

近日国内与人工智能领域相关的利好政策陆续释放,中央召开的相关会议强调“未来要重视通用人工智能发展,营造创新生态。”《北京市促进通用人工智能创新发展的若干措施(2023-2025 年)(征求意见稿)》围绕五大方向提出 21 项具体措施,包括“开展大模型创新算法及关键技术研究”,“加强大模型训练数据采集及治理工具研发”等,同时面向政务服务、医疗、科学研究、金融、自动驾驶、城市治理等领域拓展应用场景,以抢抓大模型发展机遇,推动通用人工智能领域实现创新引领,中国大模型技术产业迎来了一波前所未有的发展契机,百度、阿里、华为等国内众多企业迅速布局了相关业务,推出自家的人工智能大模型产品。
此外,目前全球整个大模型领域都拥有着较高密度的人才团队,且有资本加持。在人才方面,从目前公布的部分大模型研发团队背景可以看出, 团队成员均来自国际顶级高校或拥有顶级科研经验;在资本方面,以 Amazon 和 Google 举例,这两家 2022 年在大模型技术方面的资本性支出分别达 583 亿美元和 315 亿美元,并仍然呈现上涨趋势,就 Google 最新披露数据,其训练参数规模 1750 亿的大模型, 理想训练费用超过 900 万美元。
当一个领域有高密度的资本和人才团队,那意味着这个领域将有更快的发展。很多人觉得,ChatGPT 这一现象级产品横空出世,拉开了大语言模型技术蓬勃发展的序幕。但实际上,自 2017 年大语言模型诞生,OpenAI、微软、谷歌、Facebook、百度、华为等科技巨头在大语言模型领域的探索持续不断,ChatGPT 只是将大语言模型技术推进至了爆发阶段,当下大模型产品格局更是呈现出了新形势——国外基础模型积累深厚,国内应用侧优先发力。
