
随着自然语言成为与软件交互的标准界面,无论是通过智能搜索、聊天机器人、分析助手还是企业知识探索者,系统必须处理大量措辞不同但意图相同的用户查询。在不重复调用大型语言模型的情况下,高效地检索准确的响应对于速度、一致性和成本控制至关重要。
语义缓存实现了这种效率。它是一种检索增强生成(RAG)技术,将查询和响应存储为向量嵌入,允许系统在新查询具有类似含义时重用以前的答案。与基于精确字符串匹配的传统缓存不同,语义缓存根据含义和意图进行操作,确保了不同短语模式之间的连续性。
在生产环境中,语义缓存加快了响应时间,稳定了输出质量,并减少了跨不同应用程序(从客户支持和文档检索到会话业务智能)的冗余 LLM 调用。然而,如果缓存设计不当,可能会出现语义接近但结果不正确的情况,从而产生假阳性,从而损害关键上下文中的可靠性。
当我们开始为我们的金融服务 FAQ 系统实现语义缓存时,我们期望一个简单的路径:选择一个经过验证的双编码器模型,设置合理的相似性阈值,并让系统从用户交互中学习。事实证明,实际情况要复杂得多。
我们的生产系统给用户提供了自信但完全错误的答案。一个企业主说“我不再想要这个商业账户了”,被引导到自动支付取消程序,置信度为 84.9%。一个客户说“我不再想要这张卡了”,被引导到投资账户关闭程序,置信度为 88.7%,而不是信用卡取消指导。
询问 ATM 位置的人收到了贷款余额检查指示,置信度为 80.9%。尽管使用了最先进的句子转换器,标准相似阈值为 0.7,但我们的一些模型的假阳性率达到了 99%。
本文记录了我们从语义缓存失败到生产成功的系统性旅程,在四种实验配置中测试了七个双编码器模型,其中包含 1,000 个实际银行查询。核心观点是:与模型优化相比,缓存的设计是减少假阳性的更强大杠杆。
实验方法:语义缓存的生产级基准
本文中的见解来自一个严格的、生产级的评估,测试了 1000 个查询在多个双编码器模型中的表现。我们的测试配置旨在复制真实环境,并提供对语义缓存性能的全面分析。
系统架构
