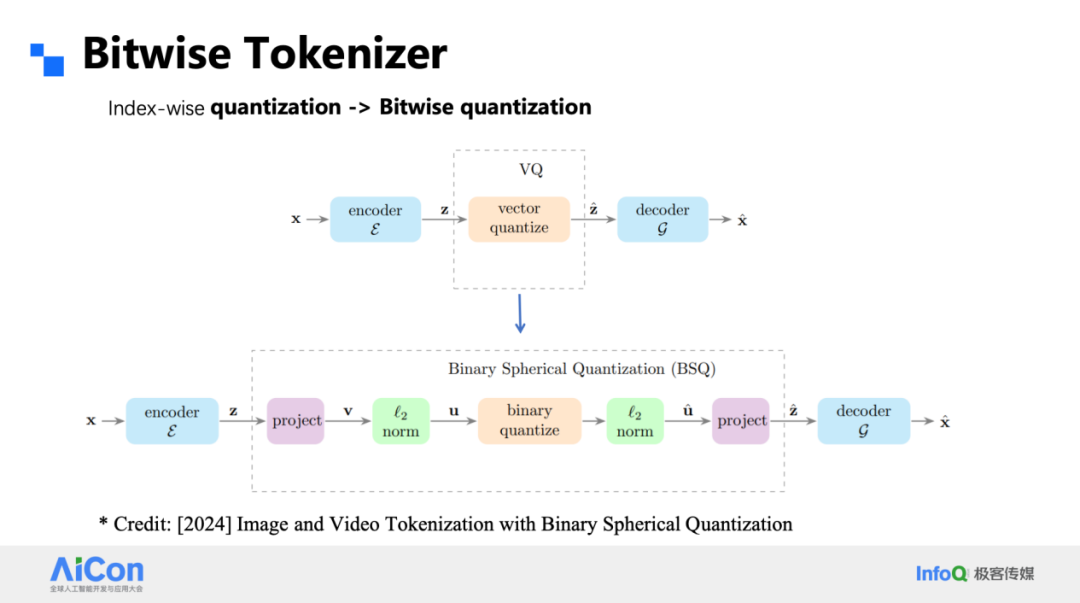
Tokenizer 侧,我们放弃了传统 VQ 的码本,直接对特征做符号量化:把每个通道的激活按正负号压成 ±1,形成 1-bit 表示。由于没有码本,词表大小随通道数指数增长(d 通道即 2^d 种组合),且不存在码本利用率问题。配合多级残差金字塔,1×1、2×2、4×4 … 逐级上采样,16 步即可覆盖 1024×1024 图像;32 通道时重建质量已超越 SD 的连续 VAE。
词表大到 2^32 时,传统分类头参数会反超主干 Transformer。我们把 token 拆成逐位预测:对每个通道独立做二元分类,而不是一次性预测整个组合索引。这样不仅把参数量从 100 B 降到可接受范围,还天然对微小扰动鲁棒——翻转一位只影响 1 bit,而非整个索引突变。

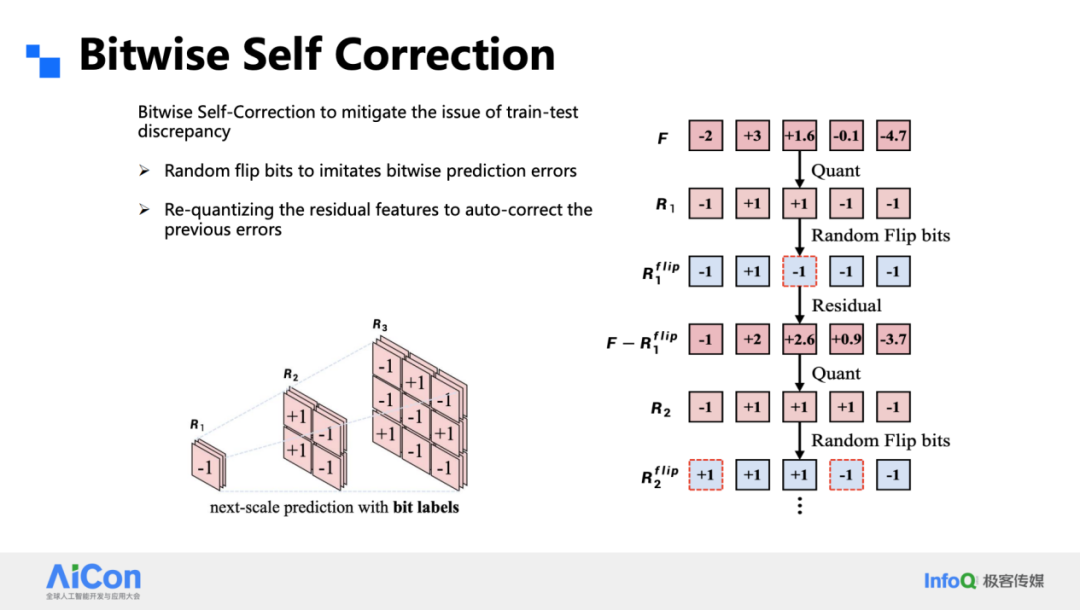
为了抑制累积误差,我们在训练阶段引入 Bitwise Self-Correction:每一步的预测结果会被再次量化并回传,网络学会在下一轮纠正前一步的位级错误。推理时这一机制同样生效,显著拉低误差扩散。