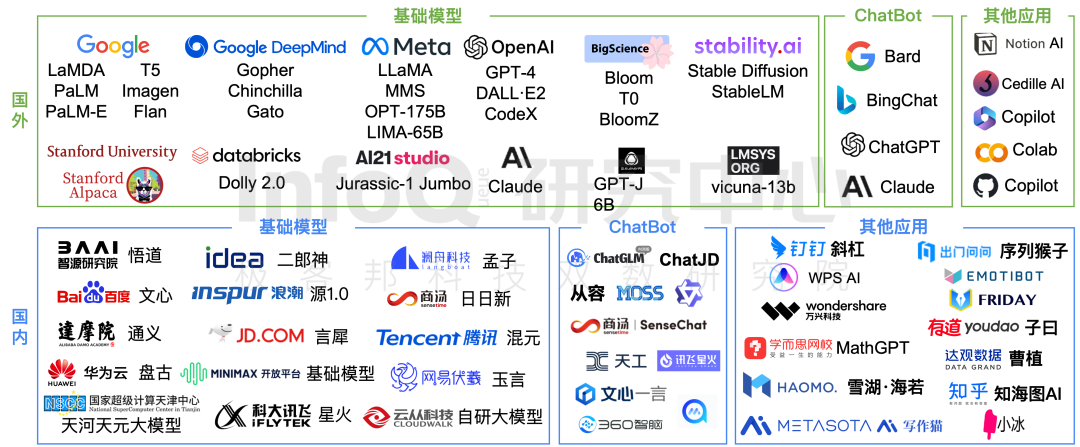
为此 InfoQ 研究中心基于桌面研究、专家访谈、科学分析三个研究方法,查找了大量文献及资料,采访了 10+ 位领域内的技术专家,同时围绕语言模型准确性、数据基础、模型和算法的能力、安全和隐私四个大维度,拆分出语义理解、语法结构、知识问答、逻辑推理、代码能力、上下文理解、语境感知、多语言能力、多模态能力、数据基础、模型和算法的能力、安全和隐私 12 个细分维度,分别对 ChatGPT gpt-3.5-turbo、Claude-instant、Sage gpt-3.5-turbo、天工 3.5、文心一言 V2.0.1、通义千问 V1.0.1、讯飞星火认知大模型、Moss-16B、ChatGLM-6B、vicuna-13B 进行了超过 3000+ 道题的评测,根据测评结果发布了《大语言模型综合能力测评报告 2023》(下文简称《报告》)。
为了保证报告的客观性、公正性及计算结果的准确性,InfoQ 研究中心根据样本制造了一套科学的计算方法——通过实际测试获得各模型对 300 道题目的答案,针对答案进行评分,正确答案获得 2 分,部分正确的答案获得 1 分,完全错误的获得 0 分,模型表示不会做的获得 -1 分。计算公式为“某模型在某细分类别题目得分率 = 模型得分 / 模型总分”。举个例子,A 大模型在 7 道题目的类别中总得分为 10,该类题目可获得的总得分为 7*2=14,则 A 大模型在这个题目类别的得分为 10/14=71.43%。
基于以上评测方法,报告主要得出了许多值得大家关注的结论,希望下文的核心结论解读可以为各位的未来大语言模型技术具体实践和探索提供方向。
一、百亿参数规模是大模型训练的“入场券”,大模型技术革命已经开始