我们的测试系统使用了查询到查询的语义缓存架构。用户查询被向量化,并与基于 Facebook AI 相似性搜索(FAISS)的先前回答查询的缓存匹配。如果在设置的相似度阈值之上找到类似的查询,则从缓存返回相应的金答案。如果查询没有达到阈值,系统会退回到大语言模型(LLM)来生成响应,然后将响应添加到缓存中以供将来使用。。评估环境旨在紧密镜像生产规模和行为,维护相同的缓存逻辑、模型配置和性能参数,以确保真实和可重复的结果。图 1 说明了高级语义缓存架构。
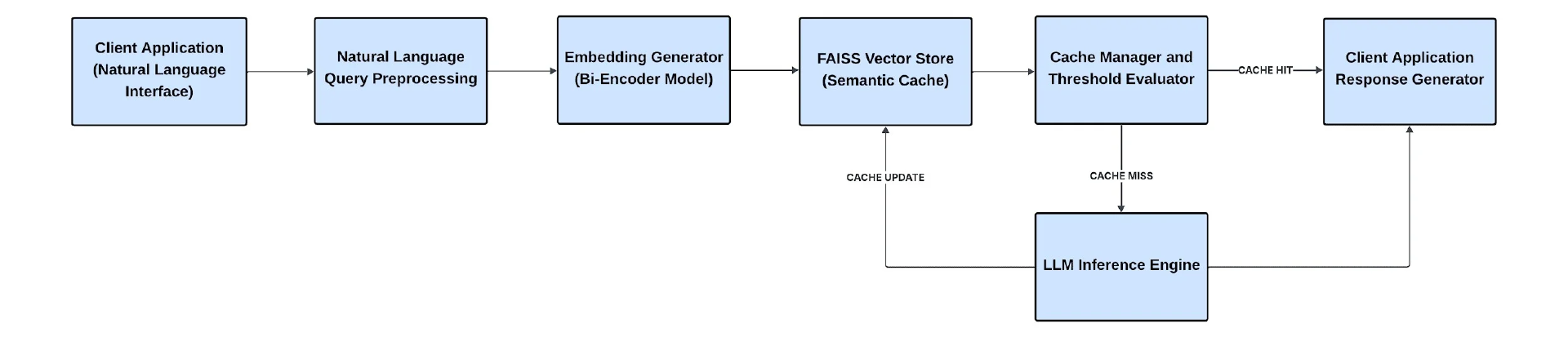
图 1:高级语义缓存架构
测试模式
在两种不同的缓存模式下进行评估,以模拟不同的生产场景:
增量模式:该模式从一个空缓存开始。只有在发生缓存丢失时才添加查询,模拟系统随时间学习和增长的“冷启动”部署。
预缓存模式:这个模式开始于一个预加载的缓存,里面有 100 个黄金答案和 300 个精心制作的干扰器。这个设置模拟了一个强大的实时环境,在这个环境中,系统被基础知识所激活。
基础设施和规模
我们的评估使用了生产级基础设施,以确保实际的性能测量:
基础设施:AWS g4dn.xlarge(NVIDIA T4 GPU,16GB GPU 内存)
规模:1000 个查询变体在七个双编码器模型中测试——all-MiniLM-L6-v2、e5-large-v2、mxbai-embed-large-v1、bge-m3、Qwen3-Embedding-0.6B、jina-embeddings-v2-base-en和 instructor-large
数据集:来自主要银行机构的 100 个银行业 FAQ
验证:与真实情况比较,准确度为 99.7%
测量指标:缓存命中率 %、LLM 命中率 %、FP%(假阳性率)、Recall@1、Recall@3 和延迟
数据集设计:真实世界的查询模式
该数据集来自真实的银行网站,经过精心设计,以模仿真实的客户互动。它由 1000 个查询组成,这些查询来自 100 个典型的银行常见问题,选自 10 个不同的领域,包括支付、贷款、纠纷、账户、投资、ATM 等。每个 FAQ 系统地增强了 10 个查询变体(例如,正式的、随意的、俚语的、带有错字的微小的等)和 3 种查询干扰来测试系统处理语义精度的能力:topical_neighbor(0.8-0.9 相似度)、semantic_near_miss(0.85-0.95 相似度)和 cross_domain(0.6-0.8 相似度)。