这套 Infinity 方案在 1024×1024 上实现了与 DiT 可比甚至更优的 FID,且支持任意长宽比,真正让 VAR 从类别生成走向通用文本到图像。
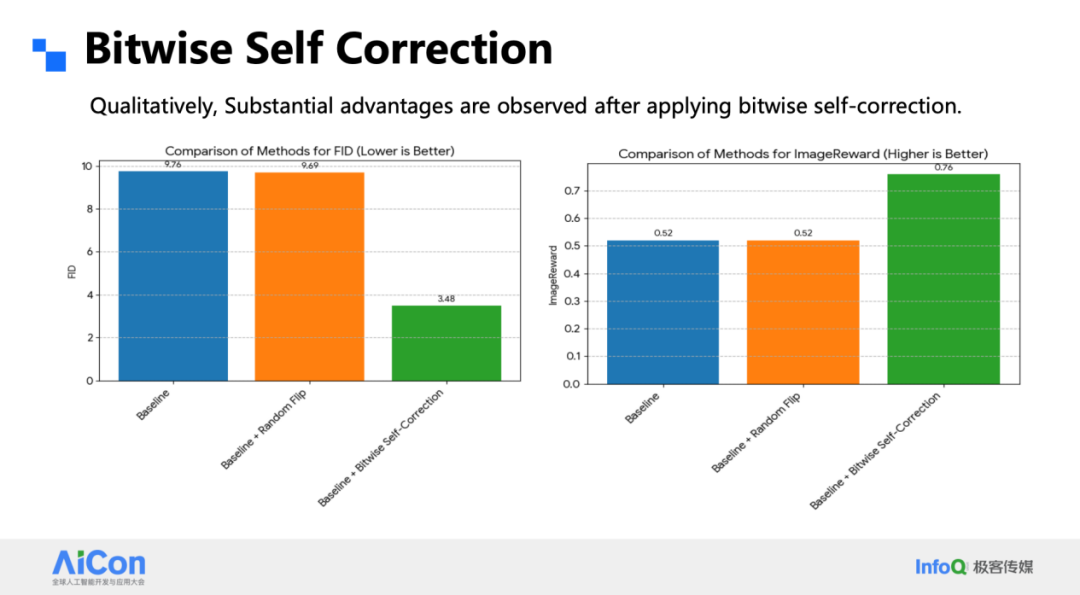
为了弥合训练 - 推理的不一致,我们在训练阶段显式模拟预测误差。做法很简单:把 1×1 token 在通道维展开后,随机翻转 20 % 的比特符号,再用被扰动的重建特征继续下一级量化。这样网络在每一步都能学会纠正位级错误,推理时误差不再逐级放大。加入这一 self-correction 后,同参数下的 FID 从 9 掉到 3,ImageReward 同步抬升;在高步数、高分辨率设置下,肉眼也能看出明显差异。
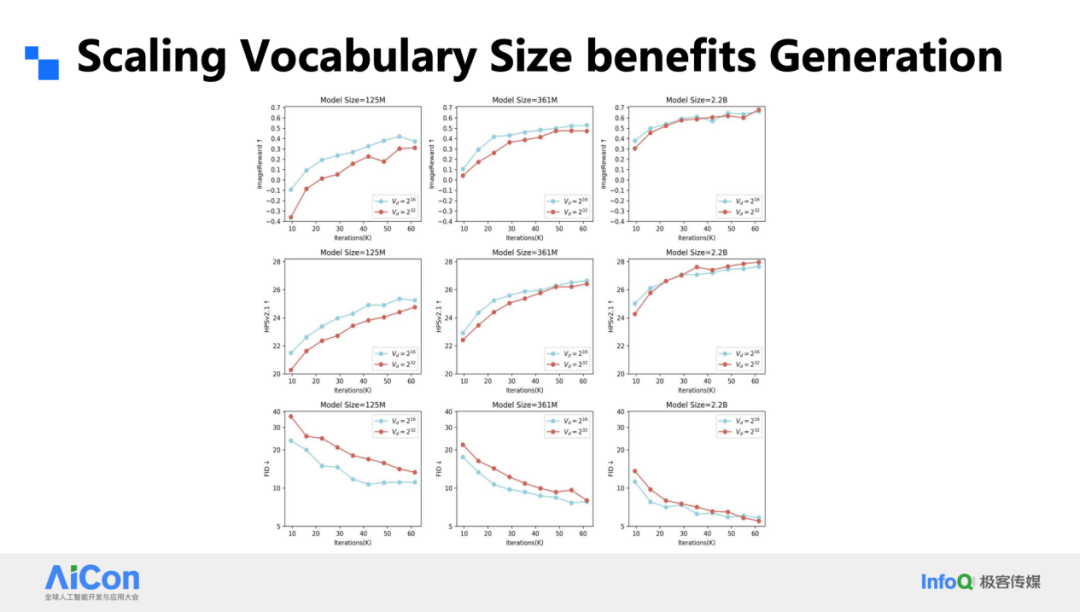
词表大小对生成的影响也出乎意料。我们把对比实验锁定在 2¹⁶ 和 2³² 两档,分别训练 125 M、361 M、2.22 B 三种体量。结果显示:小模型在小词表上更好,但随着算力增加,大小词表的差距迅速收敛;当模型继续放大,大词表开始反超。一句话,大模型值得用大词表,也值得继续加算力。验证集损失与人工指标呈 0.98 的线性相关,再次印证了 Scaling 的可靠性。
后训练阶段我们简单跑了一版 DPO,画质和细节会再上一个台阶,说明对齐工作同样适用于 VAR 框架。

