
LinkedIn 的会员可以在自己的档案中填充个人信息,例如工作经历、教育经历、技能专长等等。从会员的输入中,我们利用人工智能模型来抽取他们的档案属性或档案实体。这个过程被称为标准化和知识图谱的构建,并生成与会员有关的实体的知识图谱。
这是了解会员档案的重要一环,以便我们能在这个平台上为会员提供更多的相关工作、新闻报道、联系和广告。作为这一过程的一部分,我们也试图对“缺失”的档案实体进行推理,这些实体在现有知识图谱中并没有抽取。比如,一个会员掌握机器学习的技能,在谷歌工作,我们就推断出,这名会员精通 TensorFlow,尽管他们目前的档案中并没有这么说。
有一些原因可以解释为何总有一些缺失的实体。首先,大部分实体抽取技术都是依赖于文本信息。如果在文本中没有特别提及某个实体,则这些模型很有可能错过这个实体。第二,会员不一定会提供全部信息。比如,会员可以不把自己掌握的全部技能都列出来,而是把自己的一些技能放在自己的档案里。通过对缺失的实体进行推理,我们可以在 LinkedIn 的产品中为会员提供更好的推荐。比如,我们可以展示更多的相关工作、新闻报道和他们可能认识的人。
推理缺失的实体具有挑战性,因为它需要对会员的档案有一个整体的理解。当前的实体抽取技术是以文本为主要输入,不能对文本中没有明确提及的实体进行推理。
本文的目的是通过从会员输入的实体,对缺失的实体进行推理。比如,我们想要利用实体“机器学习”和“谷歌”来推理“TensorFlow”。这里的困难在于将多个实体之间的交互考虑在内。有几种简单的统计方式可以从单一的实体中寻找相关的实体,例如,点互信息(pointwise mutual information,PMI)。但是,如果我们仅从“谷歌”中选择相关技能,那么我们就有很大的机会最终得到其他推理的技能,比如“MapReduce”或者“Android”,但与“TensorFlow”相比,它们在这个例子中的相关性并没有那么高。
在这篇博文中,我们将会探讨如何建立一种新的模型,利用图神经网络来解决这一问题。
我们的方法
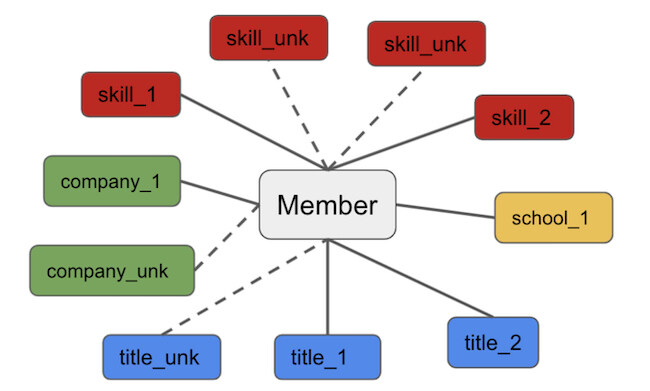
我们将实体推理表述为图上的推理问题。图 1 是我们对表述的一个可视化。实线是给定会员的现有实体邻居,虚线是潜在的新邻居,在档案中没有明确提及。我们的目标是在给定现有邻居的情况下预测新的邻居,这可以理解为图设置中的标准链接预测问题。
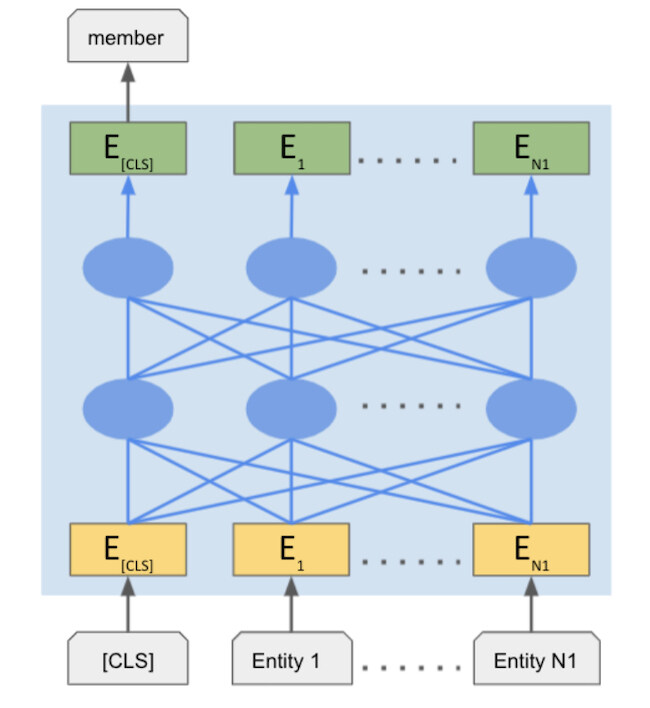