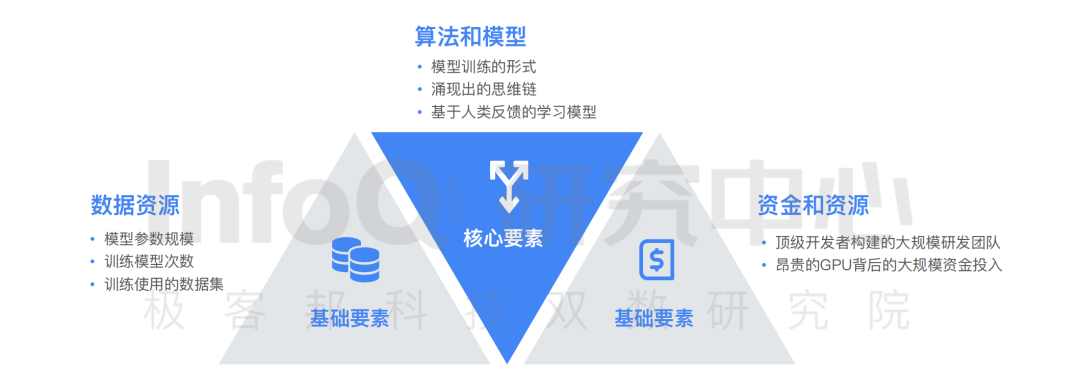
企业对于大模型产品研发需要同时具备三大要素,分别为数据资源要素、算法和模型要素、资金和资源要素。通过对目前市场中的产品特征进行分析,InfoQ 研究中心发现数据资源、资金和资源两要素为大模型研发的基础要素,算法和模型是目前区分大语言模型研发能力的核心要素。算法和模型影响的的模型丰富度、模型准确性、能力涌现等都成为评价大语言模型优劣的核心指标。此处需要说明的是,虽然数据、资金资源为大语言模型研发设置了高门槛, 但对于实力雄厚的大型企业仍然是挑战较小的。
仔细研究大模型产品的核心要素会发现,大模型训练需要“足够大”,百亿参数规模是“入场券”。就 GPT-3 和 LaMDA 的数据显示,在模型参数规模处于 100 到 680 亿这个区间时,大模型的很多能力(如计算能力)几乎为零。同时,大量计算触发了“炼丹机制”,根据 NVIDIA 论文里的附录章节显示,一次迭代的计算量约为 4.5 ExaFLOPS,而完整训练需要 9500 次迭代,完整训练的计算量即为 430 ZettaFLOPS(相当于单片 A100 跑 43.3 年的计算量)。
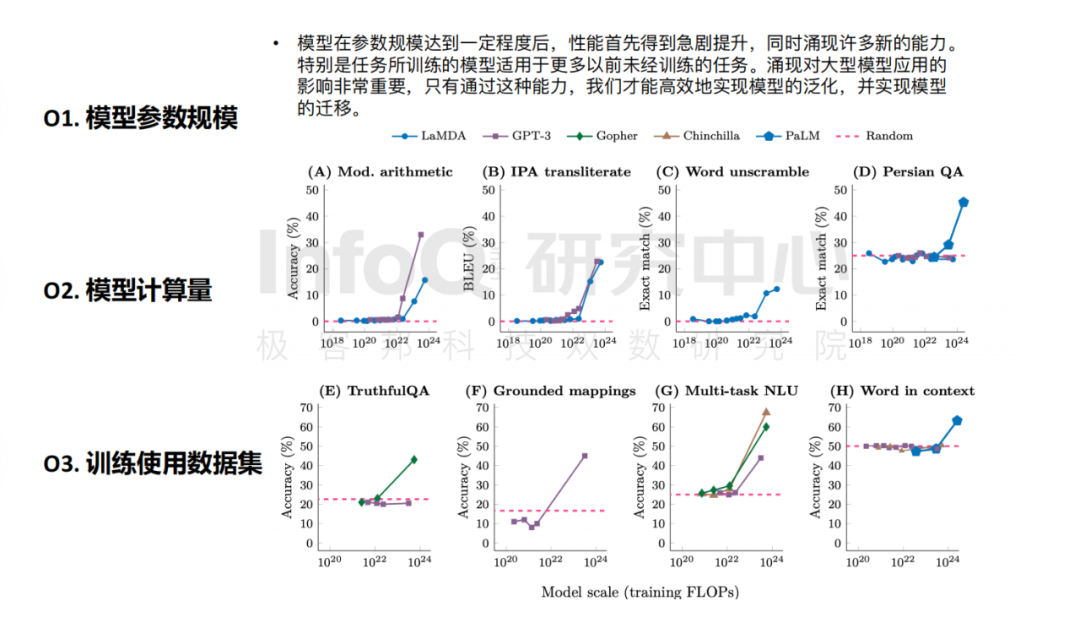
数据来源:Sparks of Artificial General Intelligence Early experiments with GPT-4
纵观全球大模型训练参数规模的数量级,根据民生证券研究所和 wiki 百科资料显示,国际领先的大模型 GPT-4 的推测参数量级可达 5 万亿以上,国内部分大模型规模大于 100 亿。其中,百度研发的 Ernie 和华为研发的盘古目前是有数据的国内大模型参数规模的领先者。

InfoQ 研究中心对各家的大语言模型进行了综合测试后也发现,国外的 ChatGPT 各项能力确实很抗打,位居第一位。令人惊喜的是,百度的文心一言闯进了前三名,位居第二,而且值得一提的是,其综合得分仅落后 ChatGPT 2.15,远超第三名 Claude。
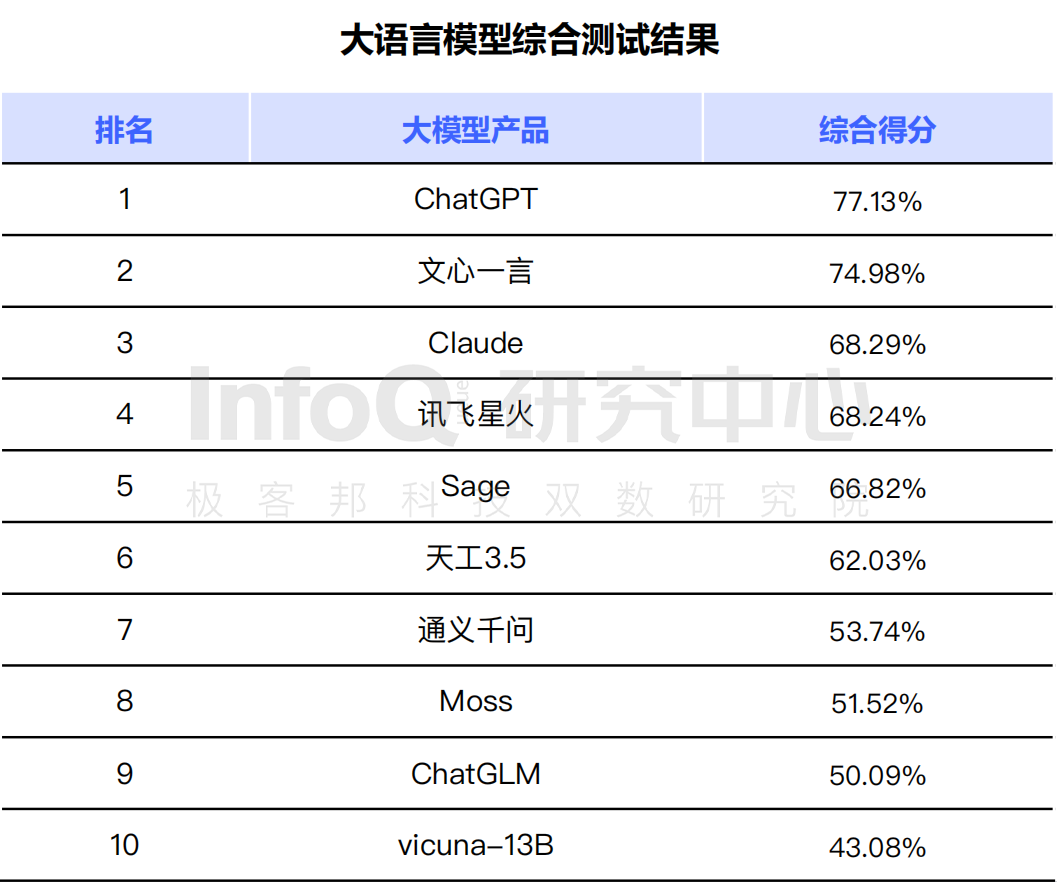
数据说明:测评结果仅基于上文所列模型,测评截止时间为 2023 年 5 月 25 日
在整个研究过程中,InfoQ 研究中心发现,算法和训练模型水平主导大语言模型的能力表现。从基础模型到训练方式的工程化,再到具体的模型训练技术,目前赛道中的所有厂商,每一个环节模型选型的差异造就了大语言模型的最终能力表现的差异。

可能各个厂商的产品能力有所差异,但是因为参与到大模型技术建设的玩家足够多,他们对技术持续的探索,让我们看到了大模型技术革命成功的希望。在大模型产品百花齐放的当下,大语言模型将计算机能力从“搜索”拓展到了“认知 & 学习”到“行动 & 解决方案”层面,大语言模型的核心能力已经呈现出金字塔结构。

二、“写作能力”和“语句理解能力”是大语言模型目前擅长能力的 Top2
据 InfoQ 研究中心的测评结果显示,安全和隐私问题是大语言模型研发的共识和底线,位居能力评分第一位。大语言模型的基础能力整体表现均排名更为靠前,逻辑推理相关的编程、推理和上下文理解目前整体表现仍有较大的提升空间;多模态仍然是少数大语言模型的独特优势。
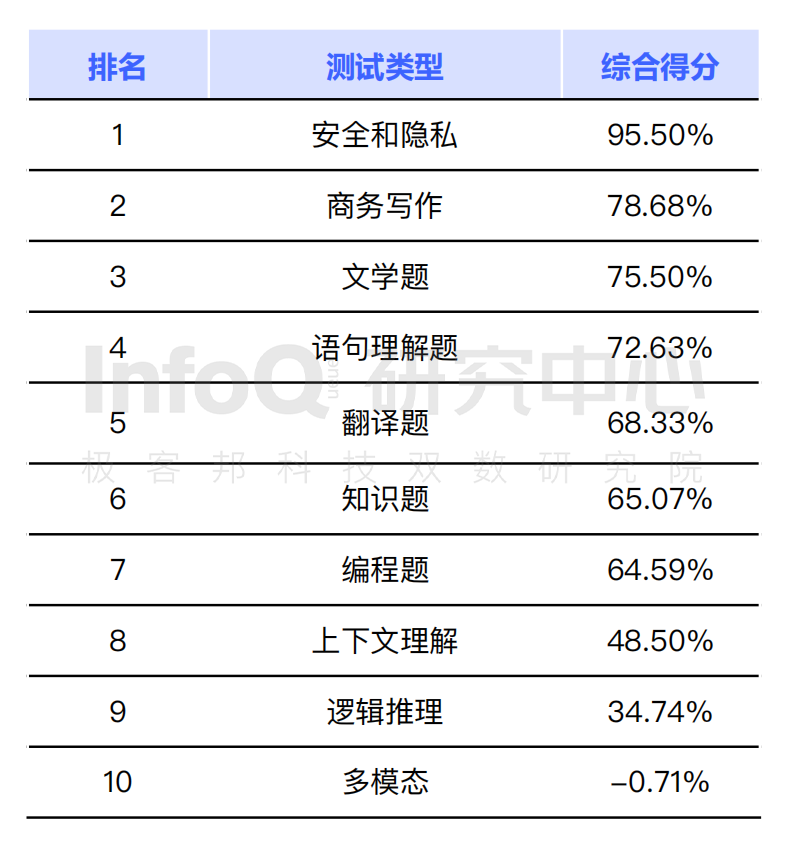