下面的截图展示了数据集构建过程中的一个示例,其中每个规范的 FAQ 被扩展为多个真实世界的查询变体,并与结构化干扰项配对以测试语义精度。这个例子反映了基准测试的重点是评估准确性和缓存在实际查询条件下区分细粒度意图差异的能力。
"faq_id": "Q003", "domain": "payment", "faq": "how do I cancel a Zelle payment", "gold_answer": "You can only cancel a Zelle payment if the recipient hasn't enrolled in Zelle yet. If they're already enrolled, the payment is sent immediately and cannot be canceled. Contact the recipient directly to request a return payment. For pending payments to unenrolled recipients, you may be able to cancel through your banking app or by calling customer service.", "variations": [ ["V001", "formal", "What is the procedure for canceling a Zelle transaction?", "hard"], ["V002", "casual", "can i cancel a zelle payment i just sent", "medium"], ["V003", "polite", "Is it possible to cancel a Zelle transfer I made by mistake?", "medium"], ["V004", "slang", "can i take back money i zelled to someone", "hard"], ["V005", "vague", "I need to stop something I did", "hard"], ["V006", "frustration", "I sent money to the wrong person on Zelle! How do I get it back?", "hard"], ["V007", "typo", "How do I cancle a Zele paymet?", "medium"], ["V008", "tiny", "cancel zelle?", "hard"], ["V009", "contradictory", "I want to complete this Zelle payment but how do I cancel it?", "hard"], ["V010", "grammar_error", "How I can canceling Zelle payment that I send?", "hard"] ], "query_distractors": [ ["Q1021", "topical_neighbor", "how do I view my recent transaction history", "medium", 0.83, "account_history", "high"], ["Q1022", "semantic_near_miss", "how do I reverse a completed wire transfer", "hard", 0.91, "payment_reversal", "high"], ["Q1023", "cross_domain", "how do I dispute unauthorized credit card charges", "medium", 0.74, "charge_dispute", "medium"] ]
模型选择策略
我们评估了七个具有代表性的双编码器模型,这些模型在尺寸、架构和提供商多样性方面涵盖了嵌入领域:
紧凑型模型:all-MiniLM-L6-v2(384 维)和 jina-embeddings-v2-base-en(768 维)