本文采用图神经网络来解决连接预测问题。图神经网络(Graph Neural Network,GNN)是一种用于从图中抽取信息的神经网络,给定一个输入图,图神经网络为每个节点学习一个潜在的表征,这样一个节点的表征就是其邻居的表征集合。
通过这一过程,由图神经网络所学到的表征,可以在输入图中捕捉到连接的结构。在我们的设置中(如图 1 所示),我们的图神经网络将使用其邻居(会员及其实体)学习“company_unk”的表示,然后我们将使用该表示来预测这将是哪家公司;也就是说,我们通过聚合来自现有实体的信息,从而推理缺失的实体。
值得注意的是,由于现有的图神经网络采用了简单的聚合方法,例如平均法或者加权平均法,因此它们在聚合邻居(会员实体)方面存在差距。若现有实体之间存在复杂的交互,那么这种简单的聚合方法将会失效。
本文针对这个问题,提出了一种新型的图神经网络模型,我们称之为 Entity-BERT。这个模型采用了一个多层双向 Transformer 来进行聚合。给定一组现有的实体,我们采用了一个叫做 Transformer 的神经网络,通过计算每一对实体之间的交互(注意力)来更新一个节点的表示。为了捕获实体之间越来越复杂的交互,它会重复这一操作 6~24 次。
在自然语言处理的句子理解方面,多层双向 Transformer 具有卓越的表现,其目的在于理解给定句子中单词之间的交互。尤其是 BERT(Bidirectional Encoder Representation with Transformers,带 Transformer 的双向编码器表示),在各种自然语言处理任务中的性能,超过了其他非 Transformer 神经网络。我们相信,BERT 同样能够提高实体推理的性能。我们的类 BERT 聚合器的结构如图 2 所示。
训练和推理
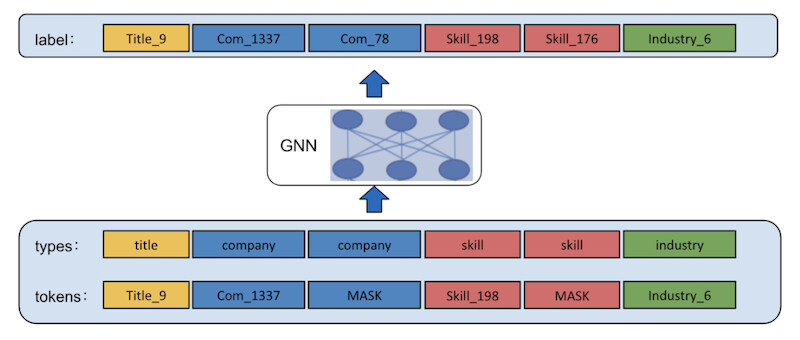
该模型通过自我监督进行训练。给定一个会员档案,我们从他们的档案中屏蔽或隐藏一些属性,并学习如何预测被屏蔽的属性。我们用 [MASK] 替换每个会员档案中 10% 的实体,并按其类型(技能、职称、公司、学校等)进行分组。
图 3 展示了一个例子,其中公司和技能被屏蔽了。受自然语言处理中 BERT 的启发,我们也将实体类型作为一个额外的输入,并且给它们分配了类型 ID。例如,公司→1,行业→2,技能→3,职称→4。
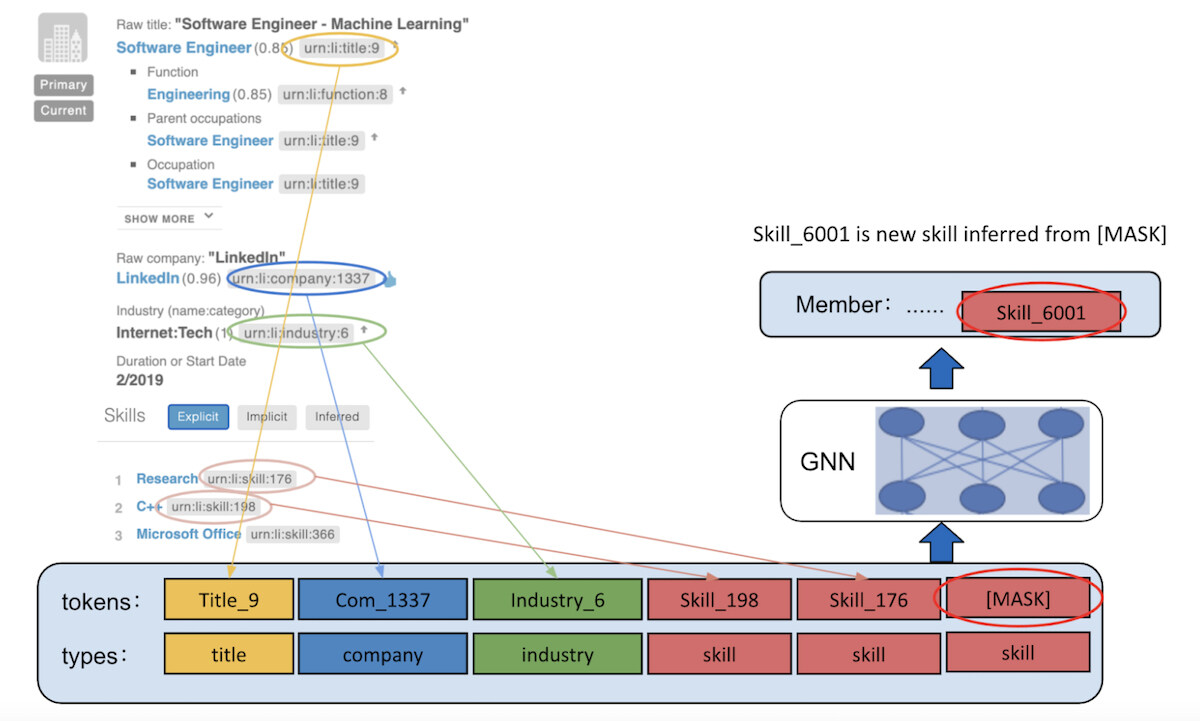
