

一、简介
优酷搜索承担着内容分发场排头兵的重任,海量的视频内容都要依赖搜索触达和呈现给用户。同时,优酷搜索的使用范围正在扩大,已经开始为阿里文娱全系产品提供搜索服务和能力。
面对如此复杂且对稳定性、精准性要求极高的系统,质量保障工作显得尤为重要。本文将为大家介绍视频搜索的质量体系是如何构建和发挥作用的。
二、业务特点
视频搜索架构特点
支持复杂多样的上层业务场景,业务逻辑复杂;
从搜索开始到结果返回的整个业务链路长,涉及的模块及外部依赖多;
算法依赖数据,底层数据变更会引起上层算法结果变化。
测试难点
业务链路长且复杂,用例覆盖率等难以进行有效度量;
离线和实时数据变更如何影响业务,数据质量的监控如何和业务紧密结合?
算法模块存在复杂性及不可解释性,算法效果难以进行有效评估;
海量数据中单个 badcase 无法说明问题,如何有效发掘共性的 badcase?
质量保障方案

三、工程质量
1.回归
回归测试主要是上线发布前的测试,目的在于提前发现 bug,保证发布质量。目前各模块的回归测试均已作为研发流程的一环,交由研发自行进行冒烟,不管是否走提测流程,均能在一定程度上把控业务质量。