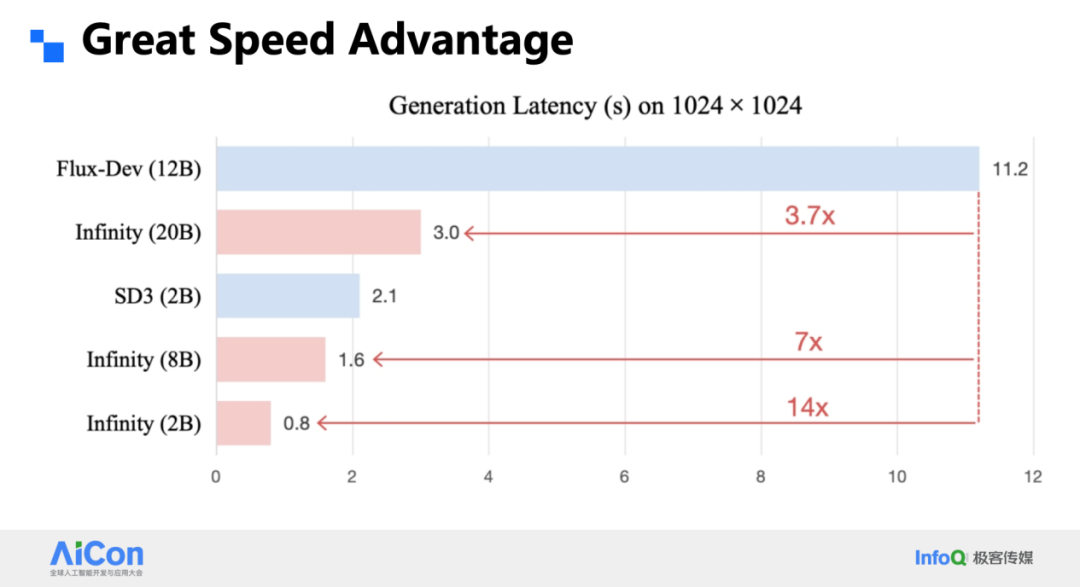
最后是速度。得益于并行解码,2B 的 Infinity 在 1024² 上只需 0.8 s,20 B 版本也只要 3 s,比同量级 DiT 快 3.7 倍。把同样的思路搬到视频,优势依然明显。在 T2I Arena 里,我们这个研究型小项目已与多款闭源 DiT 打平,证明 VAR 路线不仅能跑得快,也能跑得好。
分析和思考
从 VAR 到 Infinity,我们把离散自回归的上限往前推了一大步。新的 tokenizer 在保持离散表示的同时,已逼近连续 VAE 的重建质量,并能轻松扩展百万级词表,直接带来更细腻的纹理和更准确的指令遵循。更大模型、更长训练继续兑现 scaling 红利,生成质量与 DiT 同档而推理更快。至此,离散自回归不再是“小而快”的权宜方案,它已经能在高分辨率文本到图像任务中与扩散模型正面竞争。
会议预告
12 月 19~20 日,AICon 2025 年度收官站 · 北京见。两天时间,聊最热的 Agent、上下文工程、AI 产品创新等等话题,与头部企业与创新团队的专家深度交流落地经验与思考。2025 年最后一场,不容错过。