在评分/推理过程中,我们将某些屏蔽的实体添加到会员的档案中,并且指定每个屏蔽的类型。一个例子如图 4 所示。在这里,会员已经拥有了诸如 itle_9、Company_1337、Industry_6、Skill_198 和 Skill_176 等标准化的实体。我们希望为这个会员预测隐藏的技能。因此,我们将一个 [MASK] 实体附加到技能类型上。模型随后会在与 [MASK] 相同的位置输出技能。
成果
应用 1:技能推荐
我们的技能推荐系统推荐会员可能具备的技能,但这些技能在他们的档案中并没有提及。当会员点击档案的“技能认可”中的“添加技能”(Add a new skill)时,它就会被触发(如图 5 所示)。在新会员创建新的档案时,它也会向他们展示(如图 6 所示)。
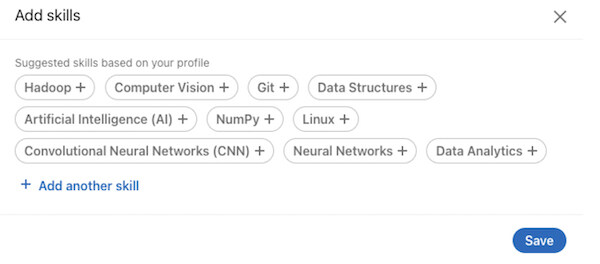
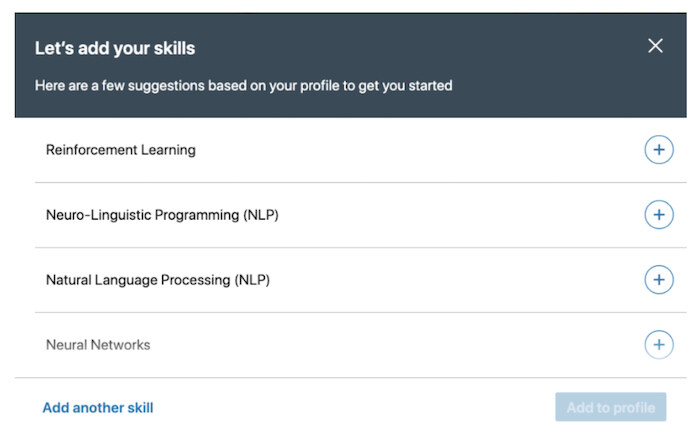
我们利用 Entity-BERT 来推理和推荐未在会员档案上提及的技能。通过将 Entity-BERT 与之前使用会员当前实体并进行简单汇总的方法进行比较,我们观察到,利用基于 Entity-BERT 的方法,可以让会员接受更多推荐。我们还观察到,这些额外的技能使得更多的会员参与,比如更多的会议。
应用 2:广告受众拓展
LinkedIn 的广告商通过会员档案属性指定他们的目标受众,比如向人工智能工程师展示广告。另外,他们中有些人还会选择受众拓展,将受众拓展到拥有类似实体的其他会员,比如向人工智能工程师和人工智能研究人员展示广告。
我们利用 Entity-BERT 对会员的档案实体(公司、技能和职称)进行扩展,并利用这些扩展的实体来拓展受众。在线上 A/B 测试中,与之前没有 Entity-BERT 的扩展模式相比,通过 Entity-BERT 进行的受众拓展,其带来的广告收入在统计学上显示出了重大影响,而不会影响到用户体验(如广告点击)。
结语
在这篇文章中,我们介绍了 Entity-BERT,它是一种新型的图神经网络,可以从现有的会员知识图谱中推理出缺失的会员实体。Entity-BERT 的创新之处在于,它使用了多层双向 Transformer 来捕捉现有实体之间的交互。Entity-BERT 已经表明,它能够有效地对缺失的实体进行推理,从而对产品产生重要的影响。
作者介绍:
Jaewon Yang,LinkedIn 高级软件工程师,韩国人。
Jiatong Chen,LinkedIn 高级软件工程师,中国人,毕业于中国科技大学,耶鲁大学研究生。
Yanen Li,LinkedIn 机器学习工程主管,中国人,毕业于华中科技大学,伊利诺伊大学香槟分校博士生。
原文链接:




