
2015 年 12 月,Netflix 新的数据流水线 Keystone 上线。本文将介绍近年来 Netflix 数据流水线的演进。这是介绍新的 Keystone 数据流水线系列文章的第一篇。
Netflix 是一家数据驱动的公司,很多业务和产品决策均基于数据分析作出。数据流水线的作用是在云上收集、聚合、处理和移动数据。Netflix 的几乎每一款应用都会用到该数据流水线。
先来看 Netflix 数据流水线的一些数据:
- 每天 5000 亿事件, 1.3PB 数据
- 峰值时间每秒处理 800 万事件,24GB 数据
有数百种事件会通过该流水线,如:
- 视频观看活动
- UI 活动
- 错误日志
- 性能事件
- 问题定位和诊断事件
这里需要注意的是,运维相关指标不通过该流水线处理,而是有一个独立的系统—— Atlas ,和 Netflix 的其他很多技术一样,该系统也开源了。
在过去这些年,因为需求的变化和技术的发展,Netflix 的数据流水线有几次大的变化。
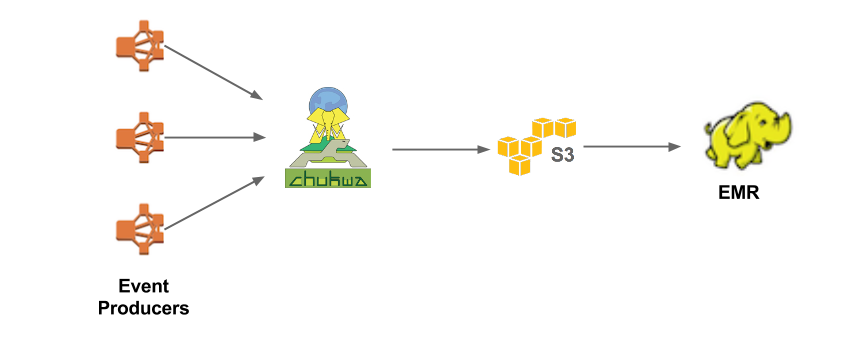
V1.0 Chukwa 流水线
原始的数据流水线,唯一目的就是聚合事件,并将其上传到 Hadoop/Hive 进行批处理。从下图中也可以看出,架构相当简单。 Chukwa 收集数据,并以 Hadoop 顺序文件格式将它们写入到 S3 中。大数据平台团队进一步处理 S3 文件,然后以 Parquet 格式写入到 Hive 中。从一端到另一端的延迟高达 10 分钟。不过对于通常以天或小时的频率扫描数据的批处理作业而言,也足够了。
V1.5 带有实时分支的 Chukwa 流水线
随着 Kafka 和 Elasticsearch 的出现,Netflix 对实时分析的需求也不断增长。这里的“实时”指的是延迟小于 1 分钟。
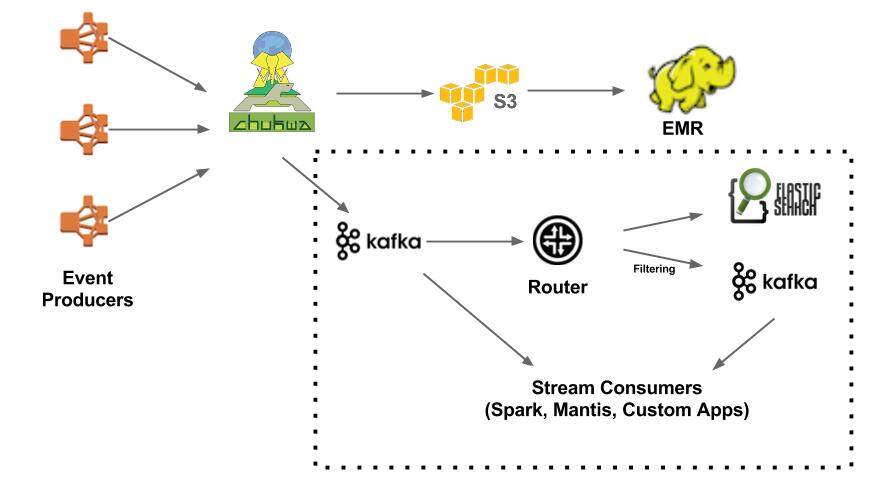
除了将事件上传到 S3/EMR,Chukwa 还能将流量发到 Kafka(实时分支的前端)。在 V1.5 中,大约有 30% 的事件会进入实时流水线。实时分支的核心是 Router。它负责将数据从 Kafka 路由到不同的地方,如 Elasticsearch 或次级 Kafka。