大规模模型:e5-large-v2、mxbai-embed-large-v1 和 bge-m3(全部 1024 维)
专业模型:Qwen3-Embedding-0.6B 和 instructor-large(针对特定任务的嵌入进行指令调优)
实验比较了在规模和表示深度上不同的模型。紧凑型模型提供较低的延迟和计算成本,而更大的架构在更高的资源需求下捕获更深层次的语义关系。指令调优和特定任务的模型增加了上下文对齐,提高了在复杂、特定领域的情境中的精度。
实验 1:零样本基线假阳性危机
我们的第一个实验使用默认的 0.7 相似度阈值在所有模型中建立基线性能,并从零开始增量构建缓存。
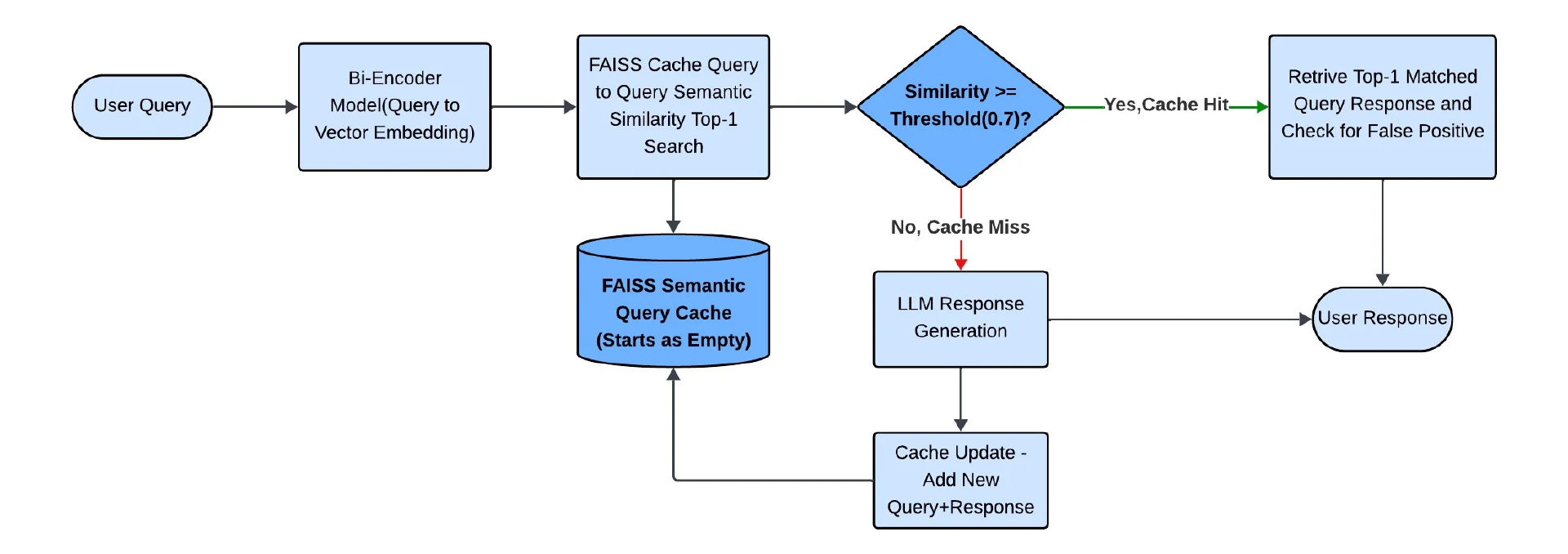
图 2:零样本语义缓存基线流程
下面的表格总结了所有模型的零样本基线结果。每个模型都使用空缓存和固定的 0.7 相似度阈值进行了测试。指标包括缓存命中率、LLM 回退率、假阳性、召回率和延迟,在进行任何缓存优化之前建立一个明确的参考点,并说明后来的架构改进如何减少生产中的假阳性。
假阳性危机
表 1:零样本语义缓存基线结果
我们的第一个实验建立了一个零样本基线,揭示了一个重要的“假阳性危机”。使用空缓存和默认阈值时,模型的表现令人无法接受,其中两个模型达到了 99%的高假阳性率,这意味着几乎每次缓存命中都是不正确的。在这个阶段,即使是表现最好的也有 19.3%的答案是错误的。这表明,在没有领域上下文的情况下对一般语义相似性进行优化的零样本模型不适合像银行这样的领域,因为它们基于表面级别的语言相似性而不是必要的功能意图来匹配查询。
实验 2:相似阈值优化限制
认识到默认阈值是不够的,我们基于验证数据对每个模型的相似性阈值进行了微调。
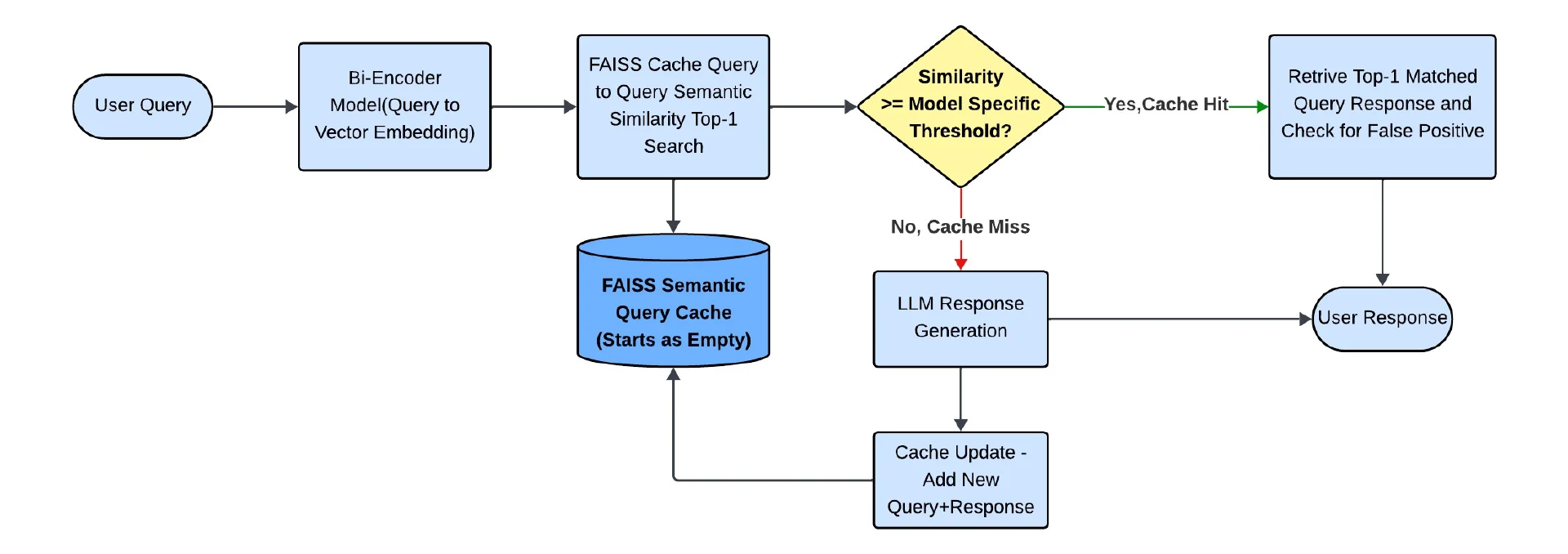
图 3:优化阈值以减少假阳性
相似度阈值优化结果
表 2:不同阈值下的模型性能变化