在基础能力层面,大语言模型展现出了优秀的中文创意写作能力。在六个写作细分题目分类中, 大语言模型表现均较为突出,其中访谈提纲和邮件写作都获得了接近满分的成绩,而比较之下视频脚本的写作仍然是大语言模型产品较不熟悉的领域,细分题目类别得分仅为 75%。
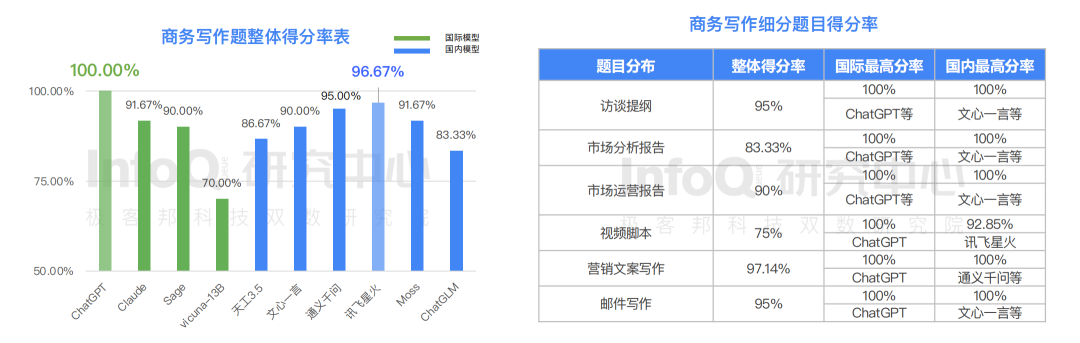
关于文学题,随着写作难度的升高,大语言模型表现的能力水平递减。其中表现最好的板块为简单写作题,得分为 91%;对联题虽然很多模型表现较好,但是有⼀些模型对对联回答表现欠佳, 整体得分最低为 55%。
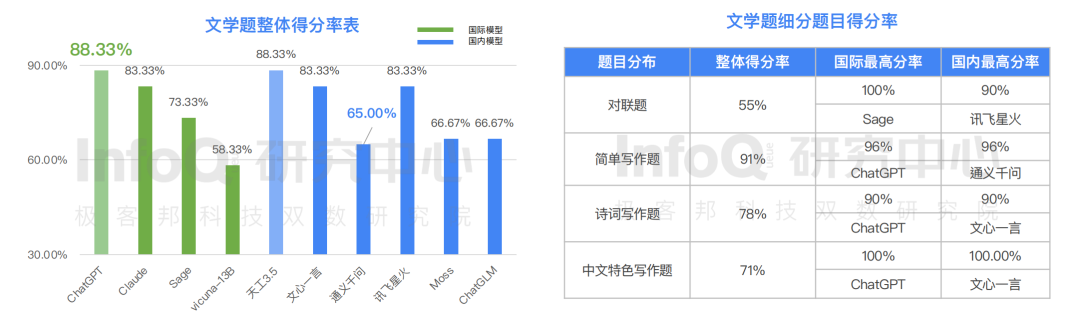
然而,在语义理解方面,目前的大语言模型就没有那么“灵”了。在方言理解、关键词提炼、语义相似判断、“怎么办”4 个题目分类中, 大语言模型呈现很大的差异化分布, “怎么办”题获得最高分 92.5%,中文方言理解题难倒了大语言模型,整体准确率仅为 40%。
InfoQ 研究中心的报告显示,就中文知识这一类题目而言,国内模型表现明显优于国际模型。在十个模型中知识得分最高的为文心一言,得分 73.33%,得分第二的为 ChatGPT,得分为 72.67%。除 IT 知识问答题目外,其他八个题目分类中国内的大模型产品在中文知识环境中会的问答表现整体接近或优于国际大模型产品。
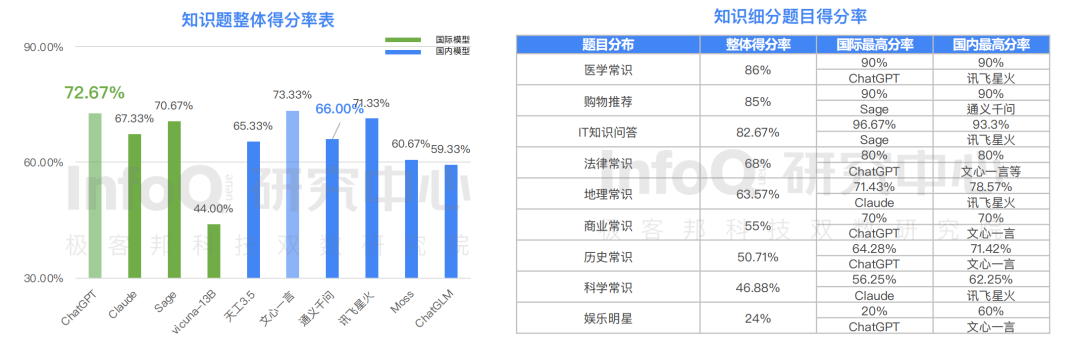
事实上,无论是中文创意写作,还是语义理解、中文知识问答,这些题目都主要反应的是大语言模型产品对文字的基础认知和学习能力,而我们从测评结果中清晰的看到,百度文心一言各方面数据表现优异,各项能力评分都位居 Top2。然而,我们看到的其实不仅是文心一言的技术能力,我们更多看到的是国内大语言模型的强势技术突破和显著进步。