我们根据链路的分层,针对各层模块进行了各模块自身的功能回归建设。各模块测试用例的自动化回归依托于冒烟平台,其可实现任意环境的快速回归,目前已积累回归用例 5000+,定时线上巡检,分钟级发现问题。
2.监控
1)功能监控
仍然是根据链路的模块划分,进行分层监控。监控仍依托于冒烟平台,并存储各模块日常冒烟监控数据以及真实 bug 数据。目前通过巡检已累计发现线上 bug 50+,具体冒烟监控数据大盘如下图所示。
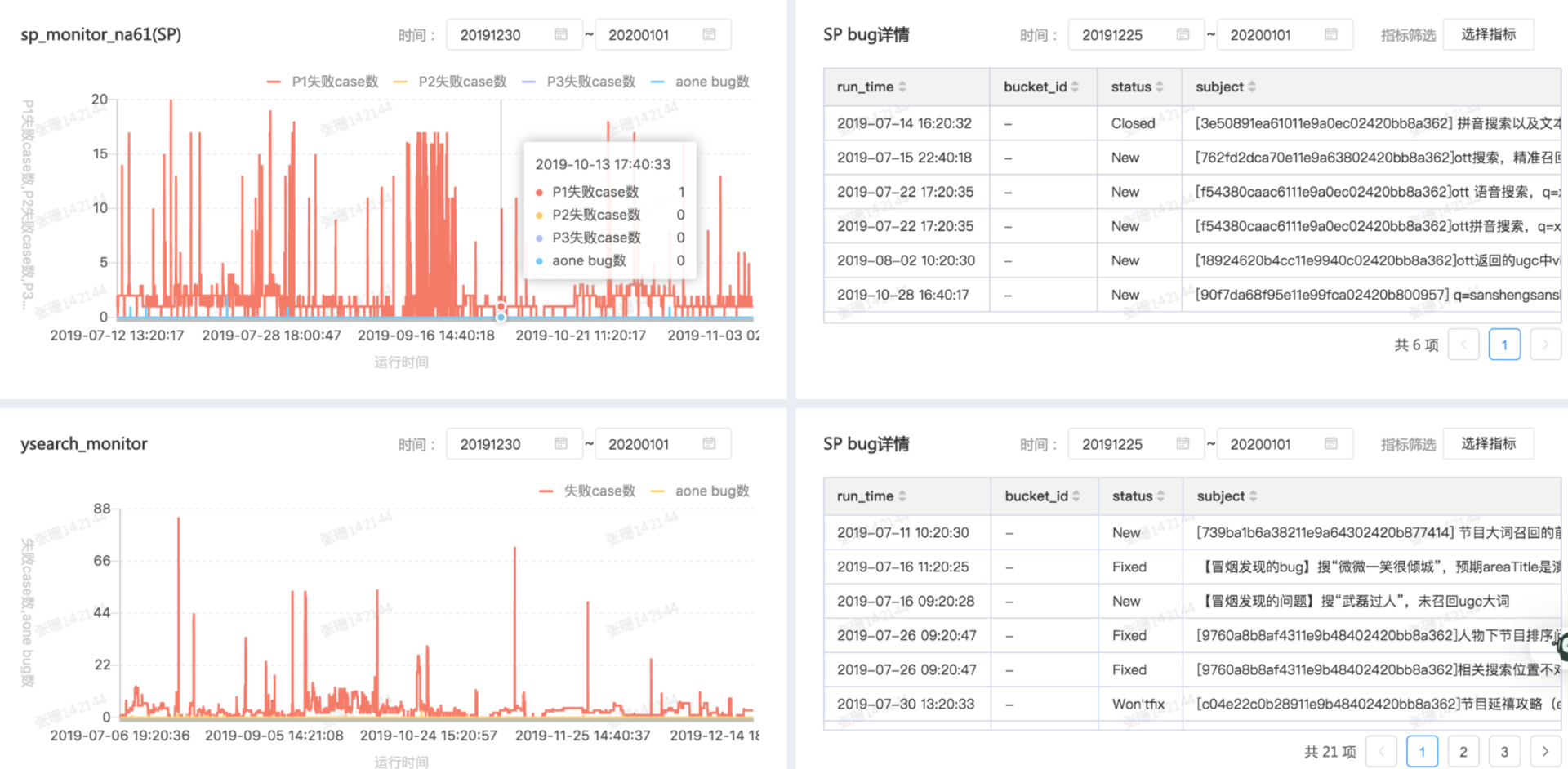
2)效果监控
线上效果监控的目的在于快速发现线上效果问题,保证线上质量。此外通过固化每次效果监控数据,监控线上效果问题的长期变化趋势,以辅助研发进行算法迭代优化,最大化利用人工评测数据。目前,已形成生成监控集合->定时监控->发现问题->解决问题闭环的处理机制。
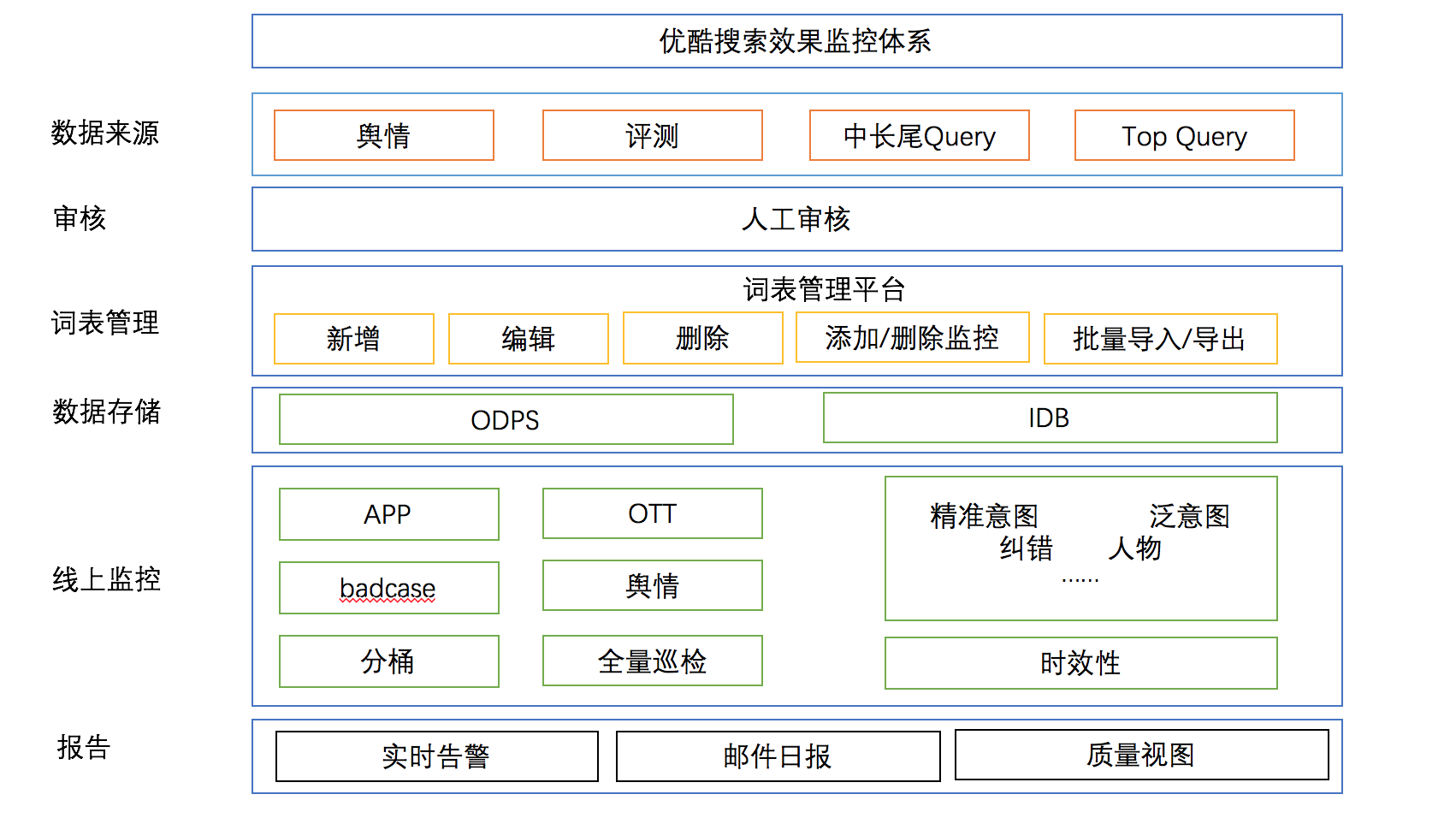
四、算法质量
1.数据
1)离线
借助集团已有平台的监控能力,定制业务细则。监控流程分为如下阶段:存在原始表、创建对应表的分区及监控规则、订阅分区规则,原始表周期任务执行结束自动触发 dqc 上对应表的对应分区的规则,如果异常会根据订阅内容报警。
step1:确定监控哪些表。