在实验 2 之后,很明显,简单地调整相似性阈值并不是达到生产就绪精度的可行途径。虽然阈值优化在初始基线的基础上提供了显著的改进,但对于生产部署来说,误报率仍然高得令人无法接受。更激进的阈值调优,虽然减少了误报,但代价是增加了缓存丢失,并增加了昂贵的 LLM 调用。这揭示了一个基本的架构缺陷:核心问题不在于模型找到良好匹配的能力,而在于缓存缺乏足够和精确的候选项供其选择。
实验 3:缓存内容的最佳候选原则和关键作用
我们的突破来自于对这个问题的重新定义。我们没有在稀疏的、增量构建的缓存上优化搜索,而是预先加载缓存,以实现全面的领域覆盖。这个实验揭示了一个具有广泛适用性的基本设计原则:
最佳候选原则:“确保有最优的候选对象可供选择,比在不充分的候选集上优化选择算法更有效”。
预加载缓存架构
新的缓存设计包含:
100 个黄金标准 FAQ:涵盖我们用例中所有 10 个银行领域的规范问题。
300 个战略干扰项:这些是精心设计的查询,旨在在语义上相似但不正确。干扰项的总数是从干扰项与黄金标准 FAQ 的 3:1 比例中得出的(300 个干扰项对应 100 个常见问题)。这种方法被用来模拟真实世界的数据,其中干扰因素很常见,允许我们严格测试模型处理细微语义边界的能力。
测量相似度范围:具有已知相似度分数(0.6-0.95)的干扰项,包括主题邻居、语义接近和跨域查询,以测试系统处理语义边界精度的能力。
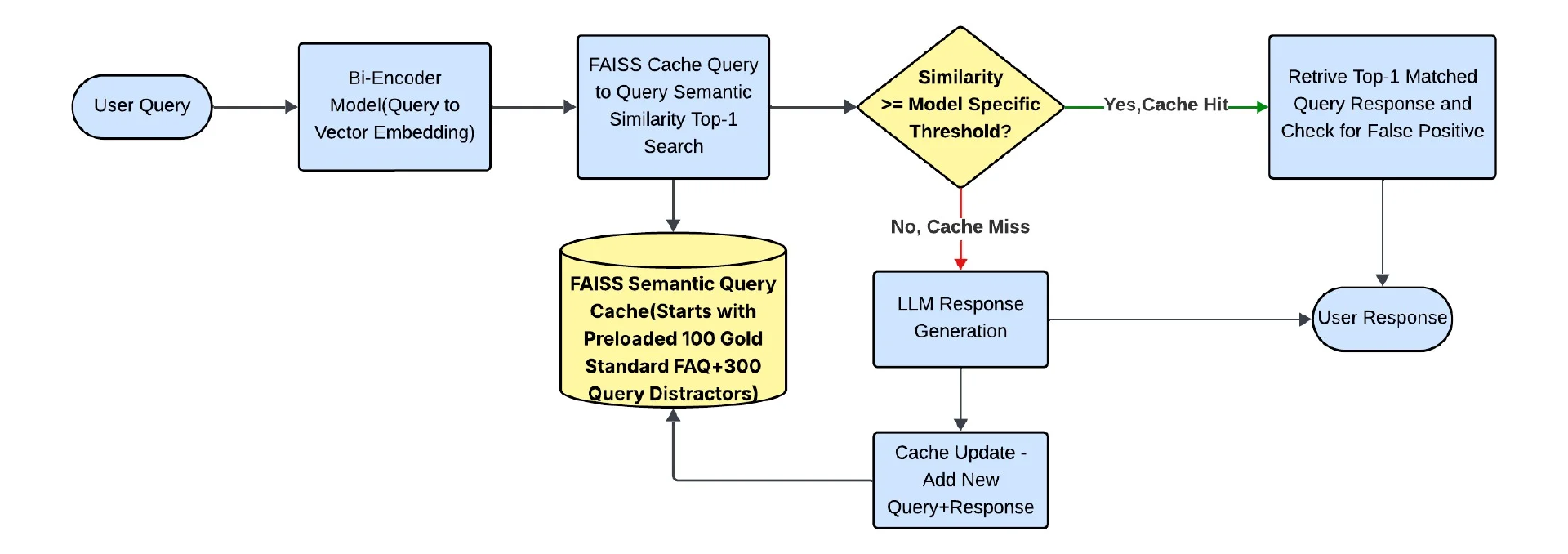
图 4:缓存优化的最佳候选选择原则
预加载干扰项的缓存结果
表 3:缓存内容选择对误报和召回的影响
这种基于最佳候选原则的架构变更带来了重大突破。尽管在缓存中添加了 300 个战略干扰项,但我们观察到了双重好处:模型的误报率下降了 59%,同时缓存命中率也有了很大的提高,从实验 2 的 53%到 69.8%的范围上升到实验 2 的 68.4%到 84.9%的新范围。这一重大改进验证了缓存设计是比单独调优阈值更强大的生产级精度杠杆。
实验 4:缓存质量控制
我们最后的优化包括引入缓存质量控制,在有问题的查询模式进入缓存之前过滤掉它们。这包括过滤微小的查询(非常短或未指定的输入,如“取消?”或“贷款?”))、错别字、语法错误以及可能造成语义混淆的模糊问题。
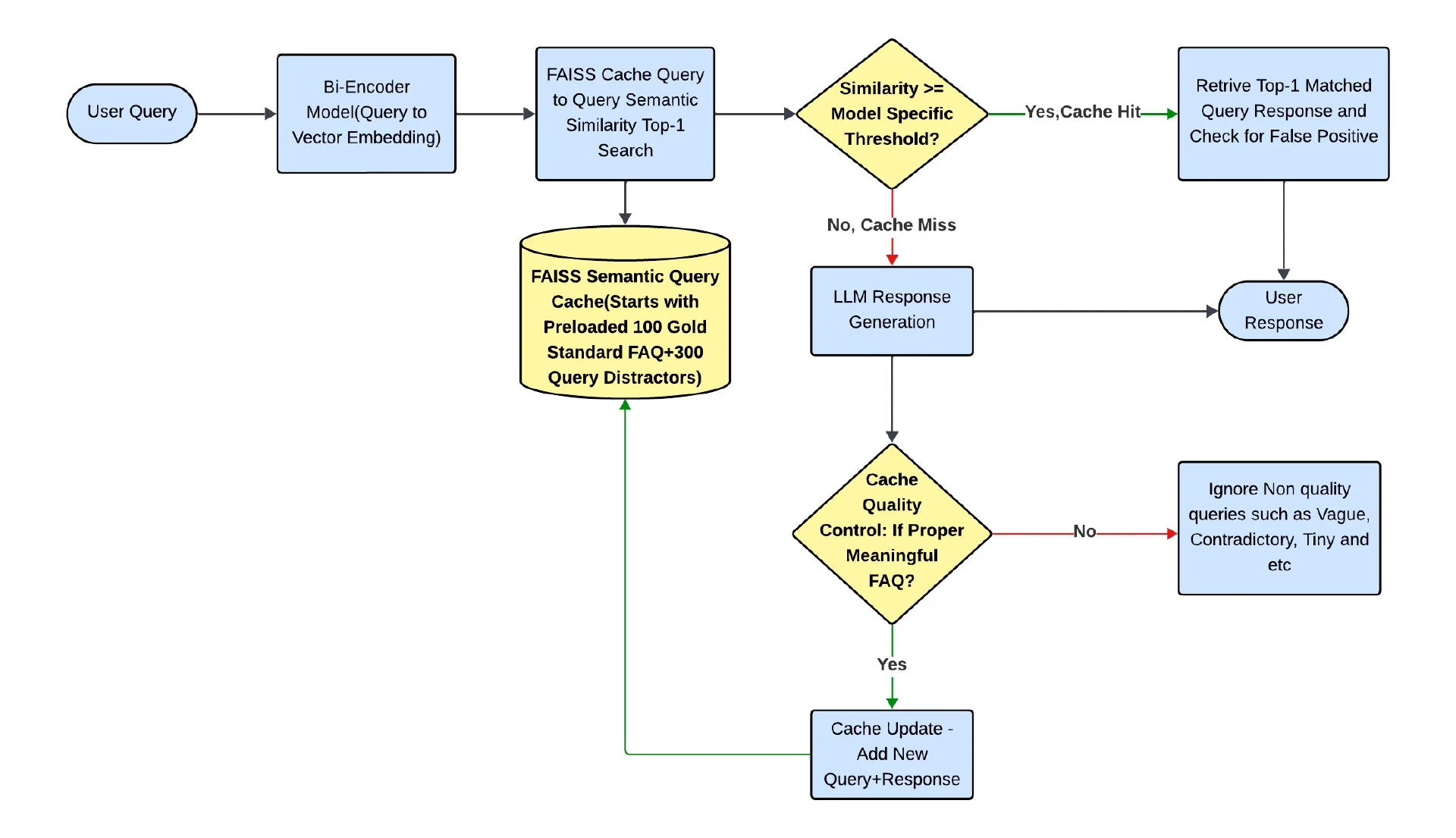
图 5:缓存质量控制机制和影响