三、国内产品在跨语言翻译中仍有较大提升空间,逻辑推理能力整体挑战较大
随着近几年,国家和国内各厂商在人工智能领域的投入逐年增大,我们看到了国内大语言模型的飞速进步,技术成果使我们喜悦,但是当我们更客观地去看大语言模型技术的发展,我们会发现我们在一些方面和国际水平相比还有许多提升空间。
比如我们从 InfoQ 研究中心发布的《报告》就可以得知,国外产品编程能力显著高于国内产品,在十个模型中编程得分最高的为 Claude,得分 73.47%,国内产品表现最好的文心一言,得分 68.37%,与 Claude 还存在一定的距离。在四个题目分类中,Android 相关题目国外产品明显超越国内产品,但令人惊喜的是,在“代码自动补全类”题目中,国内产品文心一言已经超越国外产品,这说明国内产品超越国际水平仅是时间问题。
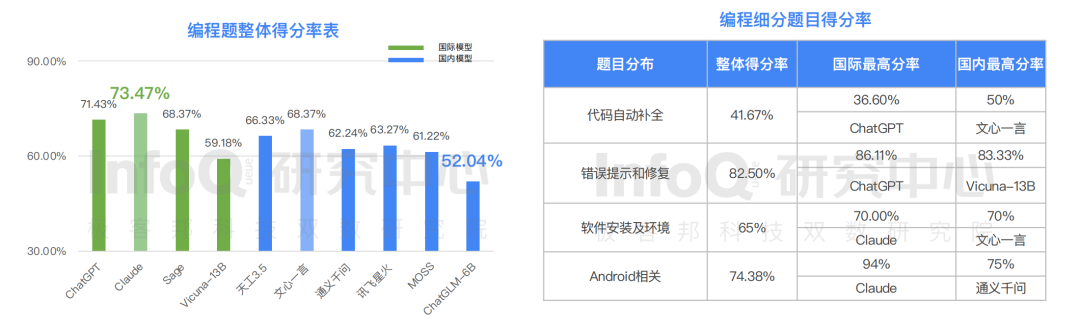
此外,在十个模型中知识得分最高者也是 Claude,得分 93.33%,国内大语言模型得分最高的分别为文心一言和天工 3.5,但与国际水平依旧存在差距。要知道,翻译类题目主要反应大语言模型产品对语言的理解能力,此次 InfoQ 评测的“编程翻译题”、“英文写作”、“英文阅读理解”三个题目分类中,大语言模型呈现很大的差异化分布, 在测评的所有模型中,英文写作题获得的最高分 80%,而英文阅读理解仅获得得分 46%,这意味着国内产品在跨语言翻译方面还需要继续努力迭代。
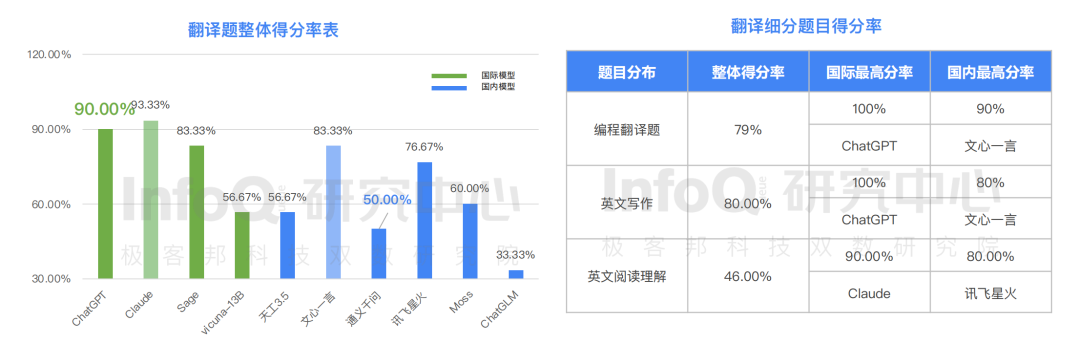