比如我们监控 A 表,该节点监控规则一旦失败,是否中断后续的生产流程?如果需要中止,那 stepn 配置强规则即可。此时要保证监控规则是业务合理的,当然一旦中止,我们要承受住多方的考验,节点多次失败账号健康分会受影响,任务的执行也会受影响。如果不需要中止,那么有两种方案,一是创建影子表,监控影子表(浪费一个存储周期的空间);二是所有规则置为弱规则(短信告警无法判断报警的严重程度)。
在实践中,对于重要的宽表数据,我们采用了监控影子表方案,次重要的表采用了对原始表全部配置弱规则的方案。
step2:在监控平台创建分区,用来指定是要监控哪天的数据。
step3:配置规则。
规则可分为通用规则和特性规则。数据量重要度属于 P0 级,采用数据量绝对值>阈值;同时采用了 7 天趋势绝对值变动在预警值在 10%,20%(不同业务阈值根据业务需要设定)。表数据量突增和突降在优酷场都不合理,所以采用了 7 天平均值波动+绝对值模式。通用规则是各字段通用的规则,基本包含是否非空,是否为 0 等等,体现在数据监控上面就是非空的数据量|数据占比变化趋势是否符合预期,值域非 0 的数据量|数据占比变化趋势是否符合预期。特性规则需要视业务特性而定,采取单字段 max、min、均值、总量,组合特征数量、变化率、空置率等个性化定制规则。