过去两年,Elasticsearch 在 Netflix 的应用增长迅速。现在有 150 个集群,总计 3500 个实例,上面有 1.3PB 数据。绝大部分数据都是通过该数据流水线进来的。
在 Chukwa 将流量发到 Kafka 时,既可以是完整的流,也可以是过滤之后的。有时还需要进一步过滤从 Chukwa 写到 Kafka 的流,这就是引入 Router 的目的所在——可以消耗一个 Kafka 主题,并生成一个不同的 Kafka 主题。
在数据到了 Kafka 之后,用户可以使用 Mantis 、 Spark 或定制的应用来做实时的流处理。“自由与责任”(Freedom and Responsibility)是 Netflix 文化的基因。用户自己选择合适的工具来处理手头的任务。
因为研发团队擅长处理数据的大规模迁移,所以将 Router 设计成了一个托管服务。在运维路由服务的过程中,他们也得到几点教训:
- Kafka 高层消费者可能会丢失分区(partition)所有权,在稳定运行一段时间后,不再处理某些分区。需要重启消费者进程才能恢复。
- 当推出新代码时,有时高层的消费者会在重新平衡过程中陷入错误状态。
- 将路由作业分组,放到一系列集群上,不过管理这些作业和集群的成本持续增长。所以需要更好的平台来管理路由作业。
V2.0 Keystone 流水线 (Kafka fronted)
除了上面提到的与路由相关的问题,还有其他几点考虑促使我们重新架构我们的数据流水线:
- 简化架构
- Kafka 实现复制,可以提高系统的可靠性,而 Chukwa 不支持复制。
- Kafka 有一个非常活跃、生机勃勃的社区。
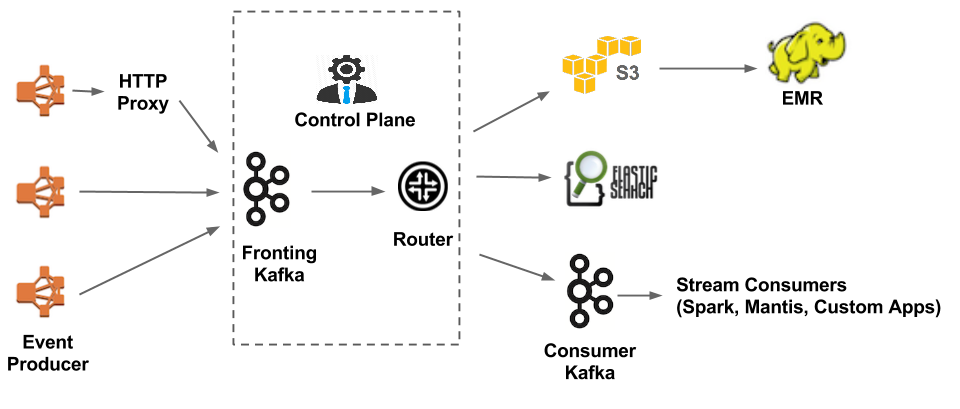
有 3 个主要组件:
- 数据获取——有两种方式:使用 Java 库,直接写入 Kafka;或者
发送给 HTTP 代理,然后由代理写入 Kafka。 - 数据缓冲——Kafka 作为复制的持久消息队列。
- 数据路由——路由服务负责将数据从前端的 Kafka 移到 S3 、 Elasticsearch 和次级 Kafka。
过去几个月,Keystone 已经应用于生产中。目前开发团队仍然在改进 Keystone,着重于 QoS、伸缩性、可用性、可运维性和自服务等方面。

略懂技术的运营同学。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论