差距犹在,但不必妄自菲薄,大模型技术的技术演进一直在进行着。据《报告》显示,目前整个大语言模型在逻辑推理能力方面的挑战都比较大。为了考评大语言模型的理解力和判断力,InfoQ 研究中心设置了多个维度的逻辑推理题。在商务制表题、数学计算题、数学应用题、幽默题、中文特色推理题 5 个题目分类中,大语言模型整体得分都低于基础能力。分析原因, 商务制表题不但需要搜集和识别内容还需要在内容的基础上做逻辑分类和排序,整体难度较大,逻辑推理能力是未来大语言模型产品的主要进攻方向。
在 InfoQ 研究中心测评的十个模型中,逻辑推理题得分最高的为文心一言和讯飞星火,得分均为 60%,与得分最高的 ChatGPT 仅差 1.43%。在部分细分领域,国内产品的表现还是十分优异的,比如在中文特色推理题中,国内模型领先国际模型得分较多, 国内模型对中文内容和逻辑的熟悉应该是该结果的核心原因。

从 InfoQ 研究中心发布的以上测评结果来看国内产品与国外产品的差距,国内大语言模型能力接近 GPT3.5 水平,但是与 GPT4 能力仍存在巨大差距。然而,纵观整个大语言模型领域,其实我们每个人都可以清晰地发现,大语言模型技术的发展门槛和挑战还是非常高的,芯片门槛、实践经验积累的门槛、数据和语料门槛都需要国内外各大厂商一起努力突破。
从 InfoQ 研究中心的评测结果来看,文心一言的综合评分已与 ChatGPT 所差无几,在中国最新涌起的互联网革命浪潮中,文心一言可以称之为国内最有希望在短期内赶超国际水准的 AIGC 产品。而拥有众多 AI 专家的文心一言团队一直保持着兢兢业业地技术探索态度,努力缩小差距中,文心一言的下一次突破已经不远了,值得我们所有人期待。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ 策划主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论