step4:订阅,支持短信、钉钉机器人、邮件等。
2)实时
把握整个实时流式计算的业务系统有几个关键点:流式计算、数据服务、全链路、数据业务(包括索引和摘要)。结合质量保障体系的线上、线下全链路闭环的理论体系去设计我们的整体质量保障方案,如下图所示:
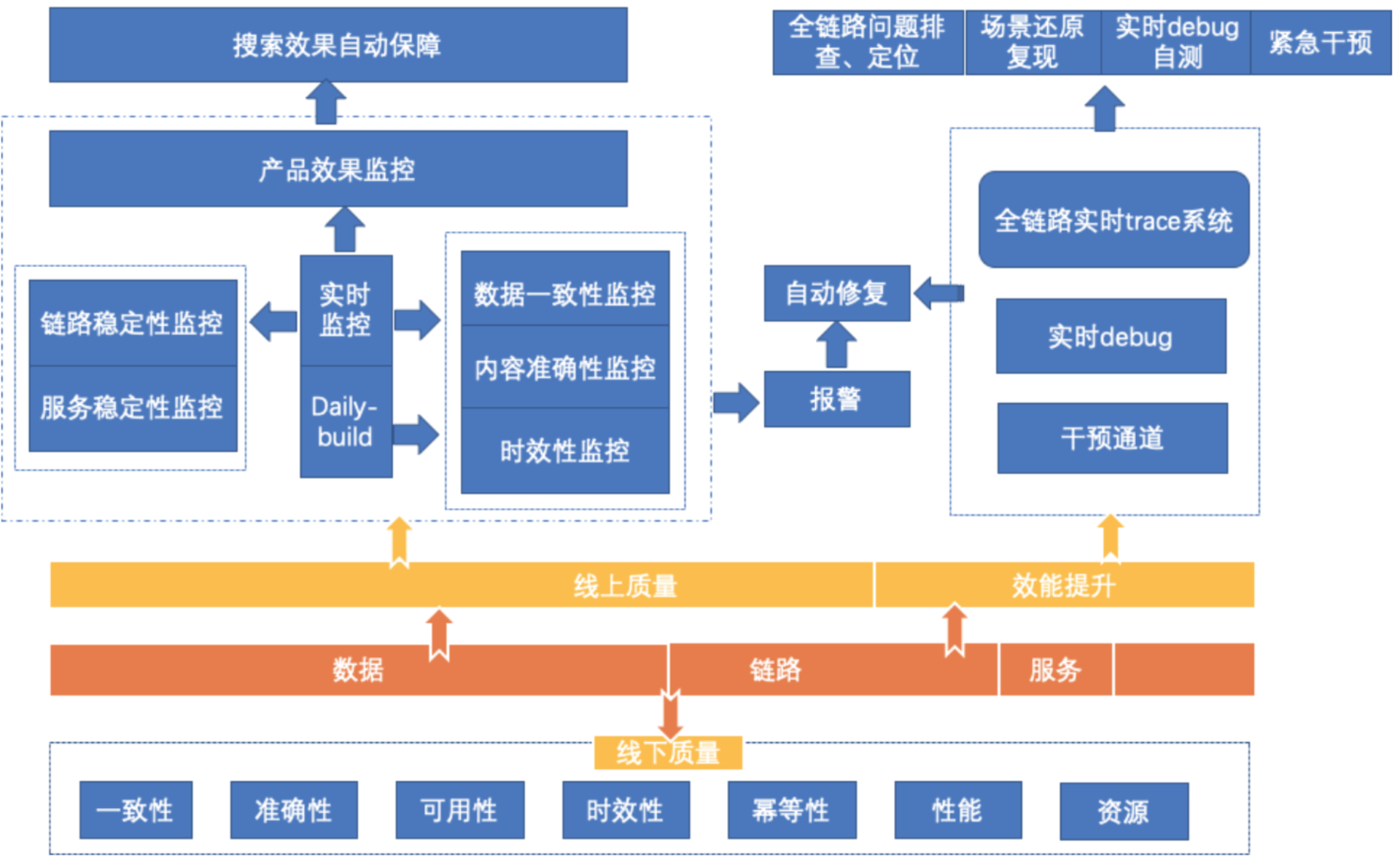
2.算法
1)特征算子组件单测
UDF 在算法数据特征计算过程中是特别普遍的开发组件单元,实时和离线都有自己的 UDF 定义。UDF 也支持多种语言,其本质上是一个函数,以不同的工程资源形式附加到各个平台的项目中使用,UDF 的测试就可以简化成函数测试,归结为输入输出的类函数单测的模式。我们复用统一框架的执行能力设计 UDF 单测模式如下:
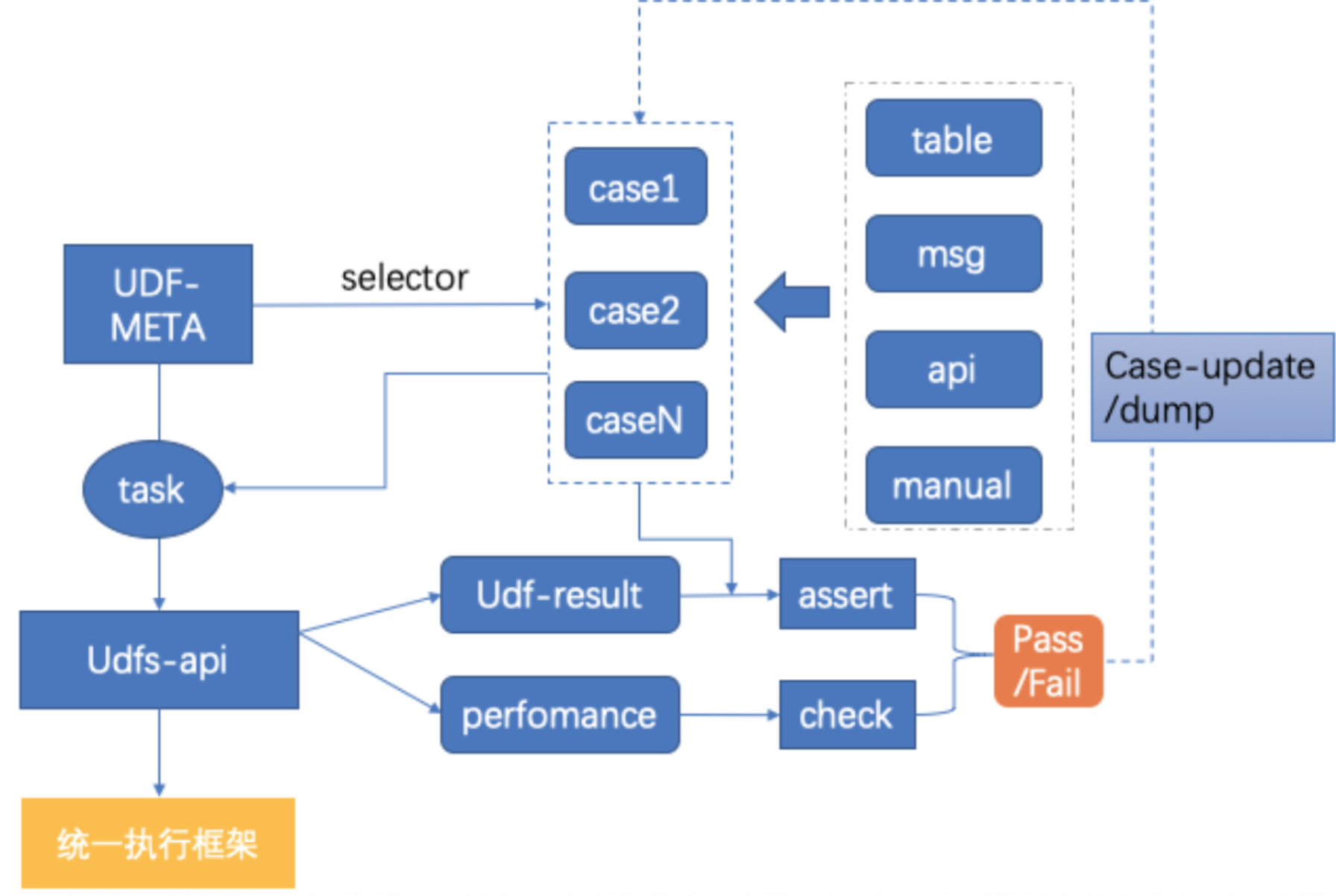
UDF 从功能输出来说分为三类:
第一类是有固定规则和处理逻辑的,可以通过输入输出来构建 case,判断时候则判断固定的输入是否等于输出就行;
第二类则是通用的规则类或者非固定业务含义输出的,这一类我们则通过正则匹配或者通用规则来校验结果;
第三类则是算法模型类,通过构建算法的评测集合,去执行评测集,获得 recall&accuracy 指标阈值来进行是否通过校验 UDF。
2)feature 列级测试
列级特征则是将整个列的计算逻辑以 UDF 算子为单元组件进行 DAG 逻辑编排,然后通过编译生成图化逻辑来流式构建特征列。计算引擎原理如图:
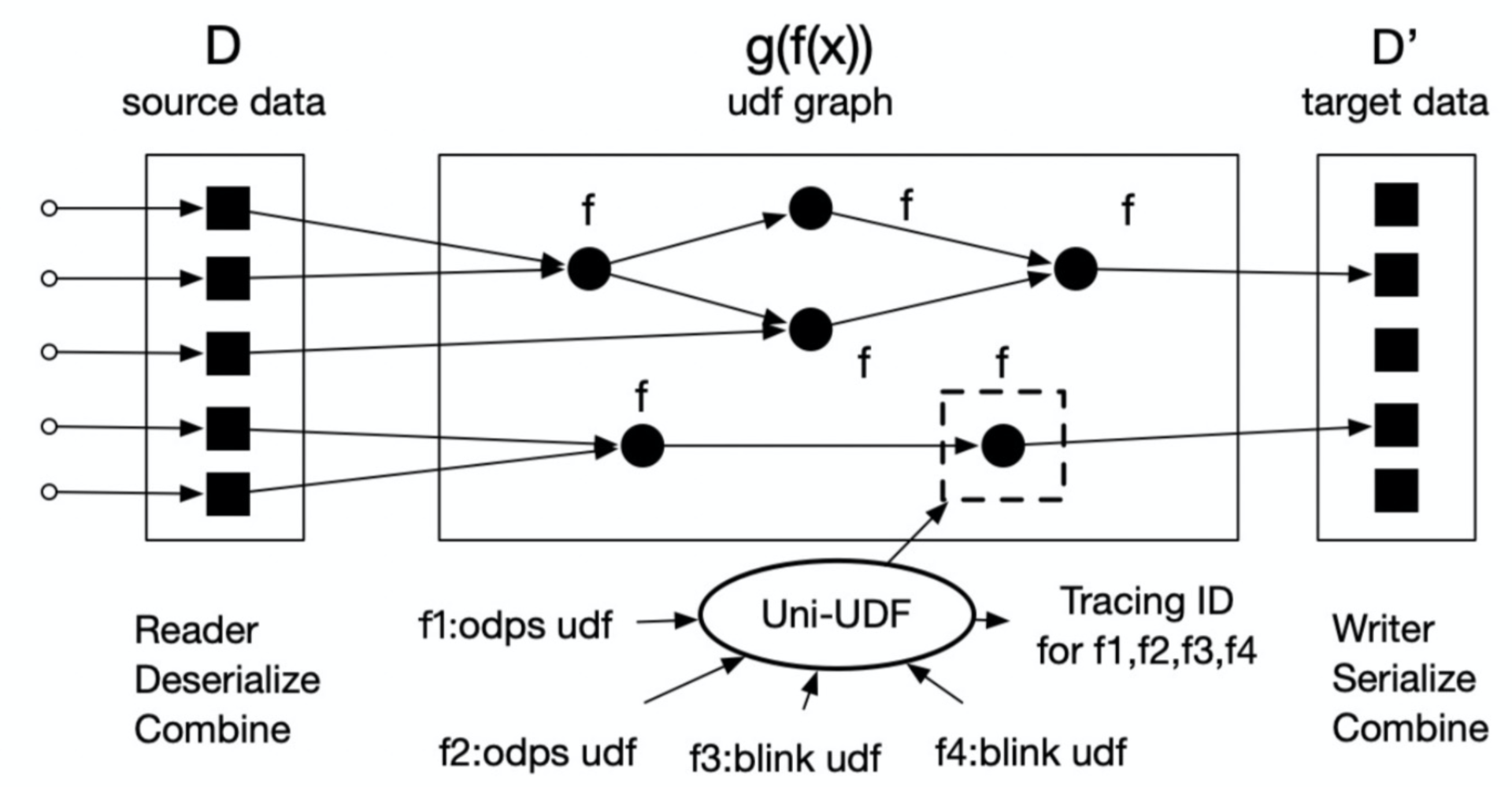
列级特征本质上是一个图化的 UDF 组合逻辑,可以看做是一个复杂图化的计算函数,包含很多子 UDF 的图化遍历的逻辑。构建编译器在列级图化逻辑编排完成后,进行编译会得到该列的 DAG 信息。这个 DAG 信息就会作为列级的图化逻辑属性。
当列级 feature 进行逻辑执行时,会解析该 DAG 信息进行图的遍历依次执行 UDF 算子。同理,在测试构建时,构造列级特征检测的 case 集合。特征既有数据含义,同时也具备部分业务应用上的含义。
特征检测可以结合数据规则和业务含义内容,共同制定特征检测机制。通过构建特征输入集来进行图化逻辑执行得到特征值,通过特征值的检测、特征分布、特征业务属性检测几个维度去完成特征检测。这时我们会通过统一的 trace 策略机制去记录每个 UDF 的调用执行情况,以供追查 UDF 执行错误和异常情况。
3)全图化索引测试