带缓存质量控制结果的预加载缓存
表 4:质量控制对缓存精度的影响
这个阶段证明了缓存质量控制层作为强制护栏的重要性。它成功地解决了拼写错误、俚语和模糊查询等长期存在的问题,这些问题可能会造成语义混淆。结果非常显著,除了一个模型外,所有模型的假阳性率都低于 6%。表现最好的大教师的 FP 率达到 3.8%,比最初的基线降低了 96.2%。这一最终的架构步骤巩固了系统在生产环境中的可行性。
结论:从危机到生产就绪
从 99%的误报率到生产语义缓存中的 3.8%误报率,需要在系统设计哲学上进行根本性的转变。虽然模型选择和参数调整很重要,但在准确性至关重要的领域,它们是不够的。
我们的实验表明,最佳候选原则,确保有最佳的候选者可供选择,比在不充分的候选集上优化搜索算法更有效。
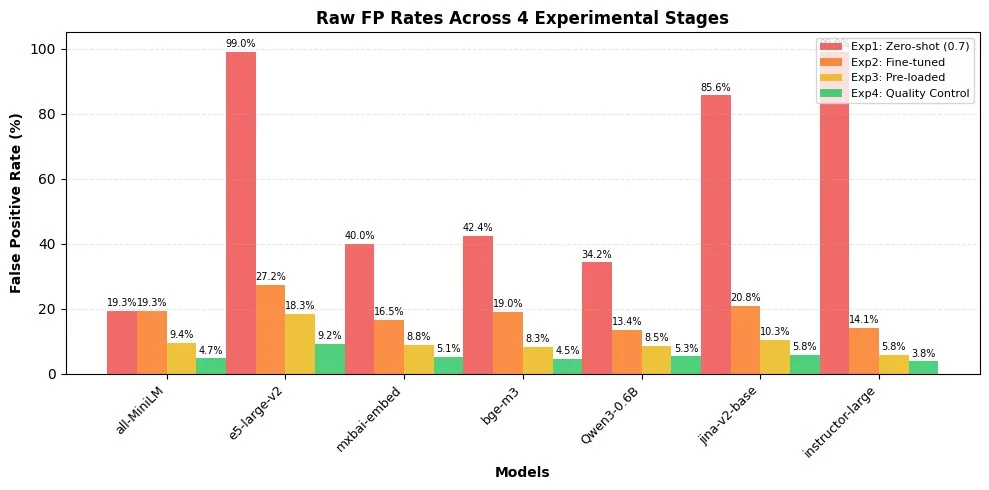
图 6:缓存优化后的性能比较
生产系统的最佳模型取决于你的特定用例和业务需求,这涉及到在延迟、LLM 成本和误报率之间找到最佳权衡。
基于这些基准测试用例,
首选:大模型,以获得最佳准确性(3.8%误报)
成本优化:bge-m3,以获得平衡的性能
延迟关键:all-MiniLM-L6-v2,用于实时应用
避免的模型:e5-large-v2 - 尽管进行了优化,但持续高误报率
未来的研究和架构路线图:解决最后的 3.8%误报
我们的实验成功地将误报率降低到了 3.8%。这一性能对于许多领域的生产部署是可行的,而低于 2%的比率将为最关键的金融指导场景提供增强的安全边际。
生产部署中的观察
在我们的生产部署中,我们观察到基于纯语义相似性的系统难以解决的一致性失败模式。这些观察是基于所有模型识别出的误报的代表性样本。
语义粒度失败:模型无法区分密切相关但不同的银行概念(例如,“信用卡”与“借记卡”)。
意图分类失败:模型无法理解用户的核心意图。例如,将高相似度分数分配给查询“我这个月可以跳过贷款支付吗”和正确的 FAQ“如果我错过贷款支付会发生什么”。在这种情况下,用户的意图是请求许可,但系统检索了一个描述过去行动后果的候选项。
