
Prime Intellect 正式发布 INTELLECT-2 语言模型,该模型拥有 320 亿参数,通过完全异步的强化学习技术在一个去中心化计算节点网络中完成训练。与传统集中式模型训练不同,INTELLECT-2 基于无需许可的基础设施开发,其轨迹生成、策略更新和训练过程均采用分布式松耦合架构。
该系统的核心是 PRIME-RL 新型训练框架,专为不可信环境下的异步强化学习设计。它将轨迹生成、模型更新和权重广播三个核心任务解耦:策略更新由 SHARDCAST 组件负责,该组件通过树状 HTTP 网络分发模型权重;计算节点提交的推理轨迹需通过 TOPLOC 验证,这种局部敏感哈希机制可检测数据篡改或数值偏差,确保异常结果不会影响训练过程。
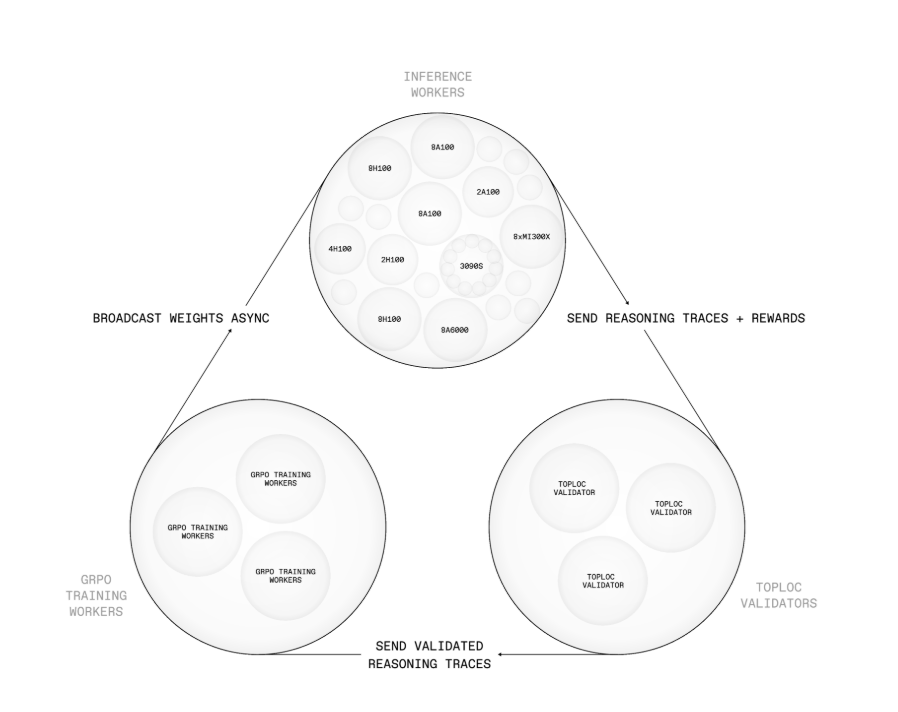
来源:https://arxiv.org/html/2505.07291v1
INTELLECT-2 的训练数据包含 285,000 项数学与编程任务,数据源包括 NuminaMath-1.5 和 SYNTHETIC-1 等数据集。其奖励机制融合了二元任务的成功判定与基于令牌长度的惩罚/奖励机制,实现了对推理阶段算力预算的细粒度控制。训练稳定性通过双面 GRPO 裁剪、梯度范数管理以及高价值任务的离线/在线筛选等技术保障。
该异步训练过程实现了推理、通信和模型更新的并行化,规避了传统集中式强化学习系统的典型瓶颈。基于 Rust 语言开发的协调器运行在测试网络上,负责全局计算节点池的协调工作,包括硬件检查、心跳监测、任务分配和贡献追踪——其运作机制类似于点对点网络或区块链系统。
性能评估显示,该模型在目标数学与编程任务上表现优于先前采用强化学习训练的 QwQ-32B 模型,但通用基准测试的提升则较为有限,意味着其性能增益主要集中在训练数据相关领域。Prime Intellect 指出,若采用 Qwen3 等更强基础模型,或整合更复杂的环境与推理工具,改进幅度可能更为显著。
一位 Reddit 用户评论其潜在影响:
分布式训练与分布式推理目前来看是未来方向。或许可以借鉴 P2P 或区块链机制,对算力贡献或交易行为给予某种奖励。我们未必需要创造新加密货币,但可以通过积分形式兑换网络免费算力。
Prime Intellect 的未来计划包括:提高推理与训练算力配比、整合网络搜索或 Python 等工具实现多轮推理、众包强化学习任务,以及试验 DiLoCo 等去中心化模型融合方法。
模型参数、代码、训练框架及相关文档已在 Prime Intellect 官网公开,同时提供 Hugging Face 模型发布和聊天演示等工具接口。