前面 UDF 是算子组件维度的,而特征 feature 是列维度的,索引全列则是以行为维度的,每行综合多列。而全列索引特征构建是综合多列 feature 的图化逻辑形成的一个 pipline。pipline 以引擎索引分类为一个完整的 Pipline,比如 OCG 就是一个全列的完整 Pipline。所以 Pipline 级别的数据测试则是以行维度的数据。
3.效果
1)效果基线
对搜索整条链路以及链路上影响算法的重要模块,例如意图分析模块,都建设了效果基线。
A、搜索链路效果基线建设
效果测试集必须是动态的,这里采用 case 放在云文件或者数据平台,当流量出现新词的时候随时添加。要作为效果基线,必须保证测试集对应的预期结果必须是准确的,这里采用的机制是评测同学维护。 总体流程是评测同学在数据平台维护效果基线 query、预期结果,代码加载数据进行规则判断,噪音消除,失败报警。
规则:检测 TOP n 召回某种类型卡片,TOP n 只能召回某些 showids,聚合卡片中 TOPN 只能召回某些 showids,n 可配、showids 可配、卡片类型可配等等;
噪音消除:失败重试、运营数据剔除、showid 可能出现在多种卡片,每种都需要相应业务逻辑。
使用场景:
搜索链路所有模块发布卡口;