上下文保留失败:模型错误地检索了一个技术上正确但完全脱离上下文的答案,通常在错别字或俚语的情况下。例如,将高相似度分数分配给查询“我如何在盘后购买股票?”和一般 FAQ“我如何购买股票”。这提供了强有力的证据,表明双编码器的密集向量平均值会将上下文限定符如“盘后”视为次要细节,而不是改变处理要求的重要上下文。
多层次架构路线图
达到近乎完美的误报率需要多层架构方法,而不仅仅是单纯的相似性。下面的路线图是一个系统的计划,旨在解决我们分析中确定的其余错误类别。
高级查询预处理:使用微调的 LLM 或简单的基于规则的系统,在查询进入语义系统之前,清理用户查询,纠正错别字,标准化俚语。
微调领域模型:通过在有限的、高质量的、领域内的数据集上微调基础模型,进一步提高嵌入性能。
多向量架构:通过为查询的不同方面创建单独的向量空间,如“内容”、“意图”和“上下文”,超越每个查询的单一向量。
交叉编码器重新排名:在系统中添加一个重新排名层,以深入分析查询与小候选列表之间的关系,提高准确率。
领域知识集成:集成一个最终的基于规则的验证层,作为防护措施,并结合领域特定知识。
银行业以外的教训:任何 RAG 系统的准则
虽然这个案例研究集中在金融服务行业,但这些原则适用于任何依赖 RAG 语义缓存的领域。
缓存设计优于模型调整:我们的研究结果表明,缓存架构,而不是模型选择或阈值调整,是减少误报的最强有力的杠杆。
垃圾进,垃圾出:错别字、模糊措辞和语法错误等低质量查询会污染缓存并造成误报。在生产中,预处理或质量控制层是一个强制性的防护措施。
阈值调整的局限性:仅依赖相似性阈值虽然可以减少误报,但代价是更高的缓存未命中和 LLM 调用,导致成本不可持续和用户体验下降。
结论
我们从一个破损的语义缓存系统开始。通过将反应式增量缓存转变为基于最佳候选原则的主动的、架构合理的设计,我们将误报率从 99%降低到了 3.8%。
通往安全、可靠的 RAG 系统的道路不仅仅是寻找完美或大型的模型。如果你的流程失败了,请先修复缓存,然后再调整模型。架构,而不是嵌入,是区分原型和生产系统的关键。
原文链接:
https://www.infoq.com/articles/reducing-false-positives-retrieval-augmented-generation/