被列为 AB test 期间关注的指标之一,指标一旦失败,实验回滚;
大流量桶的日常监控,成功率要求 100%,一旦失败必须及时修正。
B、意图模块 QP 的效果基线建设
方案:方案主要涉及意图类型、测试集构建、验证规则。效果基线要 check 哪些意图呢?主要从产品形态和算法使用情况来确定,每个意图都涉及正样本和负样本;样本数据取自线上已经识别出的意图数据,然后人工审核后分别放在对应的正样本和负样本,负样本还有一部分数据来自互斥意图的正样本数据。
规则:同一个意图对于不同的算法使用意图不同,比如人物,“郭德纲于谦”切词后这个词属于人物,但是不应该出人物卡。
使用场景
发布卡口;
线上定时监控:对于意图模块数据回流、代码发布都会影响效果,数据回流是自动触发,数据是否正确未知,也就说明线上定时监控的必要性。
2)搜索效果影响面自动评估
测试集构建:线上真实流量按照 SQV 进行分层、采样(越偏头部采样密度越大),线上流量映射到测试集;
评测规则:分析用户使用搜索的习惯,对用户经常点击的位置分别进行比对,;
影响面计算:异常请求的 sqv 总和/所有 sqv 总和;
噪音消除:异常重试、去掉算法无关卡片,来保证影响面评测的准确度。
3)指标看板
将评测能力集成到监控中,分钟级运行,产出效果指标大盘,及时发现算法问题并能指导算法优化。
五、用户体验
1.badcase 分类和挖掘
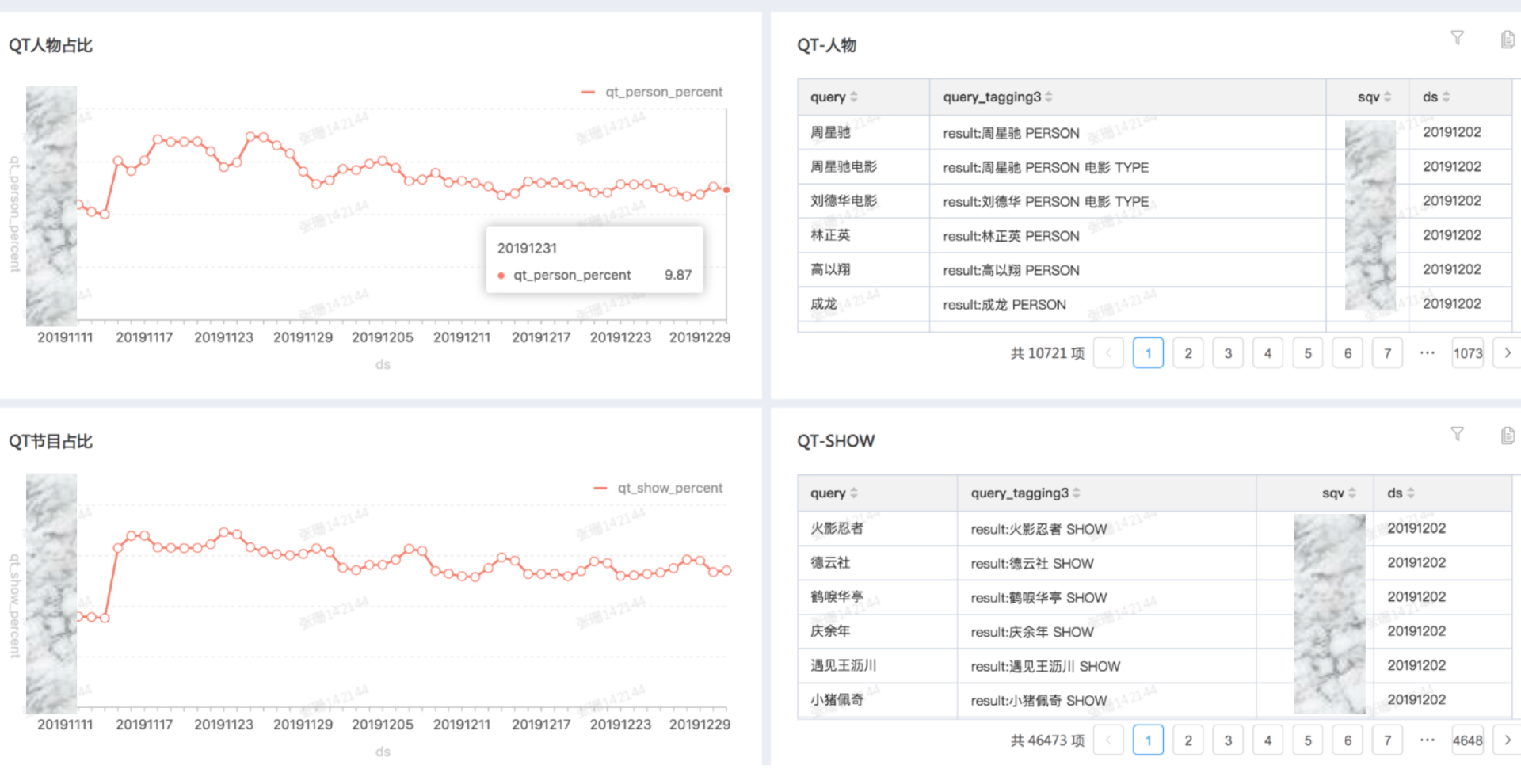
分析线上流量,badcase 挖掘主要集中在腰尾部高跳词。除了流量分层还有一个重要的流量就是实效性极高的热点。
1)高跳 badcase 挖掘:通过竞品对比等手段检测出多种类型的 badcase,badcase 会映射到具体原因上,直接进行专项优化,优化后的 case 会放入每次迭代,未优化的 case 以 badcase 形式存在 badcase 库,后续效果迭代会运行这些数据,以检测 badcase 的效果;
2)时效性分析:分析各大平台的热点内容,与自身做对比,并加入了相关性过滤逻辑;
3)运行机制:一天两次,研发会及时处理报警内容,同时会进行长期优化,现在 badcase 比例已明显下降。
2.舆情处理闭环
依托优酷舆情发现和处理平台,聚合用户观点。针对搜不到、搜不好等问题,做专项优化,已解决 5 大类 badcase。
作者介绍: 阿里文娱测试开发专家 熙闫

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论